Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server auf Azure-VMs
SQL Server auf Azure-VMs
Ein Windows Server-Failovercluster wird für Hochverfügbarkeit und Notfallwiederherstellung (HADR) mit SQL Server auf Azure Virtual Machines (VMs) verwendet.
Dieser Artikel enthält bewährte Methoden für die Clusterkonfiguration für Failoverclusterinstanzen (FCIs) sowie Verfügbarkeitsgruppen, wenn Sie diese mit SQL Server auf Azure-VMs verwenden.
Weitere Informationen finden Sie in den anderen Artikeln dieser Reihe: Prüfliste, VM-Größe, Speicher, Sicherheit, HADR-Konfiguration und Baseline auswählen.
Checkliste
In der folgenden Prüfliste finden Sie eine kurze Übersicht über die bewährten Methoden zu HADR, die im weiteren Verlauf des Artikels ausführlicher behandelt werden.
HADR-Features (High Availability and Disaster Recovery) wie die AlwaysOn-Verfügbarkeitsgruppe und die Failoverclusterinstanz basieren auf der zugrunde liegenden Windows Server-Failovercluster-Technologie. Sehen Sie sich die bewährten Methoden zum Ändern Ihrer HADR-Einstellungen an, um die Cloudumgebung besser zu unterstützen.
Erwägen Sie für Ihren Windows-Cluster die folgenden bewährten Methoden:
- Stellen Sie Ihre SQL Server-VMs nach Möglichkeit in mehreren Subnetzen bereit, um die Abhängigkeit von einem Azure Load Balancer oder einem verteilten Netzwerknamen (DNN) zur Weiterleitung des Datenverkehrs an Ihre HADR-Lösung zu vermeiden.
- Ändern Sie den Cluster in weniger aggressive Parameter, um unerwartete Ausfälle durch vorübergehende Netzwerkfehler oder Wartung der Azure-Plattform zu vermeiden. Weitere Informationen finden Sie unter Heartbeat- und Schwellenwerteinstellungen. Verwenden Sie für Windows Server 2012 und höher die folgenden empfohlenen Werte:
- SameSubnetDelay: 1 Sekunde
- SameSubnetThreshold: 40 Herzschläge
- CrossSubnetDelay: 1 Sekunde
- CrossSubnetThreshold: 40 Takte
- Platzieren Sie Ihre VMs in einer Verfügbarkeitsgruppe oder verschiedenen Verfügbarkeitszonen. Weitere Informationen finden Sie unter VM-Verfügbarkeitseinstellungen.
- Verwenden Sie eine einzelne NIC pro Clusterknoten.
- Konfigurieren Sie die Clusterquorumabstimmung so, dass eine ungerade Anzahl von mindestens drei Stimmen verwendet wird. Weisen Sie DR-Regionen keine Stimmen zu.
- Überwachen Sie Ressourcengrenzwerte sorgfältig, um unerwartete Neustarts oder Failover aufgrund von Ressourceneinschränkungen zu vermeiden.
- Stellen Sie sicher, dass Betriebssystem, Treiber und SQL Server den neuesten Builds entsprechen.
- Optimieren Sie die Leistung für SQL Server auf Azure-VMs. Weitere Informationen finden Sie in den anderen Abschnitten dieses Artikels.
- Reduzieren oder verteilen Sie die Workload, um Ressourcengrenzwerte zu vermeiden.
- Wechseln Sie zu einem virtuellen Computer oder Datenträger mit höheren Grenzwerten, um Einschränkungen zu vermeiden.
Erwägen Sie für die SQL Server Verfügbarkeitsgruppe oder Failoverclusterinstanz die folgenden bewährten Methoden:
- Wenn häufig unerwartete Fehler auftreten, befolgen Sie die leistungsbezogenen bewährten Methoden, die im restlichen Teil dieses Artikels beschrieben werden.
- Falls sich die unerwarteten Failover durch Optimierung der Leistung der SQL Server-VMs nicht beheben lassen, erwägen Sie eine Lockerung der Überwachung für die Verfügbarkeitsgruppe oder Failoverclusterinstanz. Dadurch wird jedoch möglicherweise nicht die zugrunde liegende Ursache des Problems behoben, und durch Verringerung der Fehlerwahrscheinlichkeit können Symptome maskiert werden. Möglicherweise müssen Sie die zugrunde liegende Ursache dennoch untersuchen und beheben. Verwenden Sie für Windows Server 2012 oder höher die folgenden empfohlenen Werte:
-
Leasetimeout: Verwenden Sie diese Gleichung, um den maximalen Leasetimeoutwert zu berechnen:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Beginnen Sie mit 40 Sekunden. Wenn Sie die zuvor empfohlenen gelockertenSameSubnetThreshold- undSameSubnetDelay-Werte verwenden, darf der Leasetimeoutwert 80 Sekunden nicht überschreiten. - Maximale Fehler in einem angegebenen Zeitraum: Legen Sie diesen Wert auf 6 fest.
-
Leasetimeout: Verwenden Sie diese Gleichung, um den maximalen Leasetimeoutwert zu berechnen:
- Wenn Sie den virtuellen Netzwerknamen (VNN) und einen Azure Load Balancer verwenden, um sich mit Ihrer HADR-Lösung zu verbinden, geben Sie
MultiSubnetFailover = truein der Verbindungszeichenfolge an, auch wenn sich Ihr Cluster nur über ein Subnetz erstreckt.- Wenn der Client
MultiSubnetFailover = Truenicht unterstützt, müssen Sie möglicherweiseRegisterAllProvidersIP = 0undHostRecordTTL = 300festlegen, um Clientanmeldeinformationen für kürzere Zeiträume zwischenzuspeichern. Dies kann jedoch zu zusätzlichen Abfragen an den DNS-Server führen.
- Wenn der Client
- Beim Herstellen einer Verbindung mit der HADR-Lösung mithilfe des Namens des verteilten Netzwerks (Distributed Network Name, DNN) ist Folgendes zu beachten:
- Sie müssen einen Clienttreiber verwenden, der
MultiSubnetFailover = Trueunterstützt, und dieser Parameter muss in der Verbindungszeichenfolge enthalten sein. - Verwenden Sie einen eindeutigen DNN-Port in der Verbindungszeichenfolge, wenn Sie eine Verbindung mit dem DNN-Listener für eine Verfügbarkeitsgruppe herstellen.
- Sie müssen einen Clienttreiber verwenden, der
- Verwenden Sie eine Verbindungszeichenfolge für Datenbankspiegelung für eine Basic-Verfügbarkeitsgruppe, um die Notwendigkeit eines Lastenausgleichs oder DNN zu umgehen.
- Überprüfen Sie die Sektorgröße Ihrer VHDs, bevor Sie Ihre Hochverfügbarkeitslösung bereitstellen, um falsch ausgerichtete E/A-Vorgänge zu vermeiden. Weitere Informationen finden Sie unter KB3009974.
- Wenn die SQL Server-Datenbank-Engine, der Always On-Verfügbarkeitsgruppenlistener oder der Integritätstest der Failoverclusterinstanz so konfiguriert sind, dass ein Port zwischen 49152 und 65536 (der standardmäßige dynamische Portbereich für TCP/IP) verwendet wird, fügen Sie einen Ausschluss für jeden Port hinzu. Dadurch wird verhindert, dass anderen Systemen dynamisch derselbe Port zugewiesen wird. Im folgenden Beispiel wird ein Ausschluss für Port 59999 erstellt:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Informationen zum Vergleichen der HADR-Prüfliste mit den anderen bewährten Methoden finden Sie unter Prüfliste für bewährte Methoden für die Leistung.
VM-Verfügbarkeitseinstellungen
Berücksichtigen Sie die folgenden VM-Einstellungen für die beste Verfügbarkeit, um die Auswirkungen von Ausfallzeiten zu reduzieren:
- Verwenden Sie für die niedrigste Latenz Näherungsplatzierungsgruppen zusammen mit beschleunigtem Netzwerkbetrieb.
- Platzieren Sie Clusterknoten virtueller Computer in separaten Verfügbarkeitszonen, um Schutz vor Ausfällen auf Rechenzentrumsebene zu gewährleisten, oder in einer einzelnen Verfügbarkeitsgruppe, um Redundanz mit niedriger Latenz innerhalb desselben Rechenzentrums zu erreichen.
- Verwenden Sie für VMs in einer Verfügbarkeitsgruppe verwaltete Premium-Datenträger für Betriebssystem und Daten.
- Konfigurieren Sie jede Anwendungsebene in separate Verfügbarkeitsgruppen.
Quorum
Ein Cluster mit zwei Knoten funktioniert zwar ohne eine Quorumressource, Kunden müssen jedoch unbedingt eine Quorumressource verwenden, um Unterstützung für die Produktion zu erhalten. Die Clustervalidierung lässt keinen Cluster ohne Quorumressource zu.
Technisch kann ein Cluster mit drei Knoten den Verlust eines einzelnen Knoten (sodass zwei Knoten übrig sind) ohne Quorumressource überstehen. Sobald der Cluster jedoch auf zwei Knoten heruntergefahren ist, besteht das Risiko, dass bei einem weiteren Knotenverlust oder Kommunikationsfehler die Clusterressourcen offline geschaltet werden, um ein Split-Brain-Szenario zu verhindern. Durch das Konfigurieren einer Quorumressource kann der Cluster mit nur einem Knoten online bleiben.
Der Datenträgerzeuge ist die resilienteste Quorumoption. Um jedoch einen Datenträgerzeugen für SQL Server auf einer Azure-VM zu verwenden, benötigen Sie einen freigegebenen Azure-Datenträger, der der Hochverfügbarkeitslösung einige Einschränkungen auferlegt. Verwenden Sie daher einen Datenträgerzeugen, wenn Sie Ihre Failoverclusterinstanz mit freigegebenen Azure-Datenträgern konfigurieren. Nutzen Sie andernfalls nach Möglichkeit einen Cloudzeugen.
In der folgenden Tabelle sind die für SQL Server auf Azure-VMs verfügbaren Quorumoptionen aufgeführt:
| Cloudzeuge | Datenträgerzeuge | Dateifreigabenzeuge | |
|---|---|---|---|
| Unterstütztes Betriebssystem | Windows Server 2016+ | Alle | Alle |
- Der Cloud Witness eignet sich ideal für Bereitstellungen an mehreren Standorten, in mehreren Zonen und in mehreren Regionen. Nutzen Sie nach Möglichkeit einen Cloudzeugen, es sei denn, Sie haben eine Clusterlösung mit gemeinsam genutztem Speicher.
- Der Datenträgerzeuge ist die resilienteste Quorumoption und wird für Cluster bevorzugt, die freigegebene Azure-Datenträger verwenden (oder eine Lösung für freigegebene Datenträger wie freigegebenes SCSI, iSCSI oder Fibre Channel-SAN). Ein freigegebenes Clustervolume kann nicht als Datenträgerzeuge verwendet werden.
- Der Dateifreigabenzeuge eignet sich für den Zeitpunkt, zu dem der Datenträgerzeuge und der Cloudzeuge nicht verfügbar sind.
Informationen zu den ersten Schritte finden Sie unter Konfigurieren des Clusterquorums.
Quorumabstimmung
Es ist möglich, die Quorumabstimmung (Stimme) eines Knotens zu ändern, der an einem Windows Server-Failovercluster beteiligt ist.
Wenn Sie die Einstellungen für die Knotenabstimmung ändern, befolgen Sie diese Richtlinien:
| Quorum-Abstimmungsrichtlinien |
|---|
| Beginnen Sie damit, dass jeder Knoten standardmäßig keine Stimme besitzt. Jeder Knoten sollte nur über eine Stimme verfügen, wenn es dafür eine explizite Begründung gibt. |
| Aktivieren Sie Stimmen für Clusterknoten, die das primäre Replikat einer Verfügbarkeitsgruppe hosten, oder für die bevorzugten Besitzer einer Failoverclusterinstanz. |
| Aktivieren Sie Stimmen für Besitzer des automatischen Failovers. Jeder Node, der nach einem automatischen Failover zu einem Host eines primären Replikats oder einer FCI werden könnte, sollte eine Stimme haben. |
| Wenn eine Verfügbarkeitsgruppe über mehrere sekundäre Replikate verfügt, aktivieren Sie nur Stimmen für die Replikate, die über ein automatisches Failover verfügen. |
| Deaktivieren Sie die Stimmen für Knoten, die sich an sekundären Standorten für die Notfallwiederherstellung befinden. Knoten an sekundären Standorten sollten nicht zur Entscheidung beitragen, einen Cluster offline zu schalten, wenn mit dem primären Standort alles in Ordnung ist. |
| Sie verfügen über eine ungerade Anzahl von Stimmen mit mindestens drei Quorumstimmen. Fügen Sie bei Bedarf einen Quorumzeugen für eine zusätzliche Stimme in einem Cluster mit zwei Knoten hinzu. |
| Bewerten Sie die Stimmenzuweisungen nach einem Failover neu. Sie möchten kein Failover in eine Clusterkonfiguration ausführen, die kein stabiles Quorum unterstützt. |
Verbindung
Um eine Verbindung zu Ihrem Verfügbarkeitsgruppen-Listener oder Ihrer Failover-Cluster-Instanz wie vor Ort herzustellen, stellen Sie Ihre SQL Server-VMs in mehreren Subnetzen innerhalb desselben virtuellen Netzwerks bereit. Mit mehreren Subnetzen entfällt die zusätzliche Abhängigkeit von einem Azure Load Balancer oder einem verteilten Netzwerknamen, um Ihren Datenverkehr an Ihren Listener zu leiten.
Um Ihre HADR-Lösung zu vereinfachen, sollten Sie Ihre SQL Server-VMs nach Möglichkeit in mehreren Subnetzen einsetzen. Weitere Informationen finden Sie unter Multi-Subnetz AG und Multi-Subnetz FCI.
Wenn sich Ihre SQL Server-VMs in einem einzigen Subnetz befinden, ist es möglich, entweder einen virtuellen Netzwerknamen (VNN) und einen Azure Load Balancer oder einen verteilten Netzwerknamen (DNN) sowohl für Failover-Cluster-Instanzen als auch für Verfügbarkeitsgruppen-Listener zu konfigurieren.
Der Name eines verteilten Netzwerks ist die empfohlene Konnektivitätsoption, falls verfügbar:
- Die End-to-End-Lösung ist stabiler, da Sie die Lastenausgleichsressource nicht mehr pflegen müssen.
- Wenn Sie die Lastenausgleichstests weglassen, wird die Failoverdauer minimiert.
- Der DNN vereinfacht die Bereitstellung und Verwaltung der Failoverclusterinstanz oder des Verfügbarkeitsgruppenlisteners mit SQL Server auf virtuellen Azure-Computern.
Beachten Sie die folgenden Einschränkungen:
- Der Client-Treiber muss den Parameter
MultiSubnetFailover=Trueunterstützen. - Die DNN-Funktion ist ab SQL Server 2016 SP3, SQL Server 2017 CU25 und SQL Server 2019 CU8 auf Windows Server 2016 und höher verfügbar.
Weitere Informationen finden Sie in der Übersicht über Windows Server-Failovercluster.
Informationen zum Konfigurieren der Konnektivität finden Sie in den folgenden Artikeln:
- Verfügbarkeitsgruppe: DNN konfigurieren, VNN konfigurieren
- Failover-Clusterinstanz: Konfigurieren von DNN, Konfigurieren von VNN.
Bei Verwendung des DNN funktionieren die meisten SQL Server-Features transparent mit FCI und Verfügbarkeitsgruppen. Es gibt jedoch bestimmte Features, die ggf. besondere Aufmerksamkeit erfordern. Weitere Informationen finden Sie unter FCI- und DNN-Interoperabilität sowie unter AG- und DNN-Interoperabilität.
Tipp
Legen Sie den Parameter MultiSubnetFailover = true in der Verbindungszeichenfolge fest, auch für HADR-Lösungen, die ein einzelnes Subnetz umfassen, um die künftige Überbrückung von Subnetzen zu unterstützen, ohne die Verbindungszeichenfolgen aktualisieren zu müssen.
Takt und Schwellenwert
Ändern Sie den Clustertakt und die Schwellenwerteinstellungen in gelockerte Einstellungen. Die standardmäßigen Clustereinstellungen für Takt und Schwellenwert sind für hochgradig optimierte lokale Netzwerke konzipiert und berücksichtigen nicht die Möglichkeit einer höheren Latenz in einer Cloudumgebung. Das Heartbeat-Netzwerk wird mit UDP 3343 betrieben, das traditionell weitaus weniger zuverlässig als TCP und anfälliger für unvollständige Übertragungen ist.
Ändern Sie daher beim Ausführen von Clusterknoten für SQL Server auf Azure-VM-Hochverfügbarkeitslösungen die Clustereinstellungen in einen gelockerten Überwachungsstatus, um vorübergehende Ausfälle aufgrund der erhöhten Wahrscheinlichkeit von Netzwerklatenz oder -ausfall, Azure-Wartung oder Ressourcenengpässen zu vermeiden.
Die Einstellungen für Verzögerung und Schwellenwert wirken sich kumulativ auf die gesamte Integritätserkennung aus. Wenn Sie z. B. CrossSubnetDelay so festlegen, dass alle 2 Sekunden ein Herzschlag gesendet wird, und CrossSubnetThreshold auf 10 verpasste Herzschläge, bevor die Wiederherstellung eingeleitet wird, kann der Cluster eine gesamte Netzwerktoleranz von 20 Sekunden haben, bevor die Wiederherstellungsaktion durchgeführt wird. Im Allgemeinen wird bevorzugt, weiterhin häufige Takte zu senden, aber höhere Schwellenwerte zu verwenden.
Um die Wiederherstellung während legitimer Ausfälle zu gewährleisten und gleichzeitig eine größere Toleranz für vorübergehende Probleme zu bieten, lockern Sie ihre Einstellungen für Verzögerung und Schwellenwert auf die empfohlenen Werte, die in der folgenden Tabelle beschrieben werden:
| Einstellung | Windows Server 2012 oder höher | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetVerzögerung | 1 Sekunde | 2 Sekunden |
| Schwellenwert für dasselbe Subnetz | 40 Takte | 10 Herzschläge (max.) |
| "Verzögerung zwischen Subnetzen" | 1 Sekunde | 2 Sekunden |
| CrossSubnet-Schwelle | 40 Takte | 20 Herzschläge (max) |
Verwenden Sie PowerShell, um Ihre Clusterparameter zu ändern:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Verwenden Sie PowerShell, um Ihre Änderungen zu überprüfen:
get-cluster | fl *subnet*
Beachten Sie Folgendes:
- Diese Änderung erfolgt sofort, und es ist kein Neustart des Clusters oder sonstiger Ressourcen erforderlich.
- Subnetzwerte dürfen nicht größer als die gleichen subnetzübergreifenden Werte sein.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
Legen Sie abhängig von Ihrer Anwendung, Ihren Geschäftsanforderungen und Ihrer Umgebung fest, wie viel Ausfallzeit tolerierbar ist, und wieviel Zeit verstreichen soll, bis eine Korrekturmaßnahme erfolgen sollte, und wählen Sie dafür gelockerte Werte aus. Wenn Sie die Standardwerte von Windows Server 2019 nicht überschreiten können, versuchen Sie nach Möglichkeit zumindest, sie zu erreichen:
Als Referenz finden Sie die Standardwerte in der folgenden Tabelle:
| Einstellung | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 – 2012 R2 |
|---|---|---|---|
| SameSubnetVerzögerung | 1 Sekunde | 1 Sekunde | 1 Sekunde |
| Schwellenwert für dasselbe Subnetz | 20 Herzschläge | 10 Herzschläge | 5 Herzschläge |
| "Verzögerung zwischen Subnetzen" | 1 Sekunde | 1 Sekunde | 1 Sekunde |
| CrossSubnet-Schwelle | 20 Herzschläge | 10 Herzschläge | 5 Herzschläge |
Weitere Informationen finden Sie unter Optimieren von Failovercluster-Netzwerkschwellenwerten.
Gelockerte Überwachung
Wenn die empfohlene Optimierung des Clustertakts und der Schwellenwerteinstellungen zu wenig Toleranz aufweist und weiterhin Failovers aufgrund vorübergehender Probleme anstelle echter Ausfälle auftreten, können Sie die Überwachung Ihrer AG oder FCI gelockerter konfigurieren. In einigen Szenarien kann es vorteilhaft sein, die Überwachung je nach Aktivitätsgrad für einen bestimmten Zeitraum vorübergehend zu lockern. Beispielsweise könnten Sie die Überwachung lockern, wenn Sie E/A-intensive Workloads wie Datenbanksicherungen, Indexwartung, DBCC CHECKDB usw. durchführen. Sobald die Aktivität abgeschlossen ist, legen Sie die Überwachung auf weniger gelockerte Werte fest.
Warnung
Das Ändern dieser Einstellungen kann ein zugrunde liegendes Problem maskieren und sollte als temporäre Lösung verwendet werden, um die Wahrscheinlichkeit eines Fehlers zu verringern, anstatt sie zu beseitigen. Zugrunde liegende Probleme sollten weiterhin untersucht und behoben werden.
Erhöhen Sie zunächst die folgenden Parameter von ihren Standardwerten ausgehend für die gelockerte Überwachung, und passen Sie sie nach Bedarf an:
| Parameter | Standardwert | Gelockerter Wert | BESCHREIBUNG |
|---|---|---|---|
| HealthCheck-Timeout | 30.000 | 60000 | Bestimmt die Integrität des primären Replikats oder Knotens. Die Clusterresourcen-DLL sp_server_diagnostics gibt Ergebnisse in einem Intervall zurück, das 1/3 des Schwellenwerts für das Integritätsprüfungstimeout entspricht. Wenn sp_server_diagnostics langsam ist oder keine Informationen zurückgibt, wartet die Ressourcen-DLL das gesamte Intervall des durch den Schwellenwert definierten Integritätsprüfungstimeouts ab, bevor festgestellt wird, dass die Ressource nicht reagiert, und bei entsprechender Konfiguration ein automatisches Failover initiiert wird. |
| Fehlerbedingungsebene | 3 | 2 | Bedingungen, die ein automatisches Failover auslösen. Es gibt fünf Fehlerbedingungsebenen, die von der Ebene mit den wenigsten Einschränkungen (Ebene 1) bis zur Ebene mit den meisten Einschränkungen (Ebene 5) reichen. |
Verwenden Sie Transact-SQL (T-SQL), um die Integritätsprüfungs- und Fehlerbedingungen für AGs und FCIs zu ändern.
Für Verfügbarkeitsgruppen:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
Für Failoverclusterinstanzen:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Spezifisch für Verfügbarkeitsgruppen: Beginnen Sie mit den folgenden empfohlenen Parametern, und passen Sie sie nach Bedarf an:
| Parameter | Standardwert | Gelockerter Wert | BESCHREIBUNG |
|---|---|---|---|
| Timeout für Lease | 20000 | 40.000 | Verhindert Split Brain. |
| Sitzung läuft ab | 10.000 | 20000 | Überprüft Kommunikationsprobleme zwischen Replikaten. Das Sitzungstimeout ist eine Replikateigenschaft, die steuert, wie lange ein Verfügbarkeitsreplikat auf eine Pingantwort von einem verbundenen Replikat wartet, bevor die Verbindung als fehlerhaft betrachtet wird. Standardmäßig wartet ein Replikat 10 Sekunden auf eine Pingantwort. Diese Replikateigenschaft gilt nur für die Verbindung zwischen einem angegebenen sekundären Replikat und dem primären Replikat der Verfügbarkeitsgruppe. |
| Maximale Fehler im angegebenen Zeitraum | 2 | 6 | Wird verwendet, um unbegrenzte Bewegungen einer gruppierten Ressource innerhalb mehrerer Knotenausfälle zu vermeiden. Ein zu niedriger Wert kann dazu führen, dass sich die Verfügbarkeitsgruppe in einem fehlerhaften Zustand befindet. Erhöhen Sie den Wert, um kurze Unterbrechungen aufgrund von Leistungsproblemen zu verhindern, da ein zu niedriger Wert dazu führen kann, dass sich die AG in einem fehlerhaften Zustand befindet. |
Bevor Sie Änderungen vornehmen, sollten Sie Folgendes berücksichtigen:
- Legen Sie keine Timeoutwerte fest, die unterhalb der Standardwerte liegen.
- Verwenden Sie diese Gleichung, um den maximalen Lease-Timeout-Wert zu berechnen:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay)
Beginnen Sie mit 40 Sekunden. Wenn Sie die zuvor empfohlenen gelockertenSameSubnetThreshold- undSameSubnetDelay-Werte verwenden, darf der Leasetimeoutwert 80 Sekunden nicht überschreiten. - Bei Replikaten mit synchronem Commit kann das Ändern des Sitzungstimeouts in einen hohen Wert zu einer Erhöhung der HADR_sync_commit-Wartezeiten führen.
Timeout für Lease
Ändern Sie mit dem Failovercluster-Manager die Leasetimeout-Einstellungen für Ihre Verfügbarkeitsgruppe. Ausführliche Schritte finden Sie in der SQL Server-Dokumentation unter Timeout für Lease.
Sitzung läuft ab
Ändern Sie mit Transact-SQL (T-SQL) das Sitzungstimeout für eine Verfügbarkeitsgruppe:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Maximale Fehler im angegebenen Zeitraum
Ändern Sie mit dem Failovercluster-Manager den Wert von Maximale Fehler im angegebenen Zeitraum:
- Wählen Sie im Navigationsbereich Rollen aus.
- Klicken Sie unter Rollen mit der rechten Maustaste auf die gruppierte Ressource, und wählen Sie Eigenschaften aus.
- Wählen Sie die Registerkarte Failover aus, und erhöhen Sie den Wert Maximale Fehler im angegebenen Zeitraum wie gewünscht.
Ressourceneinschränkungen
Grenzwerte für virtuelle Computer oder Datenträger können zu einem Ressourcenengpass führen, der sich auf die Integrität des Clusters auswirkt und die Integritätsprüfung beeinträchtigt. Wenn Probleme mit Ressourcengrenzwerten auftreten, berücksichtigen Sie Folgendes:
- Verwenden Sie die E/A-Analyse im Azure-Portal, um Datenträgerleistungsprobleme zu identifizieren, die zu einem Failover führen können.
- Stellen Sie sicher, dass Betriebssystem, Treiber und SQL Server den neuesten Builds entsprechen.
- Optimieren Sie SQL Server in der Azure-VM-Umgebung, wie in den Leistungsrichtlinien für SQL Server in Azure Virtual Machines beschrieben.
- Verwendung
- Reduzieren oder verteilen Sie die Workload, um die Auslastung zu reduzieren, ohne Ressourcengrenzwerte zu überschreiten.
- Optimieren Sie nach Möglichkeit die SQL Server-Workload, zum Beispiel
- Fügen Sie Indizes hinzu, bzw. optimieren Sie sie.
- Aktualisieren Sie Statistiken gegebenenfalls und nach Möglichkeit mit vollständigem Scan.
- Verwenden Sie Features wie den Resource Governor (ab SQL Server 2014, nur Enterprise), um die Ressourcenauslastung während bestimmter Workloads wie Sicherungen oder Indexwartung zu begrenzen.
- Wechseln Sie zu einem virtuellen Computer oder Datenträger mit höheren Grenzwerten, um die Anforderungen Ihrer Workload zu erfüllen oder zu überschreiten.
Netzwerk
Stellen Sie Ihre SQL Server-VMs nach Möglichkeit in mehreren Subnetzen bereit, um die Abhängigkeit von einem Azure Load Balancer oder einem verteilten Netzwerknamen (DNN) zur Weiterleitung des Datenverkehrs an Ihre HADR-Lösung zu vermeiden.
Verwenden Sie eine einzelne NIC pro Server (Clusterknoten). Azure-Netzwerktechnologie bietet physische Redundanz, die zusätzliche Netzwerkkarten (NICs) in einem Azure-VM-Gastcluster überflüssig macht. Der Clusterüberprüfungsbericht weist Sie darauf hin, dass die Knoten nur in einem einzigen Netzwerk erreichbar sind. Diese Warnung kann für Azure-VM-Gastfailovercluster ignoriert werden.
Die Bandbreitenlimits für einen bestimmten virtuellen Computer werden von NICs gemeinsam genutzt, und das Hinzufügen einer zusätzlichen NIC verbessert die Verfügbarkeitsgruppenleistung für SQL Server auf virtuellen Azure-Computern nicht. Daher ist es nicht erforderlich, eine zweite NIC hinzuzufügen.
Der nicht RFC-kompatible DHCP-Dienst in Azure kann dazu führen, dass die Erstellung bestimmter Failoverclusterkonfigurationen fehlschlägt. Dieser Fehler tritt auf, weil dem Clusternetzwerknamen eine doppelte IP-Adresse zugewiesen wird, z. B. die gleiche IP-Adresse wie einer der Clusterknoten. Dies stellt bei der Verwendung von Verfügbarkeitsgruppen ein Problem dar, da diese vom Windows-Failoverclusterfeature abhängen.
Beachten Sie folgendes Szenario, wenn ein Cluster mit zwei Knoten erstellt und online geschaltet wird:
- Der Cluster verbindet sich mit dem Netzwerk, und KNOTEN1 fordert eine dynamisch zugewiesene IP-Adresse für den Netzwerknamen des Clusters an.
- Der DHCP-Dienst weist ausschließlich die IP-Adresse von KNOTEN1 zu, da der DHCP-Dienst erkennt, dass die Anforderung von KNOTEN1 selbst stammt.
- Windows erkennt, dass sowohl NODE1 als auch dem Netzwerknamen des Failoverclusters dieselbe IP-Adresse zugewiesen wurde, und die Standardclustergruppe kommt nicht online.
- Die Standardclustergruppe wechselt zu KNOTEN2. KNOTEN2 behandelt die IP-Adresse von KNOTEN1 als Cluster-IP-Adresse und schaltet die Standardclustergruppe online.
- Wenn KNOTEN2 versucht, eine Verbindung mit KNOTEN1 herzustellen, verlassen für KNOTEN1 bestimmten Pakete niemals KNOTEN2, da die IP-Adresse von KNOTEN1 in sich selbst aufgelöst wird. KNOTEN2 kann keine Verbindung mit KNOTEN1 herstellen, verliert daraufhin das Quorum und fährt den Cluster herunter.
- KNOTEN1 kann Pakete an KNOTEN2 senden, aber KNOTEN2 kann nicht antworten. KNOTEN1 verliert das Quorum und fährt den Cluster herunter.
Sie können dieses Szenario vermeiden, indem Sie dem Clusternetzwerknamen eine unbenutzte statische IP-Adresse zuweisen, um den Clusternetzwerknamen online zu bringen und die IP-Adresse zu Azure Load Balancer hinzuzufügen.
Konfigurieren des Probeports
Wenn Sie einen Azure Load Balancer verwenden, um eine VNN-Ressource (Virtual Network Name) zu unterstützen, müssen Sie den Cluster so konfigurieren, dass er auf die Integritätstestanforderungen für Ihren AlwaysOn-Verfügbarkeitsgruppenlistener oder Ihre Failoverclusterinstanz antwortet. Wenn die Integritätssonde keine Antwort von einer Back-End-Instanz erhalten kann, werden keine neuen Verbindungen an diese Back-End-Instanz gesendet, bis die Integritätssonde erneut erfolgreich ist.
Konfigurieren des Portausschlusses
Wenn Sie eine VNN-Ressource (Virtual Network Name) mit einem Azure Load Balancer verwenden, müssen Sie bei Verwendung eines Integritätstestports zwischen 49.152 und 65.536 (dem standardmäßigen dynamischen Portbereich für TCP/IP) den Portausschluss für Ihren AlwaysOn-Verfügbarkeitsgruppenlistener oder Ihre Failoverclusterinstanz konfigurieren.
Das Konfigurieren des Portausschlusses verhindert Ereignisse wie ereignis-ID: 1069 mit Status 10048, die durch einen internen Prozess verursacht werden kann, der den port definierten Port als Probeport verwendet.
Das folgende Beispiel zeigt die Ereignis-ID 1069 mit Status 10048 in den Clusterprotokollen:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status 10048 tritt auf, wenn eine Anwendung versucht, einen Socket an eine IP-Adresse/einen Port zu binden, die bereits für einen vorhandenen Socket verwendet wurde.
Bekannte Probleme
Überprüfen Sie die Lösungen für einige häufig auftretende Probleme und Fehler.
Failover durch Ressourcenkonflikte (insbesondere E/A)
Die Ausschöpfung der E/A- oder CPU-Kapazität für den virtuellen Computer kann zu einem Failover Ihrer Verfügbarkeitsgruppe führen. Die Identifizierung des Konflikts, der direkt vor dem Failover auftritt, ist die zuverlässigste Möglichkeit, die Ursache des automatischen Failovers zu ermitteln.
E/A-Analyse verwenden
Verwenden Sie die E/A-Analyse im Azure-Portal, um Datenträgerleistungsprobleme zu identifizieren, die zu einem Failover führen können.
Überwachen mit VM-Speicher-E/A-Metriken
Überwachen Sie Azure Virtual Machines, um die Metriken für die Speicher-E/A-Auslastung zu untersuchen, um die Wartezeit auf VM- oder Datenträgerebene zu verstehen.
Führen Sie die folgenden Schritte aus, um das Azure-VM-Ereignis „Allgemeine E/A-Erschöpfung“ zu überprüfen:
Navigieren Sie im Azure-Portal zu Ihrer VM, nicht zu den SQL-VMs.
Wählen Sie unter Überwachung die Option Metriken aus, um die Seite Metriken zu öffnen.
Wählen Sie Ortszeit aus, um den gewünschten Zeitraum und die Zeitzone anzugeben, entweder lokal für die VM oder UTC/GMT.
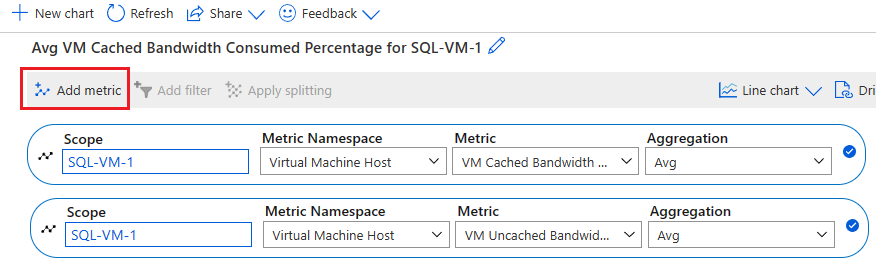
Wählen Sie Metrik hinzufügen aus, um die folgenden beiden Metriken hinzuzufügen, um das Diagramm anzuzeigen:
- Prozentsatz der von der VM beanspruchten zwischengespeicherten Bandbreite
- Prozentsatz der von der VM beanspruchten nicht zwischengespeicherten Bandbreite
Azure VM HostEvent verursacht Failover
Es ist möglich, dass ein Azure VM HostEvent dazu führt, dass Ihre Verfügbarkeitsgruppe ein Failover auslöst. Wenn Sie der Meinung sind, dass ein Azure VM HostEvent ein Failover verursacht hat, können Sie das Azure Monitor-Aktivitätsprotokoll und die Azure-VM-Resource Health-Übersicht überprüfen.
Das Azure Monitor-Aktivitätsprotokoll ist ein Plattformprotokoll in Azure, das einen Einblick in Ereignisse auf Abonnementebene ermöglicht. Es enthält Informationen wie den Zeitpunkt, zu dem eine Ressource geändert oder ein virtueller Computer gestartet wurde. Sie können das Aktivitätsprotokoll im Azure-Portal anzeigen oder Einträge mit PowerShell und der Azure CLI abrufen.
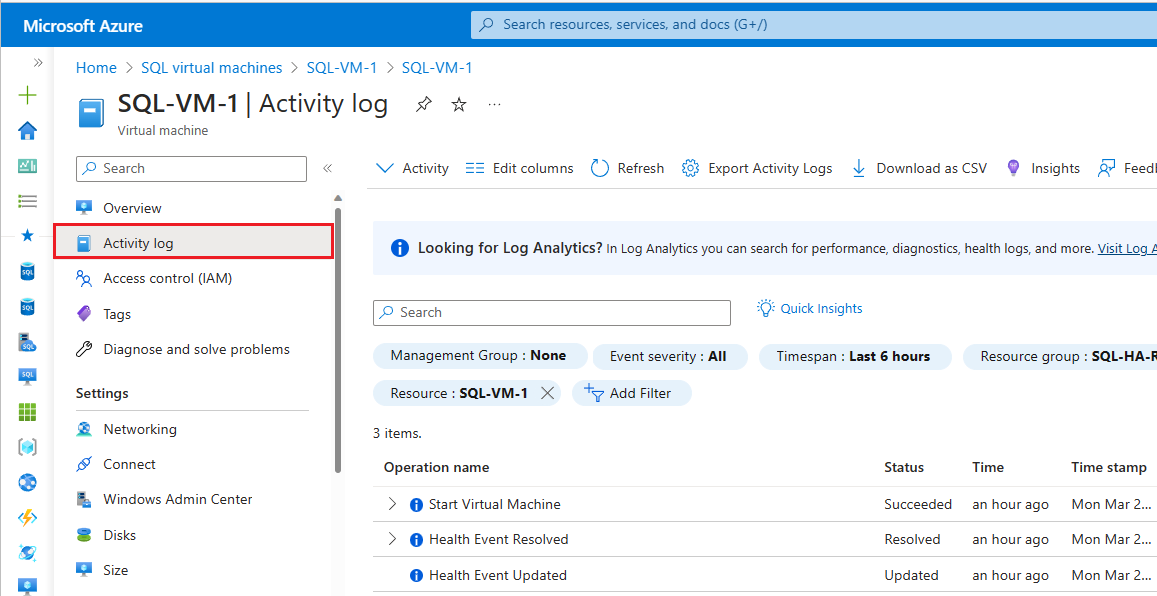
Führen Sie die folgenden Schritte aus, um das Azure Monitor-Aktivitätsprotokoll zu überprüfen:
Navigieren Sie im Azure-Portal zu Ihrem virtuellen Computer.
Wählen Sie das Aktivitätsprotokoll im Fensterbereich „Virtueller Computer“ aus.
Wählen Sie Zeitraum und dann den Zeitraum aus, in dem Ihre Verfügbarkeitsgruppe ein Failover ausgeführt hat. Wählen Sie Übernehmen aus.
Wenn Azure weitere Informationen zur Grundursache einer Nichtverfügbarkeit besitzt, die von der Plattform initiiert wurde, können diese Informationen bis zu 72 Stunden nach der ersten Nichtverfügbarkeit auf der Seite Azure-VM: Resource Health-Übersicht veröffentlicht werden. Diese Informationen sind derzeit nur für virtuelle Computer verfügbar.
- Navigieren Sie im Azure-Portal zu Ihrem virtuellen Computer.
- Wählen Sie im Bereich Ressourcengesundheit die Option Gesundheit aus.
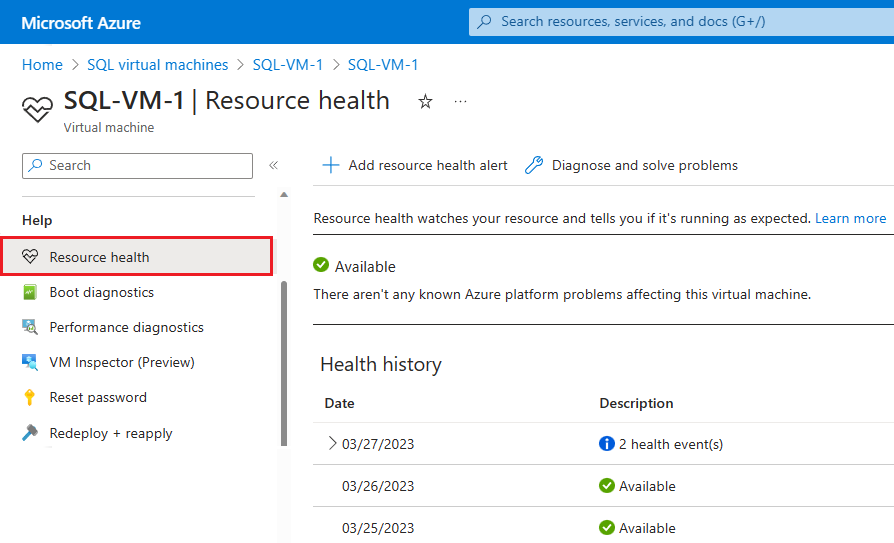
Sie können Warnungen auch basierend auf Gesundheitsereignissen auf dieser Seite konfigurieren.
Clusterknoten aus Mitgliedschaft entfernt
Wenn die Takt- und Schwellenwerteinstellungen für Windows-Cluster für Ihre Umgebung zu aggressiv sind, wird möglicherweise häufig die folgende Meldung im Systemereignisprotokoll angezeigt.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Weitere Informationen finden Sie unter Problembehandlung bei einem Clusterproblem mit Ereignis-ID 1135.
Lease ist abgelaufen/Lease ist nicht mehr gültig
Wenn die Überwachung für Ihre Umgebung zu aggressiv ist, kann es bei der Verfügbarkeitsgruppe oder FCI zu häufigen Neustarts, Fehlern oder Failovern kommen. Darüber hinaus werden für Verfügbarkeitsgruppen möglicherweise die folgenden Meldungen im SQL Server-Fehlerprotokoll angezeigt:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Verbindungstimeout
Wenn das Sitzungstimeout für Ihre Verfügbarkeitsgruppenumgebung zu aggressiv ist, werden möglicherweise häufig folgende Meldungen angezeigt:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
Kein Failover der Gruppe
Wenn der Wert Maximal zulässige Fehler im angegebenen Zeitraum zu niedrig ist und zeitweilige Fehler aufgrund vorübergehender Probleme auftreten, kann Ihre Verfügbarkeitsgruppe in einem fehlerhaften Zustand enden. Erhöhen Sie diesen Wert, um weitere vorübergehende Fehler zu tolerieren.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Ereignis 1196: Für die Netzwerknamenressource konnte der zugeordnete DNS-Name nicht registriert werden.
- Überprüfen Sie jeweils die NIC-Einstellungen für die einzelnen Clusterknoten, um sicherzustellen, dass keine externen DNS-Einträge vorhanden sind.
- Vergewissern Sie sich, dass für Ihren Cluster auf Ihren internen DNS-Servern ein A-Eintrag vorhanden ist. Wenn dies nicht der Fall ist, erstellen Sie auf dem DNS-Server manuell einen A-Eintrag für das Clusterzugriffssteuerungsobjekt und aktivieren Sie die Option, damit authentifizierte Benutzer DNS-Einträge mit demselben Benutzernamen aktualisieren können.
- Versetzen Sie die Ressource „Clustername“ mit der IP-Ressource in den Offlinezustand, und beheben Sie den Fehler.
Ereignis 157: Der Datenträger wurde überraschenderweise entfernt.
Dies kann passieren, wenn die Speicherplätze-Eigenschaft AutomaticClusteringEnabled für eine Verfügbarkeitsgruppenumgebung auf True festgelegt ist. Ändern Sie diesen Wert in False. Die Zurücksetzung des Datenträgers oder das Ereignis für die überraschende Entfernung kann auch durch das Ausführen eines Überprüfungsberichts mit Storage-Option ausgelöst werden. Ein weiterer Grund für die Auslösung des Ereignisses für die überraschende Entfernung des Datenträgers kann zudem die Drosselung des Speichersystems sein.
Ereignis 1206: Die Netzwerknamenressource des Clusters kann nicht in den Onlinezustand versetzt werden.
Das Computerobjekt, das der Ressource zugeordnet ist, konnte in der Domäne nicht aktualisiert werden. Stellen Sie sicher, dass Sie über die richtigen Berechtigungen für die Domäne verfügen.
Windows-Clusteringfehler
Beim Einrichten eines Windows-Failoverclusters oder der zugehörigen Konnektivität treten ggf. Probleme auf, wenn keine Clusterdienstports für die Kommunikation geöffnet sind.
Falls bei Verwendung von Windows Server 2019 keine Windows-Cluster-IP-Adresse angezeigt wird, haben Sie einen Distributed Network Name (DNN) konfiguriert. DNNs werden nur unter SQL Server 2019 unterstützt. Wenn Sie frühere Versionen von SQL Server nutzen, können Sie den Cluster entfernen und mit dem Netzwerknamen neu erstellen.
Weitere Fehler bei Windows-Failoverclusterereignissen und deren Lösungen finden Sie hier.
Nächste Schritte
Weitere Informationen finden Sie unter:
- HADR-Einstellungen für SQL Server auf Azure-VMs
- Windows Server-Failovercluster mit SQL Server auf Azure-VMs
- Always On-Verfügbarkeitsgruppen mit SQL Server auf Azure-VMs
- Windows Server-Failovercluster mit SQL Server auf Azure-VMs
- Failoverclusterinstanzen mit SQL Server auf Azure-VMs
- AlwaysOn-Failoverclusterinstanzen (SQL Server)