Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Databricks unterstützt die Verwendung verschiedener Programmiersprachen für entwicklung und Data Engineering. In diesem Artikel werden die verfügbaren Optionen beschrieben, in denen diese Sprachen verwendet werden können, und deren Einschränkungen.
Empfehlungen
Databricks empfiehlt Python und SQL für neue Projekte:
- Python ist eine sehr beliebte allgemeine Programmiersprache. PySpark DataFrames machen es einfach, testbare, modulare Transformationen zu erstellen. Das Python-Ökosystem unterstützt auch eine breite Palette von Bibliotheken zur Erweiterung Ihrer Lösung.
-
SQL ist eine sehr beliebte Sprache zum Verwalten und Bearbeiten relationaler Datasets durch Ausführen von Vorgängen wie Abfragen, Aktualisieren, Einfügen und Löschen von Daten. SQL ist eine gute Wahl, wenn sich Ihr Hintergrund in erster Linie in Datenbanken oder Data Warehouse befindet. SQL kann auch in Python mit
spark.sqleingebettet werden.
Die folgenden Sprachen haben eingeschränkte Unterstützung, sodass Databricks sie nicht für neue Data Engineering-Projekte empfiehlt:
- Scala ist die Sprache, die für die Entwicklung von Apache Spark™ verwendet wird.
- R wird nur in Databricks-Notizbüchern vollständig unterstützt.
Die Sprachunterstützung variiert auch je nach den Featurefunktionen, die zum Erstellen von Datenpipelines und anderen Lösungen verwendet werden. Beispielsweise unterstützt Lakeflow Spark Declarative Pipelines Python und SQL, während Workflows es Ihnen ermöglichen, Datenpipelinen mit Python, SQL, Scala und Java zu erstellen.
Hinweis
Andere Sprachen können verwendet werden, um mit Databricks zu interagieren, um Daten abzufragen oder Datentransformationen durchzuführen. Diese Interaktionen sind jedoch in erster Linie im Kontext von Integrationen mit externen Systemen. In diesen Fällen kann ein Entwickler fast jede Programmiersprache verwenden, um mit Databricks über die Databricks-REST-API, ODBC-/ODBC-TREIBER, bestimmte Sprachen mit Databricks SQL Connector-Unterstützung (Go, Python, Javascript/Node.js) oder Sprachen mit Spark Connect-Implementierungen wie Go und Rust zu interagieren.
Arbeitsbereichsentwicklung im Vergleich zur lokalen Entwicklung
Sie können Datenprojekte und Pipelines mithilfe des Databricks-Arbeitsbereichs oder einer IDE (integrierte Entwicklungsumgebung) auf Ihrem lokalen Computer entwickeln, aber das Starten neuer Projekte im Databricks-Arbeitsbereich wird empfohlen. Auf den Arbeitsbereich kann über einen Webbrowser zugegriffen werden, er bietet einfachen Zugriff auf Daten im Unity-Katalog und unterstützt leistungsstarke Debugfunktionen und -features wie den Genie Code.
Entwickeln Sie Code im Databricks-Arbeitsbereich mithilfe von Databricks-Notizbüchern oder dem SQL-Editor. Databricks-Notizbücher unterstützen auch innerhalb desselben Notizbuchs mehrere Programmiersprachen, sodass Sie mit Python, SQL und Scala entwickeln können.
Es gibt mehrere Vorteile, code direkt im Databricks-Arbeitsbereich zu entwickeln:
- Die Feedbackschleife ist schneller. Sie können sofort geschriebenen Code für reale Daten testen.
- Der integrierte, kontextabhängige Genie Code kann die Entwicklung beschleunigen und Dabei helfen, Probleme zu beheben.
- Sie können Notizbücher und Abfragen ganz einfach direkt aus dem Databricks-Arbeitsbereich planen.
- Für die Python-Entwicklung können Sie Ihren Python-Code richtig strukturieren, indem Sie Dateien als Python-Pakete in einem Arbeitsbereich verwenden.
Die lokale Entwicklung innerhalb einer IDE bietet jedoch die folgenden Vorteile:
- IDEs verfügen über bessere Tools zum Arbeiten mit Softwareprojekten, z. B. Navigation, Codeumgestaltung und statische Codeanalyse.
- Sie können auswählen, wie Sie Ihre Quelle steuern, und wenn Sie Git verwenden, sind erweiterte Funktionen lokal verfügbar als im Arbeitsbereich mit Git-Ordnern.
- Es gibt eine breitere Palette unterstützter Sprachen. Sie können z. B. Code mithilfe von Java entwickeln und als JAR-Aufgabe bereitstellen.
- Es gibt eine bessere Unterstützung für das Codedebugging.
- Es gibt eine bessere Unterstützung für die Arbeit mit Komponententests.
Beispiel für die Sprachauswahl
Die Sprachauswahl für datentechnische Daten wird mithilfe der folgenden Entscheidungsstruktur visualisiert:
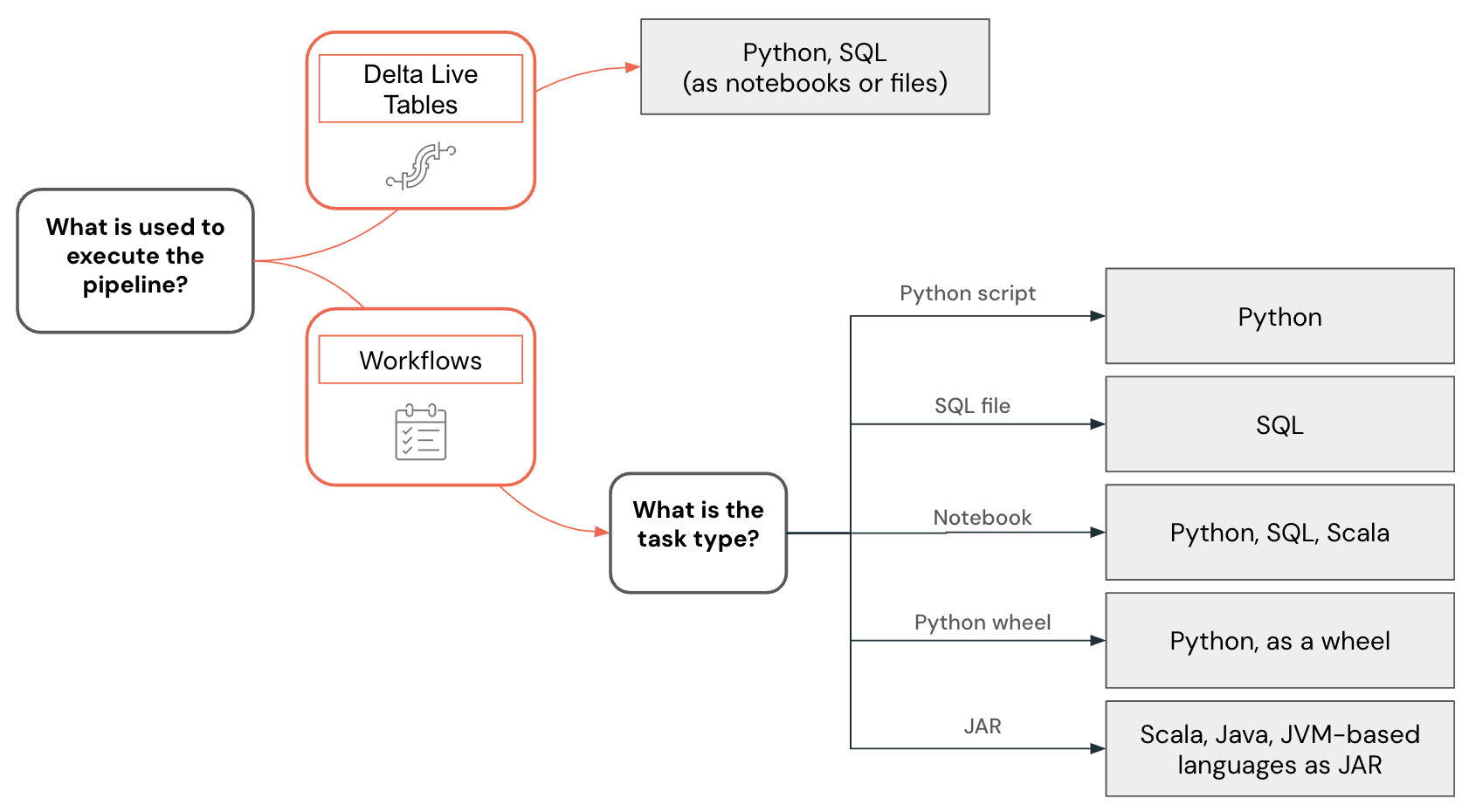
Entwickeln von Python-Code
Die Programmiersprache Python wird auf Databricks erstklassig unterstützt. Sie können es in Databricks-Notizbüchern, Lakeflow Spark Declarative Pipelines und Workflows verwenden, um UDFs zu entwickeln und sie auch als Python-Skript und als Räder bereitzustellen.
Bei der Entwicklung von Python-Projekten im Databricks-Arbeitsbereich, ob als Notizbücher oder in Dateien, stellt Databricks Tools wie Codeabschluss, Navigation, Syntaxüberprüfung, Codegenerierung mit Genie Code, interaktives Debuggen und vieles mehr bereit. Entwickelter Code kann interaktiv ausgeführt, als Databricks-Workflow oder als Lakeflow Spark Declarative Pipelines oder sogar als Funktion im Unity-Katalog bereitgestellt werden. Sie können Ihren Code strukturieren, indem Sie ihn in separate Python-Pakete aufteilen, die dann in mehreren Pipelines oder Aufträgen verwendet werden können.
Databricks bietet eine Erweiterung für Visual Studio Code und JetBrains bietet ein Plug-In für PyCharm , mit dem Sie Python-Code in einer IDE entwickeln, Code mit einem Databricks-Arbeitsbereich synchronisieren, es innerhalb des Arbeitsbereichs ausführen und schrittweises Debuggen mithilfe von Databricks Connect ausführen können. Der entwickelte Code kann dann mithilfe von Declarative Automation Bundles als Databricks-Auftrag oder Pipeline bereitgestellt werden.
Entwickeln von SQL-Code
Die SQL-Sprache kann in Databricks-Notizbüchern oder als Databricks-Abfragen mit dem SQL-Editor verwendet werden. In beiden Fällen erhält ein Entwickler Zugriff auf Tools wie die Code-Vervollständigung und den kontextbezogenen Genie Code, der für die Codegenerierung und das Beheben von Problemen verwendet werden kann. Der entwickelte Code kann als Job oder Pipeline bereitgestellt werden.
Mit Databricks-Workflows können Sie auch SQL-Code ausführen, der in einer Datei gespeichert ist. Sie können eine IDE verwenden, um diese Dateien zu erstellen und in den Arbeitsbereich hochzuladen. Eine weitere beliebte Verwendung von SQL ist in Data Engineering-Pipelines, die mit dbt (Data Build Tool) entwickelt wurden. Databricks-Workflows unterstützen die Orchestrierung von DBT-Projekten.
Entwickeln von Scala-Code
Scala ist die Originalsprache von Apache Spark™. Es ist eine mächtige Sprache, aber es hat eine steile Lernkurve. Obwohl Scala eine unterstützte Sprache in Databricks-Notizbüchern ist, gibt es einige Einschränkungen im Zusammenhang mit der Erstellung und Wartung von Scala-Klassen und -Objekten, die die Entwicklung komplexer Pipelines erschweren können. In der Regel bieten IDEs eine bessere Unterstützung für die Entwicklung von Scala-Code, der dann mithilfe von JAR-Aufgaben in Databricks-Workflows bereitgestellt werden kann.
Nächste Schritte
- Develop on Databricks ist ein Einstiegspunkt für Dokumentationen zu verschiedenen Entwicklungsoptionen für Databricks.
- Auf der Seite "Entwicklertools" werden unterschiedliche Entwicklungstools beschrieben, die verwendet werden können, um lokal für Databricks zu entwickeln, einschließlich deklarativer Automatisierungsbündel und Plug-Ins für IDEs.
- Das Entwickeln von Code in Databricks-Notizbüchern beschreibt, wie sie im Databricks-Arbeitsbereich mithilfe von Databricks-Notizbüchern entwickelt werden.
- Schreiben Sie Abfragen, und untersuchen Sie Daten im SQL-Editor. In diesem Artikel wird beschrieben, wie Sie den SQL-Editor von Databricks verwenden, um mit SQL-Code zu arbeiten.
- Die Entwicklung von Lakeflow Spark Declarative Pipelines beschreibt den Entwicklungsprozess für Lakeflow Spark Declarative Pipelines.
- Databricks Connect ermöglicht Es Ihnen, eine Verbindung mit Databricks-Clustern herzustellen und Code aus Ihrer lokalen Umgebung auszuführen.
- Erfahren Sie, wie Sie Genie Code für eine schnellere Entwicklung und zum Beheben von Codeproblemen verwenden.