Verwenden des Azure-Toolkits für IntelliJ zum Remotedebuggen von Apache Spark-Anwendungen über VPN
Es wird empfohlen, für das Remotedebuggen von Apache Spark-Anwendungen SSH zu verwenden. Anweisungen finden Sie unter Remotedebuggen von Apache Spark-Anwendungen in einem HDInsight-Cluster mit dem Azure-Toolkit für IntelliJ über SSH.
Dieser Artikel enthält eine schrittweise Anleitung, in der erläutert wird, wie Sie mithilfe der HDInsight Tools im Azure-Toolkit für IntelliJ einen Spark-Auftrag in einem HDInsight Spark-Cluster senden und anschließend über den Desktopcomputer per Remotezugriff debuggen. Zum Durchführen dieser Aufgaben müssen Sie die folgenden allgemeinen Schritte ausführen:
- Erstellen Sie ein virtuelles Azure-Netzwerk vom Typ „Site-to-Site“ oder „Point-to-Site“. Für die Schritte in diesem Dokument wird vorausgesetzt, dass Sie ein Standort-zu-Standort-Netzwerk verwenden.
- Erstellen Sie einen Spark-Cluster in HDInsight, der Teil des virtuellen Site-to-Site-Netzwerks ist.
- Überprüfen Sie die Konnektivität zwischen dem Clusterhauptknoten und Ihrem Desktopcomputer.
- Erstellen Sie eine Scala-Anwendung in IntelliJ IDEA, und konfigurieren Sie sie anschließend für das Remotedebuggen.
- Stellen Sie die Anwendung bereit, und führen Sie das Debuggen durch.
Voraussetzungen
- Ein Azure-Abonnement. Weitere Informationen finden Sie im Artikel zur kostenlosen Azure-Testversion.
- Ein Apache Spark-Cluster in HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight.
- Oracle Java Development Kit. Sie können dieses von der Oracle-Website herunterladen und installieren.
- IntelliJ IDEA. In diesem Artikel wird die Version 2017.1 verwendet. Sie können diese IDE von der JetBrains-Website herunterladen und installieren.
- HDInsight-Tools im Azure-Toolkit für IntelliJ. Die HDInsight Tools für IntelliJ sind als Teil des Azure-Toolkits für IntelliJ verfügbar. Anweisungen zum Installieren des Azure-Toolkits finden Sie unter Installieren des Azure-Toolkits für IntelliJ.
- Melden Sie sich über IntelliJ IDEA bei Ihrem Azure-Abonnement an. Folgen Sie den Anweisungen unter Erstellen von Apache Spark-Anwendungen für einen HDInsight-Cluster mit dem Azure-Toolkit für IntelliJ.
- Ausnahmeproblemumgehung. Wenn Sie die Spark Scala-Anwendung zum Remotedebuggen auf einem Windows-Computer ausführen, wird unter Umständen eine Ausnahme angezeigt. Diese Ausnahme wird in SPARK-2356 erläutert und tritt aufgrund einer fehlenden Datei „WinUtils.exe“ in Windows auf. Um diesen Fehler zu umgehen, müssen Sie Winutils.exe herunterladen und an einem Speicherort wie C:\WinUtils\bin ablegen. Fügen Sie eine Umgebungsvariable HADOOP_HOME hinzu, und legen Sie den Wert der Variable dann auf C\WinUtils fest.
Schritt 1: Erstellen eines virtuellen Azure-Netzwerks
Führen Sie die Anweisungen unter den folgenden Links aus, um ein virtuelles Azure-Netzwerk zu erstellen, und überprüfen Sie anschließend die Konnektivität zwischen dem Desktopcomputer und dem virtuellen Netzwerk:
- Erstellen eines VNet mit einer Site-to-Site-VPN-Verbindung über das Azure-Portal
- Erstellen eines VNet mit einer Site-to-Site-VPN-Verbindung per PowerShell
- Konfigurieren einer Punkt-zu-Standort-VPN-Verbindung mit einem virtuellen Netzwerk mithilfe von PowerShell
Schritt 2: Erstellen eines HDInsight Spark-Clusters
Wir empfehlen, auch einen Apache Spark-Cluster in Azure HDInsight zu erstellen, der Teil des von Ihnen erstellten virtuellen Azure-Netzwerks ist. Verwenden Sie die im Artikel zum Erstellen von Linux-basierten Clustern in HDInsight verfügbaren Informationen. Wählen Sie als Teil der optionalen Konfiguration das virtuelle Azure-Netzwerk aus, das Sie im vorherigen Schritt erstellt haben.
Schritt 3: Überprüfen der Konnektivität zwischen dem Clusterhauptknoten und dem Desktopcomputer
Rufen Sie die IP-Adresse des Hauptknotens ab. Öffnen Sie die Ambari-Benutzeroberfläche für den Cluster. Klicken Sie auf dem Clusterblatt auf Dashboard.
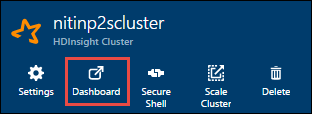
Wählen Sie in der Ambari-Benutzeroberfläche die Option Hosts aus.

Eine Liste mit Hauptknoten, Workerknoten und Zookeeper-Knoten wird angezeigt. Die Hauptknoten haben das Präfix hn\*. Wählen Sie den ersten Hauptknoten aus.
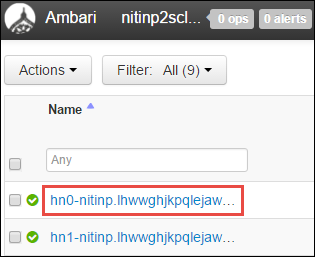
Kopieren Sie unten auf der angezeigten Seite im Bereich Summary (Zusammenfassung) die IP-Adresse des Hauptknotens und den Hostnamen.
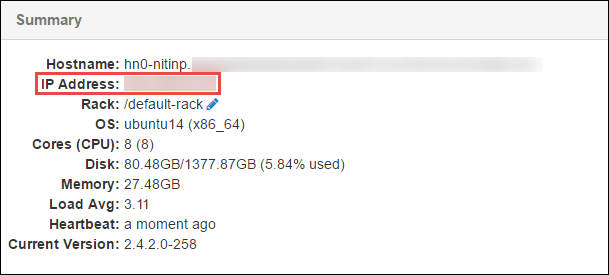
Fügen Sie die IP-Adresse und den Hostnamen des Hauptknotens der Datei hosts auf dem Computer hinzu, auf dem Sie den Spark-Auftrag ausführen und per Remotezugriff debuggen möchten. Auf diese Weise können Sie sowohl anhand der IP-Adresse als auch des Hostnamens mit dem Hauptknoten kommunizieren.
a. Öffnen Sie eine Editor-Datei mit erhöhten Rechten. Klicken Sie im Menü File (Datei) auf Open (Öffnen), und navigieren Sie zum Speicherort der Datei „hosts“. Auf einem Windows-Computer ist der Speicherort C:\Windows\System32\Drivers\etc\hosts.
b. Fügen Sie der Datei hosts die folgenden Informationen hinzu:
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netÜberprüfen Sie auf dem Computer, den Sie mit dem vom HDInsight-Cluster verwendeten virtuellen Azure-Netzwerk verbunden haben, ob Sie die Hauptknoten sowohl mit der IP-Adresse als auch dem Hostnamen pingen können.
Verwenden Sie SSH, um eine Verbindung mit dem Clusterhauptknoten herzustellen, indem Sie den Anweisungen unter Herstellen einer Verbindung mit HDInsight (Hadoop) per SSH folgen. Pingen Sie vom Clusterhauptknoten aus die IP-Adresse des Desktopcomputers. Testen Sie die Konnektivität mit beiden IP-Adressen, die dem Computer zugewiesen sind:
- Eine für die Netzwerkverbindung
- Eine für das virtuelle Azure-Netzwerk
Wiederholen Sie die Schritte für den anderen Hauptknoten.
Schritt 4: Erstellen einer Apache Spark Scala-Anwendung mit den HDInsight-Tools im Azure-Toolkit für IntelliJ und Konfigurieren der Anwendung für das Remotedebuggen
Öffnen Sie IntelliJ IDEA, und erstellen Sie ein neues Projekt. Führen Sie im Dialogfeld Neues Projekt folgende Schritte aus:
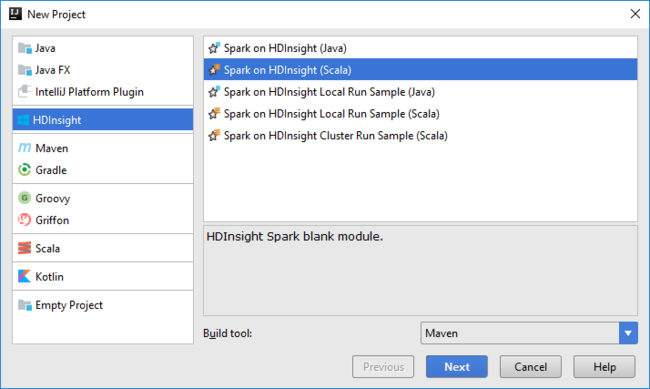
a. Wählen Sie HDInsight>Spark auf HDInsight (Scala) aus.
b. Wählen Sie Weiter aus.
Führen Sie im Dialogfeld New Project (Neues Projekt) die folgenden Schritte aus, und klicken Sie anschließend auf Finish (Fertig stellen):
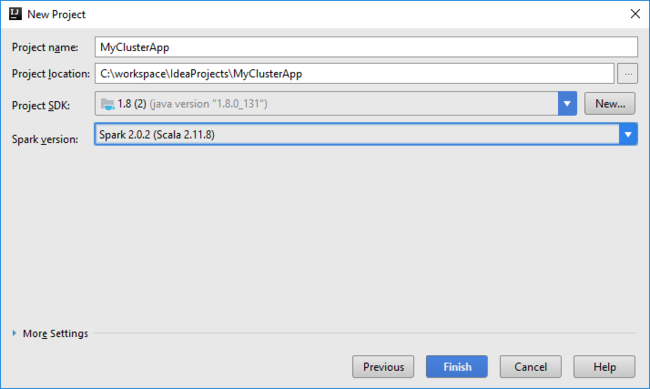
Geben Sie einen Projektnamen und einen Speicherort ein.
Wählen Sie in der Dropdownliste Project SDK (SDK für Projekt) Java 1.8 für den Spark 2.x-Cluster oder Java 1.7 für den Spark 1.x-Cluster aus.
In der Dropdownliste Spark version (Spark-Version) fügt der Scala-Projekterstellungs-Assistent die entsprechende Version für das Spark-SDK und das Scala-SDK ein. Wenn Sie eine ältere Spark-Clusterversion als 2.0 verwenden, wählen Sie Spark 1.x aus. Wählen Sie andernfalls Spark 2.x aus. In diesem Beispiel wird Spark 2.0.2 (Scala 2.11.8) verwendet.
Das Spark-Projekt erstellt automatisch ein Artefakt. Um das Artefakt anzuzeigen, gehen Sie folgendermaßen vor:
a. Wählen Sie im Menü File (Datei) die Option Project Structure (Projektstruktur) aus.
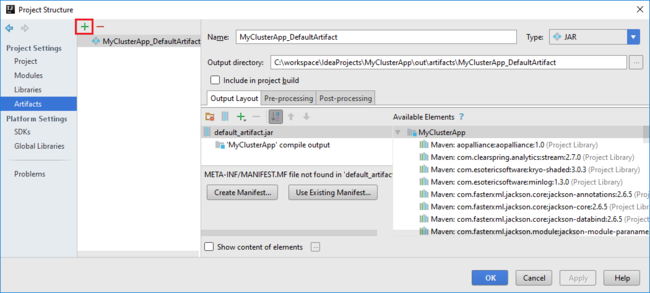
b. Klicken Sie im Dialogfeld Project Structure (Projektstruktur) auf Artifacts (Artefakte), um sich das erstellte Standardartefakt anzeigen zu lassen. Sie können auch ein eigenes Artefakt erstellen, indem Sie auf das Pluszeichen ( + ) klicken.
Fügen Sie dem Projekt Bibliotheken hinzu. Gehen Sie zum Hinzufügen einer Bibliothek wie folgt vor:
a. Klicken Sie in der Projektstruktur mit der rechten Maustaste auf den Projektnamen, und wählen Sie dann Open Module Settings (Moduleinstellungen öffnen) aus.
b. Wählen Sie im Dialogfeld Project Structure (Projektstruktur) die Option Libraries (Bibliotheken) aus, klicken Sie auf das Plussymbol ( + ), und wählen Sie dann From Maven (Aus Maven) aus.
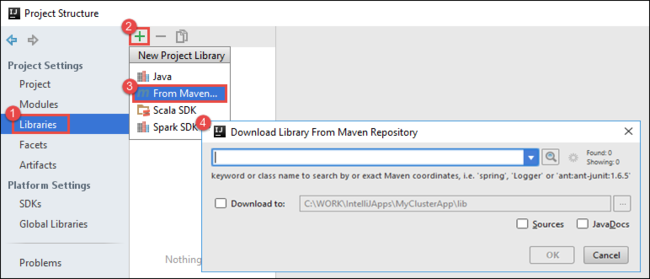
c. Suchen Sie im Dialogfeld Download Library from Maven Repository (Bibliothek aus Maven-Repository herunterladen) nach den folgenden Bibliotheken, und fügen Sie sie hinzu:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Kopieren Sie
yarn-site.xmlundcore-site.xmlvom Clusterhauptknoten, und fügen Sie die Dateien dem Projekt hinzu. Führen Sie die folgenden Befehle aus, um die Dateien zu kopieren: Sie können Cygwin verwenden, um die folgendenscp-Befehle zum Kopieren der Dateien vom Clusterhauptknoten auszuführen:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Da wir die IP-Adresse und den Hostnamen des Clusterhauptknotens für die Datei „hosts“ auf dem Desktopcomputer bereits hinzugefügt haben, können wir die
scp-Befehle wie folgt verwenden:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Kopieren Sie diese Dateien in den Ordner /src der Projektstruktur (z. B.
<your project directory>\src), um sie dem Projekt hinzuzufügen.Aktualisieren Sie die Datei
core-site.xml, um die folgenden Änderungen vorzunehmen:a. Ersetzen Sie den verschlüsselten Schlüssel. Die Datei
core-site.xmlenthält den verschlüsselten Schlüssel für das Speicherkonto, das dem Cluster zugeordnet ist. Ersetzen Sie in der Dateicore-site.xml, die Sie dem Projekt hinzugefügt haben, den verschlüsselten Schlüssel durch den tatsächlichen Speicherschlüssel, der dem Standardspeicherkonto zugeordnet ist. Weitere Informationen finden Sie unter Verwalten von Speicherkonto-Zugriffsschlüsseln.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. Entfernen Sie die folgenden Einträge aus der Datei
core-site.xml:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. Speichern Sie die Datei .
Fügen Sie die Hauptklasse für Ihre Anwendung hinzu. Klicken Sie im Projekt-Explorer (Projekt-Explorer) mit der rechten Maustaste auf src, zeigen Sie auf New (Neu), und wählen Sie dann Scala Class (Scala-Klasse) aus.
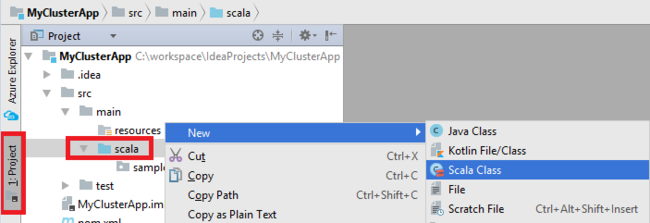
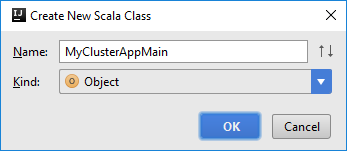
Geben Sie im Dialogfeld Create New Scala Class (Neue Scala-Klasse erstellen) einen Namen ein. Wählen Sie unter Kind (Art) die Option Object aus, und wählen Sie dann OK aus.
Fügen Sie den folgenden Code in die Datei
MyClusterAppMain.scalaein. Dieser Code erstellt den Spark-Kontext und öffnet über dasSparkSample-Objekt eineexecuteJob-Methode.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Wiederholen Sie die Schritte 8 und 9, um ein neues Scala-Objekt mit dem Namen
*SparkSamplehinzuzufügen. Fügen Sie dieser Klasse den folgenden Code hinzu. Dieser Code liest die Daten aus der Datei „HVAC.csv“ (verfügbar in allen HDInsight Spark-Clustern). Er ruft die Zeilen ab, die nur eine Ziffer in der siebten Spalte der CSV-Datei enthalten, und schreibt die Ausgabe dann in /HVACOut unter dem Standardspeichercontainer für den Cluster.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }Wiederholen Sie die Schritte 8 und 9, um eine neue Klasse mit dem Namen
RemoteClusterDebugginghinzuzufügen. Diese Klasse implementiert das Spark-Testframework, das zum Debuggen der Anwendungen verwendet wird. Fügen Sie derRemoteClusterDebugging-Klasse den folgenden Code hinzu:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Hierbei sind einige wichtige Punkte zu beachten:
- Stellen Sie für
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar")sicher, dass die Spark-Assembly-JAR-Datei im Clusterspeicher unter dem angegebenen Pfad verfügbar ist. - Geben Sie für
setJarsden Speicherort an, an dem die Artefakt-JAR-Datei erstellt wird. Normalerweise ist dies<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jar.
- Stellen Sie für
Klicken Sie in der
*RemoteClusterDebugging-Klasse mit der rechten Maustaste auf das Schlüsselworttest, und wählen Sie anschließend Create RemoteClusterDebugging Configuration (RemoteClusterDebugging-Konfiguration erstellen) aus.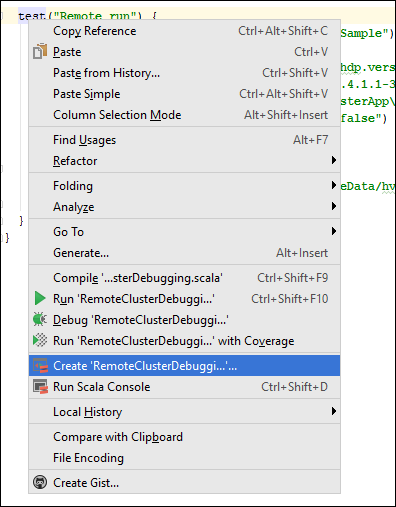
Geben Sie im Dialogfeld Create RemoteClusterDebugging Configuration (RemoteClusterDebugging-Konfiguration erstellen) einen Namen für die Konfiguration an, und wählen Sie dann Test kind (Testvariante) als Test name (Testname) aus. Übernehmen Sie für alle anderen Werte die Standardeinstellungen. Klicken Sie auf Apply (Anwenden) und dann auf OK.
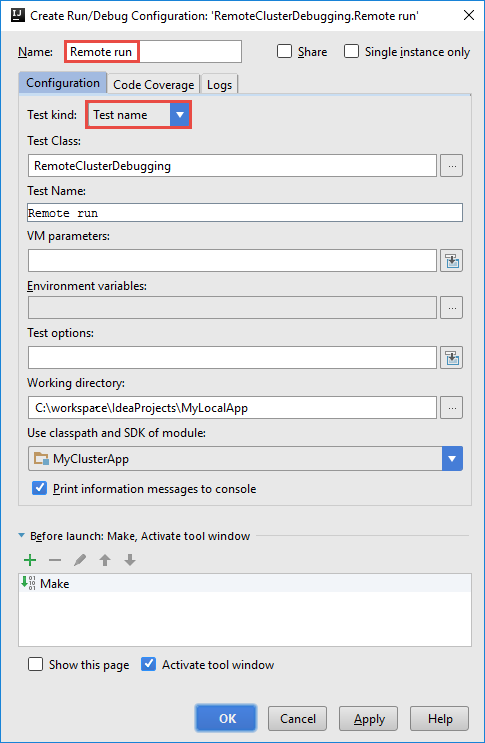
In der Menüleiste sollte nun eine Dropdownliste Remote run (Remotetestlauf) für die Konfiguration angezeigt werden.

Schritt 5: Ausführen der Anwendung im Debugmodus
Öffnen Sie im IntelliJ IDEA-Projekt die Datei
SparkSample.scala, und erstellen Sie nebenval rdd1einen Breakpoint. Wählen Sie im Popupmenü Create Breakpoint for (Breakpoint erstellen für) die Option line in function executeJob (Zeile in executeJob-Funktion) aus.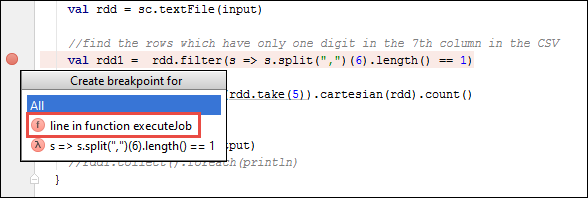
Klicken Sie zum Ausführen der Anwendung neben der Dropdownliste Remote Run (Remotetestlauf) für die Konfiguration auf die Schaltfläche Debug Run (Debugausführung).

Wenn die Programmausführung den Breakpoint erreicht, wird im unteren Bereich die Registerkarte Debugger angezeigt.
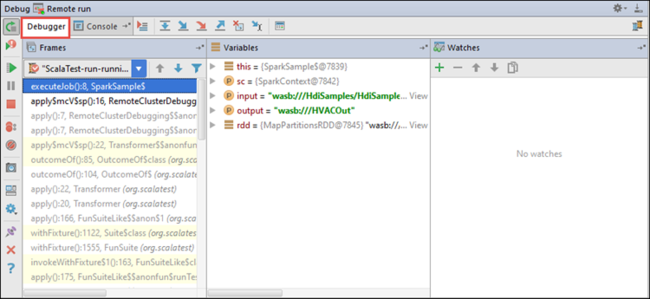
Klicken Sie zum Hinzufügen eines Überwachungselements auf das Plussymbol ( + ).
In diesem Beispiel wurde die Anwendung unterbrochen, bevor die
rdd1-Variable erstellt wurde. Mithilfe dieses Überwachungselements können wir die ersten fünf Zeilen in derrdd-Variablen anzeigen. Drücken Sie die EINGABETASTE.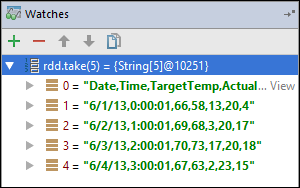
Wie Sie in der obigen Abbildung sehen, können Sie zur Laufzeit Terabytes von Daten abfragen und den Ablauf der Anwendung debuggen. In der Ausgabe in der vorherigen Abbildung können Sie beispielsweise sehen, dass die erste Zeile der Ausgabe ein Header ist. Basierend auf dieser Ausgabe können Sie bei Bedarf den Anwendungscode ändern, um die Headerzeile zu überspringen.
Nun können Sie auf das Symbol Resume Program (Programm fortsetzen) klicken, um die Ausführung der Anwendung fortzusetzen.
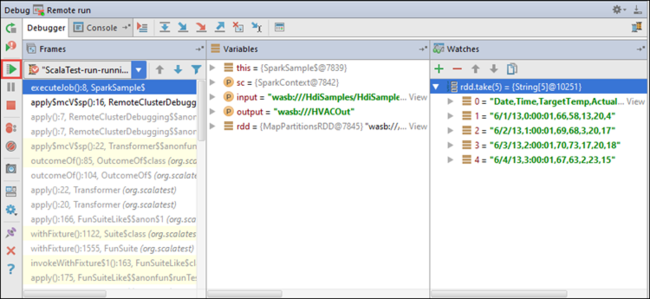
Wenn die Ausführung der Anwendung erfolgreich abgeschlossen wird, sollte eine Ausgabe der folgenden Art angezeigt werden:
Nächste Schritte
Szenarien
- Apache Spark mit BI: Durchführen interaktiver Datenanalysen mithilfe von Spark in HDInsight mit BI-Tools
- Apache Spark mit Machine Learning: Analysieren von Gebäudetemperaturen mithilfe von Spark in HDInsight und HVAC-Daten
- Apache Spark mit Machine Learning: Vorhersage von Lebensmittelkontrollergebnissen mithilfe von Spark in HDInsight
- Websiteprotokollanalyse mithilfe von Apache Spark in HDInsight
Erstellen und Ausführen von Anwendungen
- Erstellen einer eigenständigen Anwendung mit Scala
- Ausführen von Remoteaufträgen in einem Apache Spark-Cluster mithilfe von Apache Livy
Tools und Erweiterungen
- Erstellen von Apache Spark-Anwendungen für einen HDInsight-Cluster mit dem Azure-Toolkit für IntelliJ
- Verwenden des Azure-Toolkits für IntelliJ zum Remotedebuggen von Apache Spark-Anwendungen über SSH
- Verwenden der HDInsight-Tools im Azure-Toolkit für Eclipse zum Erstellen von Apache Spark-Anwendungen
- Verwenden von Apache Zeppelin Notebooks mit einem Apache Spark-Cluster in HDInsight
- Verfügbare Kernels für Jupyter Notebooks in einem Apache Spark-Cluster für HDInsight
- Verwenden von externen Paketen mit Jupyter Notebooks
- Installieren von Jupyter Notebook auf Ihrem Computer und Herstellen einer Verbindung zum Apache Spark-Cluster in Azure HDInsight (Vorschau)