Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Das Choreographiemuster dezentralisiert Workflowlogik und verteilt Verantwortlichkeiten an andere Komponenten innerhalb eines Systems. Anstatt sich auf einen zentralen Orchestrator zu verlassen, entscheiden Dienste selbst, wann und wie eine Geschäftsoperation verarbeitet werden soll.
Kontext und Problem
In der Regel teilen Sie eine cloudbasierte Anwendung in mehrere kleine Dienste auf, die zusammenarbeiten, um eine End-to-End-Geschäftstransaktion zu verarbeiten. Ein einzelner Vorgang innerhalb einer Transaktion kann zu mehreren Punkt-zu-Punkt-Aufrufen zwischen allen Diensten führen. Im Idealfall sind diese Dienste lose gekoppelt. Es ist schwierig, einen verteilten, effizienten und skalierbaren Workflow zu entwerfen, da es eine komplexe Interservicekommunikation erfordert.
Ein gängiges Muster für die Kommunikation ist die Verwendung eines zentralisierten Dienstes oder eines Orchestrators. Eingehende Anfragen fließen durch den Orchestrator, der Vorgänge an die jeweiligen Dienste delegiert. Jeder Dienst erledigt seine Verantwortung und weiß nicht über den gesamten Workflow.

In der Regel implementieren Sie das Orchestratormuster als benutzerdefinierte Software, die über Domänenwissen über die Verantwortlichkeiten der Dienste im System verfügt. Ein Vorteil dieses Ansatzes besteht darin, dass der Orchestrator den Status einer Transaktion basierend auf den Ergebnissen einzelner Vorgänge konsolidieren kann, die die nachgeschalteten Dienste durchführen.
Dieser Ansatz schafft auch einige Hindernisse. Das Hinzufügen oder Entfernen von Diensten kann zu einer Unterbrechung der bestehenden Logik führen, da Sie Teile des Kommunikationspfads neu verdrahten müssen. Diese Abhängigkeit macht die Orchestrator-Implementierung komplex und schwer zu pflegen. Der Orchestrator kann sich negativ auf die Zuverlässigkeit der Workload auswirken. Unter Last können Leistungsengpässe auftreten und es kann der Single Point of Failure (SPoF) sein. Außerdem kann es zu kaskadenartigen Ausfällen bei den nachgelagerten Diensten kommen.
Lösung
Delegieren Sie die Transaktionsverarbeitungslogik zwischen den Diensten. Lassen Sie jeden Dienst am Kommunikationsworkflow für einen Geschäftsvorgang teilnehmen und entscheiden, wann und wie er verarbeitet werden soll.
Das Choreographiemuster minimiert die Abhängigkeit von benutzerdefinierter Software, die den Kommunikationsworkflow zentralisiert. Die Komponenten implementieren gemeinsame Logik, während sie den Workflow unter sich selbst choreographieren, ohne sich direkt miteinander zu kommunizieren.
Eine gängige Methode zur Implementierung der Choreografie ist die Verwendung eines Nachrichtenmaklers, der Anfragen puffert, bis nachgelagerte Komponenten sie anfordern und verarbeiten. Die folgende Abbildung zeigt die Anforderungsverarbeitung über ein Herausgeberabonnentmodell.

Clientanforderungen werden als Nachrichten in einer Warteschlange eines Nachrichtenbrokers platziert.
Die Dienste oder der Abonnent fragt den Broker ab, um festzustellen, ob diese Nachricht basierend auf ihrer implementierten Geschäftslogik verarbeitet werden kann. Der Broker kann nachrichten auch an Abonnenten senden, die an dieser Nachricht interessiert sind.
Jeder abonnierte Dienst führt seinen Vorgang wie in der Nachricht angegeben aus und antwortet dem Broker mit einer Erfolgs- oder Fehlermeldung.
Wenn der Vorgang erfolgreich ist, kann der Dienst eine Nachricht zurück an dieselbe Warteschlange oder eine andere Nachrichtenwarteschlange senden, damit ein anderer Dienst den Workflow bei Bedarf fortsetzen kann. Schlägt der Vorgang fehl, arbeitet der Message Broker mit anderen Diensten zusammen, um diesen Vorgang oder die gesamte Transaktion zu kompensieren.
Probleme und Überlegungen
Berücksichtigen Sie die folgenden Punkte, wenn Sie sich für die Implementierung dieses Musters entscheiden:
Die Behandlung von Fehlern kann eine Herausforderung darstellen. Komponenten in einer Anwendung können Atomaufgaben verwalten und von anderen Teilen des Systems abhängen. Fehler in einer Komponente können sich auf andere Komponenten auswirken, was zu Verzögerungen beim Abschließen der Gesamtanforderung führen kann.
Um Fehler ordnungsgemäß zu behandeln, implementieren Sie Fehlerbehandlungslogik, die Komplexität einführt. Fehlerbehandlungslogik, z. B. Ausgleichstransaktionen, sind ebenfalls anfällig für Fehler.
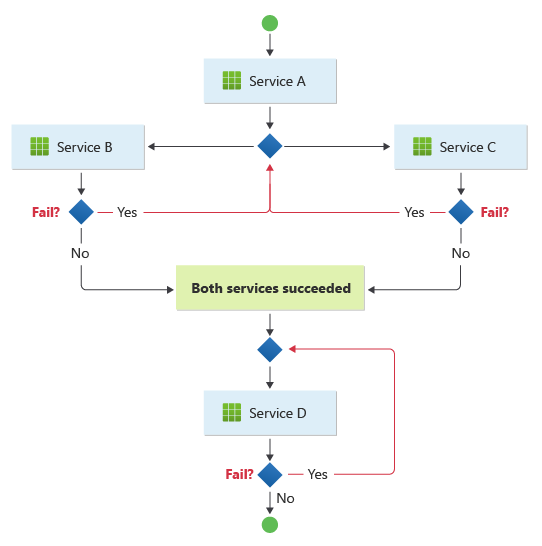
Dieses Muster passt zu einem Workflow, der unabhängige Geschäftsvorgänge parallel verarbeitet. Der Arbeitsablauf kann kompliziert werden, wenn die Choreografie in einer Abfolge stattfinden muss. Beispielsweise kann Service D den Vorgang erst starten, nachdem Service B und Service C ihre Vorgänge erfolgreich abgeschlossen haben.
Dieses Muster stellt Herausforderungen dar, wenn die Anzahl der Dienste schnell wächst. Zahlreiche unabhängige bewegliche Teile erschweren den Workflow zwischen Diensten. Sie müssen die verteilte Ablaufverfolgung und die Korrelations-IDs konsistent verwenden, um die Observierbarkeit aufrechtzuerhalten.
In einem orchestratorgeführten Design kann die zentrale Komponente Resilienzaufgaben, wie die Fehlerbehandlung für vorübergehende, nicht-transiente und Zeitüberschreitungsfehler, an einen dedizierten Resilienz-Handler delegieren.
Wenn Sie den Orchestrator in einem Choreographie-basierten Design entfernen, übernehmen downstream-Komponenten keine Resilienzverantwortung. Sie bleiben zentral im Resilienzhandler. Nachgeschaltete Komponenten müssen jedoch direkt mit diesem Handler kommunizieren, wodurch die Punkt-zu-Punkt-Kommunikation erhöht wird.
Die Ereignisschemaentwicklung kann im Laufe der Zeit zu unterbrechungsübergreifenden Änderungen bei Verbrauchern führen. In diesem Muster nutzen mehrere unabhängige Dienste dieselben Ereignisse. Wenn ein Produzent die Datenstruktur eines Ereignisses ändert, kann es nachgeschaltete Verbraucher unterbrechen, die von dem alten Schema abhängen. Verwenden Sie eine Schemaregistrierung, um Ereignisverträge zu verwalten und abwärtskompatible Weiterentwicklung zu verwenden, wenn Dienste unabhängig voneinander weiterentwickelt werden.
Die Reihenfolge von Ereignissen ist bei Wiederholungen oder Skalierung nicht garantiert. Entwerfen Sie für Idempotenz und senden Sie Nachrichten in der richtigen Reihenfolge erneut, um doppelte oder außerhalb der Reihenfolge liegende Ereignisse zu behandeln.
Dezentrale Ereignistopologien können emergentes Verhalten in großem Maßstab erzeugen. Wenn viele Dienste auf die Ereignisse der anderen reagieren, kann das System unbeabsichtigt Feedbackschleifen oder Ereignisstürme erzeugen. Ein kleineres Ereignis kann eine Kaskade von nachgeschalteten Reaktionen auslösen. Um zyklische Ereignisketten zu verhindern, verwenden Sie Schutzmaßnahmen wie Ereignisfilterung, Begrenzung der gleichzeitigen Verbraucher, Drosselung und explizite Regeln.


Wann Sie dieses Muster verwenden sollten
Verwenden Sie dieses Muster in folgenden Fällen:
Die nachgelagerten Komponenten behandeln atomare Operationen unabhängig voneinander. Stellen Sie sich dieses Muster als Fire-and-Forget-Mechanismus vor, bei dem eine Komponente eine Aufgabe ausführt, die keine aktive Verwaltung benötigt. Nach Abschluss der Aufgabe sendet die Komponente eine Benachrichtigung an die anderen Komponenten.
Sie erwarten, dass Sie die Komponenten häufig aktualisieren und ersetzen. Mit diesem Muster können Sie die Anwendung mit weniger Aufwand und minimalen Unterbrechungen für vorhandene Dienste ändern.
Sie verwenden serverlose Architekturen für einfache Workflows. Die Komponenten können kurzlebig und ereignisgesteuert sein. Wenn ein Ereignis auftritt, erstellt der Dienst Komponenten, die eine Aufgabe ausführen, und der Dienst entfernt Komponenten, nachdem sie diese Aufgabe abgeschlossen haben.
Die Kommunikation zwischen gebundenen Kontexten erfordert eine lose Kopplung über Domänengrenzen hinweg. Wenden Sie für die Kommunikation innerhalb eines einzelnen gebundenen Kontexts stattdessen ein Orchestratormuster an.
Der zentrale Orchestrator führt zu einem Leistungsengpass.
Dieses Muster ist möglicherweise nicht geeignet, wenn:
Die Anwendung ist komplex und erfordert eine zentrale Komponente, die die gemeinsame Logik handhabt, um die nachgeschalteten Komponenten schlank zu halten.
Die Punkt-zu-Punkt-Kommunikation zwischen den Komponenten ist unvermeidlich.
Sie müssen die Geschäftslogik verwenden, um sämtliche Vorgänge, die nachgelagerte Komponenten übernehmen, zu konsolidieren.
Workloadentwurf
Bewerten Sie, wie Sie das Choreographiemuster im Entwurf einer Workload verwenden, um die in den Azure Well-Architected Framework-Säulen behandelten Ziele und Prinzipien zu erfüllen. Die folgende Tabelle enthält Anleitungen dazu, wie dieses Muster die Ziele jeder Säule unterstützt.
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Operational Excellence unterstützt die Workloadqualität durch standardisierte Prozesse und Teamzusammenhalt. | Die verteilten Komponenten in diesem Muster sind autonom und so konzipiert, dass sie austauschbar sind, sodass Sie die Arbeitsauslastung mit weniger gesamter Änderung am System ändern können. - OE:04 Tools und Prozesse |
| Performance Efficiency hilft Ihrem Workload durch Optimierungen bei Skalierung, Daten und Code, die Anforderungen effizient zu erfüllen . | Dieses Muster bietet eine Alternative, wenn Leistungsengpässe in einer zentralisierten Orchestrierungstopologie auftreten. - PE:02 Kapazitätsplanung - PE:05 Skalierung und Partitionierung |
Wenn dieses Muster Kompromisse innerhalb einer Säule einführt, sollten Sie sie gegen die Ziele der anderen Säulen berücksichtigen.
Beispiel
In diesem Beispiel wird das Choreographiemuster veranschaulicht, indem eine ereignisgesteuerte, cloudeigene Workload erstellt wird, die Funktionen zusammen mit Microservices ausführt. Wenn ein Kunde ein Paket versenden möchte, weist die Arbeitsauslastung eine Drohne zu. Nachdem das Paket für die Abholung durch die geplante Drohne bereit ist, beginnt der Liefervorgang. Während sich das Paket auf dem Weg befindet, bearbeitet die Workload die Lieferung, bis sie den Versandstatus erreicht.

Der Aufnahmedienst empfängt Kundenanfragen und wandelt sie in Nachrichten um, welche die Lieferdetails enthalten. Geschäftstransaktionen beginnen, nachdem Dienste diese neuen Nachrichten nutzen.
Ein einziger Geschäftsvorgang eines Kunden erfordert drei verschiedene Geschäftsvorgänge:
Erstellen oder Aktualisieren eines Pakets.
Weisen Sie eine Drohne zu, um das Paket zu liefern.
Bearbeiten Sie die Lieferung, einschließlich der Überprüfung und des Sendens einer Benachrichtigung, wenn das Paket versandt wird.
Paket-, Drohnen-Scheduler- und Liefer-Microservices führen die Geschäftsverarbeitung durch. Die Dienste verwenden Messaging anstelle eines zentralen Orchestrators, um miteinander zu kommunizieren. Jeder Dienst muss im Voraus ein Protokoll implementieren, das den Geschäftsworkflow dezentral koordiniert.
Entwurf
Dienste verarbeiten Geschäftstransaktionen in einer Abfolge über mehrere Sprünge. Jeder Hop teilt einen einzelnen Nachrichtenbus mit allen Geschäftsdiensten.
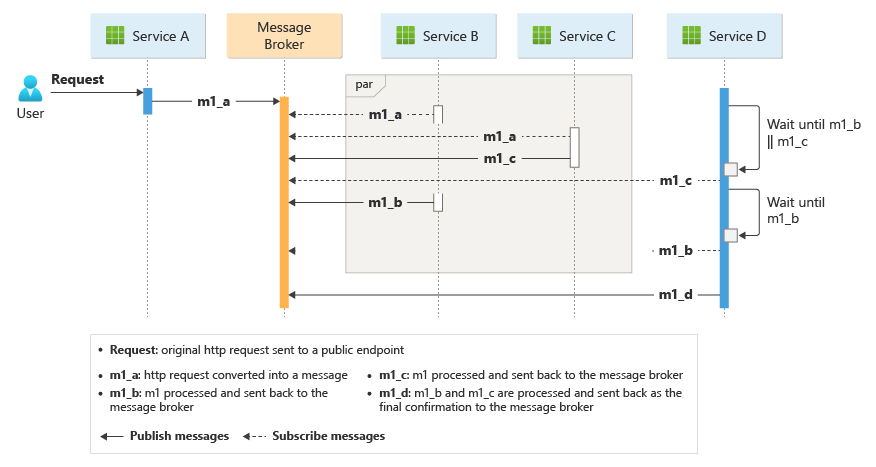
Wenn ein Client eine Übermittlungsanforderung über einen HTTP-Endpunkt sendet, empfängt der Aufnahmedienst sie, konvertiert sie in eine Nachricht und veröffentlicht dann die Nachricht im freigegebenen Nachrichtenbus. Die abonnierten Geschäftsdienste nutzen neue Nachrichten, die dem Bus hinzugefügt wurden. Wenn ein Geschäftsdienst die Nachricht empfängt, wird der Vorgang erfolgreich abgeschlossen, oder die Anforderung schlägt fehl oder bricht aus. Wenn die Anforderung erfolgreich ist, antwortet der Dienst mit dem Statuscode auf den Ok Bus, löst eine neue Vorgangsnachricht aus und sendet sie an den Nachrichtenbus. Wenn die Anforderung fehlschlägt oder eine Zeitüberschreitung auftritt, meldet der Dienst einen Fehler, indem der Fehlercode an den Message Bus gesendet wird und die Nachricht dann einer Dead-Letter-Queue (DLQ) hinzugefügt wird. Der Dienst verschiebt auch Nachrichten, die er innerhalb eines bestimmten Zeitraums nicht empfangen oder verarbeiten kann, in den DLQ.
Dieses Design verwendet mehrere Nachrichtenbusse, um die gesamte Geschäftstransaktion zu verarbeiten. Azure Service Bus und Azure Event Grid bieten die Messagingdienstplattform für dieses Design. Die Workload wird in Azure Container Apps ausgeführt, die Azure-Funktionen für die Aufnahme hosten. Container-Apps behandeln ereignisgesteuerte Verarbeitung, die die Geschäftslogik ausführt.
Dieses Design sorgt auch dafür, dass die Choreographie in einer Sequenz auftritt. Ein einzelner ServiceBus-Namespace enthält ein Thema mit zwei Abonnements und einer sitzungsfähigen Warteschlange. Der Ingestionsdienst publiziert Nachrichten auf dem Thema. Der Paketdienst und der Drohnen-Planer-Service abonnieren das Thema und veröffentlichen Nachrichten, die die Warteschlange über erfolgreiche Anfragen benachrichtigen. Fügen Sie einen allgemeinen Sitzungsbezeichner hinzu, der eine GUID dem Übermittlungsbezeichner zuordnet, sodass Dienste ungebundene Sequenzen verwandter Nachrichten in der Reihenfolge verarbeiten können. Der Zustellungsdienst wartet auf zwei verwandte Nachrichten für jede Transaktion. Die erste Nachricht zeigt an, dass das Paket einsatzbereit ist, und die zweite Nachricht signalisiert, dass eine Drohne geplant ist.
In diesem Design verarbeitet Service Bus hochwertige Nachrichten, die während des gesamten Zustellungsprozesses nicht verloren gehen oder dupliziert werden dürfen. Wenn das Paket versandt wird, wird eine Zustandsänderung im Event Grid veröffentlicht. Der Ereignissender erwartet nicht, wie die Zustandsänderung behandelt wird. Nachgeschaltete Organisationsdienste, die dieses Design nicht enthält, können auf diesen Ereignistyp lauschen und bestimmte Geschäftslogik ausführen, z. B. das Senden einer Bestellstatus-E-Mail an den Benutzer.
Wenn Sie dieses Muster in einem anderen Computedienst wie AKS bereitstellen, können Sie den Publisher-Subscriber Musteranwendungsbaustein mit zwei Containern im selben Pod implementieren. Ein Container führt den Botschafter aus, der mit dem von Ihnen ausgewählten Nachrichtenbus interagiert, während der andere Container die Geschäftslogik ausführt. Dieser Ansatz verbessert die Leistung und Skalierbarkeit. Der Botschafter und der Geschäftsdienst teilen sich dasselbe Netzwerk, wodurch die Latenz reduziert und der Durchsatz erhöht wird.
Um kaskadierende Wiederholungsvorgänge zu vermeiden, die zu mehreren Versuchen führen können, sollten Geschäftsdienste sofort inakzeptable Nachrichten kennzeichnen. Bereichern Sie diese Nachrichten mithilfe gängiger Grundcodes oder eines definierten Anwendungscodes, damit die Dienste sie in einen DLQ verschieben können. Erwägen Sie die Implementierung des Saga-Musters, um Konsistenzprobleme von nachgelagerten Diensten zu verwalten. Ein anderer Dienst behandelt beispielsweise Nachrichten in der Dead-Letter-Queue ausschließlich zu Korrekturzwecken, indem eine Entschädigung, ein Wiederholungsversuch oder eine Pivottransaktion ausgeführt wird.
Die Geschäftsdienste sind idempotent, um sicherzustellen, dass Wiederholungsversuche keine doppelten Ressourcen erstellen. Beispielsweise verwendet der Paketdienst Upsert-Vorgänge, um dem Datenspeicher Daten hinzuzufügen.
Nächste Schritte
Zentralisieren Sie die Ereignisschemaverwaltung mithilfe der Schemaregistrierung in Azure Event Hubs , um die Kompatibilität aufrechtzuerhalten, während Sich Ihre Dienste entwickeln.
Überprüfen Sie die asynchronen Messaging-Optionen in Azure , um mehr über die verschiedenen Infrastrukturoptionen zu erfahren, die für die Implementierung eines dezentralen Workflows verfügbar sind.
Bewerten Sie die technischen Funktionen verschiedener Plattformen, um den richtigen Azure-Messagingdienst für Ihre spezifischen Choreographieanforderungen auszuwählen.
Verwandte Ressourcen
Berücksichtigen Sie diese Muster in Ihrem Design für Choreographie:
Modularisieren Sie den Geschäftsdienst mithilfe des Botschaftermusters.
Implementieren Sie das Queue-Based Load Leveling-Muster, um Spitzen in der Arbeitslast zu bewältigen.
Verwenden Sie asynchron verteilte Nachrichten über das Publisher-Subscriber Muster.
Verwenden Sie Ausgleichstransaktionen , um eine Reihe erfolgreicher Vorgänge rückgängig zu machen, wenn mindestens ein verwandter Vorgang fehlschlägt.