Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Mit Azure Machine Learning-Registrierungen können Sie in Ihrer Organisation über Arbeitsbereiche hinweg zusammenarbeiten. Mithilfe von Registrierungen können Sie Modelle, Komponenten und Umgebungen freigeben.
Es gibt zwei Szenarien, in denen Sie dieselbe Gruppe von Modellen, Komponenten und Umgebungen in mehreren Arbeitsbereichen verwenden möchten:
- Arbeitsbereichsübergreifende MLOps: Sie trainieren ein Modell in einem
dev-Arbeitsbereich und müssen es intest- undprod-Arbeitsbereichen bereitstellen. In diesem Fall möchten Sie eine End-to-End-Linie zwischen Endpunkten haben, zu denen das Modell intestoderprodarbeitsbereichen bereitgestellt wird, sowie den Schulungsauftrag, Metriken, Code, Daten und Umgebung, die zum Trainieren des Modells imdevArbeitsbereich verwendet wurde. - Freigeben und Wiederverwenden von Modellen und Pipelines in verschiedenen Teams: Durch Teilen und Wiederverwenden werden Zusammenarbeit und Produktivität verbessert. In diesem Szenario möchten Sie möglicherweise ein trainiertes Modell und die zugeordneten zum Trainieren genutzten Komponenten und Umgebungen in einen zentralen Katalog veröffentlichen. Von dort aus können Kollegen aus anderen Teams die Ressourcen, die Sie freigegeben haben, durchsuchen und in ihren eigenen Experimenten wiederverwenden.
In diesem Artikel erfahren Sie, wie Sie:
- Erstellen einer Umgebung und Komponente in der Registrierung.
- Verwenden der Komponente aus der Registrierung zum Übermitteln eines Modelltrainingsauftrags in einen Arbeitsbereich.
- Registrieren des trainierten Modells in der Registrierung.
- Bereitstellen des Modells aus der Registrierung auf einem Onlineendpunkt im Arbeitsbereich und anschließendes Übermitteln einer Rückschlussanforderung.
Voraussetzungen
Stellen Sie vor dem Ausführen der Schritte in diesem Artikel sicher, dass Sie über die folgenden erforderlichen Komponenten verfügen:
- Ein Azure-Abonnement. Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
Eine Azure Machine Learning-Registrierung zum Freigeben von Modellen, Komponenten und Umgebungen. Informationen zum Erstellen einer Registrierung finden Sie unter Informationen zum Erstellen einer Registrierung.
Ein Azure Machine Learning-Arbeitsbereich. Führen Sie die Schritte im Schnellstartartikel: Arbeitsbereichsressourcen erstellen aus, um eines zu erstellen, falls Sie keines haben.
Wichtig
Die Azure-Region (Standort), in der Sie Ihren Arbeitsbereich erstellen, muss sich in der Liste der unterstützten Regionen für die Azure Machine Learning-Registrierung befinden.
Die Azure CLI und die
ml-Erweiterung oder das Azure Machine Learning Python SDK v2:Informationen zum Installieren der Azure CLI und der Erweiterung finden Sie unter Installieren, Einrichten und Verwenden der CLI (v2).
Wichtig
In den CLI-Beispielen in diesem Artikel wird davon ausgegangen, dass Sie die Bash-Shell (oder eine kompatible Shell) verwenden, beispielsweise über ein Linux-System oder ein Windows-Subsystem für Linux.
In den Beispielen wird auch davon ausgegangen, dass Sie Standardwerte für die Azure CLI konfiguriert haben, damit Sie die Parameter für Ihr Abonnement, Ihren Arbeitsbereich, Ihre Ressourcengruppe oder Ihren Standort nicht angeben müssen. Verwenden Sie zum Festlegen von Standardeinstellungen die folgenden Befehle. Ersetzen Sie die folgenden Parameter durch die Werte für Ihre Konfiguration:
- Ersetzen Sie
<subscription>durch Ihre Azure-Abonnement-ID. - Ersetzen Sie
<workspace>durch den Namen Ihres Azure Machine Learning-Arbeitsbereichs. - Ersetzen Sie
<resource-group>durch die Azure-Ressourcengruppe, die Ihren Arbeitsbereich enthält. - Ersetzen Sie
<location>durch die Azure-Region, die Ihren Arbeitsbereich enthält.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Mit dem Befehl
az configure -lkönnen Sie die aktuellen Standardwerte anzeigen.- Ersetzen Sie
Repository für Klonbeispiele
Die Codebeispiele in diesem Artikel basieren auf dem nyc_taxi_data_regression-Beispiel im Beispielrepository. Wenn Sie diese Dateien in Ihrer Entwicklungsumgebung verwenden möchten, klonen Sie das Repository, und ändern Sie die Verzeichnisse in das Beispiel mit den folgenden Befehlen:
git clone https://github.com/Azure/azureml-examples
cd azureml-examples
Ändern Sie für das CLI-Beispiel Verzeichnisse cli/jobs/pipelines-with-components/nyc_taxi_data_regression in Ihrem lokalen Klon des Beispielrepositorys.
cd cli/jobs/pipelines-with-components/nyc_taxi_data_regression
Erstellen einer SDK-Verbindung
Tipp
Dieser Schritt ist nur erforderlich, wenn das Python SDK verwendet wird.
Erstellen Sie eine Clientverbindung sowohl mit dem Azure Machine Learning-Arbeitsbereich als auch mit der Azure Machine Learning-Registrierung:
ml_client_workspace = MLClient( credential=credential,
subscription_id = "<workspace-subscription>",
resource_group_name = "<workspace-resource-group",
workspace_name = "<workspace-name>")
print(ml_client_workspace)
ml_client_registry = MLClient(credential=credential,
registry_name="<REGISTRY_NAME>",
registry_location="<REGISTRY_REGION>")
print(ml_client_registry)
Erstellen einer Umgebung in der Registrierung
Umgebungen definieren die Abhängigkeiten von Docker-Containern und Python, die zum Ausführen von Trainingsaufträgen oder Bereitstellen von Modellen erforderlich sind. Weitere Informationen zu Umgebungen finden Sie in den folgenden Artikeln:
Tipp
Der gleiche CLI-Befehl az ml environment create kann verwendet werden, um Umgebungen in einem Arbeitsbereich oder einer Registrierung zu erstellen. Wenn Sie den Befehl mit dem Befehl --workspace-name ausführen, wird die Umgebung in einem Arbeitsbereich erstellt. Ausführen des Befehls mit --registry-name erstellt die Umgebung in der Registrierung.
Wir erstellen eine Umgebung, die das python:3.8 Docker-Image verwendet und Python-Pakete installiert, die zum Ausführen eines Schulungsauftrags mit dem SciKit Learn-Framework erforderlich sind. Wenn Sie das Beispiel-Repository geklont haben und sich im Ordner cli/jobs/pipelines-with-components/nyc_taxi_data_regressionbefinden, sollten Sie die Umgebungsdefinitionsdatei env_train.yml anzeigen können, die auf die Docker-Datei env_train/Dockerfileverweist. Der Inhalt lautet env_train.yml wie folgt:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: SKLearnEnv
version: 1
build:
path: ./env_train
Erstellen der Umgebung mit az ml environment create wie folgt
az ml environment create --file env_train.yml --registry-name <registry-name>
Wenn Sie einen Fehler erhalten, dass eine Umgebung mit diesem Namen und dieser Version bereits in der Registrierung vorhanden ist, können Sie entweder das Feld version in env_train.yml bearbeiten oder eine andere Version in der Befehlszeilenschnittstelle angeben, die den Versionswert in env_train.yml außer Kraft setzt.
# use shell epoch time as the version
version=$(date +%s)
az ml environment create --file env_train.yml --registry-name <registry-name> --set version=$version
Tipp
version=$(date +%s) funktioniert nur unter Linux. Ersetzen Sie $version diese durch eine Zufallszahl, wenn dies nicht funktioniert.
Notieren Sie sich den name und die version der Umgebung aus der Ausgabe des Befehls az ml environment create, und verwenden Sie sie mit den Befehlen az ml environment show wie folgt. Sie benötigen den name und die version im nächsten Abschnitt, wenn Sie eine Komponente in der Registrierung erstellen.
az ml environment show --name SKLearnEnv --version 1 --registry-name <registry-name>
Tipp
Wenn Sie einen anderen Umgebungsnamen oder eine andere Version verwendet haben, ersetzen Sie die Parameter --name und --version entsprechend.
Sie können auch mit az ml environment list --registry-name <registry-name> alle Umgebungen in der Registrierung auflisten.
Sie können alle Umgebungen in Azure Machine Learning Studio durchsuchen. Navigieren Sie zur globalen Benutzeroberfläche, und suchen Sie nach dem Eintrag Registries.

Erstellen einer Komponente in der Registrierung
Komponenten sind wiederverwendbare Bausteine von Machine Learning-Pipelines in Azure Machine Learning. Sie können den Code, den Befehl, die Umgebung, die Eingabeschnittstelle und die Ausgabeschnittstelle eines einzelnen Pipelineschritts in eine Komponente packen. Anschließend können Sie die Komponente über mehrere Pipelines hinweg wiederverwenden, ohne sich Gedanken über das Portieren von Abhängigkeiten und Code bei jedem Schreiben einer anderen Pipeline zu machen.
Durch das Erstellen einer Komponente in einem Arbeitsbereich können Sie die Komponente in jedem Pipelineauftrag innerhalb dieses Arbeitsbereichs verwenden. Durch das Erstellen einer Komponente in einer Registrierung können Sie die Komponente in jedem Arbeitsbereich innerhalb Ihrer Organisation verwenden. Das Erstellen von Komponenten in einer Registrierung ist eine gute Möglichkeit, modulare, wiederverwendbare Hilfsprogramme oder freigegebene Trainingsaufgaben zu erstellen, die für Experimente von verschiedenen Teams innerhalb Ihrer Organisation verwendet werden können.
Weitere Informationen zu Komponenten finden Sie in den folgenden Artikeln:
Verwenden von Komponenten in Pipelines (Befehlszeilenschnittstelle)
Verwenden von Komponenten in Pipelines (SDK)
Wichtig
Die Registrierung unterstützt nur benannte Objekte (data/model/component/environment). Um auf ein Objekt in einer Registrierung zu verweisen, müssen Sie es zuerst in der Registrierung erstellen. Beachten Sie insbesondere bei Pipelinekomponenten Folgendes: Wenn Sie auf eine Komponente oder eine Umgebung in der Pipelinekomponente verweisen möchten, müssen Sie die Komponente oder Umgebung zuerst in der Registrierung erstellen.
Stellen Sie sicher, dass Sie sich im Ordner cli/jobs/pipelines-with-components/nyc_taxi_data_regression befinden. Sie finden die Komponentendefinitionsdatei train.yml , die ein Scikit Learn-Schulungsskript train_src/train.py und die kuratierte UmgebungAzureML-sklearn-0.24-ubuntu18.04-py37-cpu enthält. Wir verwenden die Scikit Learn-Umgebung, die in mühsamen Schritten anstelle der kuratierten Umgebung erstellt wurde. Sie können das Feld environment in train.yml bearbeiten, um auf Ihre Scikit-learn-Umgebung zu verweisen. Die resultierende Komponentendefinitionsdatei train.yml ähnelt dem folgenden Beispiel:
# <component>
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_linear_regression_model
display_name: TrainLinearRegressionModel
version: 1
type: command
inputs:
training_data:
type: uri_folder
test_split_ratio:
type: number
min: 0
max: 1
default: 0.2
outputs:
model_output:
type: mlflow_model
test_data:
type: uri_folder
code: ./train_src
environment: azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1`
command: >-
python train.py
--training_data ${{inputs.training_data}}
--test_data ${{outputs.test_data}}
--model_output ${{outputs.model_output}}
--test_split_ratio ${{inputs.test_split_ratio}}
Wenn Sie einen anderen Namen oder eine andere Version verwendet haben, sieht die Darstellung allgemeiner wie folgt aus: environment: azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>. Stellen Sie daher sicher, dass Sie <registry-name>, <sklearn-environment-name> und <sklearn-environment-version> entsprechend ersetzen. Anschließend führen Sie wie folgt den Befehl az ml component create aus, um die Komponente zu erstellen.
az ml component create --file train.yml --registry-name <registry-name>
Tipp
Derselbe CLI-Befehl az ml component create kann zum Erstellen von Komponenten in einem Arbeitsbereich oder in einer Registrierung verwendet werden. Wenn Sie den Befehl mit dem Befehl --workspace-name ausführen, wird die Komponente in einem Arbeitsbereich erstellt. Ausführen des Befehls mit --registry-name erstellt die Komponente in der Registrierung.
Wenn Sie train.yml lieber nicht bearbeiten möchten, können Sie den Umgebungsnamen in der Befehlszeilenschnittstelle wie folgt außer Kraft setzen:
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1
# or if you used a different name or version, replace `<sklearn-environment-name>` and `<sklearn-environment-version>` accordingly
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>
Tipp
Wenn Sie einen Fehler erhalten, dass der Name der Komponente bereits in der Registrierung vorhanden ist, können Sie die Version in train.yml bearbeiten oder sie in der CLI durch eine zufällige Version außer Kraft setzen.
Notieren Sie sich den name und die version der Komponente aus der Ausgabe des Befehls az ml component create, und verwenden Sie sie mit den Befehlen az ml component show wie folgt. Sie benötigen den name und die version im nächsten Abschnitt, wenn Sie einen Trainingsauftrag im Arbeitsbereich erstellen.
az ml component show --name <component_name> --version <component_version> --registry-name <registry-name>
Sie können auch mit az ml component list --registry-name <registry-name> alle Komponenten in der Registrierung auflisten.
Sie können alle Komponenten in Azure Machine Learning Studio durchsuchen. Navigieren Sie zur globalen Benutzeroberfläche, und suchen Sie nach dem Eintrag Registries.

Ausführen eines Pipelineauftrags in einem Arbeitsbereich mithilfe einer Komponente aus der Registrierung
Wenn Sie einen Pipelineauftrag ausführen, der eine Komponente aus einer Registrierung verwendet, sind die Computeressourcen und Trainingsdaten lokal für den Arbeitsbereich. Weitere Informationen zum Ausführen von Aufträgen finden Sie in den folgenden Artikeln:
- Ausführen von Aufträgen (Befehlszeilenschnittstelle)
- Ausführen von Aufträgen (SDK)
- Pipelineaufträge mit Komponenten (Befehlszeilenschnittstelle)
- Pipelineaufträge mit Komponenten (SDK)
Wir führen einen Pipelineauftrag mit der im vorherigen Abschnitt erstellten Scikit-learn-Trainingskomponente aus, um ein Modell zu trainieren. Überprüfen Sie, ob Sie sich im Ordner cli/jobs/pipelines-with-components/nyc_taxi_data_regression befinden. Das Trainingsdataset befindet sich im Ordner data_transformed. Bearbeiten Sie den Abschnitt component im Abschnitt train_job der Datei single-job-pipeline.yml, um auf die im vorherigen Abschnitt erstellte Trainingskomponente zu verweisen. Das Ergebnis single-job-pipeline.yml lautet wie folgt:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: nyc_taxi_data_regression_single_job
description: Single job pipeline to train regression model based on nyc taxi dataset
jobs:
train_job:
type: command
component: azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
compute: azureml:cpu-cluster
inputs:
training_data:
type: uri_folder
path: ./data_transformed
outputs:
model_output:
type: mlflow_model
test_data:
Der wichtigste Aspekt besteht darin, dass diese Pipeline in einem Arbeitsbereich unter Verwendung einer Komponente ausgeführt wird, die sich nicht in einem bestimmten Arbeitsbereich befindet. Die Komponente befindet sich in einer Registrierung, die mit jedem Arbeitsbereich in Ihrer Organisation verwendet werden kann. Sie können diesen Trainingsauftrag in jedem Arbeitsbereich ausführen, auf den Sie Zugriff haben, ohne sich Gedanken darüber zu machen, ob der Trainingscode und die Umgebung in diesem Arbeitsbereich verfügbar sind.
Warnung
- Vergewissern Sie sich vor dem Ausführen des Pipelineauftrags, dass sich der Arbeitsbereich, in dem Sie den Auftrag ausführen, in einer Azure-Region befindet, die von der Registrierung unterstützt wird, in der Sie die Komponente erstellt haben.
- Vergewissern Sie sich, dass der Arbeitsbereich über einen Computecluster mit dem Namen
cpu-clusterverfügt, oder bearbeiten Sie das Feldcomputeunterjobs.train_job.computemit dem Namen Ihres Compute.
Führen Sie den Pipelineauftrag mit dem Befehl az ml job create aus.
az ml job create --file single-job-pipeline.yml
Tipp
Wenn Sie den Standardarbeitsbereich und die Ressourcengruppe nicht wie im Abschnitt "Voraussetzungen" beschrieben konfiguriert haben, müssen Sie die Parameter --workspace-name und --resource-group angeben, damit az ml job create ordnungsgemäß funktioniert.
Alternativ können Sie die Bearbeitung von single-job-pipeline.yml überspringen und den in train_job verwendeten Komponentennamen über die Befehlszeilenschnittstelle außer Kraft setzen.
az ml job create --file single-job-pipeline.yml --set jobs.train_job.component=azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
Da die im Trainingsauftrag verwendete Komponente über eine Registrierung freigegeben wird, können Sie den Auftrag an jeden Arbeitsbereich übermitteln, auf den Sie in Ihrer Organisation zugreifen können, auch über unterschiedliche Abonnements hinweg. Wenn Sie beispielsweise über dev-workspace, test-workspace und prod-workspace verfügen, entspricht das Ausführen des Trainingsauftrags in diesen drei Arbeitsbereichen einfach dem dreimaligen Ausführen des Befehls az ml job create.
az ml job create --file single-job-pipeline.yml --workspace-name dev-workspace --resource-group <resource-group-of-dev-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name test-workspace --resource-group <resource-group-of-test-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name prod-workspace --resource-group <resource-group-of-prod-workspace>
Wählen Sie in Azure Machine Learning Studio den Endpunktlink in der Auftragsausgabe aus, um den Auftrag anzuzeigen. Hier können Sie Trainingsmetriken analysieren, sich vergewissern, dass der Auftrag die Komponente und die Umgebung aus der Registrierung verwendet, und das trainierte Modell überprüfen. Notieren Sie sich den name des Auftrags aus der Ausgabe, oder suchen Sie diese Informationen in der Auftragsübersicht in Azure Machine Learning Studio. Sie benötigen diese Informationen, um das trainierte Modell im nächsten Abschnitt zum Erstellen von Modellen in der Registrierung herunterzuladen.

Erstellen eines Modells in der Registrierung
In diesem Abschnitt erfahren Sie, wie Sie Modelle in einer Registrierung erstellen. Lesen Sie Verwalten von Modellen, um mehr über die Modellverwaltung in Azure Machine Learning zu erfahren. Wir betrachten zwei verschiedene Möglichkeiten zum Erstellen eines Modells in einer Registrierung. Die erste erfolgt über lokale Dateien. Die zweite besteht im Kopieren eines im Arbeitsbereich registrierten Modells in eine Registrierung.
In beiden Optionen erstellen Sie ein Modell mit dem MLflow-Format, mit dem Sie dieses Modell für Rückschlüsse bereitstellen können, ohne Einenschlusscode zu schreiben.
Erstellen eines Modells in der Registrierung aus lokalen Dateien
Laden Sie das Modell herunter, das als Ausgabe der Datei train_job verfügbar ist, indem Sie <job-name> durch den Namen des Auftrags aus dem vorherigen Abschnitt ersetzen. Das Modell und die zugehörigen MLflow-Metadatendateien sollten unter ./artifacts/model/ verfügbar sein.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --query [0].name | sed 's/\"//g')
# download the default outputs of the train_job
az ml job download --name $train_job_name
# review the model files
ls -l ./artifacts/model/
Tipp
Wenn Sie den Standardarbeitsbereich und die Ressourcengruppe nicht gemäß dem Abschnitt „Voraussetzungen“ konfiguriert haben, müssen Sie die Parameter --workspace-name und --resource-group angeben, damit az ml model create funktioniert.
Warnung
Die Ausgabe von az ml job list wird an sed weitergegeben. Dies funktioniert nur in Linux-Shells. Wenn Sie unter Windows arbeiten, führen Sie az ml job list --parent-job-name <job-name> --query [0].name aus, und entfernen Sie etwaige Anführungszeichen im Namen des Trainingsauftrags.
Wenn Sie das Modell nicht herunterladen können, finden Sie ein MLflow-Beispielmodell, das durch den Trainingsauftrag im vorherigen Abschnitt trainiert wurde, im Ordner cli/jobs/pipelines-with-components/nyc_taxi_data_regression/artifacts/model/.
Erstellen Sie das Modell in der Registrierung:
# create model in registry
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path ./artifacts/model/ --registry-name <registry-name>
Tipp
- Verwenden Sie eine Zufallszahl für den
versionParameter, wenn Sie einen Fehler erhalten, dass der Modellname und die Version bereits existieren. - Derselbe CLI-Befehl
az ml model createkann zum Erstellen von Modellen in einem Arbeitsbereich oder in einer Registrierung verwendet werden. Wenn Sie den Befehl mit dem Befehl--workspace-nameausführen, wird das Modell in einem Arbeitsbereich erstellt. Ausführen des Befehls mit--registry-nameerstellt das Modell in der Registrierung.
Freigeben eines Modells aus dem Arbeitsbereich für die Registrierung
In diesem Workflow erstellen Sie zuerst das Modell im Arbeitsbereich und geben es dann für die Registrierung frei. Dieser Workflow ist nützlich, wenn Sie das Modell im Arbeitsbereich testen möchten, bevor Sie es freigeben. Stellen Sie es beispielsweise für Endpunkte bereit, und testen Sie die Ableitung mit einigen Testdaten, und kopieren Sie das Modell dann in eine Registrierung, wenn alles gut aussieht. Dieser Workflow kann auch hilfreich sein, wenn Sie eine Reihe von Modellen mit verschiedenen Techniken, Frameworks oder Parametern entwickeln und nur eine davon als Produktionskandidat in die Registrierung bewerben möchten.
Stellen Sie sicher, dass Sie über den Namen des Pipelineauftrags aus dem vorherigen Abschnitt verfügen, und ersetzen Sie diesen im Befehl, um den Namen des Trainingsauftrags abzurufen. Anschließend registrieren Sie das Modell aus der Ausgabe des Trainingsauftrags im Arbeitsbereich. Beachten Sie, wie der Parameter --path auf die Ausgabe von train_job mit der Syntax azureml://jobs/$train_job_name/outputs/artifacts/paths/model verweist.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --workspace-name <workspace-name> --resource-group <workspace-resource-group> --query [0].name | sed 's/\"//g')
# create model in workspace
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path azureml://jobs/$train_job_name/outputs/artifacts/paths/model
Tipp
- Verwenden Sie eine Zufallszahl für den
versionParameter, wenn Sie einen Fehler erhalten, dass der Modellname und die Version bereits vorhanden sind. - Wenn Sie den Standardarbeitsbereich und die Ressourcengruppe nicht wie im Abschnitt „Voraussetzungen“ erläutert konfiguriert haben, müssen Sie die Parameter
--workspace-nameand--resource-groupangeben, damitaz ml model createfunktioniert.
Notieren Sie den Namen und die Version des Modells. Sie können überprüfen, ob das Modell im Arbeitsbereich registriert ist, indem Sie diesen in der Studio-Benutzeroberfläche oder mithilfe des Befehls az ml model show --name nyc-taxi-model --version $model_version durchsuchen.
Als nächstes geben Sie das Modell aus dem Arbeitsbereich für die Registrierung frei.
# share model registered in workspace to registry
az ml model share --name nyc-taxi-model --version 1 --registry-name <registry-name> --share-with-name <new-name> --share-with-version <new-version>
Tipp
- Achten Sie darauf, im Befehl
az ml model createden richtigen Modellnamen und die richtige Version zu verwenden, wenn Sie diese geändert haben. - Der obige Befehl verfügt über die beiden optionalen Parameter „--share-with-name“ und „--share-with-version“. Wenn diese nicht bereitgestellt werden, hat das neue Modell den gleichen Namen und dieselbe Version wie das Modell, das freigegeben wird.
Notieren Sie sich den
nameund dieversiondes Modells aus der Ausgabe des Befehlsaz ml model create, und verwenden Sie sie mit den Befehlenaz ml model showwie folgt. Sie benötigen dennameund dieversionim nächsten Abschnitt, wenn Sie das Modell für Rückschlüsse auf einem Onlineendpunkt bereitstellen.
az ml model show --name <model_name> --version <model_version> --registry-name <registry-name>
Sie können auch mit az ml model list --registry-name <registry-name> alle Modelle in der Registrierung auflisten oder alle Komponenten auf der Azure Machine Learning Studio-Benutzeroberfläche durchsuchen. Navigieren Sie zur globalen Benutzeroberfläche, und suchen Sie nach dem Eintrag Registrierungshub.
Der folgende Screenshot zeigt ein Modell in einer Registrierung in Azure Machine Learning Studio. Wenn Sie ein Modell aus der Auftragsausgabe erstellt und dann aus dem Arbeitsbereich in die Registrierung kopiert haben, sehen Sie, dass das Modell einen Link zu dem Auftrag aufweist, der das Modell trainiert hat. Sie können über diesen Link zum Trainingsauftrag navigieren, um den Code, die Umgebung und die zum Trainieren des Modells verwendeten Daten zu überprüfen.
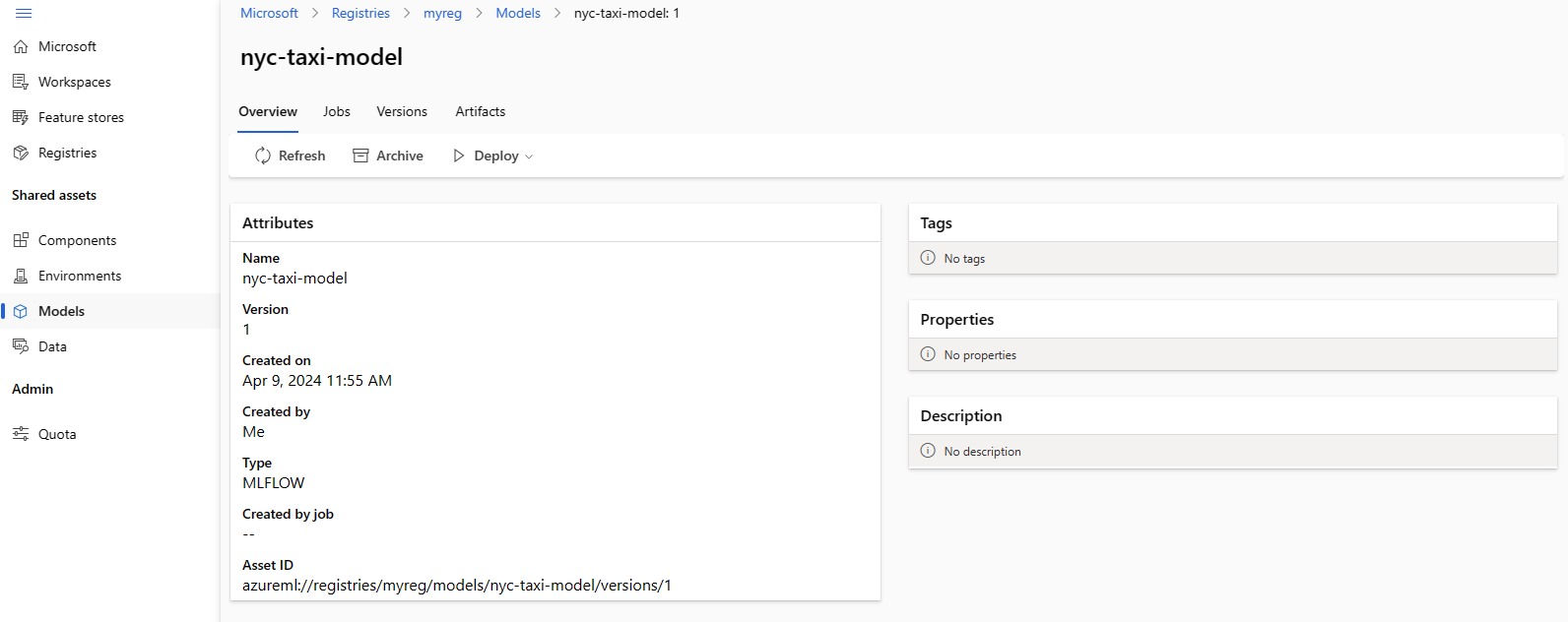
Bereitstellen des Modells aus der Registrierung auf einem Onlineendpunkt in einem Arbeitsbereich
Im letzten Abschnitt stellen Sie ein Modell aus der Registrierung auf einen Onlineendpunkt in einem Arbeitsbereich bereit. Sie können jeden Arbeitsbereich bereitstellen, auf den Sie in Ihrer Organisation zugreifen können, sofern der Standort des Arbeitsbereichs einer der von der Registrierung unterstützten Standorte ist. Diese Möglichkeit ist hilfreich, wenn Sie ein Modell in einem dev-Arbeitsbereich trainiert haben und jetzt in einem test- oder prod-Arbeitsbereich bereitstellen müssen, während die Herkunftsinformationen rund um den Code, die Umgebung und Daten zum Trainieren des Modells beibehalten werden.
Onlineendpunkte ermöglichen Ihnen die Bereitstellung von Modellen und das Übermitteln von Rückschlussanforderungen über die REST-APIs. Weitere Informationen finden Sie unter Bereitstellen und Bewerten eines Machine Learning-Modells mithilfe eines Onlineendpunkts.
Erstellen Sie einen Onlineendpunkt.
az ml online-endpoint create --name reg-ep-1234
Aktualisieren Sie die Zeile model: in der Datei deploy.yml, die im Ordner cli/jobs/pipelines-with-components/nyc_taxi_data_regression verfügbar ist, sodass sie auf den Modellnamen und die Version aus dem vorherigen Schritt verweist. Erstellen Sie eine Onlinebereitstellung für den Onlineendpunkt. deploy.yml wird zu Ihrer Referenz im Folgenden dargestellt.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: demo
endpoint_name: reg-ep-1234
model: azureml://registries/<registry-name>/models/nyc-taxi-model/versions/1
instance_type: Standard_DS2_v2
instance_count: 1
Erstellen Sie die Onlinebereitstellung. Die Bereitstellung kann einige Minuten in Anspruch nehmen.
az ml online-deployment create --file deploy.yml --all-traffic
Rufen Sie den Bewertungs-URI ab, und übermitteln Sie eine Beispielbewertungsanforderung. Beispieldaten für die Bewertungsanforderung stehen in scoring-data.json im Ordner cli/jobs/pipelines-with-components/nyc_taxi_data_regression zur Verfügung.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n reg-ep-1234 -o tsv --query primaryKey)
SCORING_URI=$(az ml online-endpoint show -n reg-ep-1234 -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @./scoring-data.json
Tipp
- Der Befehl
curlfunktioniert nur unter Linux. - Wenn Sie den Standardarbeitsbereich und die Ressourcengruppe nicht gemäß dem Abschnitt „Voraussetzungen“ konfiguriert haben, müssen Sie die Parameter
--workspace-nameund--resource-groupangeben, damit die Befehleaz ml online-endpointundaz ml online-deploymentfunktionieren.
Bereinigen von Ressourcen
Wenn Sie die Bereitstellung nicht verwenden, sollten Sie sie löschen, um die Kosten zu reduzieren. Im folgenden Beispiel werden der Endpunkt und alle zugrunde liegenden Bereitstellungen gelöscht:
az ml online-endpoint delete --name reg-ep-1234 --yes --no-wait