Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
In diesem Artikel wird beschrieben, wie Sie die Kopieraktivität in Pipelines von Azure Data Factory und Synapse Analytics verwenden, um Daten aus und in Azure Database for PostgreSQL zu kopieren. Und wie Sie Data Flow zum Transformieren von Daten in Azure Database for PostgreSQL verwenden. Weitere Informationen finden Sie in den Einführungsartikeln für Azure Data Factory und Synapse Analytics.
Von Bedeutung
Die Azure Database for PostgreSQL Version 2.0 bietet verbesserte native Azure Database for PostgreSQL Unterstützung. Wenn Sie Azure Database for PostgreSQL Version 1.0 in Ihrer Lösung verwenden, empfiehlt es sich, ihren Azure Database for PostgreSQL-Connector bei der frühestmöglichen Gelegenheit zu aktualisieren.
Dieser Connector ist auf den Azure Database for PostgreSQL-Dienst spezialisiert. Wenn Sie Daten aus einer generischen PostgreSQL-Datenbank in der lokalen Umgebung oder in der Cloud kopieren möchten, verwenden Sie den PostgreSQL-Connector.
Unterstützte Funktionen
Dieser Azure Database for PostgreSQL Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR | Verwalteter privater Endpunkt | Unterstützte Versionen von Connector |
|---|---|---|---|
| Copy-Aktivität (Quelle/Senke) | (1) (2) | 1.0 & 2.0 | |
| Zuordnungsdatenfluss (Quelle/Senke) | ① | 1.0 & 2.0 | |
| Lookup-Aktivität | (1) (2) | 1.0 & 2.0 | |
| Skriptaktivität | (1) (2) | 2.0 |
(1) Azure Integrationslaufzeit (2) Selbst gehostete Integrationslaufzeit
Die drei Aktivitäten arbeiten an Azure Database for PostgreSQL Single Server, Flexible Server und Azure Cosmos DB für PostgreSQL.
Von Bedeutung
Azure Database for PostgreSQL Single Server wird am 28. März 2025 eingestellt. Migrieren Sie nach diesem Datum zu flexiblem Server. Sie können sich auf diesen Artikel und häufig gestellte Fragen zu den Migrationsleitfäden beziehen.
Erste Schritte
Zum Ausführen der Kopieraktivität mit einer Pipeline können Sie eines der folgenden Tools oder SDKs verwenden:
- Datenkopier-Werkzeug
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST-API
- Azure Resource Manager Vorlage
Erstellen eines verknüpften Diensts zum Azure Database for PostgreSQL mithilfe der Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen verknüpften Service für Azure-Datenbank für PostgreSQL im Azure-Portal zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte "Verwalten", und wählen Sie "Verknüpfte Dienste" und dann "Neu" aus:
Suchen Sie nach PostgreSQL, und wählen Sie die Azure Datenbank für Den PostgreSQL-Connector aus.
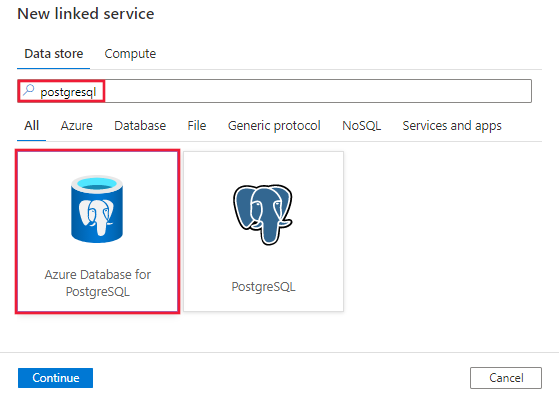
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
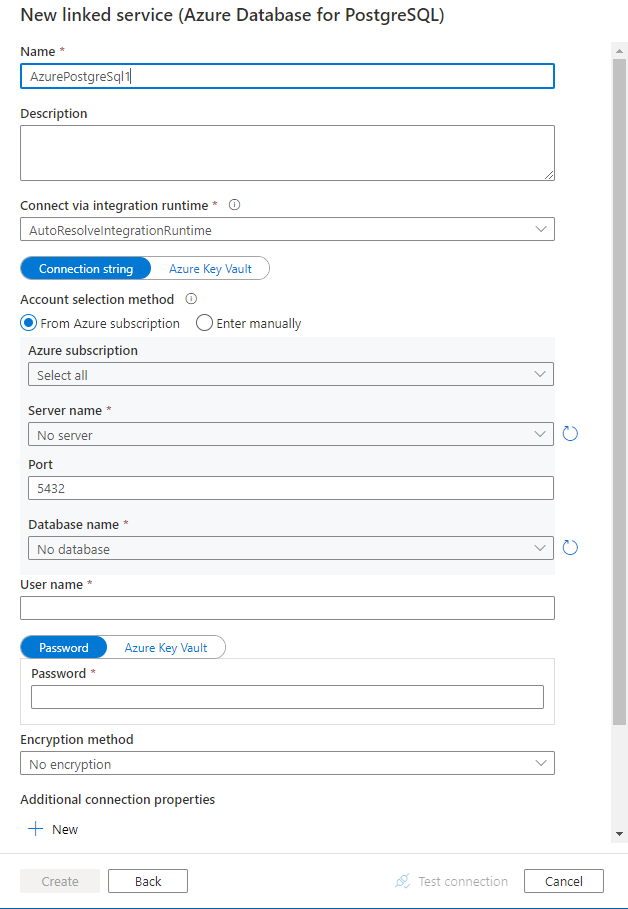
Details zur Connectorkonfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Data Factory-Entitäten verwendet werden, die für Azure Database for PostgreSQL Connector spezifisch sind.
Eigenschaften des verknüpften Diensts
Die Azure Database for PostgreSQL Connectorversion 2.0 unterstützt transport Layer Security (TLS) 1.3 und mehrere SSL-Modi (Secured Socket Layer). Verweisen Sie auf diesen Abschnitt, um die Azure SQL Database Connectorversion von Version 1.0 zu aktualisieren. Einzelheiten zur Eigenschaft finden Sie in den entsprechenden Abschnitten.
Version 2.0
Die folgenden Eigenschaften werden für den Azure Database for PostgreSQL verknüpften Dienst unterstützt, wenn Sie Version 2.0 anwenden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Typeigenschaft muss auf AzurePostgreSql festgelegt sein. | Ja |
| version | Die von Ihnen angegebene Version. Der Wert ist 2.0. |
Ja |
| Authentifizierungstyp | Wählen Sie aus den Authentifizierungstypen Basis, Dienstprinzipal, vom System zugewiesene verwaltete Identität oder vom Benutzer zugewiesene verwaltete Identität. | Ja |
| server | Gibt den Hostnamen und optionalen Port an, auf dem Azure Database for PostgreSQL ausgeführt wird. | Ja |
| Hafen | Der TCP-Port des Azure Database for PostgreSQL-Servers. Der Standardwert ist 5432. |
Nein |
| Datenbank | Der Name der Azure Database for PostgreSQL Datenbank, mit der eine Verbindung hergestellt werden soll. | Ja |
| SSL-Modus | Steuert, ob SSL verwendet wird, je nach Serverunterstützung - Deaktiviert: SSL ist deaktiviert. Wenn der Server SSL erfordert, schlägt die Verbindung fehl. - Allow: Nicht-SSL-Verbindungen werden bevorzugt, wenn der Server sie zulässt, aber SSL-Verbindungen werden zugelassen. - Bevorzugt: Bevorzugen Sie SSL-Verbindungen, wenn der Server sie zulässt, aber Verbindungen ohne SSL zulassen. - Erforderlich: Die Verbindung schlägt fehl, wenn der Server SSL nicht unterstützt. - Verify_ca: Die Verbindung schlägt fehl, wenn der Server SSL nicht unterstützt. Überprüft außerdem das Serverzertifikat - Verify_full: Die Verbindung schlägt fehl, wenn der Server SSL nicht unterstützt. Überprüft außerdem das Serverzertifikat mit dem Namen des Hosts Optionen: Deaktiviert (0) / Zulassen (1) / Bevorzugt (2) (Standard) / Erforderlich (3) / Verify_ca (4) / Verify_full (5) |
Nein |
| connectVia | Diese Eigenschaft gibt die Integration Runtime an, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet wird. Sie können Azure Integration Runtime oder selbst gehostete Integration Runtime verwenden (wenn sich Ihr Datenspeicher im privaten Netzwerk befindet). Wenn nicht angegeben, wird die Standard-Azure Integration Runtime verwendet. | Nein |
| Zusätzliche Verbindungseigenschaften: | ||
| schema | Legt den Schema-Suchpfad fest | Nein |
| pooling | Gibt an, ob Verbindungspooling verwendet werden soll | Nein |
| connectionTimeout | Die Wartezeit (in Sekunden) beim Versuch, eine Verbindung herzustellen, bevor der Versuch beendet und ein Fehler erzeugt wird. | Nein |
| commandTimeout | Die Zeit (in Sekunden), die beim Ausführen eines Befehls gewartet werden soll, bis der Versuch beendet und ein Fehler generiert wird. Legen Sie für die Unendlichkeit Null fest. | Nein |
| trustServerZertifikat | Gibt an, ob dem Serverzertifikat vertraut werden soll, ohne es zu überprüfen | Nein |
| readBufferSize | Bestimmt die Größe des internen Puffers, den Npgsql beim Lesen verwendet. Die Erhöhung kann die Leistung verbessern, wenn große Werte aus der Datenbank übertragen werden. | Nein |
| Zeitzone | Ruft die Zeitzone der Sitzung ab oder legt sie fest | Nein |
| Kodierung | Dient zum Abrufen oder Festlegen der .NET-Codierung für die Codierung/Decodierung von PostgreSQL-Zeichenfolgendaten. | Nein |
Standardauthentifizierung
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Benutzername | Der Benutzername, mit dem eine Verbindung hergestellt werden soll. Ist bei Verwendung von IntegratedSecurity nicht erforderlich | Ja |
| Kennwort | Das Kennwort, mit dem eine Verbindung hergestellt werden soll. Ist bei Verwendung von IntegratedSecurity nicht erforderlich Markieren Sie dieses Feld als SecureString, um es sicher zu speichern. Sie können auch auf ein im Azure Key Vault gespeichertes Geheimnis verweisen. | Ja |
Beispiel:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Beispiel:
Passwort in Azure Key Vault speichern
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Authentifizierung mit systemseitig zugewiesener verwalteter Identität
Ein Data Factory- oder Synapse-Arbeitsbereich kann einer System zugewiesenen verwalteten Identität zugeordnet werden, die den Dienst darstellt, wenn er bei anderen Ressourcen in Azure authentifiziert wird. Sie können diese verwaltete Identität für Azure Datenbank für die PostgreSQL-Authentifizierung verwenden. Die angegebenen Factory oder Synapse Arbeitsbereiche können mittels dieser Identität auf Daten zugreifen und Daten aus der oder in die Datenbank kopieren.
Führen Sie die schritte aus, um vom System zugewiesene verwaltete Identität zu verwenden:
Eine Datenfabrik oder ein Synapse-Arbeitsbereich kann einer vom System zugewiesenen verwalteten Identität zugeordnet werden. Weitere Informationen, Generieren von vom System zugewiesener verwalteter Identität
Die Azure Daten für PostgreSQL mit vom System zugewiesener verwalteter Identität On.
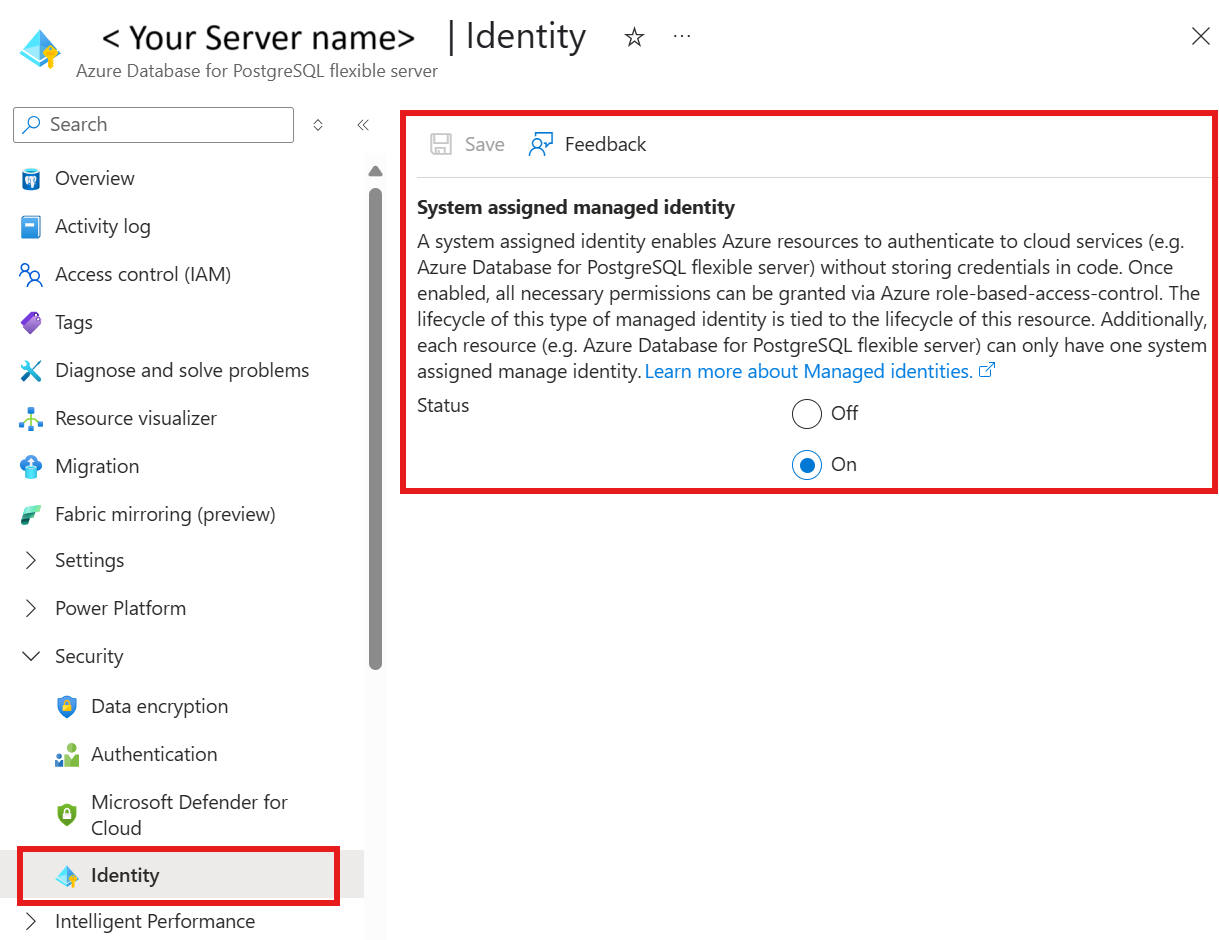
In Ihrer Azure Database for PostgreSQL-Ressource unter Sicherheit
Authentifizierung auswählen
Wählen Sie entweder nur Microsoft Entra-Authentifizierung oder PostgreSQL und Microsoft Entra-Authentifizierung-Authentifizierungsmethode aus.
Wählen Sie + Microsoft Entra-Administratoren hinzufügen
Fügen Sie die vom System zugewiesene verwaltete Identität für die Azure Data Factory-Ressource als eine der Microsoft Entra Administratoren hinzu.
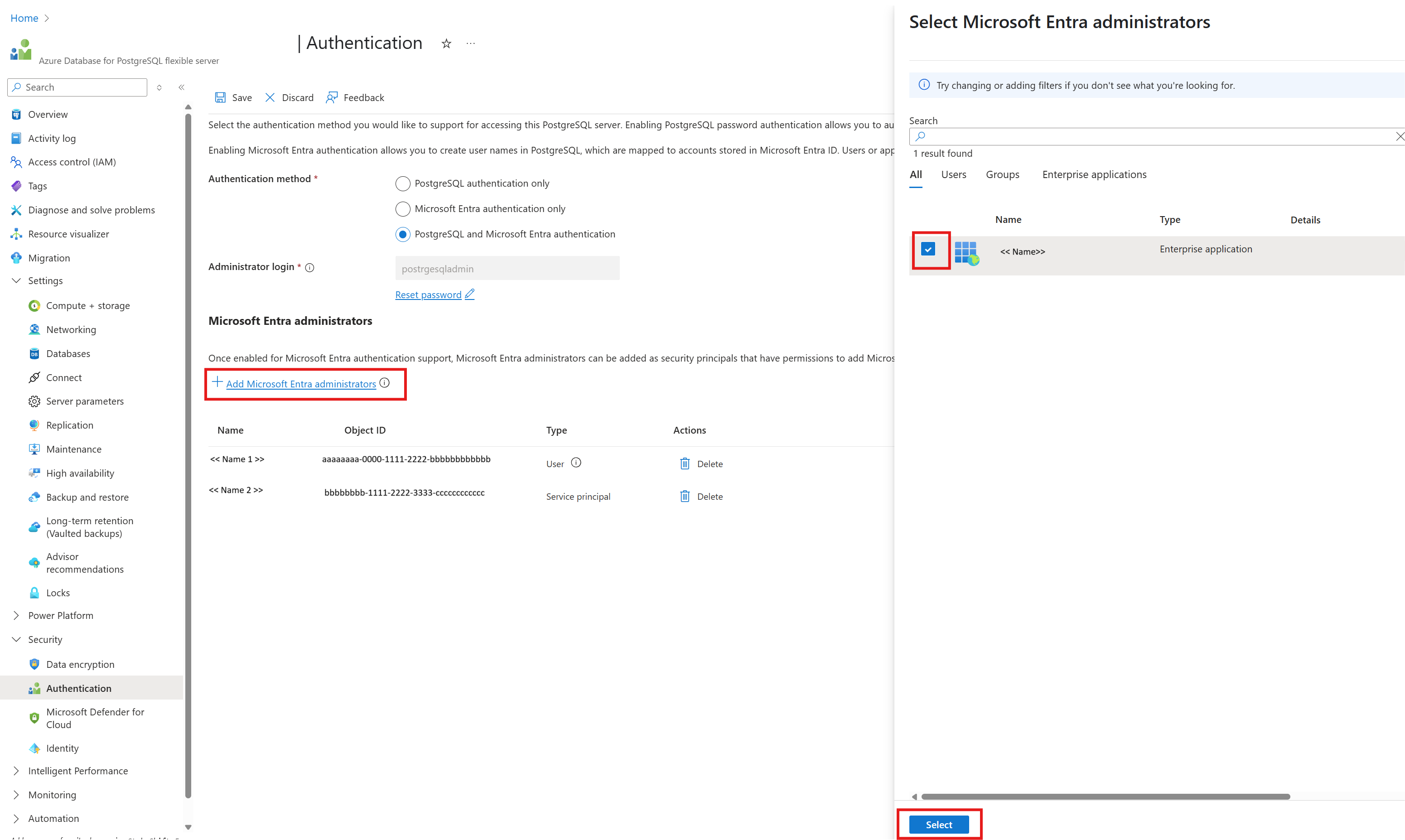
Konfigurieren Sie eine Azure-Datenbank für den mit PostgreSQL verknüpften Dienst.


Beispiel:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "SystemAssignedManagedIdentity"
}
}
}
Hinweis
Dieser Authentifizierungstyp wird für die selbst gehostete Integrationslaufzeit nicht unterstützt.
Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Ein Data Factory- oder Synapse-Arbeitsbereich kann einer benutzerdefinierten verwalteten Identität zugeordnet werden, die den Dienst darstellt, wenn er gegenüber anderen Ressourcen in Azure authentifiziert wird. Sie können diese verwaltete Identität für Azure Datenbank für die PostgreSQL-Authentifizierung verwenden. Die angegebenen Factory oder Synapse Arbeitsbereiche können mittels dieser Identität auf Daten zugreifen und Daten aus der oder in die Datenbank kopieren.
Um die vom Benutzer zugewiesene verwaltete Identitätsauthentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Anmeldeinformationen (credential) | Geben Sie die vom Benutzer zugewiesene verwaltete Identität als Anmeldeobjekt an. | Ja |
Sie müssen auch die Schritte ausführen:
Stellen Sie sicher, dass Sie eine Benutzer zugewiesene verwaltete Identität-Ressource im Azure-Portal erstellen. Weitere Informationen finden Sie unter Verwalten von vom Benutzer zugewiesenen verwalteten Identitäten
Weisen Sie die benutzerzugewiesene verwaltete Identität Ihrer Azure-Datenbank für die PostgreSQL-Ressource zu.
In Ihrer Azure-Datenbank für die PostgreSQL-Serverressource unter Security
Authentifizierung auswählen
Überprüfen Sie, ob die Authentifizierungsmethode nur Microsoft Entra Authentifizierung oder PostgreSQL und Microsoft Entra Authentifizierung ist
Wählen Sie + Microsoft Entra-Administratoren hinzufügen und wählen Sie Ihre vom Benutzer zugewiesene verwaltete Identität aus.
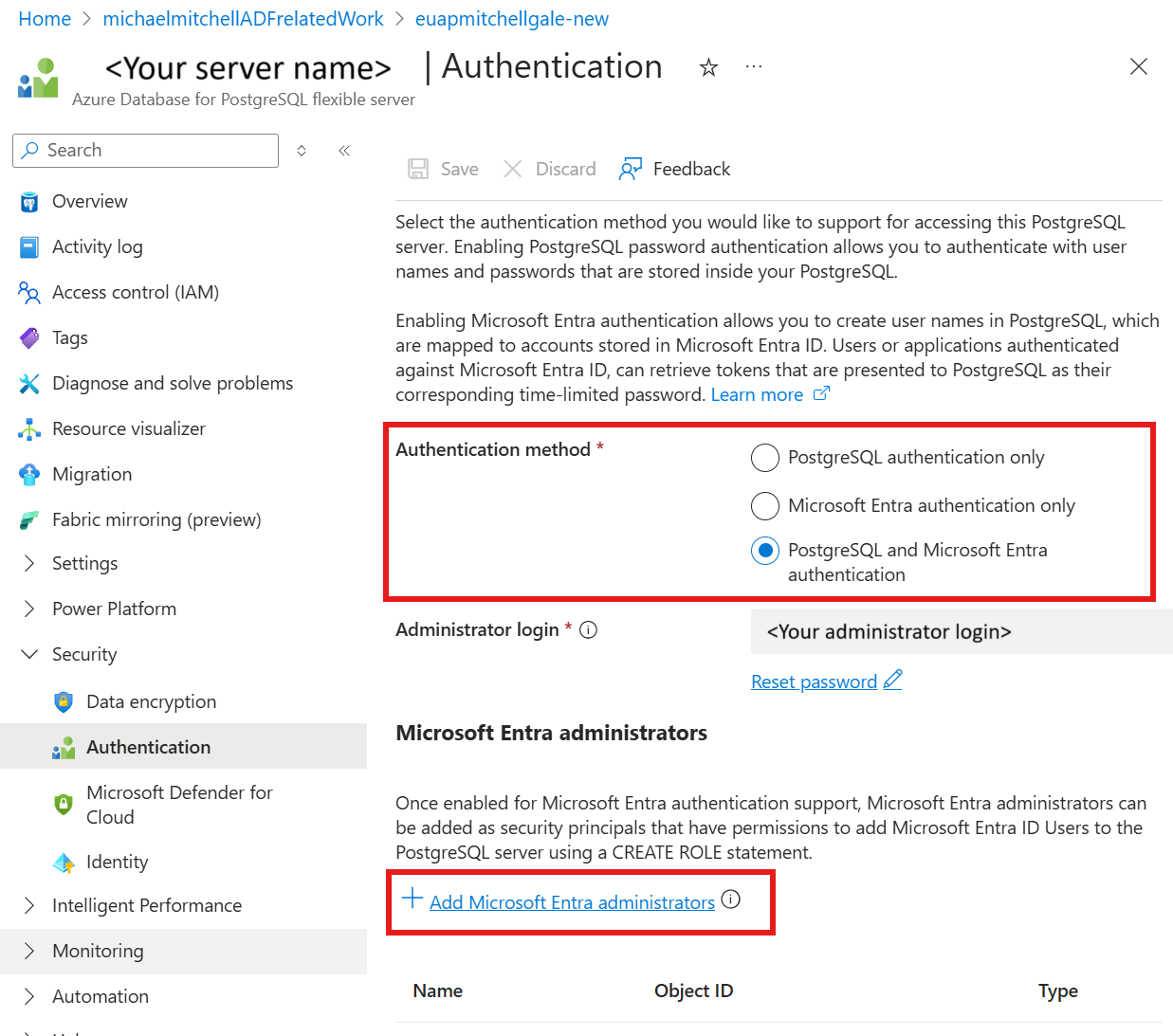
Weisen Sie die Benutzer zugewiesene verwaltete Identität Ihrer Azure Data Factory-Ressource zu.
Wählen Sie "Einstellungen" und dann "Verwaltete Identitäten" aus.
Unter der Registerkarte "Benutzer zugewiesen" wählen Sie den Link + Hinzufügen aus und wählen Sie Ihre benutzerverwaltete Identität aus.
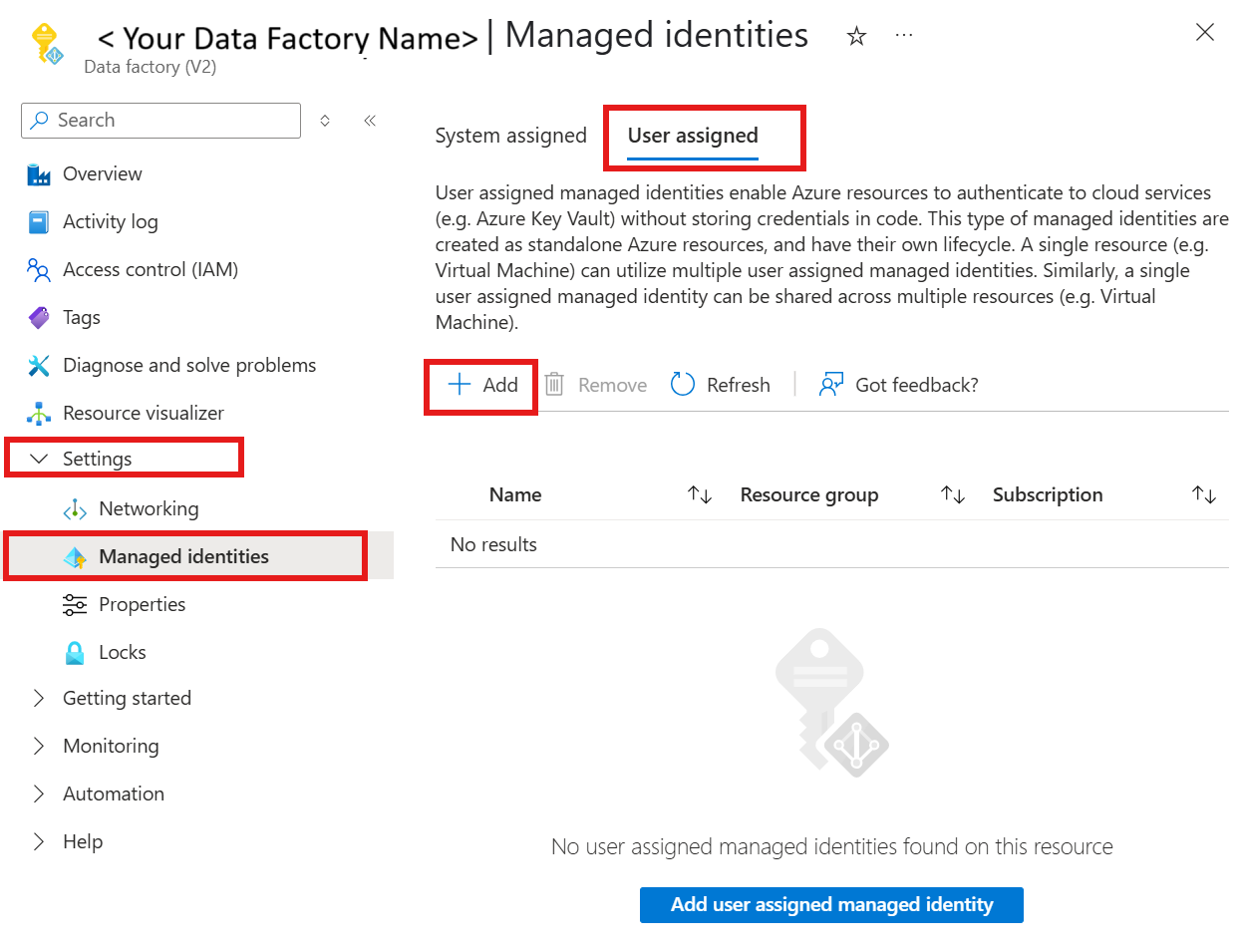
Konfigurieren Sie eine Azure-Datenbank für den mit PostgreSQL verknüpften Dienst.


Beispiel:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "<your credential>",
"type": "CredentialReference"
}
}
}
}
Dienstprinzipalauthentifizierung
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Benutzername | Der Anzeigename des Dienstprinzipals | Ja |
| Mieter | Der Mandant, in dem sich der Azure Database for PostgreSQL-Server befindet | Ja |
| servicePrincipalId | Anwendungs-ID des Dienstprinzipals | Ja |
| servicePrincipalCredentialType | Wählen Sie aus, ob das Dienstprinzipalzertifikat oder der Dienstprinzipalschlüssel die gewünschte Authentifizierungsmethode ist. - ServicePrincipalCert: Auf Dienstprinzipalzertifikat für Dienstprinzipalzertifikate festlegen. - ServicePrincipalKey: Auf Dienstprinzipalschlüssel für die Dienstprinzipalschlüsselauthentifizierung festlegen. |
Ja |
| servicePrincipalKey | Wert für den geheimen Clientschlüssel Wird verwendet, wenn der Dienstprinzipalschlüssel ausgewählt ist | Ja |
| azureCloudType | Wählen Sie den Azure Cloudtyp Ihres Azure Database for PostgreSQL-Servers aus. | Ja |
| servicePrincipalEmbeddedCert | Dienstprinzipal-Zertifikatdatei | Ja |
| servicePrincipalEmbeddedCertPassword | Dienstprinzipal-Zertifikatkennwort, sofern erforderlich | Nein |
Beispiel:
Dienstprinzipalschlüssel
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalKey": "<service principal key>"
}
}
}
Beispiel:
Dienstprinzipalzertifikat
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalEmbeddedCert": "<service principal certificate>",
"servicePrincipalEmbeddedCertPassword": "<service principal embedded certificate password>"
}
}
}
Hinweis
Die Microsoft Entra ID-Authentifizierung mithilfe des Dienstprinzipals und der benutzerseitig zugewiesenen verwalteten Identität wird in der selbstgehosteten Integration Runtime Version 5.50 oder höher unterstützt.
Version 1.0
Die folgenden Eigenschaften werden für den Azure Database for PostgreSQL verknüpften Dienst unterstützt, wenn Sie Version 1.0 anwenden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Typeigenschaft muss auf AzurePostgreSql festgelegt sein. | Ja |
| version | Die von Ihnen angegebene Version. Der Wert ist 1.0. |
Ja |
| connectionString | Eine Npgsql-connection string, um eine Verbindung mit Azure Database for PostgreSQL herzustellen. Sie können auch ein Kennwort in Azure Key Vault einfügen und die konfiguration password aus dem connection string ziehen. Weitere Informationen finden Sie in den folgenden Beispielen und unter Anmeldeinformationen in Azure Key Vault speichern. |
Ja |
| connectVia | Diese Eigenschaft gibt die Integration Runtime an, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet wird. Sie können Azure Integration Runtime oder selbst gehostete Integration Runtime verwenden (wenn sich Ihr Datenspeicher im privaten Netzwerk befindet). Wenn nicht angegeben, wird die Standard-Azure Integration Runtime verwendet. | Nein |
Ein typischer connection string ist host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>. Weitere Eigenschaften, die Sie für Ihren Fall festlegen können:
| Eigenschaft | Beschreibung | Tastatur | Erforderlich |
|---|---|---|---|
| EncryptionMethod (EM) | Diese Methode wird vom Treiber verwendet, um Daten zu verschlüsseln, die zwischen dem Treiber und dem Datenbankserver gesendet werden. Zum Beispiel, EncryptionMethod=<0/1/6>; |
0 (keine Verschlüsselung) (Standard) / 1 (SSL) / 6 (RequestSSL) | Nein |
| ValidateServerCertificate (VSC) | Bestimmt, ob der Treiber das Zertifikat überprüft, das vom Datenbankserver gesendet wird, wenn die SSL-Verschlüsselung aktiviert ist (Encryption Method=1). Zum Beispiel, ValidateServerCertificate=<0/1>; |
0 (Deaktiviert) (Standard) / 1 (Aktiviert) | Nein |
Beispiel:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>"
}
}
}
Beispiel:
Passwort in Azure Key Vault speichern
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von Azure Database for PostgreSQL in Datensätzen unterstützt werden.
Um Daten aus Azure Database for PostgreSQL zu kopieren, legen Sie die Typeigenschaft des Datasets auf AzurePostgreSqlTable fest. Folgende Eigenschaften werden unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Typeigenschaft des Datasets muss auf AzurePostgreSqlTable festgelegt werden. | Ja |
| schema | Name des Schemas. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
| Tisch | Name der Tabelle/Ansicht. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
| Tabellenname | Name der Tabelle. Diese Eigenschaft wird aus Gründen der Abwärtskompatibilität weiterhin unterstützt. Verwenden Sie für eine neue Workload schema und table. |
Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
Beispiel:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste der verfügbaren Abschnitte und Eigenschaften zum Definieren von Aktivitäten finden Sie unter Pipelines. Dieser Abschnitt enthält eine Liste von Eigenschaften, die von einer Azure Database for PostgreSQL Quelle unterstützt werden.
Azure Datenbank für PostgreSql als Quelle
Um Daten aus Azure Database for PostgreSQL zu kopieren, legen Sie den Quelltyp in der Kopieraktivität auf AzurePostgreSqlSource fest. Folgende Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf AzurePostgreSqlSource festgelegt werden. | Ja |
| Abfrage | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. Zum Beispiel: SELECT * FROM mytable oder SELECT * FROM "MyTable". Beachten Sie, dass in PostgreSQL bei einem Entitätsnamen ohne Anführungszeichen die Groß-/Kleinschreibung nicht berücksichtigt wird. |
Nein (wenn die tableName-Eigenschaft im Dataset angegeben ist) |
| queryTimeout | Die Wartezeit, bevor der Versuch, einen Befehl auszuführen, beendet und ein Fehler generiert wird (der Standardwert ist 120 Minuten). Wenn für diese Eigenschaft ein Parameter festgelegt ist, sind Zeitspannen als Werte (Timespan-Werte) zulässig, z. B. „02:00:00“ (120 Minuten). Weitere Informationen finden Sie unter CommandTimeout. | Nein |
| Partitionierungsoptionen | Gibt die Datenpartitionierungsoptionen an, die zum Laden von Daten aus Azure SQL Database verwendet werden. Zulässige Werte sind: None (Standard), PhysicalPartitionsOfTable und DynamicRange. Wenn eine Partitionsoption aktiviert ist (d. h. nicht None), wird der Grad der Parallelität zum gleichzeitigen Laden von Daten aus einem Azure SQL Database durch die Einstellung parallelCopies für die Kopieraktivität gesteuert. |
Nein |
| Partitionseinstellungen | Geben Sie die Gruppe der Einstellungen für die Datenpartitionierung an. Verwenden Sie diese Option, wenn die Partitionsoption nicht None lautet. |
Nein |
Unter partitionSettings: |
||
| partitionNames | Die Liste der physischen Partitionen, die kopiert werden müssen. Verwenden Sie diese Option, wenn die Partitionsoption PhysicalPartitionsOfTable lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfTabularPartitionName in die WHERE-Klausel. Siehe als Beispiel den Abschnitt Paralleler Kopiervorgang aus Azure Database for PostgreSQL. |
Nein |
| partitionColumnName | Geben Sie den Namen der Quellspalte, der von der Bereichspartitionierung für paralleles Kopieren verwendet wird, als „integer“ oder „date/datetime“ (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone oder time without time zone) an. Ohne Angabe wird der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet.Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfRangePartitionColumnName in die WHERE-Klausel. Siehe als Beispiel den Abschnitt Paralleler Kopiervorgang aus Azure Database for PostgreSQL. |
Nein |
| partitionUpperBound | Der Höchstwert der Partitionsspalte zum Herauskopieren von Daten Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfRangePartitionUpbound in die WHERE-Klausel. Siehe als Beispiel den Abschnitt Paralleler Kopiervorgang aus Azure Database for PostgreSQL. |
Nein |
| partitionLowerBound | Der Mindestwert der Partitionsspalte zum Exportieren von Daten. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfRangePartitionLowbound in die WHERE-Klausel. Siehe als Beispiel den Abschnitt Paralleler Kopiervorgang aus Azure Database for PostgreSQL. |
Nein |
Beispiel:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database for PostgreSQL als Senke
Um Daten in Azure Database for PostgreSQL zu kopieren, legen Sie den Sinktyp in der Kopieraktivität auf SqlSink fest. Folgende Eigenschaften werden im Abschnitt sink der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich | Connector-Supportversion |
|---|---|---|---|
| Typ | Die type-Eigenschaft der Senke der Kopieraktivität muss auf AzurePostgreSQLSink festgelegt sein. | Ja | Version 1.0 & Version 2.0 |
| preCopyScript | Geben Sie eine SQL-Abfrage für die auszuführende Kopieraktivität an, bevor Sie Daten in Azure Database for PostgreSQL jeder Ausführung schreiben. Sie können diese Eigenschaft nutzen, um die vorab geladenen Daten zu bereinigen. | Nein | Version 1.0 & Version 2.0 |
| writeMethod | Die Methode zum Schreiben von Daten in Azure Database for PostgreSQL. Zulässige Werte sind: CopyCommand (Standard, was leistungsfähiger ist), BulkInsert und Upsert (nur Version 2.0). |
Nein | Version 1.0 & Version 2.0 |
| upsertSettings | Geben Sie die Gruppe der Einstellungen für das Schreibverhalten an. Wenden Sie dies an, wenn die WriteBehavior-Option Upsert ist. |
Nein | Version 2.0 |
Unter upsertSettings: |
|||
| Schlüssel | Geben Sie die Spaltennamen für die eindeutige Zeilenidentifikation an. Es kann entweder ein einzelner Schlüssel oder eine Reihe von Tasten verwendet werden. Schlüssel müssen ein Primärschlüssel oder eine eindeutige Spalte sein. Wenn nicht angegeben, wird der Primärschlüssel verwendet. | Nein | Version 2.0 |
| writeBatchSize | Die Anzahl der zeilen, die pro Batch in Azure Database for PostgreSQL geladen wurden. Als Wert ist ein Integer zulässig, der die Anzahl der Zeilen angibt. |
Nein (Standardwert: 1.000.000) | Version 1.0 & Version 2.0 |
| writeBatchTimeout | Die Wartezeit für den Abschluss der Batcheinfügung, bis das Timeout wirksam wird. Zulässige Werte sind Timespan-Zeichenfolgen. Beispiel: 00:30:00 (30 Minuten). |
Nein (Standardwert: 00:30:00) | Version 1.0 & Version 2.0 |
Beispiel 1: Befehl kopieren
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSqlSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Beispiel 2: Upsert von Daten
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"writeMethod": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
]
},
}
}
}
]
Daten-Update durchführen
Die Copy-Aktivität unterstützt Upsert‑Operationen nativ. Um ein Upsert durchzuführen, sollte der Benutzer Schlüsselspalten bereitstellen, die entweder Primärschlüssel oder eindeutige Spalten sind. Wenn der Benutzer keine Schlüsselspalten bereitstellt, werden Primärschlüsselspalten in der Senkentabelle verwendet. Kopieraktivität aktualisiert nicht schlüsselbezogene Spalten in der Sinktabelle, wobei die Schlüsselspaltenwerte mit denen in der Quelltabelle übereinstimmen; andernfalls werden neue Daten eingefügt.
Parallele Kopie aus Azure Database for PostgreSQL
Der Connector für Azure SQL-Datenbank in der Kopieraktivität verfügt über eine integrierte Datenpartitionierung zum parallelen Kopieren von Daten. Die Datenpartitionierungsoptionen befinden sich auf der Registerkarte Quelle der Kopieraktivität.
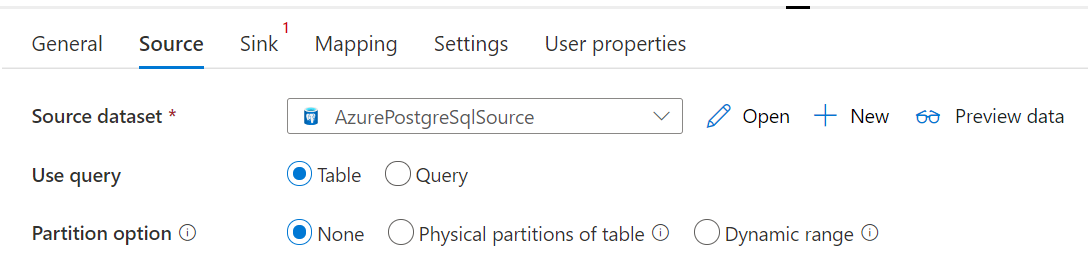
Wenn Sie partitionierte Kopie aktivieren, führt kopieraktivität parallele Abfragen für Ihre Azure Database for PostgreSQL Quelle aus, um Daten nach Partitionen zu laden. Der Parallelitätsgrad wird über die Einstellung parallelCopies der Kopieraktivität gesteuert. Wenn Sie z. B. parallelCopies auf vier festlegen, generiert der Dienst parallel vier Abfragen basierend auf Ihrer angegebenen Partitionsoption und -einstellungen, und jede Abfrage ruft einen Teil der Daten aus Ihrer Azure Database for PostgreSQL ab.
Sie werden empfohlen, parallele Kopie mit Datenpartitionierung zu aktivieren, insbesondere wenn Sie eine große Datenmenge aus Ihrem Azure Database for PostgreSQL laden. Im Anschluss finden Sie empfohlene Konfigurationen für verschiedene Szenarien. Beim Kopieren von Daten in einen dateibasierten Datenspeicher empfiehlt es sich, in einen Ordner als mehrere Dateien zu schreiben (nur den Ordnernamen angeben), in diesem Fall ist die Leistung besser als das Schreiben in eine einzelne Datei.
| Szenario | Empfohlene Einstellungen |
|---|---|
| Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen |
Partitionsoption: Physische Partitionen der Tabelle. Während der Ausführung erkennt der Dienst automatisch die physischen Partitionen und kopiert Daten nach Partitionen. |
| Vollständiges Laden aus einer großen Tabelle ohne physische Partitionen, aber mit einer Integerspalte für die Datenpartitionierung |
Partitionsoptionen: Partition des dynamischen Bereichs. Partitionsspalte: Geben Sie die Spalte an, die zum Partitionieren von Daten verwendet wird. Ohne Angabe wird die Primärschlüsselspalte verwendet. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage mit physischen Partitionen |
Partitionsoption: Physische Partitionen der Tabelle. Abfrage: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>Partitionsname: Geben Sie mindestens einen Partitionsnamen an, aus dem Daten kopiert werden sollen. Wenn keine Angabe erfolgt, erkennt der Dienst automatisch die physischen Partitionen in der Tabelle, die Sie im PostgreSQL-Dataset angegeben haben. Während der Ausführung ersetzt der Dienst ?AdfTabularPartitionName durch den tatsächlichen Partitionsnamen und sendet an Azure Database for PostgreSQL. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage ohne physische Partitionen, aber mit einer Integerspalte für die Datenpartitionierung |
Partitionsoptionen: Partition des dynamischen Bereichs. Abfrage: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte an, die zum Partitionieren von Daten verwendet wird. Sie können eine Partition für die Spalte mit einem Integer- oder date/datetime-Datentyp erstellen. Partition obere Grenze und Partition untere Grenze: Geben Sie an, ob Sie nach Partitionsspalte filtern möchten, um Daten nur zwischen dem unteren und oberen Bereich abzurufen. Während der Ausführung ersetzt der Dienst ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound und ?AdfRangePartitionLowbound durch den tatsächlichen Spaltennamen und Wertbereiche für jede Partition und sendet an Azure Database for PostgreSQL. Wenn z. B. für Ihre Partitionsspalte „ID“ die untere Grenze auf 1 und die obere Grenze auf 80 festgelegt ist und die Parallelkopie auf 4 eingestellt ist, ruft der Dienst Daten nach vier Partitionen ab. Die ID-Bereiche sehen dann wie folgt aus: [1–20], [21–40], [41–60] und [61–80]. |
Bewährte Methoden zum Laden von Daten mit Partitionierungsoption:
- Wählen Sie eine aussagekräftige Spalte als Partitionsspalte (wie Primärschlüssel oder eindeutiger Schlüssel), um Datenabweichungen zu vermeiden.
- Wenn die Tabelle eine integrierte Partition aufweist, verwenden Sie die Partitionsoption „Physikalische Partitionen der Tabelle“, um eine bessere Leistung zu erzielen.
- Wenn Sie Azure Integration Runtime zum Kopieren von Daten verwenden, können Sie größere "Data Integration Units (DIU)" (>4) festlegen, um weitere Rechenressourcen zu nutzen. Prüfen Sie dort die anwendbaren Szenarien.
- "Der Grad der Kopierparallelität bestimmt die Partitionsnummern. Eine zu große Zahl kann manchmal die Leistung beeinträchtigen." Empfehlen Sie, diese Zahl als (DIU oder Anzahl von selbst gehosteten IR-Knoten) * (2 bis 4) festzulegen.
Beispiel: Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Beispiel: Abfrage mit dynamischer Bereichspartition
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Eigenschaften von Mapping Data Flow
Beim Transformieren von Daten im Zuordnungsdatenfluss können Sie Tabellen aus Azure Database for PostgreSQL lesen und in diese schreiben. Weitere Informationen finden Sie unter Quellentransformation und Senkentransformation in Zuordnungsdatenflüssen. Sie können ein Azure Database for PostgreSQL-Dataset oder ein Inlinedataset als Quell- und Senkentyp verwenden.
Hinweis
Derzeit wird nur die Standardauthentifizierung für V1- und V2-Versionen des Azure Database for PostgreSQL-Connectors in der Zuordnung von Datenflüssen unterstützt.
Quellentransformation
In der folgenden Tabelle sind die von Azure Database for PostgreSQL Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Tabelle | Wenn Sie „Tabelle“ als Eingabe auswählen, ruft der Datenfluss alle Daten aus der im Dataset angegebenen Tabelle ab. | Nein | - |
(nur für Inlinedataset) Tabellenname |
| Abfrage | Wenn Sie „Abfrage“ als Eingabe auswählen, geben Sie eine SQL-Abfrage zum Abrufen von Daten aus der Quelle an, die Vorrang vor jeder im Dataset angegebenen Tabelle hat. Die Verwendung von Abfragen stellt eine gute Möglichkeit dar, um die Zeilen für Tests oder Suchvorgänge zu verringern. Order By-Klausel wird nicht unterstützt, Sie können jedoch eine vollständige SELECT FROM-Anweisung festlegen. Sie können auch benutzerdefinierte Tabellenfunktionen verwenden. select * from udfGetData() ist eine benutzerdefinierte Funktion in SQL, mit der eine Tabelle zurückgegeben wird, die Sie im Datenfluss verwenden können. Abfragebeispiel: select * from mytable where customerId > 1000 and customerId < 2000 oder select * from "MyTable". Beachten Sie, dass in PostgreSQL bei einem Entitätsnamen ohne Anführungszeichen die Groß-/Kleinschreibung nicht berücksichtigt wird. |
Nein | Schnur | Abfrage |
| Schemaname | Wenn Sie „Gespeicherte Prozedur als Eingabe“ auswählen, geben Sie einen Schemanamen der gespeicherten Prozedur an, oder wählen Sie „Aktualisieren“ aus, um den Dienst aufzufordern, die Schemanamen zu ermitteln. | Nein | Schnur | schemaName |
| Gespeicherte Prozedur | Wenn Sie „Gespeicherte Prozedur als Eingabe“ auswählen, geben Sie einen Namen der gespeicherten Prozedur an, um Daten aus der Quelltabelle zu lesen, oder wählen Sie „Aktualisieren“ aus, um den Dienst aufzufordern, die Prozedurnamen zu ermitteln. | Ja (wenn Sie „Gespeicherte Prozedur als Eingabe“ auswählen) | Schnur | procedureName |
| Prozedurparameter | Wenn Sie „Gespeicherte Prozedur als Eingabe“ auswählen, geben Sie alle Eingabeparameter für die gespeicherte Prozedur in der in der Prozedur festgelegten Reihenfolge an, oder wählen Sie „Importieren“ aus, um alle Prozedurparameter mithilfe des Formulars @paraNamezu importieren. |
Nein | Array | Eingaben |
| Batchgröße | Geben Sie eine Batchgröße an, um große Datenmengen in Batches zu segmentieren. | Nein | Integer | batchSize |
| Isolationsstufe | Wählen Sie eine der folgenden Isolationsstufen aus: – Lesen zugesichert – Lesen nicht zugesichert (Standard) – Wiederholbarer Lesevorgang – Serialisierbar – Keine (Isolationsstufe ignorieren) |
Nein | READ_COMMITTED READ_UNCOMMITTED Wiederholbarer_Lesevorgang (REPEATABLE_READ) SERIALISIERBAR NICHTS |
Isolationsebene |
Beispiel für Azure Database for PostgreSQL Quellskript
Wenn Sie Azure Database for PostgreSQL als Quelltyp verwenden, lautet das zugeordnete Datenflussskript:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Senkentransformation
In der folgenden Tabelle sind die Eigenschaften aufgeführt, die von Azure Database for PostgreSQL Sink unterstützt werden. Sie können diese Eigenschaften auf der Registerkarte Senkenoptionen bearbeiten.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Updatemethode | Geben Sie an, welche Vorgänge für das Datenbankziel zulässig sind. Standardmäßig sind lediglich Einfügevorgänge zulässig. Um Aktualisierungs-, Upsert- oder Löschaktionen auf Zeilen anzuwenden, muss eine Zeilenänderungstransformation zum Kennzeichnen von Zeilen für diese Aktionen erfolgen. |
Ja |
true oder false |
löschbar insertable aktualisierbar upsertable |
| Schlüsselspalten | Für Update-, Upsert- und Löschvorgänge müssen Schlüsselspalten festgelegt werden, um die Zeile zu bestimmen, die geändert werden soll. Der Spaltenname, den Sie als Schlüssel auswählen, wird als Teil der nachfolgenden Update-, Upsert- und Löschvorgänge verwendet. Daher müssen Sie eine Spalte auswählen, die in der Senkenzuordnung vorhanden ist. |
Nein | Array | Schlüssel |
| Schreiben von Schlüsselspalten überspringen | Wenn Sie den Wert nicht in die Schlüsselspalte schreiben möchten, wählen Sie „Schreiben von Schlüsselspalten überspringen“ aus. | Nein |
true oder false |
skipKeyWrites |
| Aktion table | Bestimmt, ob alle Zeilen vor dem Schreiben neu erstellt oder aus der Zieltabelle entfernt werden sollen. - Keine: Für die Tabelle wird keine Aktion ausgeführt. - Neu erstellen: Die Tabelle wird gelöscht und neu erstellt. Erforderlich, wenn eine neue Tabelle dynamisch erstellt wird. - Abschneiden: Alle Zeilen werden aus der Zieltabelle entfernt. |
Nein |
true oder false |
Neu erstellen abschneiden |
| Batchgröße | Geben Sie an, wie viele Zeilen in die einzelnen Batches geschrieben werden. Durch größere Batches werden zwar Komprimierung und Arbeitsspeicheroptimierung verbessert, beim Zwischenspeichern von Daten besteht aber die Gefahr, dass Ausnahmen wegen unzureichenden Arbeitsspeichers auftreten. | Nein | Integer | batchSize |
| Benutzerdatenbankschema auswählen | Standardmäßig wird eine temporäre Tabelle unter dem Senkenschema als Staging erstellt. Alternativ können Sie die Option Senkenschema verwenden deaktivieren, und stattdessen einen Schemanamen angeben, unter dem Data Factory eine Stagingtabelle erstellt, um vorgelagerte Daten zu laden und diese automatisch nach Abschluss zu löschen. Stellen Sie sicher, dass Sie Tabellenberechtigungen in der Datenbank erstellen und die Berechtigung für das Schema ändern. | Nein | Schnur | stagingSchemaName |
| Pre- und Post-SQL-Skripts | Geben Sie mehrzeilige SQL-Skripts an, die vor (Vorverarbeitung) und nachdem die Daten in Ihre Senk-Datenbank geschrieben wurden (Nachverarbeitung), ausgeführt werden. | Nein | Schnur | preSQLs postSQLs |
Tipp
- Teilen sie einzelne Batchskripts mit mehreren Befehlen in mehrere Batches auf.
- In einem Batch können nur DDL- (Data Definition Language) und DML-Anweisungen (Data Manipulation Language) ausgeführt werden, die eine einfache Updatezählung zurückgeben. Weitere Informationen finden Sie unter Ausführen von Batchvorgängen.
Inkrementelles Extrahieren aktivieren: Verwenden Sie diese Option, um ADF anweisen, nur Zeilen zu verarbeiten, die seit der letzten Ausführung der Pipeline geändert wurden.
Inkrementelle Spalte: Wenn Sie die inkrementelle Extraktfunktion verwenden, müssen Sie die Datums-/Uhrzeitspalte oder numerische Spalte auswählen, die Sie als Wasserzeichen in der Quelltabelle verwenden möchten.
Beginnen Sie mit dem Lesen von Anfang: Wenn Sie diese Option mit inkrementeller Extraktion festlegen, weist dies ADF an, bei der ersten Ausführung einer Pipeline mit aktivierter inkrementeller Extraktion alle Zeilen zu lesen.
Azure Database for PostgreSQL: Beispiel für ein Senkenskript
Wenn Sie Azure Database for PostgreSQL als Sinktyp verwenden, lautet das zugehörige Datenflussskript:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSqlSink
Skriptaktivität
Von Bedeutung
Skriptaktivitäten werden nur im Connector der Version 2.0 unterstützt.
Von Bedeutung
Mehrfachabfrageanweisungen mit Ausgabeparametern werden nicht unterstützt. Es wird empfohlen, alle Ausgabeabfragen in separate Skriptblöcke innerhalb derselben oder unterschiedlicher Skriptaktivität aufzuteilen.
Mehrfachabfrageanweisungen mit Positionsparametern werden nicht unterstützt. Es wird empfohlen, alle Positionsabfragen in separate Skriptblöcke innerhalb derselben oder unterschiedlicher Skriptaktivität aufzuteilen.
Weitere Informationen zur Skriptaktivität finden Sie unter Skriptaktivität.
Eigenschaften der Lookup-Aktivität
Weitere Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität in Azure Data Factory.
Azure Database für PostgreSQL-Connector aktualisieren
Wählen Sie auf der Seite "Verknüpften Dienst bearbeiten " die Option 2.0 unter "Version " aus, und konfigurieren Sie den verknüpften Dienst, indem Sie auf die Verknüpften Diensteigenschaften Version 2.0 verweisen.
Verwandte Inhalte
Eine Liste der Datenspeicher, die als Quellen und Senken für die Kopieraktivität unterstützt werden, finden Sie unter Unterstützte Datenspeicher.