Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Important
Dies ist nicht das neueste Java SDK für Azure Cosmos DB! Sie sollten Ihr Projekt auf Azure Cosmos DB Java SDK v4 aktualisieren und dann das Azure Cosmos DB Java SDK v4-Leistungstippshandbuch lesen. Befolgen Sie die Anweisungen im Leitfaden "Migrate to Azure Cosmos DB Java SDK v4 " und " Reactor vs RxJava " zum Upgrade.
Die Leistungstipps in diesem Artikel gelten nur für Azure Cosmos DB Async Java SDK v2. Weitere Informationen finden Sie in den Azure Cosmos DB Async Java SDK v2 Versionshinweisen, dem Maven-Repository und dem Azure Cosmos DB Async Java SDK v2 – Handbuch zur Problembehandlung .
Important
Am 31. August 2024 wird das Azure Cosmos DB Async Java SDK v2.x eingestellt; das SDK und alle Anwendungen, die das SDK verwenden , funktionieren weiterhin; Azure Cosmos DB wird einfach keine weitere Wartung und Unterstützung für dieses SDK bereitstellen. Es wird empfohlen, die obigen Anweisungen zur Migration zum Azure Cosmos DB Java SDK v4 zu befolgen.
Azure Cosmos DB ist eine schnelle und flexible verteilte Datenbank, die nahtlos mit garantierter Latenz und Durchsatz skaliert wird. Die Skalierung Ihrer Datenbank mit Azure Cosmos DB erfordert weder aufwendige Änderungen an der Architektur noch das Schreiben von komplexem Code. Zentrales Hoch- und Herunterskalieren ist ebenso problemlos möglich wie das Aufrufen einer einzelnen API oder SDK-Methode. Da jedoch über Netzwerkaufrufe auf Azure Cosmos DB zugegriffen wird, gibt es clientseitige Optimierungen, die Sie vornehmen können, um Spitzenleistung zu erzielen, wenn Sie das Azure Cosmos DB Async Java SDK v2 verwenden.
Wenn Sie sich also fragen, wie Sie die Leistung Ihrer Datenbank verbessern können, sollten Sie die folgenden Optionen in Betracht ziehen:
Networking
Verbindungsmodus: Verwenden des direkten Modus
Wie ein Client eine Verbindung mit Azure Cosmos DB herstellt, hat wichtige Auswirkungen auf die Leistung, insbesondere hinsichtlich der clientseitigen Latenz. Der ConnectionMode ist eine wichtige Konfigurationseinstellung, die zum Konfigurieren der Clientverbindungsrichtlinie verfügbar ist. Für Azure Cosmos DB Async Java SDK v2 sind die beiden verfügbaren ConnectionModes:
Der Gatewaymodus wird auf allen SDK-Plattformen unterstützt und ist standardmäßig die konfigurierte Option. Wenn Ihre Anwendungen innerhalb eines Unternehmensnetzwerks mit strengen Firewalleinschränkungen ausgeführt werden, ist der Gatewaymodus die beste Wahl, da sie den standardmäßigen HTTPS-Port und einen einzelnen Endpunkt verwendet. Der Leistungsnachteil besteht jedoch darin, dass der Gatewaymodus bei jedem Lesen oder Schreiben von Daten zu Azure Azure Cosmos DB einen zusätzlichen Netwerksprung mit sich bringt. Aus diesem Grund bietet der Direct-Modus aufgrund weniger Netzwerk-Sprünge eine bessere Leistung.
Der ConnectionMode wird während der Erstellung der DocumentClient-Instanz mit dem Parameter ConnectionPolicy konfiguriert.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
public ConnectionPolicy getConnectionPolicy() {
ConnectionPolicy policy = new ConnectionPolicy();
policy.setConnectionMode(ConnectionMode.Direct);
policy.setMaxPoolSize(1000);
return policy;
}
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);
Platzieren der Clients in der gleichen Azure-Region
Platzieren Sie nach Möglichkeit sämtliche Anwendungen, die Azure Cosmos DB aufrufen, in der gleichen Region wie die Azure Cosmos DB-Datenbank. Damit Sie einen ungefähren Vergleich haben: Azure Cosmos DB-Aufrufe aus derselben Region werden normalerweise innerhalb von 1 bis 2 ms abgeschlossen, während die Latenz zwischen West- und Ostküste der USA >50 ms beträgt. Diese Latenz variiert ggf. von Anforderung zu Anforderung und ist abhängig von der Route, die die Anforderung zwischen dem Client und der Grenze des Azure-Datencenters nimmt. Die geringste Latenz erzielen Sie, wenn sich die aufrufende Anwendung in der gleichen Azure-Region wie der bereitgestellte Azure Cosmos DB-Endpunkt befindet. Eine Liste mit den verfügbaren Regionen finden Sie unter Azure-Regionen.
SDK-Verwendung
Installieren des neuesten SDKs
Azure Cosmos DB-SDKs werden ständig verbessert, um eine optimale Leistung zu ermöglichen. Sehen Sie sich die Seiten der Azure Cosmos DB Async Java SDK v2 Versionshinweise an, um das neueste SDK zu ermitteln und die Verbesserungen zu überprüfen.
Verwenden eines Singleton-Azure Cosmos DB-Clients für die Lebensdauer der Anwendung
Jede AsyncDocumentClient-Instanz ist threadsicher und führt effiziente Verbindungsverwaltung und Adresszwischenspeicherung durch. Um eine effiziente Verbindungsverwaltung und eine bessere Leistung durch AsyncDocumentClient zu ermöglichen, empfiehlt es sich, eine einzelne Instanz von AsyncDocumentClient pro AppDomain für die Lebensdauer der Anwendung zu verwenden.
Optimieren von ConnectionPolicy
Standardmäßig werden Azure Cosmos DB-Anforderungen im direkten Modus über TCP vorgenommen, wenn Sie das Azure Cosmos DB Async Java SDK v2 verwenden. Intern verwendet das SDK eine spezielle Direct Mode-Architektur, um Netzwerkressourcen dynamisch zu verwalten und die beste Leistung zu erzielen.
Im Azure Cosmos DB Async Java SDK v2 ist der direct-Modus die beste Wahl, um die Datenbankleistung mit den meisten Workloads zu verbessern.
- Übersicht über den direkten Modus
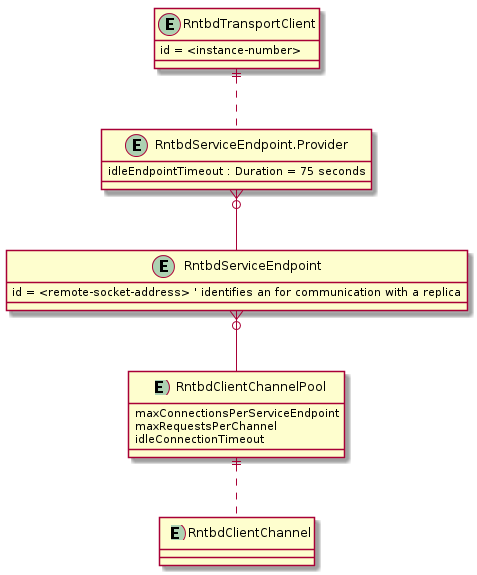
Die clientseitige Architektur, die im Direct-Modus verwendet wird, ermöglicht eine vorhersehbare Netzwerknutzung und einen multiplexen Zugriff auf Azure Cosmos DB Replikate. Das obige Diagramm zeigt, wie Der direkte Modus Clientanforderungen an Replikate im Azure Cosmos DB-Back-End weiter leitet. Die Architektur des direkten Modus weist bis zu 10 Kanäle auf der Clientseite pro DB-Replikat zu. Ein Kanal ist eine TCP-Verbindung, die einem Anforderungspuffer vorausgeht, der 30 Anforderungen tief ist. Die Kanäle, die zu einem Replikat gehören, werden dynamisch nach Bedarf vom Dienstendpunkt des Replikats zugewiesen. Wenn der Benutzer eine Anforderung im direkten Modus ausgibt, leitet der TransportClient die Anforderung basierend auf dem Partitionsschlüssel an den richtigen Dienstendpunkt weiter. Die Anforderungswarteschlange puffert Anforderungen vor dem Dienstendpunkt.
ConnectionPolicy-Konfigurationsoptionen für den direkten Modus
Verwenden Sie im ersten Schritt die folgenden empfohlenen Konfigurationseinstellungen. Wenden Sie sich an das Azure Cosmos DB-Team , wenn Probleme in diesem speziellen Thema auftreten.
Wenn Sie Azure Cosmos DB als Referenzdatenbank verwenden (d. a. die Datenbank wird für viele Lesevorgänge und wenige Schreibvorgänge verwendet), kann es akzeptabel sein, idleEndpointTimeout auf 0 festzulegen (d. a. kein Timeout).
Konfigurationsoption Vorgabe PufferSeitengröße 8192 connectionTimeout „PT1M“ idleChannelTimeout "PT0S" idleEndpointTimeout "PT1M10S" maximale Pufferkapazität 8388608 Maximale Kanäle pro Endpunkt 10 maxRequestsPerChannel 30 receiveHangDetectionTime "PT1M5S" requestExpiryInterval "PT5S" requestTimeout „PT1M“ requestTimerResolution "PT0.5S" sendHangDetectionTime "PT10S" shutdownTimeout "PT15S"
Programmiertipps für den direct-Modus
Lesen Sie den Artikel zur Problembehandlung im Azure Cosmos DB Async Java SDK v2 als Basis für die Lösung von SDK-Problemen.
Einige wichtige Programmiertipps beim Verwenden des direct-Modus:
Verwenden Sie Multithreading in Ihrer Anwendung für eine effiziente TCP-Datenübertragung – Nachdem Sie eine Anforderung gestellt haben, sollte Ihre Anwendung die Daten in einem anderen Thread empfangen. Wenn dies nicht getan wird, erzwingt dies einen unbeabsichtigten "Halbduplex"-Betrieb, und die nachfolgenden Anfragen werden blockiert, während sie auf die Antwort der vorherigen Anforderung warten.
Durchführen von rechenintensiven Workloads auf einem dedizierten Thread – Aus ähnlichen Gründen wie dem vorherigen Tipp werden Vorgänge wie komplexe Datenverarbeitung am besten in einem separaten Thread platziert. Eine Anforderung, die Daten aus einem anderen Datenspeicher abruft (z. B. wenn der Thread Azure Cosmos DB- und Spark-Datenspeicher gleichzeitig verwendet), kann eine erhöhte Latenz auftreten und es wird empfohlen, einen zusätzlichen Thread zu erstellen, der auf eine Antwort aus dem anderen Datenspeicher wartet.
- Das zugrunde liegende Netzwerk-IO im Azure Cosmos DB Async Java SDK v2 wird von Netty verwaltet. Lesen Sie diese Tipps, um Codierungsmuster zu vermeiden, die Netty IO-Threads blockieren.
Datenmodellierung – Die Sla für Azure Cosmos DB geht davon aus, dass die Dokumentgröße kleiner als 1 KB ist. Die Optimierung Ihres Datenmodells und der Programmierung zur Günstigung kleinerer Dokumentgrößen führt in der Regel zu einer verringerten Latenz. Wenn Sie Speicher und Abruf von Dokumenten benötigen, die größer als 1 KB sind, empfiehlt es sich, Dokumente mit Daten in Azure Blob Storage zu verknüpfen.
Optimieren paralleler Abfragen für partitionierte Sammlungen
Azure Cosmos DB Async Java SDK v2 unterstützt parallele Abfragen, mit denen Sie eine partitionierte Sammlung parallel abfragen können. Weitere Informationen finden Sie in Codebeispielen zum Arbeiten mit den SDKs. Parallele Abfragen wurden entwickelt, um die Abfragelatenz und den Durchsatz gegenüber ihrem seriellen Gegenstück zu verbessern.
Anpassen von setMaxDegreeOfParallelism:
Bei parallelen Abfragen werden mehrere Partitionen parallel abgefragt. Daten aus einer einzelnen partitionierten Sammlung werden jedoch in Bezug auf die Abfrage fortlaufend abgerufen. Verwenden Sie also setMaxDegreeOfParallelism, um die Anzahl der Partitionen festzulegen, die die maximale Wahrscheinlichkeit haben, die leistungsstärkste Abfrage zu erreichen, vorausgesetzt, alle anderen Systembedingungen bleiben gleich. Wenn Sie die Anzahl der Partitionen nicht kennen, können Sie setMaxDegreeOfParallelism verwenden, um eine hohe Zahl festzulegen, und das System wählt das Minimum (Anzahl der Partitionen, vom Benutzer bereitgestellte Eingabe) als maximale Parallelität aus.
Es ist wichtig zu beachten, dass parallele Abfragen die besten Vorteile erzielen, wenn die Daten gleichmäßig über alle Partitionen in Bezug auf die Abfrage verteilt werden. Wenn die partitionierte Sammlung so partitioniert ist, dass alle oder die meisten der von einer Abfrage zurückgegebenen Daten in wenigen Partitionen (im schlimmsten Fall in einer einzigen Partition) konzentriert sind, wird die Leistung der Abfrage von diesen Partitionen eingeschränkt.
Optimierung von setMaxBufferedItemCount:
Parallele Abfrage ist für das Vorabfetch von Ergebnissen konzipiert, während der aktuelle Batch der Ergebnisse vom Client verarbeitet wird. Das Vorabrufen hilft bei der allgemeinen Latenzverbesserung einer Abfrage. setMaxBufferedItemCount begrenzt die Anzahl der vorab zurückgegebenen Ergebnisse. Wenn "setMaxBufferedItemCount" auf die erwartete Anzahl der zurückgegebenen Ergebnisse (oder eine höhere Zahl) festgelegt wird, kann die Abfrage den maximalen Nutzen aus dem Vorabruf erhalten.
Das Vorabfetching funktioniert unabhängig vom MaxDegreeOfParallelism auf die gleiche Weise, und es gibt einen einzelnen Puffer für die Daten aus allen Partitionen.
Backoff-Mechanismus in getRetryAfterInMilliseconds-Intervallen implementieren
Während der Leistungstests sollten Sie die Last erhöhen, bis eine kleine Anzahl von Anforderungen gedrosselt wird. Wenn die Clientanwendung gedrosselt wird, sollte sie für das vom Server angegebene Warteintervall zurücktreten. Durch die Einhaltung des Backoffs wird sichergestellt, dass Sie nur minimale Zeit mit Warten zwischen Wiederholungsversuchen verbringen müssen.
Aufskalieren Ihrer Clientworkload
Wenn Sie auf hohen Durchsatzebenen (>50.000 RU/s) testen, kann die Clientanwendung aufgrund der Cpu- oder Netzwerkauslastung des Computers zu einem Engpass werden. Wenn dieser Punkt erreicht wird, können Sie das Azure Cosmos DB-Konto weiter auslasten, indem Sie Ihre Clientanwendungen auf mehrere Server horizontal hochskalieren.
Namensbasierte Adressierung verwenden
Verwenden Sie namensbasierte Adressierung, wobei Links das Format
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentIdanstelle von SelfLinks (_self) aufweisen, die das Formatdbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>aufweisen, um das Abrufen von ResourceIds aller Ressourcen zu vermeiden, die zum Erstellen der Verknüpfung verwendet werden. Da diese Ressourcen neu erstellt werden (möglicherweise mit demselben Namen), hilft das Zwischenspeichern dieser Ressourcen möglicherweise nicht.Optimieren der Seitengröße für Abfragen/Lesefeeds für eine bessere Leistung
Beim Ausführen eines Massenlesevorgangs von Dokumenten mithilfe von Lesefeedfunktionen (z. B. readDocuments) oder beim Ausgeben einer SQL-Abfrage werden die Ergebnisse in segmentierter Weise zurückgegeben, wenn das Resultset zu groß ist. Standardmäßig werden Ergebnisse in Blöcken von 100 Elementen oder 1 MB zurückgegeben, je nachdem, welcher Grenzwert zuerst erreicht wird.
Um die Anzahl von Netzwerk-Roundtrips zu reduzieren, die zum Abrufen aller anwendbaren Ergebnisse erforderlich sind, können Sie die Seitengröße mithilfe des Anforderungsheaders "x-ms-max-item-count " auf bis zu 1000 erhöhen. In Fällen, in denen Nur wenige Ergebnisse angezeigt werden müssen, z. B. wenn Ihre Benutzeroberfläche oder Anwendungs-API nur 10 Ergebnisse pro Zeit zurückgibt, können Sie auch die Seitengröße auf 10 verringern, um den für Lese- und Abfragen verbrauchten Durchsatz zu verringern.
Sie können auch die Seitengröße mithilfe der setMaxItemCount-Methode festlegen.
Verwenden des geeigneten Planers (Vermeiden des Diebstahls von Eventloop-E/A-Threads in Netty)
Das Azure Cosmos DB Async Java SDK v2 verwendet netty für nicht blockierende E/A. Das SDK verwendet eine feste Anzahl (die Anzahl von CPU-Kernen Ihres Computers) von E/A-Eventloop-Threads in Netty zum Ausführen von E/A-Vorgängen. Das von der API zurückgegebene Observable-Objekt gibt das Ergebnis auf einem der freigegebenen E/A-Eventloop-Threads in Netty aus. Daher ist es wichtig, die freigegebenen E/A-Eventloop-Threads in Netty nicht zu blockieren. Das Ausführen von CPU-intensiven Arbeiten oder das Blockieren von Vorgängen im IO-Ereignisschleifen-Netty-Thread kann zu einem Deadlock führen oder den SDK-Durchsatz erheblich verringern.
Der folgende Code führt z. B. eine CPU-intensive Aufgabe auf dem Netty-IO-Thread der Ereignisschleife aus.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribe( resourceResponse -> { //this is executed on eventloop IO netty thread. //the eventloop thread is shared and is meant to return back quickly. // // DON'T do this on eventloop IO netty thread. veryCpuIntensiveWork(); });Wenn Sie nach dem Empfang des Ergebnisses CPU-intensive Arbeiten an diesem ausführen möchten, sollten Sie dies vermeiden, indem Sie den Eventloop-IO-Netty-Thread nicht dafür nutzen. Sie können stattdessen Ihren eigenen Scheduler bereitstellen, um Ihren eigenen Thread für die Ausführung Ihrer Arbeit bereitzustellen.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
import rx.schedulers; Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribeOn(Schedulers.computation()) subscribe( resourceResponse -> { // this is executed on threads provided by Scheduler.computation() // Schedulers.computation() should be used only when: // 1. The work is cpu intensive // 2. You are not doing blocking IO, thread sleep, etc. in this thread against other resources. veryCpuIntensiveWork(); });Basierend auf der Art Ihrer Arbeit sollten Sie den entsprechenden vorhandenen RxJava Scheduler für Ihre Arbeit verwenden. Lesen Sie hier nach:
Schedulers.Weitere Informationen finden Sie auf der GitHub-Seite für Azure Cosmos DB Async Java SDK v2.
Deaktivieren der Netty-Protokollierung
Die Netty-Bibliotheksprotokollierung führt zu übermäßiger Kommunikation und muss deaktiviert werden (das Unterdrücken der Anmeldung in der Konfiguration reicht möglicherweise nicht aus), um zusätzliche CPU-Kosten zu vermeiden. Wenn Sie sich nicht im Debuggingmodus befinden, deaktivieren Sie die Protokollierung von Netty vollständig. Wenn Sie also log4j verwenden, um die zusätzlichen CPU-Kosten zu entfernen, die durch
org.apache.log4j.Category.callAppenders()Netty entstehen, fügen Sie der Codebasis die folgende Zeile hinzu:org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);Ressourcengrenzwert des Betriebssystems für geöffnete Dateien
Einige Linux-Systeme (z. B. Red Hat) haben eine Obergrenze für die Anzahl von offenen Dateien und damit für die Gesamtanzahl von Verbindungen. Führen Sie den folgenden Befehl aus, um die aktuellen Grenzwerte anzuzeigen:
ulimit -aDie Anzahl der geöffneten Dateien (nofile) muss groß genug sein, um genügend Platz für die konfigurierte Größe des Verbindungspools und andere geöffnete Dateien des Betriebssystems zu haben. Sie kann geändert werden, um einen größeren Verbindungspool zu ermöglichen.
Öffnen Sie die Datei „limits.conf“:
vim /etc/security/limits.confÄndern Sie die folgenden Zeilen, bzw. fügen Sie sie hinzu:
* - nofile 100000
Indizierungsrichtlinie
Beschleunigen von Schreibvorgängen durch Ausschließen nicht verwendeter Pfade von der Indizierung
Mit der Indizierungsrichtlinie von Azure Cosmos DB können Sie angeben, welche Dokumentpfade mithilfe der Indizierungspfade (setIncludedPaths und setExcludedPaths) in die Indizierung eingeschlossen bzw. von ihr ausgeschlossen werden sollen. von der Indizierung ausgeschlossen werden sollen. Der folgende Code veranschaulicht beispielsweise, wie ein vollständiger Abschnitt der Dokumente (auch als Unterstruktur bezeichnet) aus der Indizierung mithilfe des "*"-Wildcards ausgeschlossen wird.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Weitere Informationen finden Sie unter Indizierungsrichtlinien für Azure Cosmos DB.
Durchsatz
Messen und Optimieren (Senken) der Anzahl von Anforderungseinheiten pro Sekunde
Azure Cosmos DB bietet vielfältige Datenbankvorgänge (einschließlich relationaler und hierarchischer Abfragen mit UDFs, gespeicherter Prozeduren und Trigger), die alle in den Dokumenten innerhalb einer Datenbanksammlung ausgeführt werden. Die Kosten im Zusammenhang mit diesen Vorgängen variieren basierend auf dem CPU-, E/A- und Speicheraufwand, der für den jeweiligen Vorgang erforderlich ist. Anstelle sich Gedanken über Hardwareressourcen und deren Verwaltung zu machen, können Sie sich eine Anforderungseinheit (RU) als alleinige Maßeinheit für die Ressourcen vorstellen, die für das Durchführen der verschiedenen Datenbankvorgänge und das Ausführen einer Anwendungsanforderung erforderlich sind.
Der Durchsatz wird basierend auf der für jeden Container festgelegten Anzahl von Anforderungseinheiten bereitgestellt. Der Verbrauch von Anforderungseinheiten wird als Rate pro Sekunde bemessen. Anwendungen, die die bereitgestellte Anforderungseinheitenrate für ihre Container überschreiten, werden begrenzt, bis die Rate wieder unter das bereitgestellte Niveau für den Container fällt. Wenn Ihre Anwendung einen höheren Durchsatz erfordert, können Sie ihn durch Bereitstellung zusätzlicher Anforderungseinheiten erhöhen.
Die Komplexität einer Abfrage wirkt sich darauf aus, wie viele Anforderungseinheiten für einen Vorgang verbraucht werden. Die Anzahl von Prädikaten, die Art der Prädikate, die Anzahl von UDFs und die Größe des Quelldatasets beeinflussen die Kosten von Abfragevorgängen.
Untersuchen Sie zum Ermitteln des Indizierungsaufwands für einen beliebigen Vorgang (Erstellen, Aktualisieren oder Löschen) den Header x-ms-request-charge. So ermitteln Sie die Anzahl von Anforderungseinheiten, die von diesen Vorgängen genutzt werden. Sie können sich außerdem die entsprechende RequestCharge-Eigenschaft in ResourceResponse<T> oder FeedResponse<T> ansehen.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
ResourceResponse<Document> response = asyncClient.createDocument(collectionLink, documentDefinition, null, false).toBlocking.single(); response.getRequestCharge();Bei der in diesem Header zurückgegebenen Anforderungsbelastung handelt es sich um einen Bruchteil Ihres bereitgestellten Durchsatzes. Wenn Sie beispielsweise 2000 RU/s bereitgestellt haben und die vorherige Abfrage 1.000 1 KB Dokumente zurückgibt, beträgt die Kosten für den Vorgang 1000. Somit werden vom Server innerhalb einer Sekunde nur zwei solcher Anforderungen berücksichtigt, und für weitere Anforderungen wird die Rate begrenzt. Weitere Informationen finden Sie unter Anforderungseinheiten in DocumentDB sowie unter dem Rechner für Anforderungseinheiten.
Behandeln von Ratenbeschränkungen/zu hohen Anforderungsraten
Wenn ein Client versucht, den für ein Konto reservierten Durchsatz zu überschreiten, wird die Serverleistung nicht beeinträchtigt, und es wird kein über die reservierte Kapazität hinausgehender Durchsatz in Anspruch genommen. Der Server beendet die Anforderung präemptiv mit „RequestRateTooLarge“ (HTTP-Statuscode 429) und gibt den Header x-ms-retry-after-ms zurück. Darin ist die Zeitspanne (in Millisekunden) angegeben, die der Benutzer warten muss, bis ein neuer Anforderungsversuch unternommen werden kann.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100Alle SDKs fangen diese Antwort implizit ab, berücksichtigen den vom Server angegebenen Header vom Typ „retry-after“ und wiederholen die Anforderung. Wenn nicht mehrere Clients gleichzeitig auf Ihr Konto zugreifen, wird die nächste Wiederholung erfolgreich ausgeführt.
Wenn mehr als ein Client kumulativ über der Anforderungsrate arbeitet, reicht die standardmäßige Wiederholungsanzahl, die derzeit vom Client intern auf 9 festgelegt ist, möglicherweise nicht aus. In diesem Fall wird eine DocumentClientException mit dem Statuscode 429 für die Anwendung ausgelöst. Die Standardmäßige Wiederholungsanzahl kann mithilfe von setRetryOptions in der ConnectionPolicy-Instanz geändert werden. Standardmäßig wird die DocumentClientException mit Dem Statuscode 429 nach einer kumulierten Wartezeit von 30 Sekunden zurückgegeben, wenn die Anforderung weiterhin über der Anforderungsrate ausgeführt wird. Dies gilt auch, wenn die aktuelle Wiederholungsanzahl unter der maximalen Wiederholungsanzahl liegt – ganz gleich, ob es sich dabei um den Standardwert (9) oder um einen benutzerdefinierten Wert handelt.
Das automatisierte Wiederholungsverhalten trägt zwar bei den meisten Anwendungen zur Verbesserung der Resilienz und Nutzbarkeit bei, kann bei Leistungsbenchmarks aber auch hinderlich sein (insbesondere beim Ermitteln der Latenz). Die Wartezeit für den Client nimmt stark zu, wenn das Experiment die Serverdrosselung erreicht und damit die automatische Wiederholung durch das Client-SDK auslöst. Ermitteln Sie zur Vermeidung von Latenzspitzenwerten bei Leistungsexperimenten die von den einzelnen Vorgängen zurückgegebene Belastung, und stellen Sie sicher, dass die Anforderungen die reservierte Anforderungsrate nicht überschreiten. Weitere Informationen finden Sie unter Anforderungseinheiten in DocumentDB.
Konzipieren für kleinere Dokumente und höheren Durchsatz
Die Anforderungsbelastung (die Kosten für die Anforderungsverarbeitung) eines Vorgangs hängt direkt mit der Größe des Dokuments zusammen. Vorgänge für große Dokumente sind teurer als Vorgänge für kleine Dateien.
Nächste Schritte
Weitere Informationen zum Entwerfen einer auf Skalierung und hohe Leistung ausgelegten Anwendung finden Sie unter Partitionieren und Skalieren in Azure Cosmos DB.