Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: ![]() NoSQL
NoSQL
Wichtig
Die Leistungstipps in diesem Artikel gelten ausschließlich für das Azure Cosmos DB Java SDK v4. Weitere Informationen finden Sie in den Versionshinweisen zum Azure Cosmos DB Java SDK v4, im Maven-Repository und im Leitfaden zur Problembehandlung für das Azure Cosmos DB Java SDK v4. Wenn Sie aktuell eine ältere Version als v4 verwenden, lesen Sie den Leitfaden Migrieren zum Azure Cosmos DB Java SDK v4, um Hilfe beim Upgrade auf v4 zu erhalten.
Azure Cosmos DB ist eine schnelle und flexible verteilte Datenbank mit nahtloser Skalierung, garantierter Latenz und garantiertem Durchsatz. Die Skalierung Ihrer Datenbank mit Azure Cosmos DB erfordert weder aufwendige Änderungen an der Architektur noch das Schreiben von komplexem Code. Zentrales Hoch- und Herunterskalieren ist ebenso problemlos möglich wie das Aufrufen einer einzelnen API oder SDK-Methode. Da der Zugriff auf Azure Cosmos DB jedoch über Netzwerkaufrufe erfolgt, können Sie bei der Verwendung des Azure Cosmos DB Java SDK v4 clientseitige Optimierungen vornehmen, um eine optimale Leistung zu erzielen.
Wenn Sie sich also fragen, wie Sie die Leistung Ihrer Datenbank verbessern können, sollten Sie die folgenden Optionen in Betracht ziehen:
Netzwerk
Platzieren Sie Clients in derselben Azure-Region, um die Leistung zu verbessern.
Platzieren Sie nach Möglichkeit sämtliche Anwendungen, die Azure Cosmos DB aufrufen, in der gleichen Region wie die Azure Cosmos DB-Datenbank. Damit Sie einen ungefähren Vergleich haben: Azure Cosmos DB-Aufrufe aus derselben Region werden normalerweise innerhalb von 1 bis 2 ms abgeschlossen, während die Latenz zwischen West- und Ostküste der USA >50 ms beträgt. Diese Latenz variiert ggf. von Anforderung zu Anforderung und ist abhängig von der Route, die die Anforderung zwischen dem Client und der Grenze des Azure-Datencenters nimmt. Die geringste Latenz erzielen Sie, wenn sich die aufrufende Anwendung in der gleichen Azure-Region wie der bereitgestellte Azure Cosmos DB-Endpunkt befindet. Eine Liste mit den verfügbaren Regionen finden Sie unter Azure-Regionen.
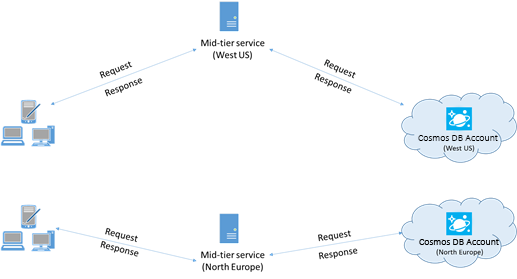
Eine App, die mit einem Azure Cosmos DB-Konto in mehreren Regionen interagiert, muss bevorzugte Regionen konfigurieren, um sicherzustellen, dass Anforderungen in eine angegebene Region weitergeleitet werden.
Aktivieren des beschleunigten Netzwerkbetriebs zur Verringerung von Latenz und CPU-Jitter
Wir empfehlen dringend, die Anweisungen zum Aktivieren des beschleunigten Netzwerkbetriebs in Ihrer Azure-VM unter Windows oder Linux (für Anweisungen jeweils auswählen) zu befolgen, um die Leistung durch Reduktion von Wartezeit und CPU-Jitter zu reduzieren.
Ohne den beschleunigten Netzwerkbetrieb könnten E/A-Vorgänge zwischen Ihrer Azure-VM und anderen Azure-Ressourcen über einen Host und einen virtuellen Switch zwischen der VM und dessen Netzwerkkarte geroutet werden. Wenn sich der Host und der virtuelle Switch inline auf dem Datenpfad befinden, sorgt dies beim Kommunikationskanal nicht nur für eine längere Wartezeit und Jitter, sondern auch die CPU-Zyklen von der VM werden reduziert. Mit beschleunigtem Netzwerkbetrieb kommuniziert die VM direkt mit der Netzwerkkarte, ohne Zwischenstationen. Alle Netzwerkrichtliniendetails werden in der Hardware an der NIC behandelt, unter Umgehung des Hosts und des virtuellen Switches. Im Allgemeinen sind eine kürzere und konsistentere Wartezeit, ein höherer Durchsatz und eine geringere CPU-Auslastung zu erwarten, wenn Sie den beschleunigten Netzwerkbetrieb aktivieren.
Einschränkungen: Der beschleunigte Netzwerkbetrieb muss vom Betriebssystem der VM unterstützt werden und kann nur aktiviert werden, wenn die VM beendet und ihre Zuordnung aufgehoben wurde. Die VM kann nicht mit Azure Resource Manager bereitgestellt werden. In App Service ist der beschleunigte Netzwerkbetrieb nicht aktiviert.
Weitere Informationen finden Sie in den Windows- und Linux-Anweisungen.
Hochverfügbarkeit
Allgemeine Anleitungen zum Konfigurieren von Hochverfügbarkeit in Azure Cosmos DB finden Sie unter Hochverfügbarkeit in Azure Cosmos DB.
Neben einer guten grundlegenden Einrichtung in der Datenbankplattform gibt es spezielle Techniken, die im Java SDK selbst implementiert werden können, was für Ausfallszenarios hilfreich sein kann. Zwei wichtige Strategien sind die schwellenwertbasierte Verfügbarkeitsstrategie und der Trennschalter auf Partitionsebene.
Diese Techniken bieten erweiterte Mechanismen zur Behebung bestimmter Latenz- und Verfügbarkeitsprobleme, die über die regionsübergreifenden Wiederholungsfunktionen hinausgehen, die standardmäßig in das SDK integriert sind. Durch die proaktive Verwaltung potenzieller Probleme auf Anforderungs- und Partitionsebenen können diese Strategien die Resilienz und Leistung Ihrer Anwendung erheblich verbessern, insbesondere unter Bedingungen mit hoher Auslastung oder Beeinträchtigungen.
Schwellenwertbasierte Verfügbarkeitsstrategie
Die schwellenwertbasierte Verfügbarkeitsstrategie kann die Taillatenz und Verfügbarkeit verbessern, indem parallele Leseanforderungen an sekundäre Regionen gesendet und die schnellste Antwort akzeptiert wird. Dieser Ansatz kann die Auswirkungen regionaler Ausfälle oder hoher Latenzbedingungen auf die Anwendungsleistung drastisch reduzieren. Darüber hinaus kann die proaktive Verbindungsverwaltung eingesetzt werden, um die Leistung weiter zu verbessern, indem Verbindungen und Zwischenspeicher sowohl in der aktuellen Leseregion als auch in bevorzugten Remote-Regionen aufgewärmt werden.
Beispielkonfiguration:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Funktionsweise:
Ursprüngliche Anforderung: Derzeit wird T1, eine Leseanforderung, an die primäre Region (z. B. USA, Osten) gestellt. Das SDK wartet bis zu 500 Millisekunden auf eine Antwort (der
threshold-Wert).Zweite Anforderung: Wenn innerhalb von 500 Millisekunden keine Antwort aus der primären Region vorhanden ist, wird eine parallele Anforderung an die nächste bevorzugte Region gesendet (z. B. USA, Osten 2).
Dritte Anforderung: Wenn weder die primäre noch die sekundäre Region innerhalb von 600 Millisekunden antwortet (500 ms + 100 ms, der
thresholdStep-Wert), sendet das SDK eine weitere parallele Anforderung an die dritte bevorzugte Region (z. B. USA, Westen).Schnellste Antwort gewinnt: Gewonnen hat die Region, die zuerst antwortet und diese Antwort akzeptiert wird. Die anderen parallelen Anforderungen werden ignoriert.
Die proaktive Verbindungsverwaltung hilft dabei, Verbindungen und Zwischenspeicher für Container in den bevorzugten Regionen aufzuwärmen und so die Kaltstartwartezeit für Failoverszenarien oder Schreibvorgänge in Setups in mehreren Regionen zu reduzieren.
Diese Strategie kann die Latenz in Szenarios erheblich verbessern, in denen eine bestimmte Region langsam oder vorübergehend nicht verfügbar ist. Jedoch können mehr Kosten in Bezug auf Anforderungseinheiten entstehen, wenn parallele regionsübergreifende Anforderungen erforderlich sind.
Hinweis
Wenn der erste bevorzugte Bereich einen nicht vorübergehenden Fehlerstatuscode zurückgibt (z. B. Dokument nicht gefunden, Autorisierungsfehler, Konflikt usw.), schlägt der Vorgang selbst schnell fehl, da die Verfügbarkeitsstrategie in diesem Szenario keinen Vorteil hätte.
Trennschalter auf Partitionsebene
Der Trennschalter auf Partitionsebene verbessert die Latenz und die Schreibverfügbarkeit durch Nachverfolgen und Kurzschließen von Anforderungen an fehlerhafte physische Partitionen. Dadurch wird die Leistung verbessert, indem bekannte problematische Partitionen vermieden und Anforderungen an fehlerfreiere Regionen umgeleitet werden.
Beispielkonfiguration:
So aktivieren Sie den Trennschalter auf Partitionsebene:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
So legen Sie die Häufigkeit des Hintergrundprozesses für die Überprüfung nicht verfügbarer Regionen fest:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
So legen Sie die Dauer fest, für die eine Partition nicht verfügbar bleiben kann:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Funktionsweise:
Nachverfolgungsfehler: Das SDK verfolgt Terminalfehler (z. B. 503 s, 500 s, Zeitüberschreitungen) für einzelne Partitionen in bestimmten Regionen.
Kennzeichnung als „Nicht verfügbar“: Wenn eine Partition in einem Bereich einen konfigurierten Fehlerschwellenwert überschreitet, wird sie als „Nicht verfügbar“ markiert. Nachfolgende Anforderungen an diese Partition werden kurzgeschlossen und an andere fehlerfreiere Regionen umgeleitet.
Automatisierte Wiederherstellung: Ein Hintergrundthread überprüft regelmäßig nicht verfügbare Partitionen. Nach einer bestimmten Dauer werden diese Partitionen mit Vorbehalt als „HealthyTentative“ gekennzeichnet und Testanforderungen zur Überprüfung der Wiederherstellung unterzogen.
Integritätshöherstufung/-herabstufung: Basierend auf dem Erfolg oder Fehler dieser Testanforderungen wird der Status der Partition entweder wieder auf „Fehlerfrei“ heraufgestuft oder erneut auf „Nicht verfügbar“ herabgestuft.
Dieser Mechanismus hilft dabei, die Partitionsintegrität kontinuierlich zu überwachen und sicherzustellen, dass Anforderungen mit minimaler Latenz und maximaler Verfügbarkeit bereitgestellt werden, ohne durch problematische Partitionen eingeschränkt zu werden.
Hinweis
Der Trennschalter gilt nur für Schreibkonten mit mehreren Regionen, da sowohl Lese- als auch Schreibvorgänge in die nächste bevorzugte Region verschoben werden, sobald eine Partition als Unavailable gekennzeichnet ist. Dies soll verhindern, dass Lese- und Schreibvorgänge aus verschiedenen Regionen von derselben Clientinstanz bereitgestellt werden, da dies ein Antimuster wäre.
Wichtig
Sie müssen Version 4.63.0 des Java SDK oder höher verwenden, um die Trennschalter für Partitionsebenen zu aktivieren.
Vergleich der Verfügbarkeitsoptimierungen
Schwellenwertbasierte Verfügbarkeitsstrategie:
- Vorteil: Reduziert die Taillatenz, indem parallele Leseanforderungen an sekundäre Regionen gesendet werden, und erhöht die Verfügbarkeit, indem Anforderungen, die zu Netzwerktimeouts führen, vorgezogen werden.
- Nachteil:: Verursacht zusätzliche RU-Kosten (Request Units, Anforderungseinheiten) im Vergleich zu Trennschaltern aufgrund zusätzlicher paralleler regionsübergreifender Anforderungen (jedoch nur während Zeiträumen, in denen Schwellenwerte überschritten werden).
- Anwendungsfall: Optimal für leseintensive Workloads, bei denen die Reduzierung der Latenz kritisch ist und einige zusätzliche Kosten (sowohl hinsichtlich der RU-Gebühr als auch des Client-CPU-Drucks) akzeptabel sind. Schreibvorgänge können auch von Vorteil sein, wenn sie für nicht-idempotente Schreibwiederholungsrichtlinien gelten und das für das Konto mehrere Regionen schreibgeschützt sind.
Trennschalter auf Partitionsebene:
- Vorteil: Verbessert die Verfügbarkeit und Latenz, indem fehlerhafte Partitionen vermieden werden, um sicherzustellen, dass Anforderungen an fehlerfreiere Regionen weitergeleitet werden
- Nachteil: Verursacht keine zusätzlichen RU-Kosten, kann aber dennoch einen gewissen anfänglichen Verfügbarkeitsverlust für Anforderungen zulassen, die zu Netzwerktimeouts führen.
- Anwendungsfall: Ideal für Workloads mit vielen Schreibvorgängen oder gemischten Workloads, bei denen eine konsistente Leistung unerlässlich ist, insbesondere beim Umgang mit Partitionen, die zeitweise fehlerhaft werden können
Beide Strategien können zusammen verwendet werden, um die Lese- und Schreibverfügbarkeit zu verbessern und die Taillatenz zu reduzieren. Der Trennschalter auf Partitionsebene kann eine Vielzahl vorübergehender Fehler verarbeiten, einschließlich solcher, die zu langsamen Replikaten führen können, ohne dass parallele Anforderungen ausgeführt werden müssen. Darüber hinaus wird durch das Hinzufügen einer schwellenwertbasierten Verfügbarkeitsstrategie die Taillatenz weiter minimiert und der Verfügbarkeitsverlust beseitigt, wenn zusätzliche RU-Kosten akzeptabel sind.
Durch die Implementierung dieser Strategien können Entwickler sicherstellen, dass ihre Anwendungen resilient bleiben, die Hochleistung beibehalten und ein besseres Benutzererlebnis auch bei regionalen Ausfällen oder Bedingungen mit hoher Latenz bieten.
Regionale Sitzungskonsistenz
Übersicht
Weitere Informationen zu Konsistenzeinstellungen im Allgemeinen finden Sie unter Konsistenzebenen in Azure Cosmos DB. Das Java SDK bietet eine Optimierung für Sitzungskonsistenz für Schreibkonten mit mehreren Regionen, indem es die Möglichkeit bietet, bereichsbezogene Konten zu verwenden. Dadurch wird die Leistung verbessert, indem die latenzübergreifende Replikation durch Minimierung clientseitiger Wiederholungsversuche verringert wird. Dies wird durch die Verwaltung von Sitzungstoken auf Regionsebene statt global erreicht. Wenn die Konsistenz in Ihrer Anwendung auf eine kleinere Anzahl von Regionen ausgerichtet werden kann, können Sie durch die Implementierung der regionalen Sitzungskonsistenz eine bessere Leistung und Zuverlässigkeit für Lese- und Schreibvorgänge in Multi-Write-Konten erzielen, indem Sie regionale Replikationsverzögerungen und Wiederholungen minimieren.
Vorteile
- Reduzierte Latenz: Durch die Lokalisierung der Sitzungstokenüberprüfung auf Regionsebene werden die Chancen auf teure kontenübergreifende Wiederholungen reduziert.
- Verbesserte Leistung: Minimiert die Auswirkungen der regionalen Failover- und Replikationsverzögerung und bietet höhere Lese-/Schreibkonsistenz und eine geringere CPU-Auslastung
- Optimierte Ressourcenauslastung: Reduziert CPU- und Netzwerkaufwand für Clientanwendungen, indem die Notwendigkeit von Wiederholungen und regionsübergreifenden Aufrufen eingeschränkt wird, wodurch die Ressourcennutzung optimiert wird
- Hohe Verfügbarkeit: Durch die Verwaltung von bereichsbezogenen Sitzungstoken können Anwendungen weiterhin reibungslos funktionieren, auch wenn bestimmte Regionen eine höhere Latenz oder temporäre Fehler aufweisen.
- Konsistenzgarantien: Stellt sicher, dass die Sitzungskonsistenzgarantien (Lesen eigener Schreibvorgänge, monotones Lesen) zuverlässiger und ohne unnötige Wiederholungen erfüllt werden
- Kosteneffizienz: Reduziert die Anzahl der regionsübergreifenden Aufrufe, wodurch die Kosten für Datenübertragungen zwischen Regionen potenziell gesenkt werden
- Skalierbarkeit: Ermöglicht es Anwendungen, effizienter zu skalieren, indem der mit einem globalen Sitzungstoken verbundene Konflikt und Mehraufwand reduziert wird, insbesondere in Setups mit mehreren Regionen
Nachteile
- Erhöhte Speicherauslastung: Der Bloom-Filter und der regionale Sitzungstokenspeicher erfordern zusätzlichen Arbeitsspeicher, was für Anwendungen mit begrenzten Ressourcen eine Rolle spielen kann.
- Konfigurationskomplexität: Mit der Feinabstimmung der erwarteten Anzahl von Einfügungen und der Rate der falsch positiven Ergebnissen für den Bloom-Filter wird dem Konfigurationsprozess eine Komplexitätsebene hinzugefügt.
- Potenzial für falsch positive Ergebnisse: Während der Bloom-Filter regionsübergreifende Wiederholungen minimiert, besteht immer noch eine geringe Wahrscheinlichkeit falsch positiver Ergebnisse, die sich auf die Überprüfung des Sitzungstokens auswirken, obwohl die Rate gesteuert werden kann. Ein falsch positives Ergebnis bedeutet, dass das globale Sitzungstoken aufgelöst wird, wodurch die Wahrscheinlichkeit von regionsübergreifenden Wiederholungen erhöht wird, wenn die lokale Region diese globale Sitzung nicht erfasst hat. Die Sitzungsgarantien werden sogar bei Vorhandensein falsch positiver Ergebnisse erfüllt.
- Anwendbarkeit: Dieses Feature ist für Anwendungen mit einer hohen Kardinalität logischer Partitionen und regelmäßigen Neustarts am besten geeignet. Anwendungen mit weniger logischen Partitionen oder seltenen Neustarts sehen möglicherweise keine erheblichen Vorteile.
Funktionsweise
Festlegen des Sitzungstokens
- Anforderungsabschluss: Nach Abschluss einer Anforderung erfasst das SDK das Sitzungstoken und ordnet es dem Regions- und Partitionsschlüssel zu.
- Speicher auf Regionsebene: Sitzungstoken werden in einer geschachtelten
ConcurrentHashMapgespeichert, die Zuordnungen zwischen Partitionsschlüsselbereichen und dem Fortschritt auf Regionsebene verwaltet. - Bloom-Filter: Ein Bloom-Filter verfolgt, welche Regionen von jeder logischen Partition aufgerufen wurden, was die Lokalisierung der Überprüfung von Sitzungstoken vereinfacht.
Auflösen des Sitzungstokens
- Anforderungsinitialisierung: Bevor eine Anforderung gesendet wird, versucht das SDK, das Sitzungstoken für die entsprechende Region aufzulösen.
- Tokenüberprüfung: Das Token wird anhand der regionsspezifischen Daten überprüft, um sicherzustellen, dass die Anforderung an das aktuellste Replikat weitergeleitet wird.
- Wiederholungslogik: Wenn das Sitzungstoken nicht innerhalb der aktuellen Region überprüft wird, wiederholt das SDK den Vorgang mit anderen Regionen, aber angesichts des lokalisierten Speichers wird dies weniger häufig durchgeführt.
Verwenden des SDK
So initialisieren Sie den CosmosClient mit regionaler Sitzungskonsistenz:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Aktivieren der regionalen Sitzungskonsistenz
Legen Sie die folgende Systemeigenschaft fest, um die Erfassung der bereichsbezogenen Sitzung in Ihrer Anwendung zu aktivieren:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Konfigurieren des Bloom-Filters
Optimieren Sie die Leistung, indem Sie die erwarteten Einfügungen und die Rate der falsch positiven Ergebnisse für den Bloom-Filter konfigurieren:
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Speicherauswirkungen
Unten sehen Sie die beibehaltene Größe (Größe des Objekts und worauf es sich bezieht) vom internen Sitzungscontainer (verwaltet vom SDK) mit unterschiedlichen erwarteten Einfügungen in den Bloom-Filter.
| Erwartete Einfügungen | False Positive Rate | Beibehaltene Größe |
|---|---|---|
| 10.000 | 0.001 | 21 KB |
| 100.000 | 0.001 | 183 KB |
| 1 Mio. | 0.001 | 1,8 MB |
| 10 Millionen | 0.001 | 17,9 MB |
| 100 Mio. | 0.001 | 179 MB |
| 1 Mrd. | 0.001 | 1,8 GB |
Wichtig
Sie müssen Version 4.60.0 des Java SDK oder höher verwenden, um die regionale Sitzungskonsistenz zu aktivieren.
Optimieren der Konfiguration für direkte Verbindungen und Gatewayverbindungen
Informationen zur Optimierung von Verbindungskonfigurationen für den direkten Modus und den Gatewaymodus finden Sie unter Optimieren von Verbindungskonfigurationen für Java SDK v4.
SDK-Verwendung
- Installieren des neuesten SDKs
Azure Cosmos DB-SDKs werden ständig verbessert, um eine optimale Leistung zu ermöglichen. Informationen zu den neuesten SDK-Verbesserungen finden Sie unter Azure Cosmos DB-SDK.
Jede Azure Cosmos DB-Clientinstanz ist threadsicher und verfügt über eine effiziente Verbindungsverwaltung und Adressenzwischenspeicherung. Wir empfehlen dringend, für die gesamte Lebensdauer der Anwendung nur eine einzelne Instanz des Azure Cosmos DB-Clients zu verwenden, um eine effiziente Verbindungsverwaltung und bessere Leistung des Azure Cosmos DB-Clients zu ermöglichen.
Wenn Sie eine CosmosClient-Klasse erstellen, wird Sitzung als Standardkonsistenz festgelegt, falls keine andere explizite Angabe gemacht wird. Wenn die Konsistenz Sitzung für Ihre Anwendungslogik nicht erforderlich ist, legen Sie die Konsistenz auf Letztlich fest. Hinweis: Es wird empfohlen, mindestens die Konsistenz auf Ebene Sitzung bei Anwendungen zu verwenden, die den Azure Cosmos DB-Änderungsfeedprozessor einsetzen.
- Verwenden der Async-API zum Ausschöpfen des bereitgestellten Durchsatzes
Das Azure Cosmos DB Java SDK v4 bündelt die APIs „Sync“ und „Async“. Grob gesagt implementiert die Async-API SDK-Funktionen, während die Sync-API ein einfacher Wrapper ist, der blockierende Aufrufe der Async-API durchführt. Dies steht im Kontrast zum älteren asynchronen Azure Cosmos DB-Java SDK v2, das nur asynchron war, und dem älteren synchronen Azure Cosmos DB-Java SDK v2, das nur synchron war und eine separate Implementierung erforderte.
Die Auswahl der API wird während der Clientinitialisierung getroffen. Eine CosmosAsyncClient-Klasse unterstützt die Async-API, während die CosmosClient-Klasse die Sync-API unterstützt.
Die Async-API implementiert nicht blockierende E/A-Vorgänge und ist die beste Wahl, wenn Sie den Durchsatz beim Ausgeben von Anforderungen an Azure Cosmos DB voll ausschöpfen möchten.
Die Verwendung der Sync-API kann die richtige Wahl sein, wenn Sie eine API benötigen, welche die Antwort auf jede Anforderung blockiert, oder wenn der synchrone Betrieb das dominierende Paradigma in Ihrer Anwendung ist. Sie verwenden beispielsweise die Sync-API, wenn Sie Daten für Azure Cosmos DB in einer Microserviceanwendung beibehalten und der Durchsatz nicht entscheidend ist.
Beachten Sie, dass der Durchsatz der Sync-API mit zunehmender Anforderungsantwortzeit abnimmt, während die Async-API die volle Bandbreite Ihrer Hardware ausschöpfen kann.
Bei Verwendung der Sync-API ermöglicht eine geografische Kollokation einen höheren und konsistenteren Durchsatz (siehe Bereitstellen von Clients in derselben Azure-Region für eine bessere Leistung), der Durchsatz der Async-API wird jedoch nicht erreicht.
Einige Benutzer*innen sind möglicherweise auch nicht mit Project Reactor vertraut. Dabei handelt es sich um das Reactive Streams-Framework, das zum Implementieren der Async-API des Azure Cosmos DB Java SDK v4 verwendet wird. Wenn dies ein Problem darstellt, empfiehlt es sich, den Einführungsleitfaden zu Reactor-Mustern durchzulesen und sich mithilfe dieser Einführung in das reaktive Programmieren damit vertraut zu machen. Wenn Sie Azure Cosmos DB bereits mit einer Async-Schnittstelle verwendet haben und es sich bei dem verwendeten SDK um das Azure Cosmos DB Async Java SDK v2 gehandelt hat, sind Sie möglicherweise mit ReactiveX/RxJava vertraut, sind sich aber nicht sicher, was sich bei Project Reactor geändert hat. Sehen Sie sich in diesem Fall unseren Leitfaden mit dem Vergleich von Reactor und RxJava an.
Die folgenden Codeausschnitte zeigen, wie Sie Ihren Azure Cosmos DB-Client für Async- oder Sync-API-Vorgänge initialisieren:
Java SDK V4 (Maven com.azure::azure-cosmos) Async-API
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Aufskalieren Ihrer Clientworkload
Wenn Sie auf einem hohen Durchsatzniveau testen, könnte sich die Clientanwendung als Engpass erweisen, da der Computer die CPU- oder Netzwerkauslastung deckelt. Wenn dieser Punkt erreicht wird, können Sie das Azure Cosmos DB-Konto weiter auslasten, indem Sie Ihre Clientanwendungen auf mehrere Server horizontal hochskalieren.
Eine gute Faustregel ist, eine CPU-Auslastung von >50 Prozent auf einem beliebigen Server nicht zu überschreiten, um die Wartezeit gering zu halten.
- Verwenden des geeigneten Planers (Vermeiden des Diebstahls von Eventloop-E/A-Threads in Netty)
Die asynchrone Funktionalität des Azure Cosmos DB Java SDK basiert auf nicht blockierenden E/A-Vorgängen in Netty. Das SDK verwendet eine feste Anzahl (die Anzahl von CPU-Kernen Ihres Computers) von E/A-Eventloop-Threads in Netty zum Ausführen von E/A-Vorgängen. Das von der API zurückgegebene Flux-Objekt gibt das Ergebnis auf einem der freigegebenen E/A-Eventloop-Threads in Netty aus. Daher ist es wichtig, die freigegebenen E/A-Eventloop-Threads in Netty nicht zu blockieren. CPU-intensives Arbeiten oder das Blockieren von Vorgängen auf dem E/A-Eventloop-Thread in Netty könnte einen Deadlock verursachen oder den SDK-Durchsatz deutlich reduzieren.
Beispiel: Der folgende Code führt eine CPU-intensive Arbeit auf dem E/A-Eventloop-Thread in Netty aus:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
Nachdem das Ergebnis empfangen wurde, sollten Sie keine CPU-intensive Arbeit am Ergebnis für den E/A-Netty-Thread der Ereignisschleife ausführen. Stattdessen können Sie einen eigenen Planer bereitstellen, um wie unten gezeigt einen eigenen Thread für die Ausführung Ihrer Arbeit zur Verfügung zu stellen (erfordert import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
Je nach Art Ihrer Arbeit sollten Sie den entsprechenden vorhandenen Reactor-Planer verwenden. Lesen Sie hier nach: Schedulers.
Weitere Informationen zum Threading- und Planungsmodell des Projekts Reactor finden Sie in diesem Blogbeitrag von Project Reactor.
Weitere Informationen zum Azure Cosmos DB-Java SDK v4 finden Sie im Azure Cosmos DB-Verzeichnis des Azure-SDKs für Java-Monorepositorys auf GitHub.
- Optimieren der Protokollierungseinstellungen in Ihrer Anwendung
Aus verschiedenen Gründen sollten Sie die Protokollierung in einem Thread hinzufügen, der einen hohen Anforderungsdurchsatz generiert. Wenn das Ziel darin besteht, den bereitgestellten Durchsatz eines Containers mit den von diesem Thread generierten Anforderungen vollständig auszuschöpfen, kann die Leistung mithilfe von Protokollierungsoptimierungen erheblich verbessert werden.
- Konfigurieren einer Async-Protokollierung
Die Wartezeit einer synchronen Protokollierung ist notwendigerweise ein Faktor der Berechnung der Gesamtwartezeit des Threads, der Anforderungen generiert. Eine asynchrone Protokollierung wie log4j2 wird empfohlen, um den Protokollierungsaufwand von Hochleistungsanwendungsthreads zu entkoppeln.
- Deaktivieren der Netty-Protokollierung
Die Netty-Bibliotheksprotokollierung führt zu übermäßiger Kommunikation und muss deaktiviert werden (das Unterdrücken der Anmeldung in der Konfiguration reicht möglicherweise nicht aus), um zusätzliche CPU-Kosten zu vermeiden. Wenn Sie sich nicht im Debuggingmodus befinden, deaktivieren Sie die Protokollierung von Netty vollständig. Wenn Sie also „Log4j“ verwenden, um die zusätzlichen CPU-Kosten zu verhindern, die durch org.apache.log4j.Category.callAppenders() von Netty anfallen, fügen Sie Ihrer Codebasis die folgende Zeile hinzu:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Ressourcengrenzwert des Betriebssystems für geöffnete Dateien
Einige Linux-Systeme (z. B. Red Hat) haben eine Obergrenze für die Anzahl von offenen Dateien und damit für die Gesamtanzahl von Verbindungen. Führen Sie den folgenden Befehl aus, um die aktuellen Grenzwerte anzuzeigen:
ulimit -a
Die Anzahl von geöffneten Dateien (nofile) muss groß sein, damit ausreichend Platz für Ihre konfigurierte Verbindungspoolgröße und andere offene Dateien des Betriebssystem vorhanden ist. Sie kann geändert werden, um einen größeren Verbindungspool zu ermöglichen.
Öffnen Sie die Datei „limits.conf“:
vim /etc/security/limits.conf
Ändern Sie die folgenden Zeilen, bzw. fügen Sie sie hinzu:
* - nofile 100000
- Angeben von Partitionsschlüsseln in Punktschreibvorgängen
Geben Sie beim API-Aufruf mit Punktschreibvorgängen wie unten gezeigt Elementpartitionsschlüssel an, um die Leistung zu verbessern:
Java SDK V4 (Maven com.azure::azure-cosmos) Async-API
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
Geben Sie also nicht wie unten gezeigt nur die Elementinstanz an:
Java SDK V4 (Maven com.azure::azure-cosmos) Async-API
asyncContainer.createItem(item).block();
Die letztere Option wird unterstützt, erhöht aber die Wartezeit Ihrer Anwendung. Das SDK muss das Element analysieren und den Partitionsschlüssel extrahieren.
Abfragevorgänge
Informationen zu Abfragevorgängen finden Sie in den Leistungstipps für Abfragen.
Indizierungsrichtlinie
- Beschleunigen von Schreibvorgängen durch Ausschließen nicht verwendeter Pfade von der Indizierung
Mit der Indizierungsrichtlinie von Azure Cosmos DB können Sie angeben, welche Dokumentpfade mithilfe der Indizierungspfade (setIncludedPaths und setExcludedPaths) in die Indizierung eingeschlossen bzw. von ihr ausgeschlossen werden sollen. von der Indizierung ausgeschlossen werden sollen. Der folgende Code zeigt beispielsweise, wie Sie ganze Abschnitte der Dokumente (auch als Unterstruktur bezeichnet) mit dem Platzhalter „*“ bei der Indizierung ein- und ausschließen.
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Weitere Informationen finden Sie unter Indizierungsrichtlinien für Azure Cosmos DB.
Throughput
- Messen und Optimieren (Senken) der Anzahl von Anforderungseinheiten pro Sekunde
Azure Cosmos DB bietet vielfältige Datenbankvorgänge (einschließlich relationaler und hierarchischer Abfragen mit UDFs, gespeicherter Prozeduren und Trigger), die alle in den Dokumenten innerhalb einer Datenbanksammlung ausgeführt werden. Die Kosten im Zusammenhang mit diesen Vorgängen variieren basierend auf dem CPU-, E/A- und Speicheraufwand, der für den jeweiligen Vorgang erforderlich ist. Anstelle sich Gedanken über Hardwareressourcen und deren Verwaltung zu machen, können Sie sich eine Anforderungseinheit (RU) als alleinige Maßeinheit für die Ressourcen vorstellen, die für das Durchführen der verschiedenen Datenbankvorgänge und das Ausführen einer Anwendungsanforderung erforderlich sind.
Der Durchsatz wird basierend auf der für jeden Container festgelegten Anzahl von Anforderungseinheiten bereitgestellt. Der Verbrauch von Anforderungseinheiten wird als Rate pro Sekunde bemessen. Anwendungen, die die bereitgestellte Anforderungseinheitenrate für ihre Container überschreiten, werden begrenzt, bis die Rate wieder unter das bereitgestellte Niveau für den Container fällt. Wenn Ihre Anwendung einen höheren Durchsatz erfordert, können Sie ihn durch Bereitstellung zusätzlicher Anforderungseinheiten erhöhen.
Die Komplexität einer Abfrage wirkt sich darauf aus, wie viele Anforderungseinheiten für einen Vorgang verbraucht werden. Die Anzahl von Prädikaten, die Art der Prädikate, die Anzahl von UDFs und die Größe des Quelldatasets beeinflussen die Kosten von Abfragevorgängen.
Untersuchen Sie zum Ermitteln des Indizierungsaufwands für einen beliebigen Vorgang (Erstellen, Aktualisieren oder Löschen) den Header x-ms-request-charge. So ermitteln Sie die Anzahl von Anforderungseinheiten, die von diesen Vorgängen genutzt werden. Sie können sich außerdem die entsprechende RequestCharge-Eigenschaft in ResourceResponse<T> oder FeedResponse<T> ansehen.
Java SDK V4 (Maven com.azure::azure-cosmos) Async-API
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
Bei der in diesem Header zurückgegebenen Anforderungsbelastung handelt es sich um einen Bruchteil Ihres bereitgestellten Durchsatzes. Falls Sie beispielsweise 2000 RU/Sek. bereitgestellt haben und die vorherige Abfrage 1000 Dokumente mit einer Größe von je 1 KB zurückgibt, fallen für den Vorgang Kosten in Höhe von 1000 an. Somit werden vom Server innerhalb einer Sekunde nur zwei solcher Anforderungen berücksichtigt, und für weitere Anforderungen wird die Rate begrenzt. Weitere Informationen finden Sie unter Anforderungseinheiten in DocumentDB sowie unter dem Rechner für Anforderungseinheiten.
- Behandeln von Ratenbeschränkungen/zu hohen Anforderungsraten
Wenn ein Client versucht, den für ein Konto reservierten Durchsatz zu überschreiten, wird die Serverleistung nicht beeinträchtigt, und es wird kein über die reservierte Kapazität hinausgehender Durchsatz in Anspruch genommen. Der Server beendet die Anforderung präemptiv mit „RequestRateTooLarge“ (HTTP-Statuscode 429) und gibt den Header x-ms-retry-after-ms zurück. Darin ist die Zeitspanne (in Millisekunden) angegeben, die der Benutzer warten muss, bis ein neuer Anforderungsversuch unternommen werden kann.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Alle SDKs fangen diese Antwort implizit ab, berücksichtigen den vom Server angegebenen Header vom Typ „retry-after“ und wiederholen die Anforderung. Wenn nicht mehrere Clients gleichzeitig auf Ihr Konto zugreifen, wird die nächste Wiederholung erfolgreich ausgeführt.
Falls mehrere Clients kumulativ und kontinuierlich die Anforderungsrate überschreiten, reicht die intern vom Client festgelegte Standardanzahl von neun Wiederholungen unter Umständen nicht aus. In diesem Fall löst der Client für die Anwendung eine CosmosClientException mit dem Statuscode 429 aus. Die standardmäßige Wiederholungsanzahl kann durch Verwendung von setMaxRetryAttemptsOnThrottledRequests() für die ThrottlingRetryOptions-Instanz geändert werden. Die CosmosClientException-Klasse mit dem Statuscode 429 wird standardmäßig nach einer kumulierten Wartezeit von 30 Sekunden zurückgegeben, wenn die Anforderung weiterhin die Anforderungsrate übersteigt. Dies gilt auch, wenn die aktuelle Wiederholungsanzahl unter der maximalen Wiederholungsanzahl liegt – ganz gleich, ob es sich dabei um den Standardwert (9) oder um einen benutzerdefinierten Wert handelt.
Das automatisierte Wiederholungsverhalten trägt zwar bei den meisten Anwendungen zur Verbesserung der Resilienz und Nutzbarkeit bei, kann bei Leistungsbenchmarks aber auch hinderlich sein (insbesondere beim Ermitteln der Latenz). Die Wartezeit für den Client nimmt stark zu, wenn das Experiment die Serverdrosselung erreicht und damit die automatische Wiederholung durch das Client-SDK auslöst. Ermitteln Sie zur Vermeidung von Latenzspitzenwerten bei Leistungsexperimenten die von den einzelnen Vorgängen zurückgegebene Belastung, und stellen Sie sicher, dass die Anforderungen die reservierte Anforderungsrate nicht überschreiten. Weitere Informationen finden Sie unter Anforderungseinheiten in DocumentDB.
- Konzipieren für kleinere Dokumente und höheren Durchsatz
Die Anforderungsbelastung (die Kosten für die Anforderungsverarbeitung) eines Vorgangs hängt direkt mit der Größe des Dokuments zusammen. Vorgänge für große Dokumente sind teurer als Vorgänge für kleine Dateien. Im Idealfall sollten Sie Ihre Anwendung und Workflows so entwerfen, dass die Größe Ihrer Elemente etwa 1 KB oder eine ähnliche Größenordnung beträgt. Bei Anwendungen, die hinsichtlich der Wartezeit empfindlich sind, sollten große Elemente vermieden werden – Multi-MB-Dokumente verlangsamen Ihre Anwendung.
Nächste Schritte
Weitere Informationen zum Entwerfen einer auf Skalierung und hohe Leistung ausgelegten Anwendung finden Sie unter Partitionieren und Skalieren in Azure Cosmos DB.
Versuchen Sie, die Kapazitätsplanung für eine Migration zu Azure Cosmos DB durchzuführen? Sie können Informationen zu Ihrem vorhandenen Datenbankcluster für die Kapazitätsplanung verwenden.
- Wenn Sie lediglich die Anzahl der virtuellen Kerne und Server in Ihrem vorhandenen Datenbankcluster kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mithilfe von virtuellen Kernen oder virtuellen CPUs.
- Wenn Sie die typischen Anforderungsraten für Ihre aktuelle Datenbankworkload kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mit dem Azure Cosmos DB-Kapazitätsplaner