Einrichten des Trainings für automatisiertes maschinelles Lernen für Tabellendaten ohne Code über die Studio-Benutzeroberfläche
In diesem Artikel erfahren Sie, wie Sie Trainingsaufträge für automatisiertes maschinelles Lernen ohne eine einzige Codezeile in Azure Machine Learning Studio für Azure Machine Learning einrichten.
Automatisiertes maschinelles Lernen (AutoML) ist ein Prozess, bei dem der beste Algorithmus für das maschinelle Lernen anhand Ihrer spezifischen Daten für Sie ausgewählt wird. Dieser Prozess ermöglicht Ihnen die schnelle Erstellung von Machine Learning-Modellen. Weitere Informationen zur Implementierung des automatisierten maschinellen Lernens in Azure Machine Learning.
Ein umfassendes Beispiel finden Sie im Tutorial: Trainieren eines Klassifizierungsmodells mit AutoML ohne Schreiben von Code in Azure Machine Learning Studio.
Wenn Sie eine auf Python-Code basierende Umgebung bevorzugen, konfigurieren Sie Ihre Experimenten mit automatisiertem maschinellem Lernen mit dem Azure Machine Learning SDK.
Voraussetzungen
Ein Azure-Abonnement. Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning noch heute aus.
Ein Azure Machine Learning-Arbeitsbereich. Siehe Erstellen von Arbeitsbereichsressourcen.
Erste Schritte
Melden Sie sich bei Azure Machine Learning Studio an.
Wählen Sie Ihr Abonnement und Ihren Arbeitsbereich aus.
Navigieren Sie zum linken Bereich. Wählen Sie im Abschnitt Erstellung die Option Automatisiertes ML aus.

Wenn Sie zum ersten Mal ein Experiment durchführen, sehen Sie eine leere Liste und Links zur Dokumentation.
Andernfalls sehen Sie eine Liste Ihrer letzten automatisierten ML-Experimente, einschließlich derer, die mit dem SDK erstellt wurden.
Erstellen und Ausführen eines Experiments
Wählen Sie + Neuer Auftrag von automatisiertem ML aus, und füllen Sie das Formular aus.
Wählen Sie eine Datenressource in Ihrem Speichercontainer aus, oder erstellen Sie eine neue Datenressource. Datenressourcen können aus lokalen Dateien, Web-URLs, Datenspeichern oder Azure Open Datasets erstellt werden. Erfahren Sie mehr über die Erstellung von Datenressourcen.
Wichtig
Anforderungen für Trainingsdaten:
- Die Daten müssen in Tabellenform vorliegen.
- Der Wert, den Sie vorhersagen möchten (Zielspalte), muss in den Daten vorhanden sein.
Um ein neues Dataset aus einer Datei auf Ihrem lokalen Computer zu erstellen, wählen Sie +Dataset erstellen und anschließend Aus lokaler Datei aus.
Wählen Sie Weiter aus, um das Formular Datenspeicher- und Dateiauswahl zu öffnen. wählen Sie aus, wo das Dataset hochgeladen werden soll. Dies kann der Standardspeichercontainer sein, der automatisch mit Ihrem Arbeitsbereich erstellt wird, oder ein Speichercontainer, den Sie für das Experiment auswählen.
- Wenn sich Ihre Daten hinter einem virtuellen Netzwerk befinden, müssen Sie die Funktion zum Überspringen der Überprüfung aktivieren, um sicherzustellen, dass der Arbeitsbereich auf Ihre Daten zugreifen kann. Weitere Informationen finden Sie unter Verwenden von Azure Machine Learning Studio in einem virtuellen Azure-Netzwerk.
Wählen Sie Durchsuchen aus, um die Datendatei für das Dataset hochzuladen.
Überprüfen Sie das Formular Einstellungen und Vorschau auf Genauigkeit. Das Formular wird ausgehend vom Dateityp intelligent aufgefüllt.
Feld BESCHREIBUNG Dateiformat Definiert das Layout und den Typ der in einer Datei gespeicherten Daten. Trennzeichen Mindestens ein Zeichen zum Angeben der Grenze zwischen separaten, unabhängigen Regionen in Nur-Text- oder anderen Datenströmen. Codieren Gibt an, welche Bit-zu-Zeichen-Schematabelle verwendet werden soll, um Ihr Dataset zu lesen. Spaltenüberschriften Gibt an, wie die Header des Datasets, sofern vorhanden, behandelt werden. Zeilen überspringen Gibt an, wie viele Zeilen im Dataset übersprungen werden. Wählen Sie Weiter aus.
Das Formular Schema wird auf intelligente Weise entsprechend den auf dem Formular Einstellungen und Vorschau ausgewählten Optionen aufgefüllt. Konfigurieren Sie hier den Datentyp für jede Spalte, überprüfen Sie die Spaltennamen, und wählen Sie für die Spalten, die nicht in Ihr Experiment eingeschlossen werden sollen, die Option Nicht einschließen aus.
Wählen Sie Weiter aus.
Das Formular Details bestätigen ist eine Zusammenfassung der Informationen, die zuvor in die Formulare Grundlegende Infos und Einstellungen und Vorschau eingetragen wurden. Sie haben auch die Möglichkeit, ein Datenprofil für Ihr Dataset zu erstellen, indem Sie Compute mit aktivierter Profilerstellung verwenden.
Wählen Sie Weiter aus.
Wählen Sie Ihr neu erstelltes Dataset aus, sobald es angezeigt wird. Sie können sich auch eine Vorschau des Datasets und eine Beispielstatistik ansehen.
Wählen Sie im Formular zum Konfigurieren des Auftrags die Option Neu erstellen aus, und geben Sie als Experimentnamen Tutorial-automl-deploy ein.
Wählen Sie eine Zielspalte aus: Dies ist die Spalte, für die Sie Vorhersagen ausführen möchten.
Wählen Sie einen Computetyp für den Datenprofilerstellungs- und Trainingsauftrag aus. Sie können einen Computecluster oder eine Compute-Instanz auswählen.
Wählen Sie in der Dropdownliste Ihrer vorhandenen Computeressourcen eine Computeressource aus. Folgen Sie den Anweisungen in Schritt 8, um eine neue Computeressource zu erstellen.
Wählen Sie Create a new compute (Neue Computeressource erstellen) aus, um den Computekontext für dieses Experiment zu konfigurieren.
Feld BESCHREIBUNG Computename Geben Sie einen eindeutigen Namen ein, der Ihren Computekontext identifiziert. VM-Priorität Virtuelle Computer mit niedriger Priorität sind kostengünstiger, bieten jedoch keine garantierten Computeknoten. Typ des virtuellen Computers Wählen Sie CPU oder GPU als VM-Typ aus. Größe des virtuellen Computers Wählen Sie die Größe für Ihren Computes aus. Min/Max nodes (Min./Max. Knoten) Um ein Datenprofil zu erstellen, müssen Sie mindestens einen Knoten angeben. Geben Sie die maximale Anzahl von Knoten für Ihren Compute ein. Der Standardwert ist sechs Knoten für einen Azure Machine Learning Compute. Erweiterte Einstellungen Mit diesen Einstellungen können Sie ein Benutzerkonto und ein vorhandenes virtuelles Netzwerk für Ihr Experiment konfigurieren. Klicken Sie auf Erstellen. Das Erstellen einer neuen Computeressource kann einige Minuten dauern.
Wählen Sie Weiter aus.
Wählen Sie auf dem Formular Aufgabentyp und Einstellungen den Aufgabentyp aus: Klassifizierung, Regression oder Prognose (Vorhersage). Weitere Informationen finden Sie unter Unterstützte Aufgabentypen.
Für die Klassifizierung können Sie auch Deep Learning aktivieren.
Für Vorhersagen haben Sie folgende Möglichkeiten:
Aktivieren Sie Deep Learning.
Auswählen der Zeitspalte: Diese Spalte enthält die zu verwendenden Zeitdaten.
Auswählen des Vorhersagehorizonts: Geben Sie an, wie viele Zeiteinheiten (Minuten/Stunden/Tage/Wochen/Monate/Jahre) das Modell die Zukunft vorhersagen können soll. Je weiter in die Zukunft das Modell voraussagen muss, desto ungenauer wird es. Weitere Informationen zu Vorhersagen und zum Vorhersagehorizont.
(Optional:) Anzeigen weiterer Konfigurationseinstellungen: zusätzliche Einstellungen, mit denen Sie den Trainingsauftrag besser steuern können. Andernfalls werden die Standardwerte auf Basis der Experimentauswahl und -daten angewendet.
Zusätzliche Konfigurationen BESCHREIBUNG Primary metric (Primäre Metrik) Die wichtigste Metrik, die für die Bewertung Ihres Modells verwendet wird. Weitere Informationen zur Modellmetriken. Aktivieren der Ensemblestapelung Das Lernen mit Ensembles verbessert die Ergebnisse des maschinellen Lernens und die Vorhersageleistung, da nicht einzelne Modelle verwendet, sondern mehrere Modelle kombiniert werden. Erfahren Sie mehr über Ensemblemodelle. Blockierte Modelle Wählen Sie Modelle aus, die Sie aus den Trainingsauftrag ausschließen möchten.
Das Zulassen von Modellen ist nur für SDK-Experimente verfügbar.
Weitere Informationen finden Sie auf der Seite zu den unterstützten Algorithmen für einzelne Aufgabentypen.Explain best model (Bestes Modell erläutern) Zeigt automatisch die Erklärbarkeit für das beste Modell an, das durch automatisiertes ML erstellt wurde. Positive Klassenbezeichnung Bezeichnung, die Automatisiertes ML zum Berechnen binärer Metriken verwendet. (Optional) Anzeigen von Featurisierungseinstellungen: Wenn Sie im Formular Additional configuration settings (Zusätzliche Konfigurationseinstellungen) die Option Automatische Featurisierung aktivieren, werden standardmäßige Featurisierungstechniken angewendet. In den Einstellungen für die Ansichtsfeaturierung können Sie diese Standardwerte ändern und entsprechend anpassen. Informationen zum Anpassen von Featurisierungen finden Sie hier.
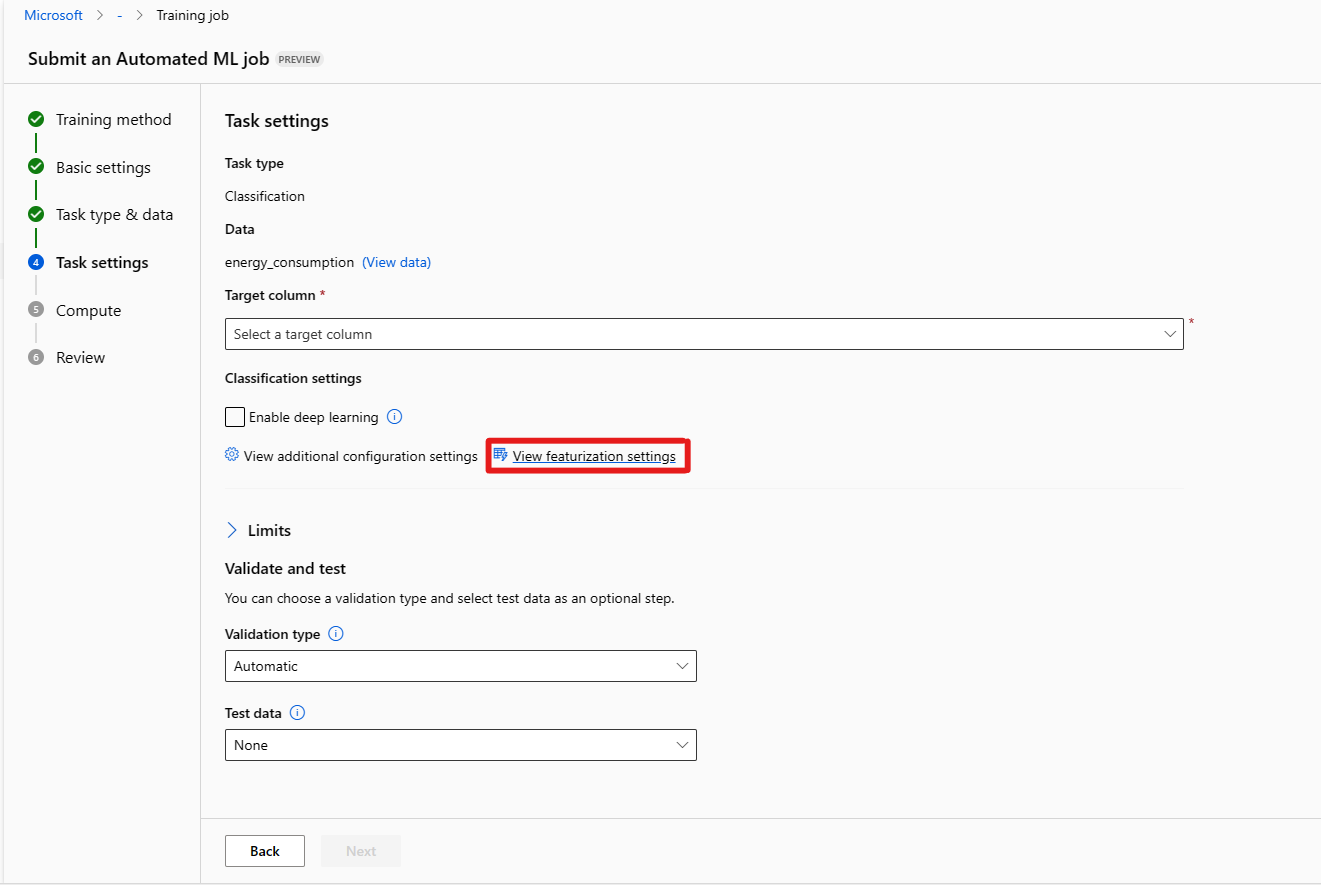
Mit dem Formular [Optional] Grenzwerte können Sie Folgendes festlegen:
Option Beschreibung Maximale Textläufe Die maximale Anzahl der Testläufe mit unterschiedlichen Kombinationen von Algorithmen und Hyperparametern, die während des AutoML-Auftrags ausprobiert werden sollen. Muss eine ganze Zahl zwischen 1 und 1000 sein. Maximale Anzahl gleichzeitiger Testläufe Die maximale Anzahl der Testaufträge, die parallel ausgeführt werden können. Muss eine ganze Zahl zwischen 1 und 1000 sein. Maximale Knotenanzahl Die maximale Anzahl der Knoten, die dieser Auftrag aus dem ausgewählten Computeziel verwenden kann Metrischer Bewertungsschwellenwert Wenn dieser Schwellenwert für eine Iterationsmetrik erreicht wird, wird der Trainingsauftrag beendet. Beachten Sie, dass aussagekräftige Modelle Korrelationen > 0 haben, andernfalls können sie bestenfalls den Durchschnitt erraten. Der Metrikschwellenwert sollte innerhalb der Grenze [0, 10] liegen. Experimenttimeout (Minuten) Die maximale Zeit in Minuten, die das gesamte Experiment ausgeführt werden darf. Sobald dieser Grenzwert erreicht ist, bricht das System den AutoML-Auftrag ab, einschließlich aller Testläufe (untergeordnete Aufträge). Iterationstimeout (Minuten) Die maximale Zeit in Minuten, die jeder Testauftrag ausgeführt werden darf. Sobald dieser Grenzwert erreicht ist, bricht das System die Testversion ab. Vorzeitige Beendigung aktivieren Legen Sie fest, ob der Auftrag beendet werden soll, wenn sich der Score kurzfristig nicht verbessert. Mit dem Formular [Optional] Validieren und testen können Sie Folgendes tun.
a. Geben Sie die Art der Validierung an, die für Ihren Ausbildungsauftrag verwendet werden soll. Wenn Sie weder einen validation_data- noch einen n_cross_validations-Parameter explizit angeben, wendet die automatisierte ML Standardtechniken an, die von der Anzahl der im Einzeldatensatz training_data angegebenen Zeilen abhängen.
| Umfang der Trainingsdaten | Validierungsverfahren |
|---|---|
| Mehr als 20.000 Zeilen | Es wird eine Aufteilung in Trainings- und Validierungsdaten vorgenommen. Standardmäßig werden 10 % des ursprünglichen Trainingsdatasets als Validierungsset verwendet. Dieses Validierungsset wird seinerseits für die Metrikberechnung verwendet. |
| Weniger als 20.000 Zeilen | Der Kreuzvalidierungsansatz wird angewendet. Die Standardanzahl der Faltungen (Folds) hängt von der Zeilenanzahl ab. Wenn das Dataset weniger als 1.000 Zeilen aufweist, werden 10 Faltungen verwendet. Wenn die Anzahl der Zeilen zwischen 1.000 und 20.000 liegt, werden drei Faltungen verwendet. |
b. Stellen Sie einen Testdatensatz (Vorschau) zur Verfügung, um das empfohlene Modell zu bewerten, das automatisierte ML am Ende Ihres Experiments für Sie erstellt. Wenn Sie Testdaten bereitstellen, wird am Ende Ihres Experiments automatisch einen Testauftrag ausgelöst. Dieser Testauftrag ist nur ein Auftrag für das beste Modell, das von der automatischen ML empfohlen wird. Erfahren Sie, wie Sie die Ergebnisse des Remotetestauftrags erhalten.
Wichtig
Die Bereitstellung eines Testdatensatzes zur Bewertung der erstellten Modelle ist eine Previewfunktion. Diese Funktion ist eine experimentelle Previewfunktion, die jederzeit geändert werden kann.
* Die Testdaten werden getrennt von den Trainings- und Validierungsdaten betrachtet, um die Ergebnisse des Testauftrags des empfohlenen Modells nicht zu verfälschen. Mehr über Verzerrungen bei der Modellvalidierung erfahren.
* Sie können entweder Ihr eigenes Test-Dataset zur Verfügung stellen oder sich dafür entscheiden, einen Prozentsatz Ihres Trainings-Datasets zu verwenden. Testdaten müssen in Form eines Azure Machine Learning TabularDatasetvorliegen.
* Das Schema des Test-Datasets sollte mit dem Trainings-Dataset übereinstimmen. Die Zielspalte ist optional, aber wenn keine Zielspalte angegeben wird, werden keine Testmetriken berechnet.
* Das Test-Dataset sollte nicht dasselbe sein wie das Trainings-Dataset oder das Validierungs-Dataset.
* Aufträge für Prognosen unterstützen keine Trennung von Training und Test.
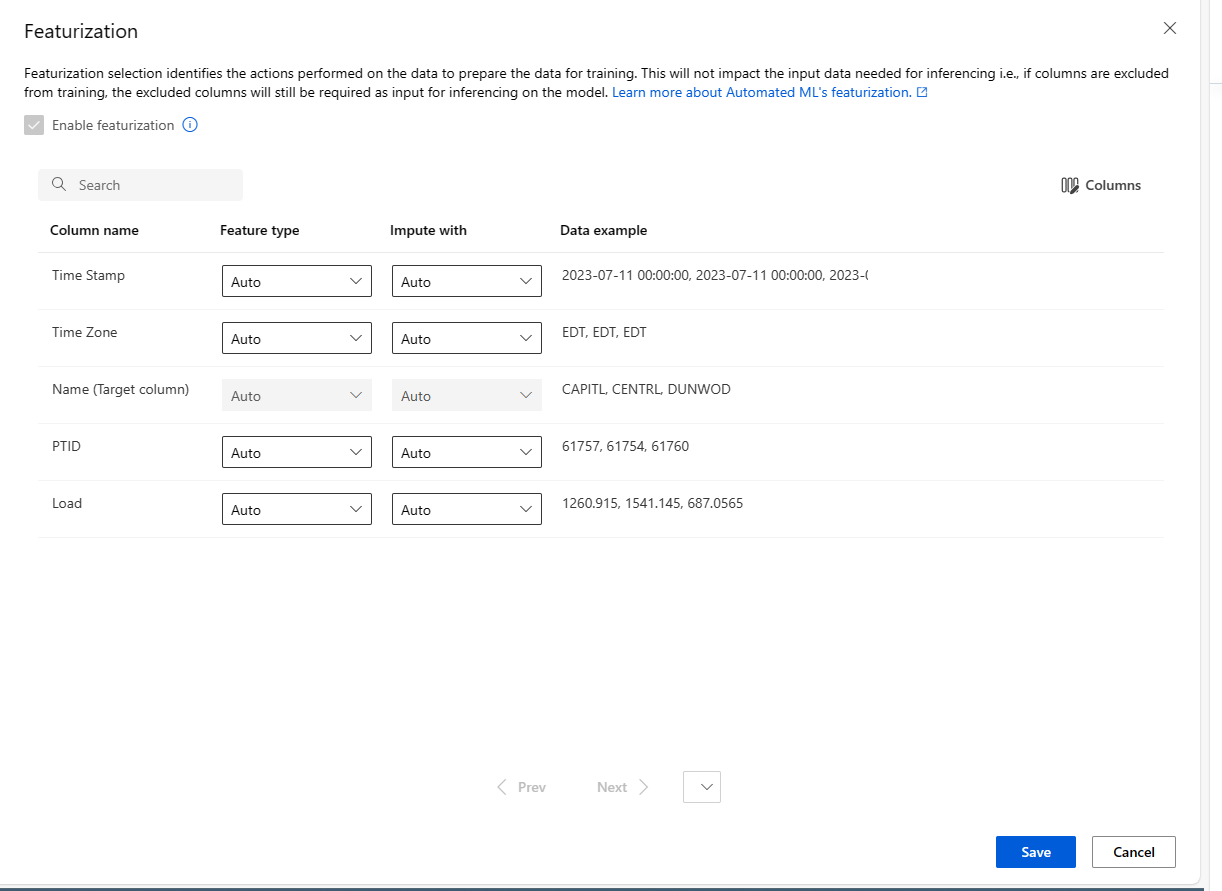
Anpassen der Featurisierung
Im Formular Featurisierung können Sie die automatische Featurisierung aktivieren/deaktivieren und die Einstellungen der automatischen Featurisierung für Ihr Experiment anpassen. Informationen zum Öffnen dieses Formulars finden Sie in Schritt 10 des Abschnitts Erstellen und Ausführen eines Experiments.
In der folgenden Tabelle sind die derzeit in Studio verfügbaren Anpassungen zusammengefasst:
| Spalte | Anpassung |
|---|---|
| Featuretyp | Dient zum Ändern des Werttyps für die ausgewählte Spalte. |
| Imputation mit | Dient zum Auswählen des Werts, mit dem fehlende Werte in Ihren Daten imputiert werden sollen. |
Ausführen des Experiments und Anzeigen der Ergebnisse
Wählen Sie Fertig stellen aus, um das Experiment auszuführen. Der Vorgang zum Vorbereiten eines Experiments kann bis zu 10 Minuten dauern. Ein Ausführen von Trainingsaufträgen kann für jede Pipeline weitere 2 bis 3 Minuten beanspruchen. Wenn Sie angegeben haben, dass das RAI-Dashboard für das beste empfohlene Modell erstellt werden soll, kann dies bis zu 40 Minuten dauern.
Hinweis
Die Algorithmen, die beim automatisierten maschinellen Lernen eingesetzt werden, weisen eine inhärente Zufälligkeit auf, die zu geringfügigen Abweichungen in der abschließenden metrischen Bewertung eines empfohlenen Modells führen kann, z. B. bei der Genauigkeit. Automatisiertes maschinelles Lernen führt bei Bedarf auch Vorgänge an Daten wie Training-Test-Aufteilung, Training-Validierung-Aufteilung oder Kreuzvalidierung durch. Wenn Sie also ein Experiment mit denselben Konfigurationseinstellungen und derselben primären Metrik mehrmals durchführen, werden Sie aufgrund dieser Faktoren wahrscheinlich bei jedem Experiment eine Abweichung in der abschließenden metrischen Bewertung sehen.
Anzeigen von Details zum Experiment
Die Anzeige für Auftragsdetails wird mit der Registerkarte Details geöffnet. In dieser Anzeige wird eine Zusammenfassung des Experimentauftrags einschließlich einer Statusleiste oben neben der Auftragsnummer angezeigt.
Die Registerkarte Modelle enthält eine Liste der erstellten Modelle, wobei diese nach der Metrikbewertung (Metrikscore) geordnet sind. Standardmäßig steht das Modell, das anhand der ausgewählten Metrik die höchste Bewertung erhält, in der Liste ganz oben. Wenn der Trainingsauftrag weitere Modelle testet, werden diese der Liste hinzugefügt. Verwenden Sie diese Liste, um einen schnellen Vergleich der Metriken für die bisher generierten Modelle zu erhalten.
Anzeigen der Details von Trainingsaufträgen
Lassen Sie zu jedem abgeschlossenen Modell Detailinformationen zum Trainingsauftrag anzeigen.
Sie können modellspezifische Leistungsmetrikdiagramme auf der Registerkarte Metriken anzeigen. Weitere Informationen zu Diagrammen.
Hier finden Sie auch Details zu allen Eigenschaften des Modells sowie den zugehörigen Code, untergeordnete Aufträge und Bilder.
Ergebnisse des Remotetestauftrags anzeigen (Vorschau)
Wenn Sie bei der Einrichtung Ihres Experiments (im Formular Validieren und Testen) ein Test-Dataset angegeben oder sich für eine Aufteilung in Training und Test entschieden haben, testet Automated ML standardmäßig automatisch das empfohlene Modell. Infolgedessen berechnet die automatisierte ML Testmetriken, um die Qualität des empfohlenen Modells und seiner Vorhersagen zu bestimmen.
Wichtig
Das Testen Ihrer Modelle mit einem Testdatensatz zur Bewertung der generierten Modelle ist eine Previewfunktion. Diese Funktion ist eine experimentelle Previewfunktion, die jederzeit geändert werden kann.
Warnung
Dieses Feature ist nicht für die folgenden Szenarien mit automatisiertem ML verfügbar:
- Aufgaben für maschinelles Sehen
- Trainieren zahlreicher Modelle und hierarchischer Zeitreihenvorhersagen (Vorschau)
- Vorhersageaufgaben, für die neuronale Deep Learning-Netze (Deep Learning Neural Networks, DNNs) aktiviert sind
- Automatisierte ML-Aufträge von lokalen Computeressourcen oder Azure Databricks-Clustern
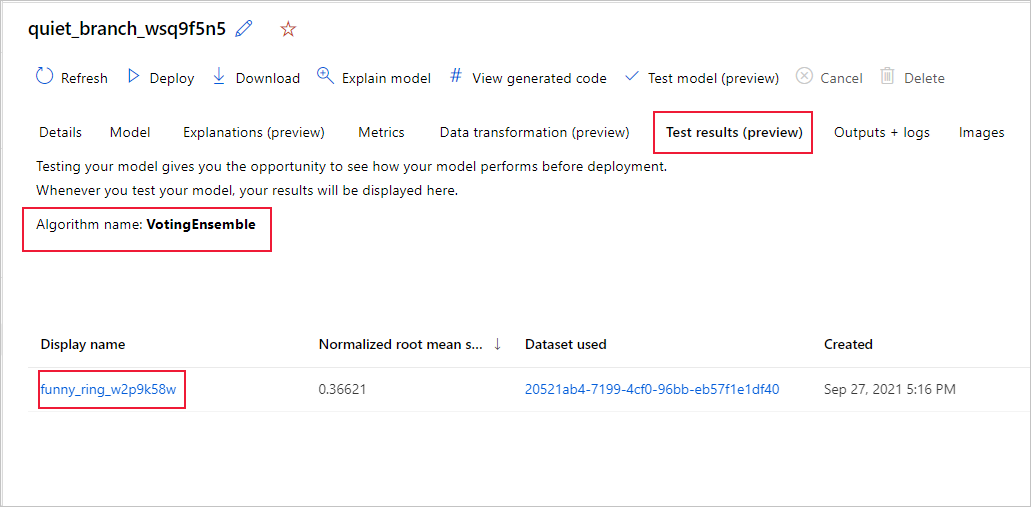
Zur Anzeige der Testauftragsmetriken des empfohlenen Modells:
- Navigieren Sie zur Seite Modelle und wählen Sie das beste Modell.
- Wählen Sie die Registerkarte Testergebnisse (Vorschau) .
- Wählen Sie den gewünschten Auftrag aus, und sehen Sie sich die Registerkarte Metriken an.
So zeigen Sie die Testvorhersagen an, die zur Berechnung der Testmetriken verwendet wurden,
- Navigieren Sie zum unteren Ende der Seite und wählen Sie den Link unter Outputs dataset, um den Datensatz zu öffnen.
- Wählen Sie auf der Seite Datensätze die Registerkarte Durchsuchen, um die Vorhersagen des Testauftrags zu betrachten.
- Alternativ kann die Vorhersagedatei auch auf der Registerkarte Ausgaben + Protokolle eingesehen/heruntergeladen werden. Erweitern Sie den Ordner Vorhersagen, um Ihre
predicted.csvDatei zu finden.
- Alternativ kann die Vorhersagedatei auch auf der Registerkarte Ausgaben + Protokolle eingesehen/heruntergeladen werden. Erweitern Sie den Ordner Vorhersagen, um Ihre
Alternativ kann die Vorhersagedatei auch auf der Registerkarte Ausgaben + Protokolle angezeigt/heruntergeladen werden. Erweitern Sie den Ordner Vorhersagen, um die Datei predictions.csv zu finden.
Beim Modelltestauftrag wird die Datei „predictions.csv“ generiert, die in dem mit dem Arbeitsbereich erstellten Standarddatenspeicher gespeichert ist. Dieser Datenspeicher ist für alle Benutzer mit demselben Abonnement sichtbar. Testaufträge werden nicht für Szenarien empfohlen, in denen Informationen, die für den Testauftrag verwendet oder von diesem erstellt werden, vertraulich bleiben müssen.
Testen Sie ein bestehendes automatisiertes ML-Modell (Vorschau)
Wichtig
Das Testen Ihrer Modelle mit einem Testdatensatz zur Bewertung der generierten Modelle ist eine Previewfunktion. Diese Funktion ist eine experimentelle Previewfunktion, die jederzeit geändert werden kann.
Warnung
Dieses Feature ist nicht für die folgenden Szenarien mit automatisiertem ML verfügbar:
- Aufgaben für maschinelles Sehen
- Trainieren zahlreicher Modelle und hierarchischer Zeitreihenvorhersagen (Vorschau)
- Vorhersageaufgaben, für die neuronale Deep Learning-Netze (Deep Learning Neural Networks, DNNs) aktiviert sind
- Ausführen von automatisiertem ML auf lokalen Computeressourcen oder in Azure Databricks-Clustern
Nach Abschluss Ihres Experiments können Sie das/die Modell(e) testen, die das automatisierte ML für Sie erstellt hat. Wenn Sie nicht das empfohlene Modell, sondern ein anderes automatisch generiertes ML-Modell testen möchten, können Sie dies mit den folgenden Schritten tun.
Wählen Sie einen vorhandenen automatisierten ML-Experimentauftrag aus.
Navigieren Sie zur Registerkarte Modelle des Auftrags, und wählen Sie das fertige Modell aus, das Sie testen möchten.
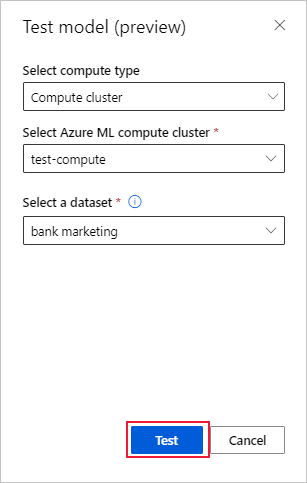
Wählen Sie auf der Seite Modell Details die Schaltfläche Testmodell (Vorschau) , um die Fensterfläche Testmodell zu öffnen.
Wählen Sie im Bereich Testmodell den Rechencluster und einen Testdatensatz, den Sie für Ihren Testauftrag verwenden möchten.
Wählen Sie die Schaltfläche Test. Das Schema des Testdatensatzes sollte mit dem Trainingsdatensatz übereinstimmen, aber die Zielspalte ist optional.
Nach erfolgreicher Erstellung eines Modellprüfauftrags wird auf der Seite Details eine Erfolgsmeldung angezeigt. Wählen Sie die Registerkarte Testergebnisse, um den Fortschritt des Auftrags zu sehen.
Um die Ergebnisse des Testauftrags zu betrachten, öffnen Sie die Seite Details, und folgen Sie den Schritten im Abschnitt Ergebnisse des Remotetestauftrags anzeigen.
Dashboard für verantwortungsvolle KI (Vorschau)
Um Ihr Modell besser zu verstehen, können Sie mit dem verantwortungsvollen KI-Dashboard verschiedene Einblicke in Ihr Modell erhalten. Damit können Sie Ihr bestes automatisiertes maschinelles Lernmodell bewerten und debuggen. Das verantwortungsvolle KI-Dashboard bewertet Modellfehler und Fairnessprobleme, diagnostiziert die Gründe für diese Fehler, indem es Ihre Trainings- und/oder Testdaten auswertet und die Erklärungen des Modells beobachtet. Diese Erkenntnisse können Ihnen dabei helfen, Vertrauen in Ihr Modell aufzubauen und die Prüfungsverfahren zu bestehen. Verantwortungsvolle KI-Dashboards können nicht für ein bestehendes automatisiertes maschinelles Lernmodell erstellt werden. Sie wird nur für das beste empfohlene Modell erstellt, wenn ein neuer AutoML-Auftrag erstellt wird. Benutzer sollten weiterhin nur Modellerklärungen (Vorschau) verwenden, bis die Unterstützung für bestehende Modelle bereitgestellt wird.
So erstellen Sie ein verantwortungsvolles KI-Dashboard für ein bestimmtes Modell:
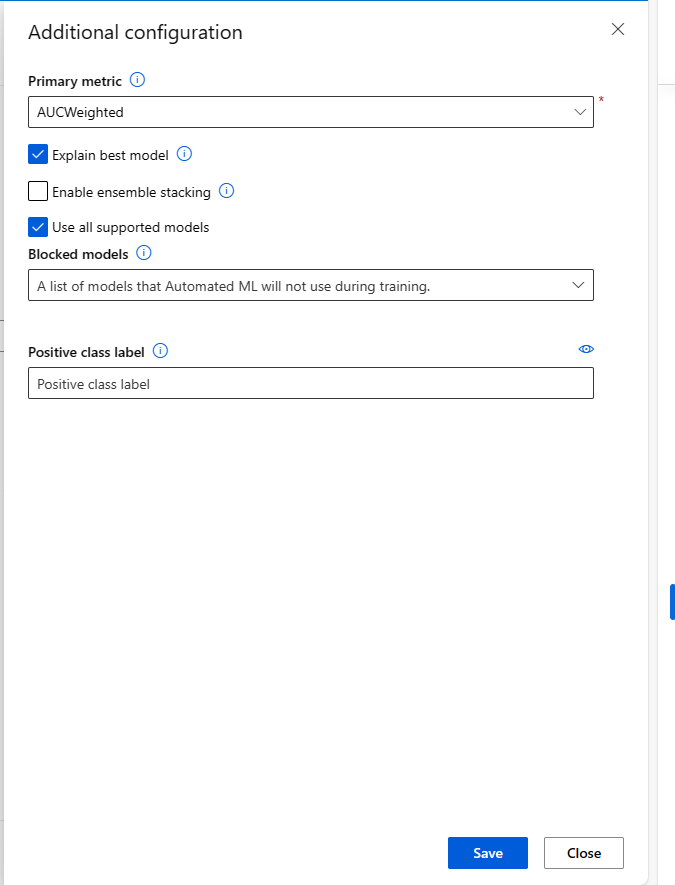
Wenn Sie einen automatisierten ML-Auftrag einreichen, gehen Sie zum Abschnitt Aufgabeneinstellungen in der linken Navigationsleiste und wählen Sie die Option Zusätzliche Konfigurationseinstellungen anzeigen aus.
In dem neuen Formular, das nach dieser Auswahl erscheint, aktivieren Sie das Kontrollkästchen Bestes Modell erklären.
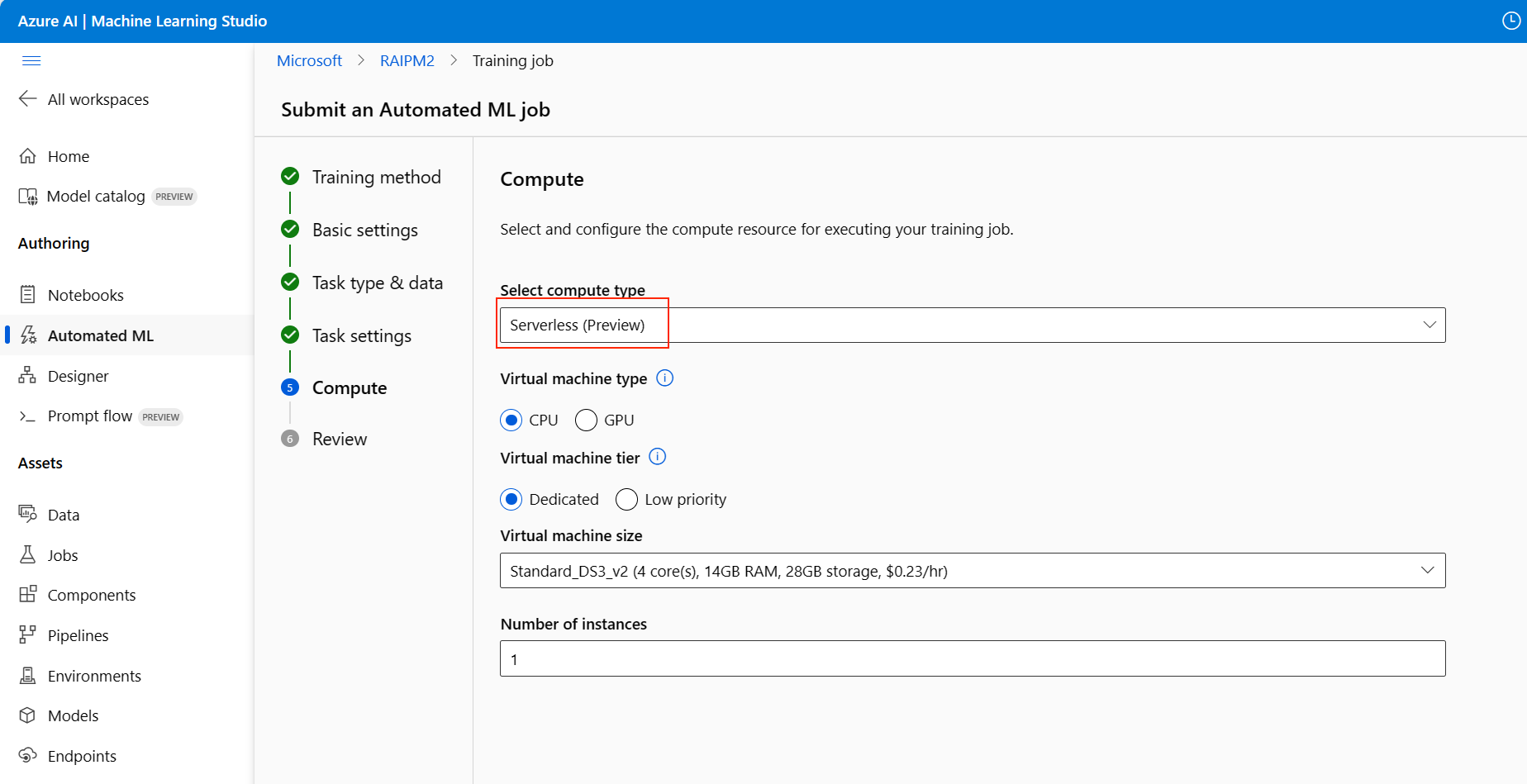
Gehen Sie auf die Seite Compute des Einrichtungsformulars und wählen Sie die Option Serverless als Compute.
Sobald Sie fertig sind, navigieren Sie zur Seite Modelle Ihres automatisierten ML-Auftrags, die eine Liste Ihrer trainierten Modelle enthält. Wählen Sie den Link Verantwortungsvolle KI Dashboard anzeigen aus:
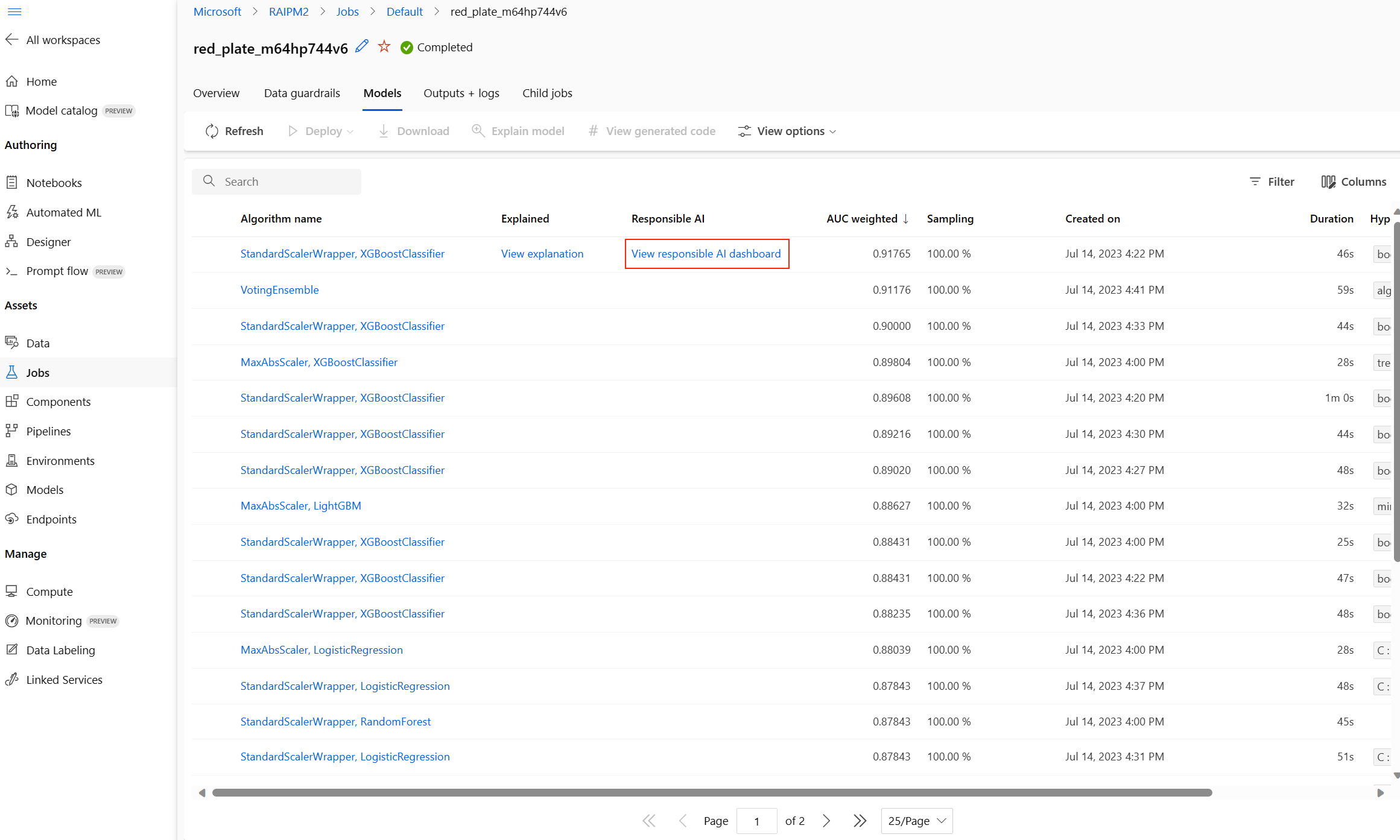
Das verantwortungsvolle KI-Dashboard erscheint für dieses Modell, wie in diesem Bild gezeigt:
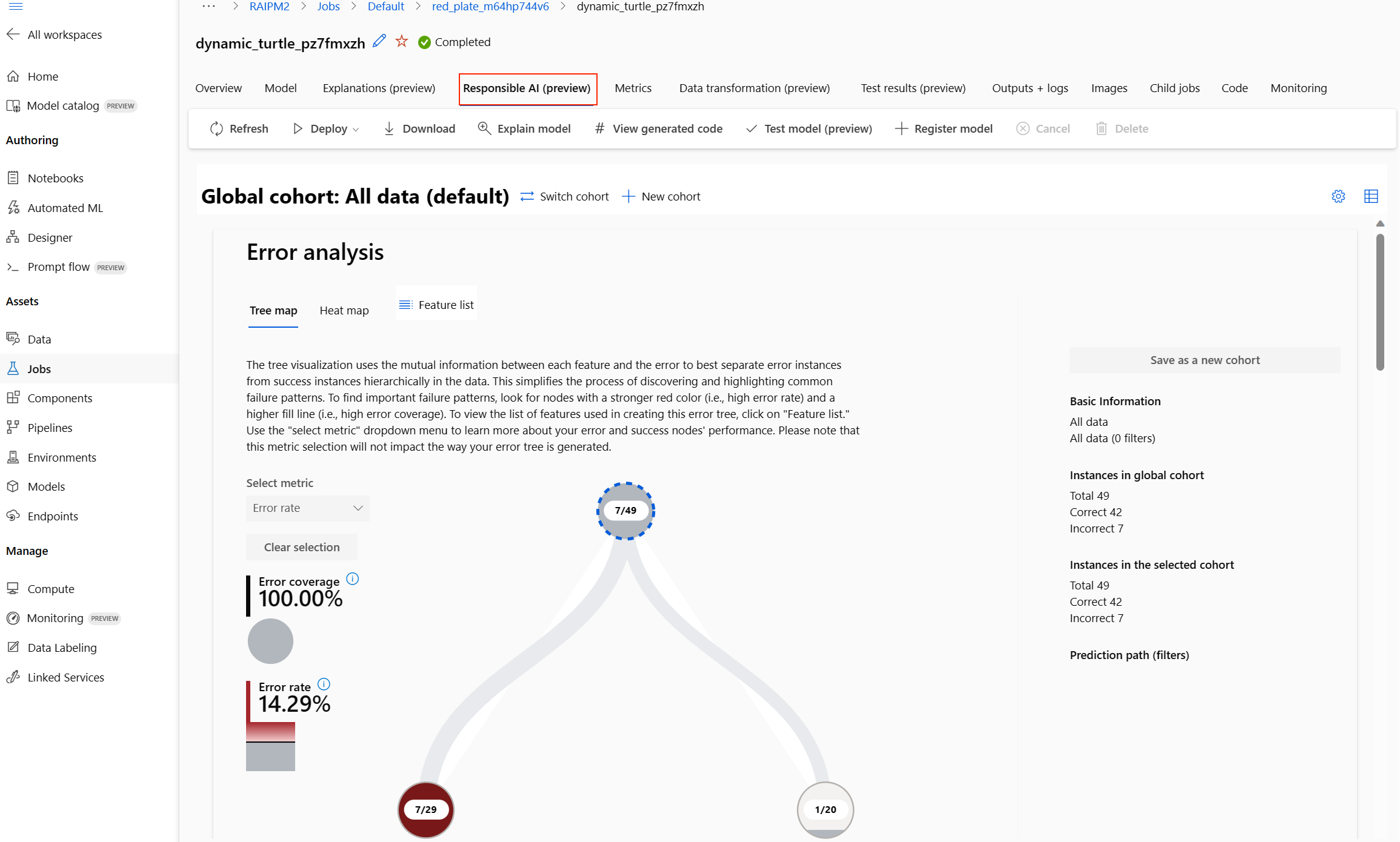
Auf dem Dashboard finden Sie vier Komponenten, die für das beste Modell Ihres automatisierten ML aktiviert sind:
| Komponente | Was zeigt die Komponente an? | Erläuterung zum Diagramm |
|---|---|---|
| Fehleranalyse | Verwenden Sie die Fehleranalyse, wenn Sie Folgendes erreichen müssen: Ein tiefes Verständnis dafür gewinnen, wie Modellfehler über ein Dataset und über mehrere Eingabe- und Featuredimensionen verteilt sind Die aggregierten Leistungsmetriken aufschlüsseln, um automatisch fehlerhafte Kohorten zu erkennen und gezielte Maßnahmen zur Risikominderung zu ergreifen |
Fehleranalysediagramme |
| Modellübersicht und Fairness | Verwenden Sie diese Komponente für Folgendes: Gewinnen Sie einen tiefen Einblick in die Leistung Ihres Modells über verschiedene Datenkohorten hinweg. Verstehen Sie die Probleme mit der Fairness Ihres Modells, indem Sie sich die Ungleichheitsmetriken ansehen. Mit diesen Metriken können Sie das Verhalten des Modells in Untergruppen bewerten und vergleichen, die anhand von sensitiven (oder nicht sensitiven) Merkmalen identifiziert wurden. |
Modellübersicht und Fairnessdiagramme |
| Modellerklärungen | Verwenden Sie die Komponente zur Modellerläuterung, um verständliche Beschreibungen der Vorhersagen eines Modells für maschinelles Lernen zu erstellen, indem Sie Folgendes betrachten: Globale Erläuterungen: Welche Merkmale beeinflussen beispielsweise das Gesamtverhalten eines Kreditvergabemodells? Lokale Erklärungen: Warum wurde beispielsweise der Kreditantrag eines Kunden genehmigt oder abgelehnt? |
Diagramme zur Modellerklärbarkeit |
| Datenanalyse | Verwenden Sie die Datenanalyse, wenn Sie Folgendes erreichen müssen: Erkunden Ihrer Datasetstatistiken durch Auswahl verschiedener Filter, um Ihre Daten in verschiedene Dimensionen zu unterteilen (auch als Kohorten bezeichnet). Verstehen der Verteilung Ihres Datasets auf verschiedene Kohorten und Featuregruppen. Ermitteln, ob Ihre Ergebnisse in Bezug auf Fairness, Fehleranalyse und Kausalität (die von anderen Dashboardkomponenten abgeleitet wurden) ein Ergebnis der Verteilung Ihres Datasets sind Entscheiden, in welchen Bereichen mehr Daten gesammelt werden sollen, um Fehler aufgrund von Repräsentationsproblemen, Bezeichnungsrauschen, Featurerauschen, Bezeichnungsverzerrungen und ähnlichen Faktoren zu minimieren |
Data Explorer Diagramme |
- Sie können außerdem Kohorten erstellen (Untergruppen von Datenpunkten, die bestimmte Merkmale gemeinsam haben), um Ihre Analyse der einzelnen Komponenten auf verschiedene Kohorten zu konzentrieren. Der Name der aktuell auf das Dashboard angewendeten Kohorte wird immer oben links auf Ihrem Dashboard angezeigt. Die Standardansicht in Ihrem Dashboard ist Ihr gesamtes Dataset, mit der Überschrift „Alle Daten“ (standardmäßig). Weitere Informationen zur globalen Steuerung Ihrer Dashboard finden Sie hier.
Bearbeiten und Übermitteln von Aufträgen (Vorschau)
Wichtig
Die Möglichkeit, ein neues Experiment basierend auf einem vorhandenen Experiment zu kopieren, zu bearbeiten und zu übermitteln, ist eine Previewfunktion. Diese Funktion ist eine experimentelle Previewfunktion, die jederzeit geändert werden kann.
In Szenarien, in denen Sie ein neues Experiment basierend auf den Einstellungen eines vorhandenen Experiments erstellen möchten, bietet das automatisierte maschinelle Lernen die Möglichkeit, dies über die Schaltfläche Bearbeiten und übermitteln auf der Studio-Benutzeroberfläche zu erreichen.
Diese Funktionalität ist auf Experimente beschränkt, die über die Studio-Benutzeroberfläche initiiert wurden, und erfordert, dass das Datenschema für das neue Experiment mit dem des ursprünglichen Experiments übereinstimmt.
Mit der Schaltfläche Bearbeiten und übermitteln wird der Assistent Erstellen eines neuen automatisierten ML-Auftrags geöffnet, in dem die Einstellungen für Daten, Compute und Experimente bereits ausgefüllt sind. Sie können jedes Formular durchlaufen und die Auswahl nach Bedarf für Ihr neues Experiment bearbeiten.
Bereitstellen Ihres Modells
Sobald Ihnen das beste Modell vorliegt, ist es an der Zeit, es als Webdienst einzusetzen, um Vorhersagen für neue Daten zu treffen.
Tipp
Wenn Sie ein Modell bereitstellen möchten, das über das automl-Paket mit dem Python SDK generiert wurde, müssen Sie Ihr Modell im Arbeitsbereich registrieren.
Nachdem Sie Ihr Modell registriert haben, navigieren Sie im Studio zu diesem, indem Sie im linken Bereich auf Modelle klicken. Sobald Sie Ihr Modell geöffnet haben, können Sie oben auf Bereitstellen klicken und dann die Anweisungen ausführen, die unter Schritt 2 des Abschnitts Bereitstellen Ihres Modells beschrieben werden.
Automatisiertes maschinelles Lernen unterstützt Sie dabei, das Modell bereitzustellen, ohne Code zu schreiben:
Sie haben einige Optionen für die Bereitstellung.
Option 1: Stellen Sie das beste Modell gemäß den von Ihnen definierten Metrikkriterien bereit.
- Navigieren Sie nach Abschluss des Experiments zur Seite mit dem übergeordneten Auftrag, indem Sie oben auf dem Bildschirm Auftrag 1 auswählen.
- Wählen Sie das Modell aus, das im Abschnitt Zusammenfassung des besten Modells aufgeführt ist.
- Wählen Sie oben links im Fenster Bereitstellen aus.
Option 2: Stellen Sie eine bestimmte Modelliteration aus diesem Experiment bereit.
- Wählen Sie das gewünschte Modell auf der Registerkarte Modelle aus.
- Wählen Sie oben links im Fenster Bereitstellen aus.
Füllen Sie den Bereich Modell bereitstellen aus.
Feld Wert Name Geben Sie einen eindeutigen Namen für die Bereitstellung ein. BESCHREIBUNG Geben Sie eine Beschreibung ein, um den Zweck dieser Bereitstellung genauer anzugeben. Computetyp Wählen Sie den Typ des Endpunkts, den Sie bereitstellen möchten: Azure Kubernetes Service (AKS) oder Azure Containerinstanz (ACI). Computename Nur für AKS: Wählen Sie den Namen des AKS-Clusters aus, der als Ziel für die Bereitstellung verwendet werden soll. Authentifizierung aktivieren Wählen Sie diese Option aus, um eine token- oder schlüsselbasierte Authentifizierung zu ermöglichen. Use custom deployment assets (Benutzerdefinierte Bereitstellungsressourcen verwenden) Aktivieren Sie dieses Feature, wenn Sie Ihr eigenes Bewertungsskript und Ihre eigene Umgebungsdatei hochladen möchten. Andernfalls stellt die automatisierte ML diese Assets standardmäßig für Sie bereit. Weitere Informationen zu Bewertungsskripts finden Sie hier. Wichtig
Ein Dateiname muss weniger als 32 Zeichen haben und muss mit einem alphanumerischen Zeichen beginnen und enden. Dazwischen darf ein Name Bindestriche, Unterstriche, Punkte und alphanumerische Zeichen enthalten. Leerzeichen sind nicht zulässig.
Das Menü Erweitert enthält Standard-Bereitstellungsfeatures wie Datensammlung und Einstellungen für die Ressourcenauslastung. Wenn Sie diese Standardeinstellungen überschreiben möchten, verwenden Sie dafür dieses Menü.
Klicken Sie auf Bereitstellen. Die Bereitstellung kann bis zu 20 Minuten dauern. Sobald die Bereitstellung beginnt, wird die Registerkarte Modellzusammenfassung angezeigt. Der Status der Bereitstellung wird im Abschnitt Bereitstellungsstatus angezeigt.
Nun haben Sie einen einsatzfähigen Webdienst, mit dem Vorhersagen generiert werden können! Sie können die Vorhersagen testen, indem Sie den Dienst über die in Power BI integrierte Azure Machine Learning-Unterstützung abfragen.