Was ist Azure Machine Learning?
Azure Machine Learning ist ein Cloud-Service zur Beschleunigung und Verwaltung des Lebenszyklus von Machine Learning (ML) Projekten. ML-Experten, Datenwissenschaftler und Ingenieure können es in ihren täglichen Arbeitsabläufen zum Trainieren und Bereitstellen von Modellen und zur Verwaltung von maschinellen Lernvorgängen (MLOps) verwenden.
Sie können ein Modell in Machine Learning erstellen oder ein Modell verwenden, das auf einer Open-Source-Plattform wie PyTorch, TensorFlow oder scikit-learn erstellt wurde. MLOps-Tools helfen Ihnen beim Überwachen, erneuten Trainieren und erneuten Bereitstellen von Modellen.
Tipp
Kostenlose Testversion! Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus. Sie erhalten dann eine Gutschrift, die Sie für Azure-Dienste einlösen können. Wenn das Guthaben aufgebraucht ist, können Sie das Konto behalten und weiterhin kostenlose Azure-Dienste nutzen. Ihre Kreditkarte wird nur dann belastet, wenn Sie Ihre Einstellungen explizit ändern und mit der Berechnung von Gebühren einverstanden sind.
Für wen ist Azure Machine Learning geeignet?
Machine Learning richtet sich an Einzelpersonen und Teams, die MLOps in ihrem Unternehmen implementieren, um ML-Modelle in einer sicheren und überprüfbaren Produktionsumgebung in Produktion zu bringen.
Datenwissenschaftler und ML-Ingenieure können Tools nutzen, um ihre täglichen Arbeitsabläufe zu beschleunigen und zu automatisieren. Anwendungsentwickler können Werkzeuge für die Integration von Modellen in Anwendungen oder Dienste verwenden. Plattformentwickler können eine robuste Reihe von Tools verwenden, die von langlebigen Azure Resource Manager-APIs unterstützt werden, um fortschrittliche ML-Tools zu erstellen.
Unternehmen, die in der Microsoft Azure-Cloud arbeiten, können die vertraute Sicherheit und rollenbasierte Zugriffskontrolle für die Infrastruktur nutzen. Sie können ein Projekt einrichten, um den Zugriff auf geschützte Daten zu verweigern und Vorgänge auszuwählen.
Produktivität für alle Teammitglieder
ML-Projekte erfordern oft ein Team mit unterschiedlichen Fähigkeiten, um sie aufzubauen und zu pflegen. Das maschinelle Lernen verfügt über Werkzeuge, die Sie dabei unterstützen:
Zusammenarbeit mit Ihrem Team über gemeinsam genutzte Notebooks, Rechenressourcen, serverlose Berechnungen, Daten und Umgebungen
Entwickeln von Modellen für Fairness und Erklärbarkeit, Nachverfolgung und Überwachbarkeit, um Complianceanforderungen im Zusammenhang mit Datenherkunft und Überwachung zu erfüllen
Schnelles und einfaches Bereitstellen von ML-Modellen im großen Stil sowie effizientes Verwalten und Steuern der Modelle mit MLOps
Ortsunabhängiges Ausführen von Machine Learning-Workloads mit integrierter Governance, Sicherheit und Compliance
Plattformübergreifende kompatible Tools, die Ihren Anforderungen entsprechen
Jedes Mitglied eines ML-Teams kann seine bevorzugten Tools für die Erledigung seiner Aufgaben verwenden. Unabhängig davon, ob Sie schnelle Experimente ausführen, Hyperparameter optimieren, Pipelines erstellen oder Rückschlüsse verwalten: Sie können vertraute Schnittstellen verwenden, darunter:
Bei der Verfeinerung des Modells und der Zusammenarbeit mit anderen während des gesamten Entwicklungszyklus des maschinellen Lernens können Sie Assets, Ressourcen und Metriken für Ihre Projekte auf der Benutzeroberfläche des Studios für maschinelles Lernen freigeben und finden.
Studio
Machine Learning Studio bietet je nach Art des Projekts und dem Grad Ihrer bisherigen ML-Erfahrung mehrere Autorenerfahrungen, ohne dass Sie etwas installieren müssen.
Notebooks: Schreiben und führen Sie Ihren eigenen Code in verwalteten Jupyter Notebook Servern aus, die direkt in das Studio integriert sind. Sie können die Notebooks auch in VS Code, im Web oder auf dem Desktop öffnen.
Visualisierung von Laufmetriken: Analysieren und optimieren Sie Ihre Experimente mit Visualisierung.
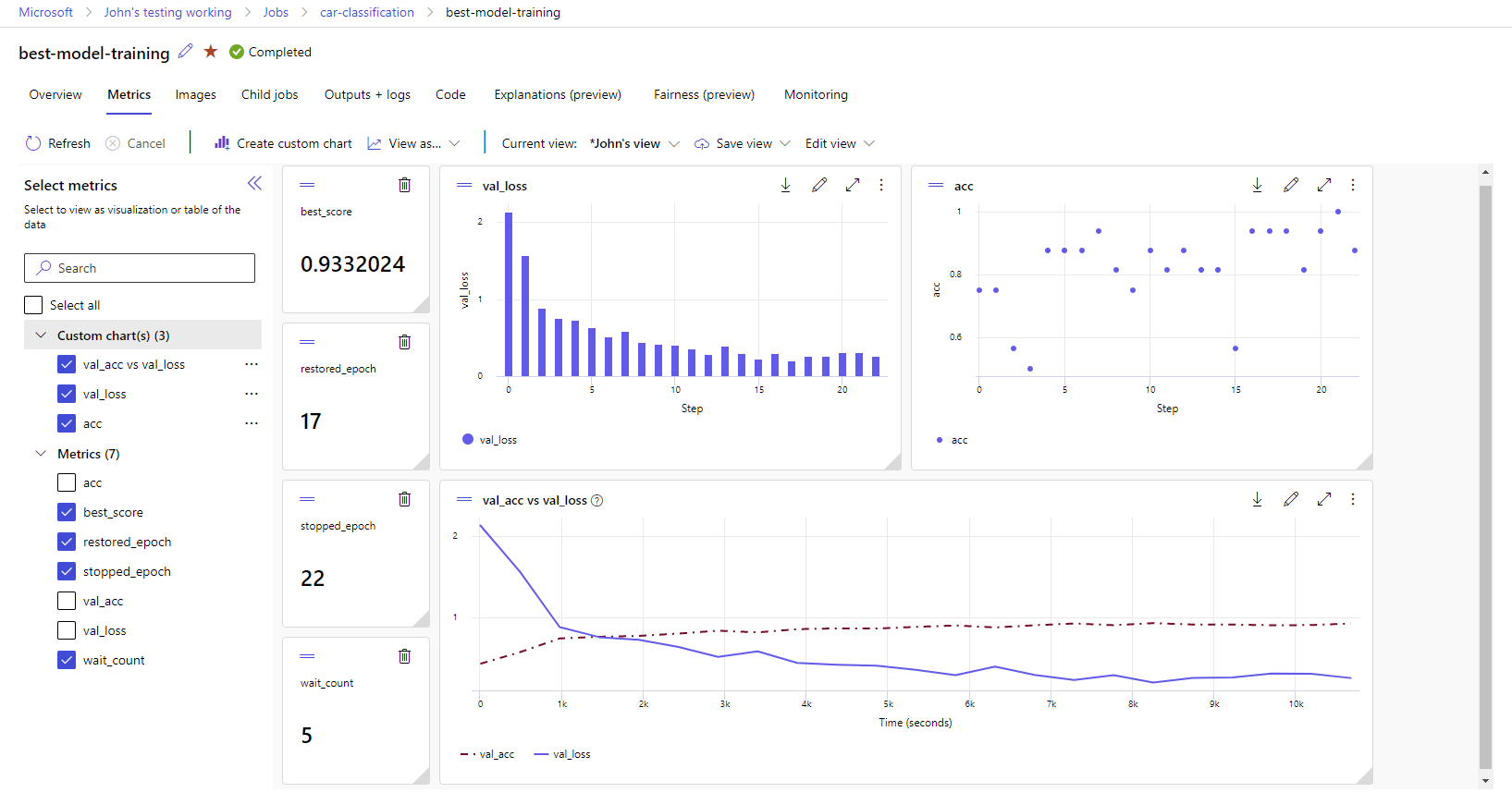
Azure Machine Learning Designer: Verwenden Sie den Designer, um ML-Modelle zu trainieren und einzusetzen, ohne Code schreiben zu müssen. Verschieben Sie Datasets und Komponenten per Drag & Drop, um ML-Pipelines zu erstellen.
Automatisiertes maschinelles Lernen UI: Lernen Sie, wie man automatisierte ML-Experimente mit einer benutzerfreundlichen Oberfläche erstellt.
Datenbeschriftung: Verwenden Sie die Datenbeschriftung mit maschinellem Lernen, um Projekte zur Bildbeschriftung oder Textbeschriftung effizient zu koordinieren.
Arbeiten mit LLMs und generativer KI
Azure Machine Learning enthält Tools, mit denen Sie generative KI-Anwendungen erstellen können, die von LLMs (Large Language Models, große Sprachmodelle) unterstützt werden. Die Lösung umfasst einen Modellkatalog, einen Prompt Flow und verschiedene Tools, um den Entwicklungszyklus von KI-Anwendungen zu optimieren.
Sowohl Azure Machine Learning Studio als auch Azure KI Studio ermöglichen Ihnen die Arbeit mit LLMs. Verwenden Sie diesen Leitfaden, um zu bestimmen, welches Studio am besten geeignet ist.
Modellkatalog
Der Modellkatalog in Azure Machine Learning Studio ist der Hub, über den Sie eine Vielzahl von Modellen entdecken und verwenden können, mit denen Sie generative KI-Anwendungen erstellen können. Der Modellkatalog enthält Hunderte von Modellen von Modellanbietern wie Azure OpenAI Service, Mistral, Meta, Cohere, Nvidia und Hugging Face, darunter auch Modelle, die von Microsoft trainiert wurden. Modelle von anderen Anbietern als Microsoft sind Nicht-Microsoft-Produkte, wie in den Produktbedingungen von Microsoft definiert und unterliegen den mit dem Modell gelieferten Geschäftsbedingungen.
prompt flow
Azure Machine Learning-Prompt-Flow ist ein Entwicklungstool, das dazu dient, den gesamten Entwicklungszyklus von KI-Anwendungen zu optimieren, die auf LLMs (Large Language Models, große Sprachmodelle) basieren. Prompt flow bietet eine umfassende Lösung, die den Prozess der Prototyperstellung, des Experimentierens, Durchlaufens und Bereitstellens Ihrer KI-Anwendungen vereinfacht.
Unternehmensbereitschaft und -sicherheit
Machine Learning lässt sich in die Azure-Cloud-Plattform integrieren, um die Sicherheit von ML-Projekten zu erhöhen.
Sicherheitsintegrationen umfassen Folgendes:
- Azure Virtual Networks mit Netzwerksicherheitsgruppen.
- Azure Key Vault, in dem Sie Sicherheitsgeheimnisse, wie z. B. Zugriffsinformationen für Speicherkonten, speichern können.
- Azure Container Registry wird hinter einem virtuellen Netzwerk eingerichtet.
Weitere Informationen finden Sie unter Tutorial: Einrichten eines sicheren Arbeitsbereichs.
Azure-Integrationen für vollständige Lösungen
Andere Integrationen mit Azure-Diensten unterstützen ein ML-Projekt von Anfang bis Ende. Dazu gehören:
- Azure Synapse Analytics, das für die Verarbeitung und das Streaming von Daten mit Spark verwendet wird.
- Azure Arc, wo Sie Azure-Dienste in einer Kubernetes-Umgebung ausführen können.
- Speicher- und Datenbankoptionen, wie z. B. Azure SQL Database und Azure Blob Storage.
- Azure App Service, mit dem Sie ML-gesteuerte Anwendungen bereitstellen und verwalten können.
- Microsoft Purview, mit dem Sie Datenbestände in Ihrem Unternehmen aufspüren und katalogisieren können.
Wichtig
Azure Machine Learning speichert oder verarbeitet Ihre Daten nicht außerhalb der Region, in der Sie diese bereitstellen.
Projektworkflow für maschinelles Lernen
In der Regel werden Modelle im Rahmen eines Projekts entwickelt, das ein Ziel und eine Zielsetzung hat. Projekte umfassen häufig mehr als eine Person. Wenn Sie mit Daten, Algorithmen und Modellen experimentieren, ist die Entwicklung iterativ.
Projektlebenszyklus
Der Projektlebenszyklus kann von Projekt zu Projekt variieren, sieht aber oft wie dieses Diagramm aus.
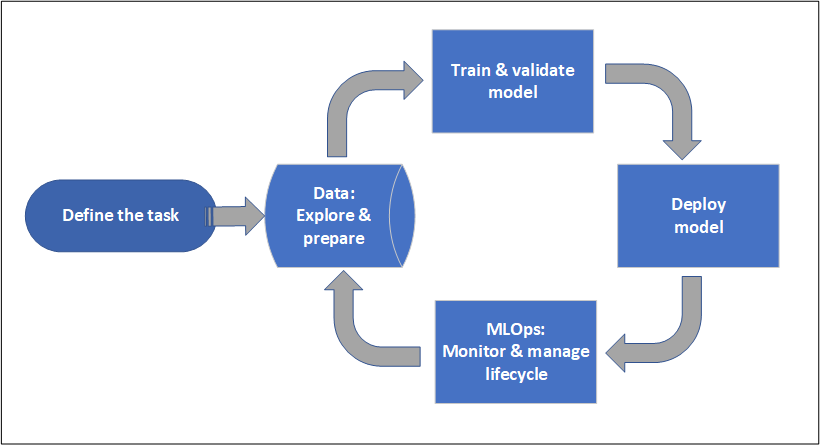
Ein Arbeitsbereich organisiert ein Projekt und ermöglicht die Zusammenarbeit für viele Benutzer, die alle an einem gemeinsamen Ziel arbeiten. Benutzer in einem Arbeitsbereich können die Ergebnisse ihrer Experimentierläufe einfach über die Studio-Benutzeroberfläche austauschen. Oder sie können versionierte Assets für Aufgaben wie Umgebungen und Speicherreferenzen verwenden.
Weitere Informationen finden Sie unter Verwalten von Azure Machine Learning-Arbeitsbereichen.
Wenn ein Projekt einsatzbereit ist, kann die Arbeit der Benutzer in einer ML-Pipeline automatisiert und nach einem Zeitplan oder einer HTTPS-Anfrage ausgelöst werden.
Sie können Modelle für die verwaltete Inferenzlösung bereitstellen, und zwar sowohl für Echtzeit- als auch für Batch-Bereitstellungen, so dass die Infrastrukturverwaltung, die normalerweise für die Bereitstellung von Modellen erforderlich ist, entfällt.
Trainieren von Modellen
In Azure Machine Learning können Sie Ihr Trainingsskript in der Cloud ausführen oder ein Modell von Grund auf neu erstellen. Kunden bringen oft Modelle mit, die sie in Open-Source-Frameworks entwickelt und trainiert haben, um sie in der Cloud zu operationalisieren.
Offen und interoperabel
Wissenschaftliche Fachkräfte für Daten können Modelle in Azure Machine Learning verwenden, die sie in allgemeinen Python-Frameworks erstellt haben. Beispiel:
- PyTorch
- TensorFlow
- scikit-learn
- XGBoost
- LightGBM
Andere Sprachen und Frameworks werden ebenfalls unterstützt:
- R
- .NET
Weitere Informationen finden Sie unter Open-Source-Integration mit Azure Machine Learning.
Automatisierte Featurierung und Algorithmenauswahl
In einem sich wiederholenden, zeitaufwändigen Prozess nutzen Datenwissenschaftler in der klassischen ML vorherige Erfahrung und Intuition, um die richtige Datenfeaturisierung und den richtigen Algorithmus für das Training auszuwählen. Automatisierte ML (AutoML) beschleunigt diesen Prozess. Sie können es über die Benutzeroberfläche von Machine Learning Studio oder das Python-SDK verwenden.
Für weitere Informationen siehe Was ist automatisiertes maschinelles Lernen?.
Hyperparameteroptimierung
Die Hyperparameteroptimierung kann eine mühsame Aufgabe darstellen. Maschinelles Lernen kann diese Aufgabe für beliebige parametrisierte Befehle automatisieren, ohne dass Ihre Auftragsdefinition geändert werden muss. Ergebnisse werden in Studio visualisiert.
Für weitere Informationen siehe Optimierung von Hyperparametern.
Verteiltes Training mit mehreren Knoten
Die Effizienz des Trainings für Deep Learning und manchmal klassische Machine Learning-Trainingsaufträge kann durch verteiltes Training mit mehreren Knoten drastisch verbessert werden. Azure Machine Learning Compute Clusters und serverloses Computing bieten die neuesten GPU-Optionen.
Unterstützt über Azure Machine Learning Kubernetes, Azure Machine Learning Compute-Cluster und serverloses Computing:
- PyTorch
- TensorFlow
- MPI
Sie können die MPI-Verteilung für Horovod oder benutzerdefinierte Multinode-Logik verwenden. Apache Spark wird über serverlose Spark-Berechnungen und angeschlossene Synapse Spark-Pools unterstützt, die Azure Synapse Analytics Spark-Cluster verwenden.
Weitere Informationen finden Sie unter Verteiltes Training mit Azure Machine Learning.
Hochgradig paralleles Training
Die Skalierung eines ML-Projekts kann die Skalierung einer peinlich parallelen Modellschulung erfordern. Dieses Muster ist bei Szenarien wie der Nachfrageprognose üblich, bei der ein Modell für viele Geschäfte trainiert werden kann.
Bereitstellen von Modellen
Um ein Modell in die Produktion zu bringen, stellen Sie das Modell bereit. Die verwalteten Endpunkte von Azure Machine Learning abstrahieren die erforderliche Infrastruktur für die Echtzeit- (Online) oder Batchmodellbewertung (Rückschlüsse).
Echtzeit- und Batchbewertung (Rückschließen)
Die Batchbewertung oder das Batchrückschließenumfasst das Aufrufen eines Endpunkts mit einem Verweis auf Daten. Der Batchendpunkt führt Aufträge asynchron aus, um Daten parallel auf Computeclustern zu verarbeiten und die Daten zur weiteren Analyse zu speichern.
Beim Echtzeit-Scoring oder Online-Inferencing wird ein Endpunkt mit einer oder mehreren Modellverteilungen aufgerufen und eine Antwort in nahezu Echtzeit über HTTPS empfangen. Der Datenverkehr kann auf mehrere Bereitstellungen aufgeteilt werden, so dass neue Modellversionen getestet werden können, indem zunächst ein gewisser Teil des Datenverkehrs umgeleitet und dann, wenn das Vertrauen in das neue Modell gefestigt ist, erhöht wird.
Weitere Informationen finden Sie unter:
- Bereitstellen eines Modells mit einem verwalteten Echtzeitendpunkt
- Verwenden von Batchendpunkten für die Bewertung
MLOps: DevOps für maschinelles Lernen
DevOps für ML-Modelle, oft als MLOps bezeichnet, ist ein Prozess zur Entwicklung von Modellen für die Produktion. Der Lebenszyklus eines Modells vom Training bis zur Bereitstellung muss überwachbar, wenn nicht gar reproduzierbar sein.
Lebenszyklus von ML-Modellen
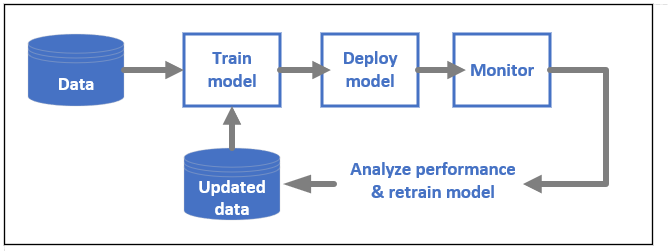
Erfahren Sie mehr über MLOps in Azure Machine Learning.
Integrationen zum Aktivieren von MLOPs
Beim maschinellen Lernen wird der Lebenszyklus des Modells berücksichtigt. Sie können den Modelllebenszyklus bis zu einem bestimmten Commit und einer bestimmten Umgebung überwachen.
Einige wichtige Features, die MLOps ermöglichen, sind:
- Integration in
git - MLflow-Integration.
- Pipeline-Planung durch maschinelles Lernen.
- Azure Event Grid-Integration für benutzerdefinierte Auslöser.
- Einfache Nutzung mit CI/CD-Tools wie GitHub Actions oder Azure DevOps.
Das maschinelle Lernen umfasst auch Funktionen zur Überwachung und Prüfung:
- Auftragsartefakte, wie z. B. Code-Snapshots, Protokolle und andere Ausgaben.
- Verbindung zwischen Aufträgen und Ressourcen, wie Containern, Daten und Rechenressourcen.
Wenn Sie Apache Airflow verwenden, ist das Paket airflow-provider-azure-machinelearning ein Anbieter, mit dem Sie Workflows von Apache AirFlow an Azure Machine Learning übermitteln können.
Zugehöriger Inhalt
Starten der Verwendung von Azure Machine Learning: