Modellierungsphase des Team Data Science-Prozesslebenszyklus
In diesem Artikel werden die Ziele, Aufgaben und Projektleistungen im Zusammenhang mit der Modellierungsphase des Team Data Science-Prozesses (TDSP) behandelt. Dieser Prozess stellt einen empfohlenen Lebenszyklus bereit, mit dem Ihr Team Ihre Data Science-Projekte strukturieren kann. Der Lebenszyklus beschreibt die wesentlichen Projektphasen, an denen Ihr Team arbeitet, häufig auf iterative Weise:
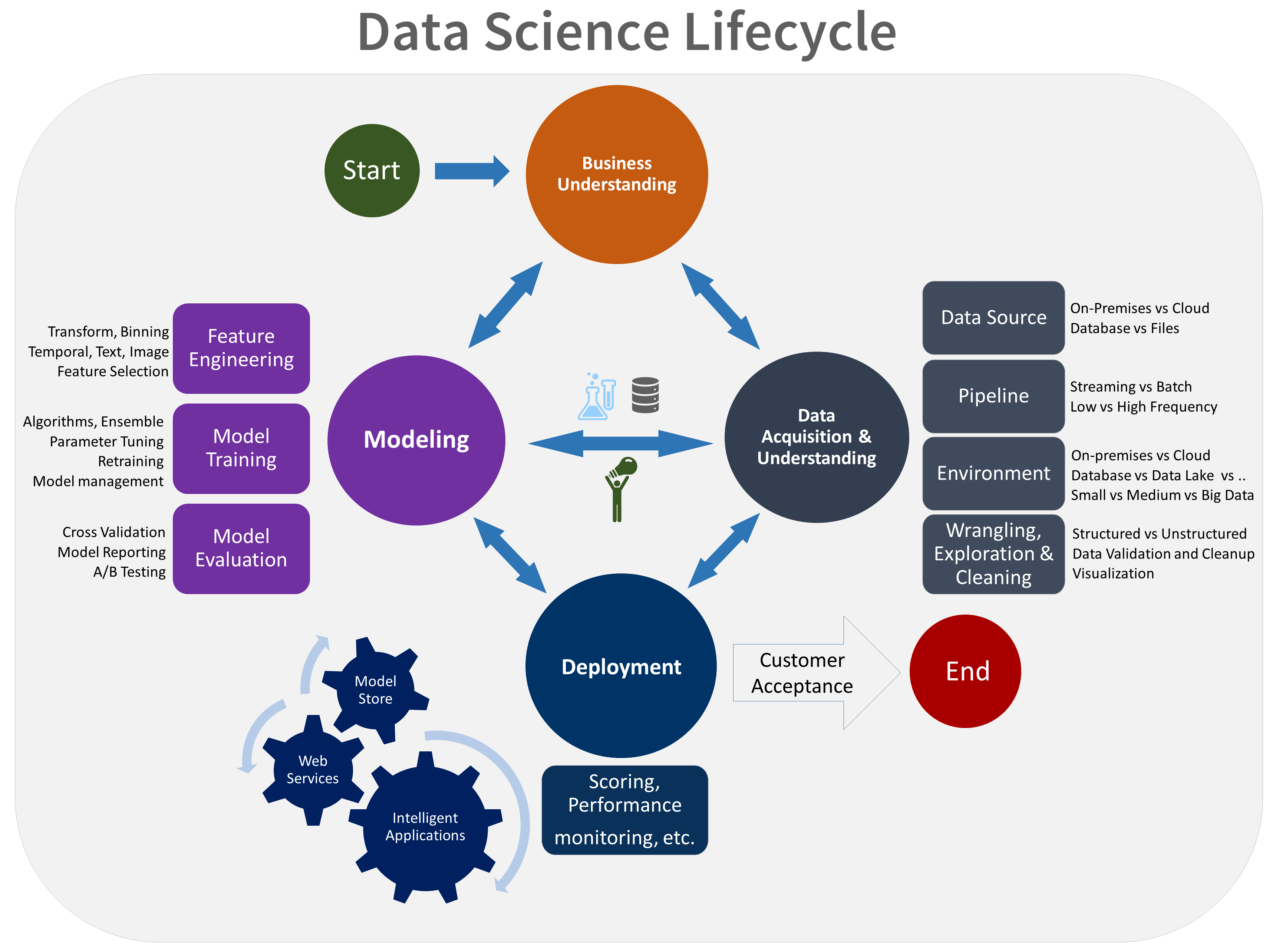
- Geschäftliche Aspekte
- Datenerfassung und -auswertung
- Modellierung
- Bereitstellung
- Kundenakzeptanz
Dies ist eine visuelle Darstellung des TDSP-Lebenszyklus:
Ziele
Dies sind die Ziele der Modellierungsphase:
Ermittlung der optimalen Datenfeatures für das Machine Learning-Modell.
Erstellung eines informativen Machine Learning-Modells, mit dem das Ziel am genauesten vorhergesagt wird.
Erstellung eines Machine Learning-Modells, das für die Produktion geeignet ist.
Ausführung der Aufgaben
Die Modellierungsphase umfasst drei Hauptaufgaben:
Featureentwicklung: Erstellen Sie Datenfeatures aus den Rohdaten, um das Trainieren des Modells zu ermöglichen.
Modelltraining: Ermittlung des Modells, das die Frage am genauesten beantwortet, durch den Vergleich der Erfolgsmetriken von Modellen.
Modellbewertung: Ermittlung, ob Ihr Modell für die Produktion geeignet ist.
Featureentwicklung
Die Featureentwicklung umfasst die Einbeziehung, Aggregation und Transformation von Rohvariablen zum Erstellen der Features, die in der Analyse verwendet werden. Wenn Sie Erkenntnisse zum Aufbau eines Modells erhalten möchten, müssen Sie die zugrunde liegenden Features des Modells untersuchen.
Dieser Schritt erfordert eine kreative Kombination von Sachkenntnis mit den im Datenuntersuchungsschritt gewonnenen Erkenntnissen. Das Feature Engineering ist ein Balanceakt, da Sie informative Variablen suchen und einfügen müssen, gleichzeitig jedoch die Einfügung zu vieler irrelevanter Variablen vermeiden sollten. Informative Variablen verbessern Ihr Ergebnis. Nicht relevante Variablen belasten Ihr Modell unnötig. Sie müssen diese Features auch für alle neuen Daten generieren, die während der Bewertung ermittelt werden. Deshalb kann die Generierung dieser Features nur von Daten abhängen, die zum Zeitpunkt der Bewertung verfügbar sind.
Modelltraining
Sie können aus zahlreichen Modellierungsalgorithmen wählen, abhängig von der Art der Frage, die Sie beantworten möchten. Eine Anleitung für die Auswahl eines vordefinierten Algorithmus finden Sie unter Spickzettel mit Machine Learning-Algorithmen für Azure Machine Learning-Designer. Andere Algorithmen sind über Open-Source-Pakete in R oder Python verfügbar. Auch wenn der Fokus dieses Artikels auf Azure Machine Learning liegt, sind die hier enthaltenen Anleitungen auf zahlreiche Machine Learning-Projekte anwendbar.
Der Prozess für das Modelltraining umfasst die folgenden Schritte:
Sie können die Eingabedaten beliebig für die Modellierung eines Trainingsdatasets und eines Testdatasets aufteilen.
Erstellen Sie die Modelle mit dem Trainingsdataset.
Führen Sie eine Auswertung von Trainings- und Testdataset durch. Verwenden Sie eine Reihe konkurrierender Machine Learning-Algorithmen. Verwenden Sie verschiedene zugeordnete Optimierungsparameter (als Parameter-Sweeping bezeichnet), die auf die Beantwortung der Frage anhand der aktuellen Daten ausgerichtet sind.
Ermitteln Sie die beste Lösung für die Beantwortung der Frage, indem Sie die Erfolgsmetriken für alternative Methoden vergleichen.
Weitere Informationen finden Sie unter Trainieren von Modellen mit Machine Learning.
Hinweis
Vermeiden von Datenlecks: Sie könnten Datenlecks verursachen, wenn Sie Daten von außerhalb des Trainingsdatasets einbeziehen, die dazu führen, dass ein Modell oder ein Machine-Learning-Algorithmus unrealistisch gute Vorhersagen erstellt. Datenlecks sind häufig der Grund dafür, warum Data Scientists nervös werden, wenn die Vorhersageergebnisse zu schön sind, um wahr zu sein. Es könnte schwierig sein, diese Abhängigkeiten zu erkennen. Zur Vermeidung von Datenlecks ist es häufig erforderlich, die Schritte zur Entwicklung eines Analyse-Datasets, zur Erstellung eines Modells und zur Auswertung der Genauigkeit der Ergebnisse wiederholt zu durchlaufen.
Modellauswertung
Nachdem das Modell trainiert wurde, wertet ein Data Scientist in Ihrem Team das Modell aus.
Treffen einer Entscheidung: Bewerten Sie das Modell hinsichtlich seiner Eignung für die Produktion. Einige wichtige Fragen lauten:
Kann die Frage mit dem Modell basierend auf den Testdaten ausreichend beantwortet werden?
Sollten Alternativen ausprobiert werden?
Sollten Sie mehr Daten sammeln, mit dem Feature Engineering fortfahren oder mit anderen Algorithmen experimentieren?
Interpretieren des Modells: Führen Sie mithilfe des Machine Learning Python SDK die folgenden Aufgaben aus:
Erläutern Sie das gesamte Modellverhalten oder einzelne Vorhersagen lokal auf Ihrem persönlichen Computer.
Aktivieren Sie Techniken zur Interpretierbarkeit von entwickelten Features.
Erläutern Sie das Verhalten für das gesamte Modell und einzelne Vorhersagen in Azure.
Laden Sie Erklärungen zum Machine Learning-Ausführungsverlauf hoch.
Interagieren Sie über ein Visualisierungsdashboard mit Ihren Modellerklärungen, sowohl in einem Jupyter-Notebook als auch im Machine Learning-Arbeitsbereich.
Stellen Sie einen Bewertungsexplainer mit Ihrem Modell bereit, um die Erklärungen während der Rückschlüsse zu beobachten.
Bewertung der Fairness: Führen Sie mithilfe des Open-Source-Pakets Fairlearn von Python mit Machine Learning die folgenden Aufgaben aus:
Bewerten Sie die Fairness Ihrer Modellvorhersagen. Mithilfe dieses Prozesses kann Ihr Team mehr über Fairness im Machine Learning erfahren.
Laden Sie Erkenntnisse zur Fairnessbewertung zu Machine Learning Studio hoch, listen Sie diese auf, und laden Sie diese herunter.
Zeigen Sie das Dashboard für die Fairnessbewertung in Machine Learning Studio an, um mit den Erkenntnissen zur Fairness Ihrer Modelle zu interagieren.
Integration in MLflow
Machine Learning kann in MLflow integriert werden, um den Modellierungslebenszyklus zu unterstützen. Der Dienst nutzt die Nachverfolgungsfunktionen von MLflow für Experimente, Projektbereitstellung, Modellverwaltung und Modellregistrierung. Diese Integration stellt einen nahtlosen und effizienten Machine-Learning-Workflow sicher. Die folgenden Funktionen in Machine Learning unterstützen diese Phase des Modellierungslebenszyklus:
Nachverfolgen von Experimenten: Die Kernfunktionalität von MLflow wird in der Modellierungsphase umfassend zur Nachverfolgung der einzelnen Experimente, Parameter, Metriken und Artefakte verwendet.
Bereitstellen von Projekten: Die Verpackung von Code mit MLflow Projects stellt sicher, dass der Code konsistent ausgeführt wird und einfach zwischen Teammitgliedern geteilt werden kann. Dies hat entscheidende Bedeutung für die iterative Modellentwicklung.
Verwalten von Modellen: Die Verwaltung und Versionierung von Modellen ist in dieser Phase von kritischer Bedeutung, da verschiedene Modelle erstellt, bewertet und optimiert werden.
Registrieren von Modellen: Die Modellregistrierung wird verwendet, um Modelle während des gesamten Lebenszyklus zu versionieren und zu verwalten.
Peer-geprüfte Literatur
Forscher*innen veröffentlichen Studien zum TDSP in Peer-geprüfter Literatur. Die Referenzen bieten eine Möglichkeit, andere Anwendungen oder dem TDSP vergleichbare Ansätze zu untersuchen, die ebenfalls eine Modellierungsphase umfassen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Mark Tabladillo | Senior Cloud Solution Architect
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Zugehörige Ressourcen
Diese Artikel beschreiben die übrigen Phasen des TDSP-Lebenszyklus:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für