Debuggen von fehlgeschlagenen Spark-Aufträgen mit dem Azure-Toolkit für IntelliJ (Vorschau)
Dieser Artikel enthält eine ausführliche Anleitung zur Verwendung der HDInsight-Tools im Azure-Toolkit für IntelliJ zum Ausführen von Anwendungen für das Debuggen von fehlgeschlagenen Spark-Aufträgen.
Voraussetzungen
Oracle Java Development Kit. In diesem Tutorial wird die Java-Version 8.0.202 verwendet.
IntelliJ IDEA. In diesem Artikel wird IntelliJ IDEA Community 2019.1.3 verwendet.
Azure-Toolkit für IntelliJ. Weitere Informationen finden Sie unter Installieren des Azure-Toolkits für IntelliJ.
Herstellen einer Verbindung mit Ihrem HDInsight-Cluster. Siehe Herstellen einer Verbindung mit Ihrem HDInsight-Cluster.
Microsoft Azure Storage-Explorer. Siehe Azure Storage-Explorer herunterladen.
Erstellen eines Projekts mit Debugvorlage
Erstellen Sie ein Spark 2.3.2-Projekt, um das Debuggen fortzusetzen. Verwenden Sie die Beispieldatei für das Debuggen von Aufgaben in diesem Dokument.
Öffnen Sie IntelliJ IDEA. Öffnen Sie das Fenster Neues Projekt.
a. Wählen Sie im linken Bereich Azure Spark/HDInsight aus.
b. Wählen Sie im Hauptfenster Spark-Projekt mit Beispielen zum Debuggen von Fehleraufgaben (Vorschau) (Scala) aus.
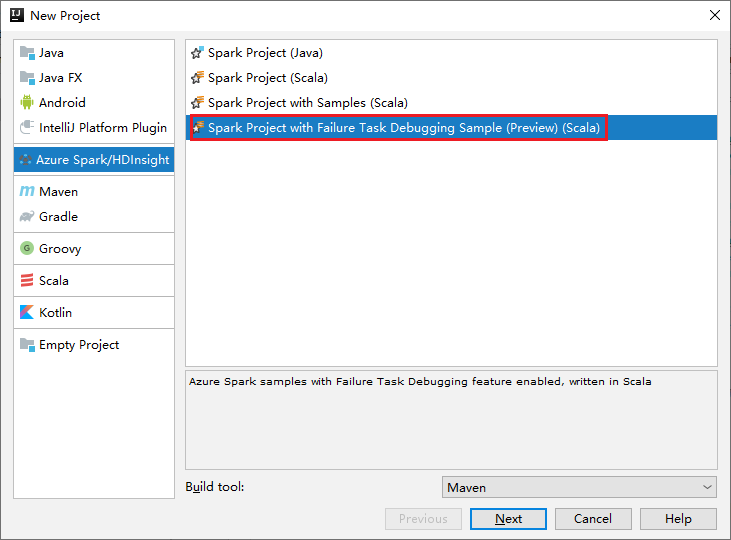
c. Wählen Sie Weiter aus.
Führen Sie im Fenster New Project (Neues Projekt) die folgenden Schritte aus:
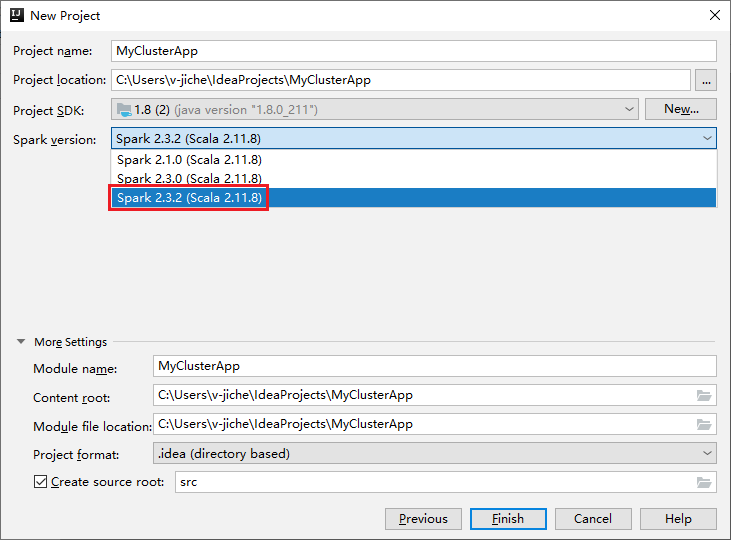
a. Geben Sie einen Projektnamen und -speicherort an.
b. Wählen Sie in der Dropdownliste Project SDK (Projekt-SDK) Java 1.8 für den Spark 2.3.2-Cluster aus.
c. Wählen Sie in der Dropdown-Liste Spark-Version den Eintrag Spark 2.3.2 (Scala 2.11.8) aus.
d. Wählen Sie Fertig stellen aus.
Wählen Sie src>main>scala aus, um Ihren Code im Projekt zu öffnen. In diesem Beispiel wird das Skript AgeMean_Div() verwendet.
Ausführen einer Spark Scala- bzw. einer Java-Anwendung in einem HDInsight-Cluster
Erstellen Sie eine Spark Scala- bzw. Java-Anwendung, und führen Sie die Anwendung dann in einem Spark-Cluster aus, indem Sie die folgenden Schritte ausführen:
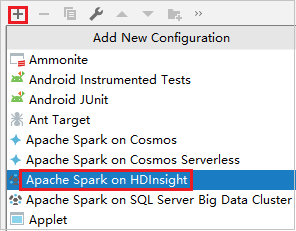
Klicken Sie auf Konfiguration hinzufügen, um das Fenster Run/Debug Configurations (Konfigurationen ausführen/debuggen) zu öffnen.

Wählen Sie im Dialogfeld Run/Debug Configurations (Konfigurationen ausführen/debuggen) das Plussymbol (+) aus. Wählen Sie dann die Option Apache Spark auf HDInsight aus.
Wechseln Sie zur Registerkarte Remotely Run in Cluster (Im Cluster remote ausführen). Geben Sie Informationen für Name, Spark cluster und Main class name (Name der main-Klasse) ein. Unseren Tools unterstützen das Debuggen mit Executors. Der Standardwert von numExectors ist 5. Es empfiehlt sich, hierfür keinen höheren Wert als 3 festzulegen. Wenn Sie die Laufzeit verkürzen möchten, können Sie spark.yarn.maxAppAttempts zu Job Configurations (Auftragskonfigurationen) hinzufügen und den Wert auf 1 festlegen. Klicken Sie auf OK, um die Konfiguration zu speichern.
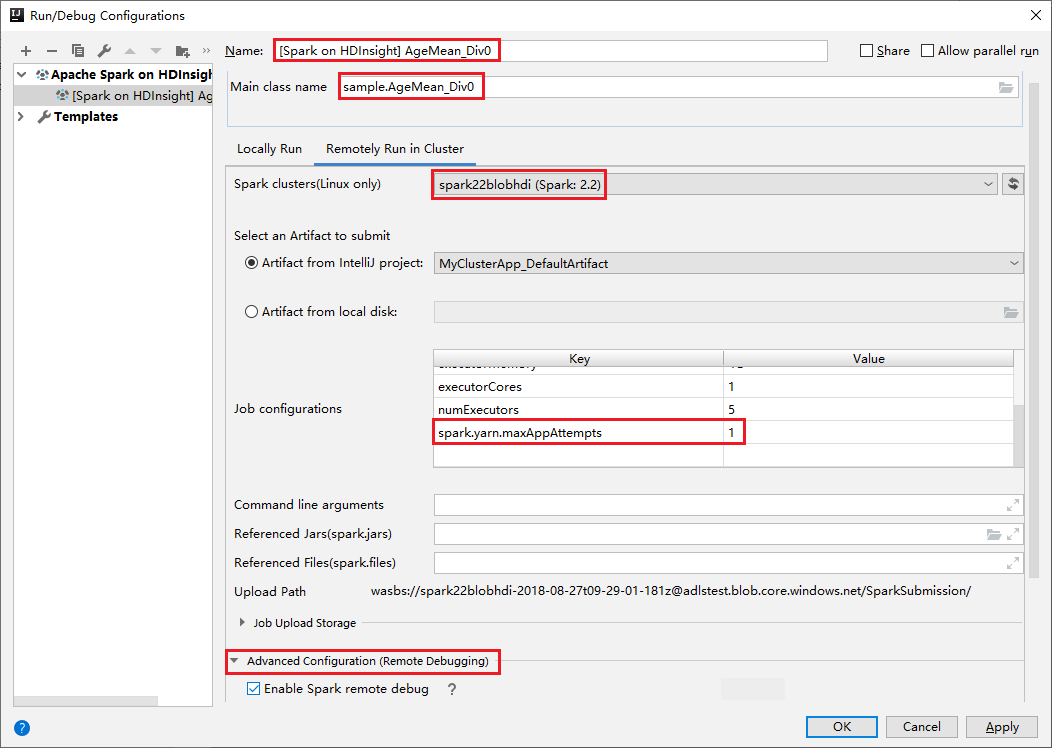
Die Konfiguration wird jetzt unter dem von Ihnen angegebenen Namen gespeichert. Um die Konfigurationsdetails anzuzeigen, wählen Sie den Konfigurationsnamen aus. Um Änderungen vorzunehmen, wählen Sie Edit Configurations (Konfigurationen bearbeiten) aus.
Nachdem Sie die Konfigurationseinstellungen abgeschlossen haben, können Sie das Projekt für den Remotecluster ausführen.

Sie können die Anwendungs-ID im Ausgabefenster überprüfen.

Herunterladen des Profils des fehlgeschlagenen Auftrags
Wenn die Auftragsübermittlung fehlschlägt, können Sie das Profil des fehlgeschlagenen Auftrags zum weiteren Debuggen auf den lokalen Computer herunterladen.
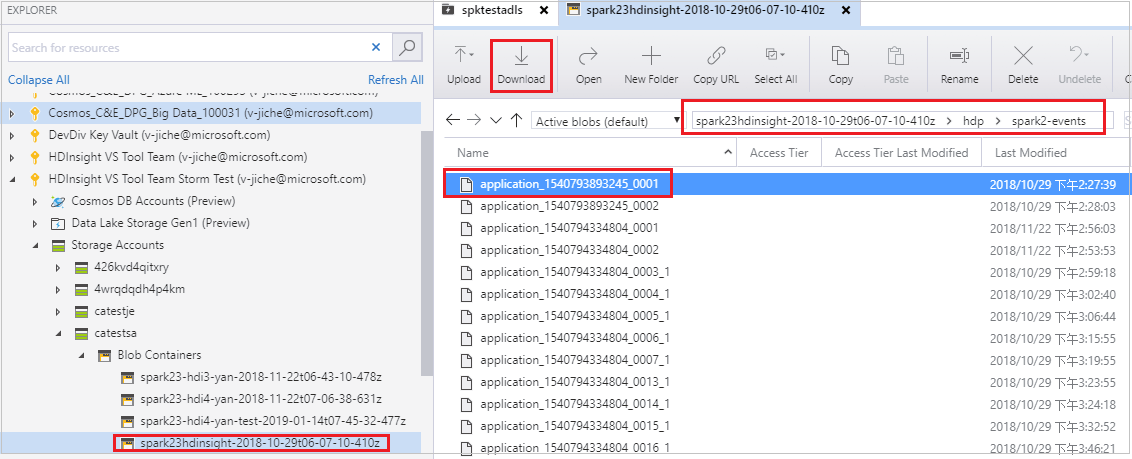
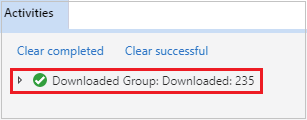
Öffnen Sie den Microsoft Azure Storage-Explorer, suchen Sie das HDInsight-Konto des Clusters mit dem fehlgeschlagenen Auftrag, und laden Sie die Ressourcen des fehlgeschlagenen Auftrags vom entsprechenden Speicherort (\hdp\spark2-events\.spark-failures\<Anwendungs-ID>) in einen lokalen Ordner herunter. Im Fenster Aktivitäten wird der Downloadfortschritt angezeigt.
Konfigurieren der lokalen Debugumgebung und Debuggen eines Fehlers
Öffnen Sie das ursprüngliche Projekt, oder erstellen Sie ein neues Projekt, und ordnen Sie es dem ursprünglichen Quellcode zu. Derzeit wird das Debuggen von Fehlern nur in der Spark 2.3.2-Version unterstützt.
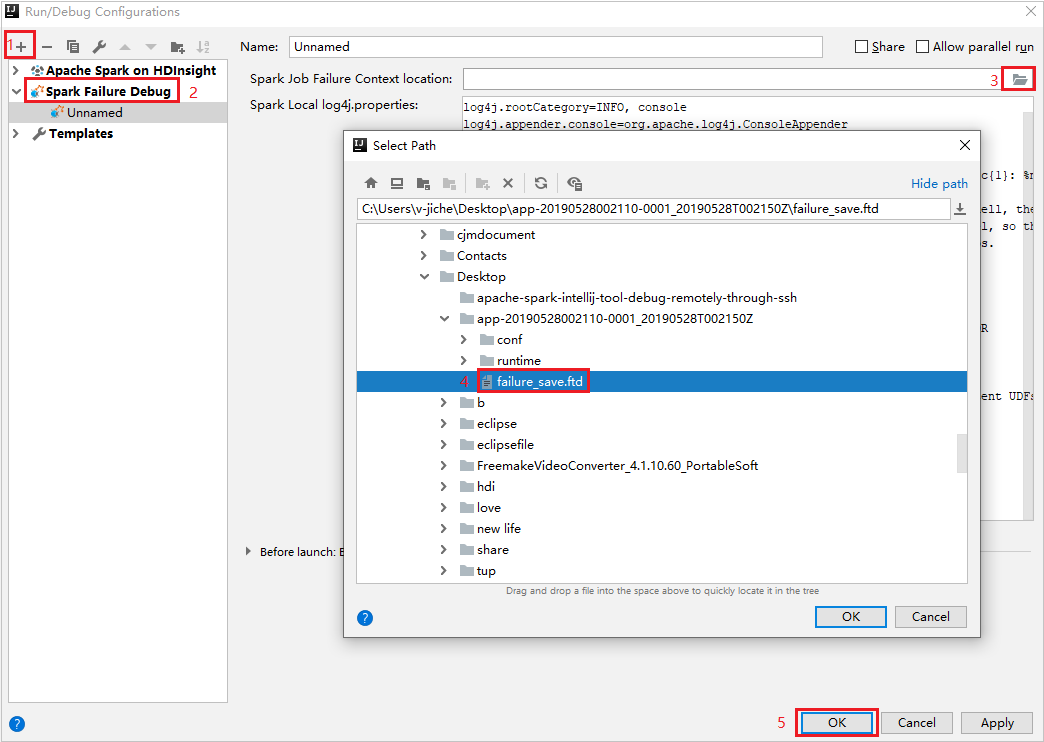
Erstellen Sie in IntelliJ IDEA unter Spark Failure Debug (Debuggen von Spark-Fehlern) eine Konfigurationsdatei, und wählen Sie für das Feld Spark Job Failure Context location (Speicherort des Fehlerkontexts für den Spark-Auftrag) die FTD-Datei für die zuvor heruntergeladenen Ressourcen des fehlgeschlagenen Auftrags aus.
Klicken Sie auf der Symbolleiste auf die Schaltfläche für lokales Ausführen, und der Fehler wird im Ausführungsfenster angezeigt.
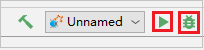
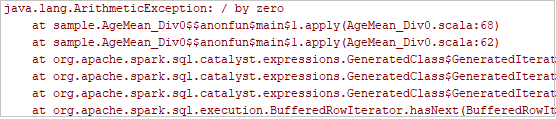
Legen Sie den im Protokoll angegebenen Haltepunkt fest, und klicken Sie dann auf die Schaltfläche für das lokale Debuggen, um das lokale Debuggen wie in normalen Scala-/Java-Projekten in IntelliJ auszuführen.
Wenn das Projekt nach dem Debuggen erfolgreich abgeschlossen wurde, können Sie den fehlgeschlagenen Auftrag erneut an Ihr Spark-Projekt im HDInsight-Cluster übermitteln.
Nächste Schritte
Szenarien
- Apache Spark mit BI: Durchführen interaktiver Datenanalysen mithilfe von Spark in HDInsight mit BI-Tools
- Apache Spark mit Machine Learning: Analysieren von Gebäudetemperaturen mithilfe von Spark in HDInsight und HVAC-Daten
- Apache Spark mit Machine Learning: Vorhersage von Lebensmittelkontrollergebnissen mithilfe von Spark in HDInsight
- Websiteprotokollanalyse mithilfe von Apache Spark in HDInsight
Erstellen und Ausführen von Anwendungen
- Erstellen einer eigenständigen Anwendung mit Scala
- Ausführen von Remoteaufträgen in einem Apache Spark-Cluster mithilfe von Apache Livy
Tools und Erweiterungen
- Erstellen von Apache Spark-Anwendungen für einen HDInsight-Cluster mit dem Azure-Toolkit für IntelliJ
- Verwenden des Azure-Toolkits für IntelliJ zum Remotedebuggen von Apache Spark-Anwendungen über VPN
- Verwenden der HDInsight-Tools im Azure-Toolkit für Eclipse zum Erstellen von Apache Spark-Anwendungen
- Verwenden von Apache Zeppelin Notebooks mit einem Apache Spark-Cluster unter HDInsight
- Verfügbare Kernels für Jupyter Notebooks in einem Apache Spark-Cluster für HDInsight
- Verwenden von externen Paketen mit Jupyter Notebooks
- Installieren von Jupyter Notebook auf Ihrem Computer und Herstellen einer Verbindung zum Apache Spark-Cluster in Azure HDInsight (Vorschau)