Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Die Azure Machine Learning-Integration mit Azure Synapse Analytics bietet einfachen Zugriff auf verteilte Computingfunktionen – unterstützt durch Azure Synapse –, um Apache Spark-Aufträge in Azure Machine Learning zu skalieren.
In diesem Artikel erfahren Sie, wie Sie einen Spark-Auftrag mithilfe einer serverlosen Spark-Compute-Instanz von Azure Machine Learning, eines Azure Data Lake Storage Gen 2-Speicherkontos (ADLS) und eines Passthrough der Benutzeridentität in wenigen einfachen Schritten übermitteln.
Für weitere Informationen zu Apache Spark in Azure Machine Learning-Konzepten besuchen Sie diese Ressource.
Voraussetzungen
GILT FÜRAzure CLI-ML-Erweiterung v2 (aktuell)
- Ein Azure-Abonnement: Sollten Sie über kein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Ein Azure Machine Learning-Arbeitsbereich. Für weitere Informationen besuchen Sie Erstellen eines Arbeitsbereichs.
- Ein ADLS Gen2-Speicherkonto (Azure Data Lake Storage). Für weitere Informationen besuchen Sie Erstellen eines Azure Data Lake Storage (ADLS) Gen 2-Speicherkontos.
- Erstellen einer Compute-Instanz von Azure Machine Learning
- Installieren Sie die Azure Machine Learning-CLI.
Hinzufügen von Rollenzuweisungen in Azure-Speicherkonten
Bevor wir einen Apache Spark-Auftrag übermitteln, müssen wir sicherstellen, dass auf die Eingabe- und Ausgabedatenpfade zugegriffen werden kann. Weisen Sie der Benutzeridentität des angemeldeten Benutzers die Rollen Mitwirkender und Mitwirkender an Speicherblobdaten zu, um Lese- und Schreibzugriff zu aktivieren.
So weisen Sie der Benutzeridentität geeignete Rollen zu
Öffnen Sie das Microsoft Azure-Portal.
Suchen Sie nach dem Dienst Speicherkonten, und wählen Sie ihn aus.

Wählen Sie auf der Seite Speicherkonten in der Liste das Speicherkonto Azure Data Lake Storage Gen 2 (ADLS) aus. Die Seite Übersicht des Speicherkontos wird geöffnet.
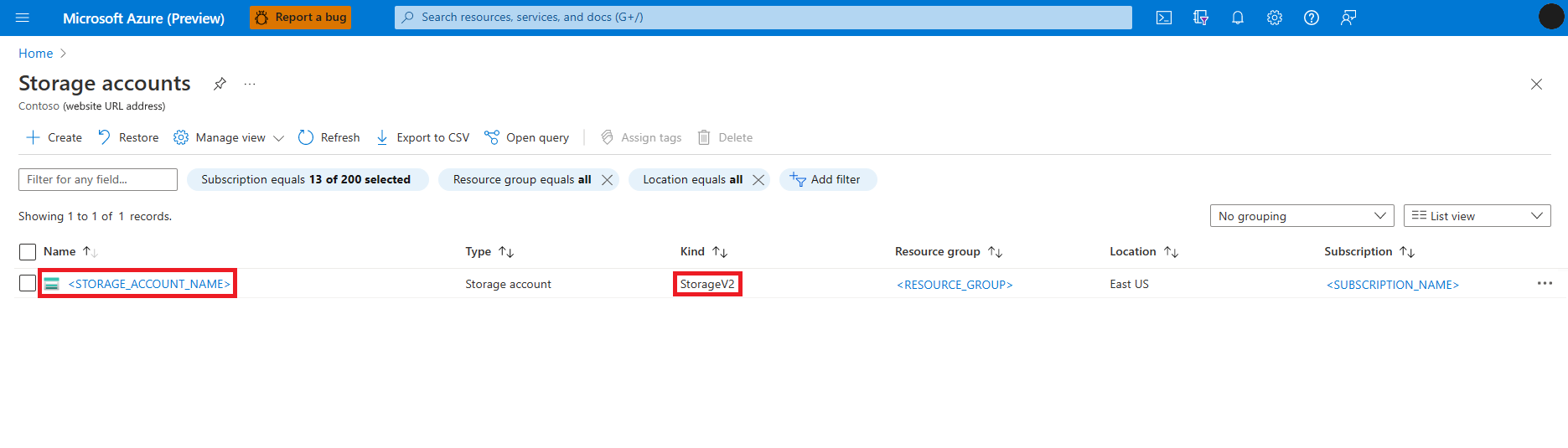
Wählen Sie im linken Bereich Zugriffssteuerung (IAM) aus.
Wählen Sie Rollenzuweisung hinzufügen aus.
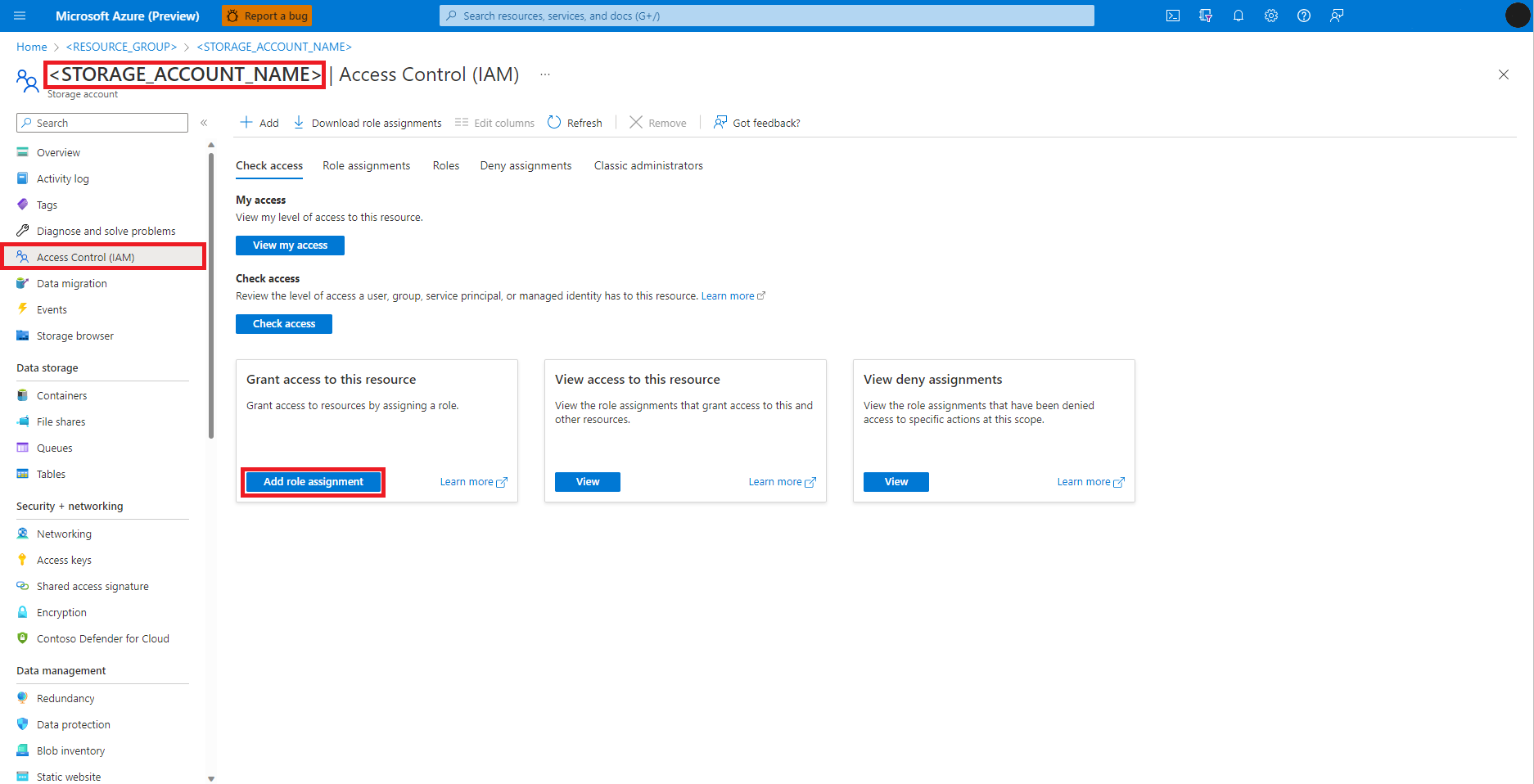
Suchen Sie nach der Rolle Mitwirkender an Speicherblobdaten.
Wählen Sie die Rolle Mitwirkender an Storage-Blobdaten aus.
Wählen Sie Weiter aus.
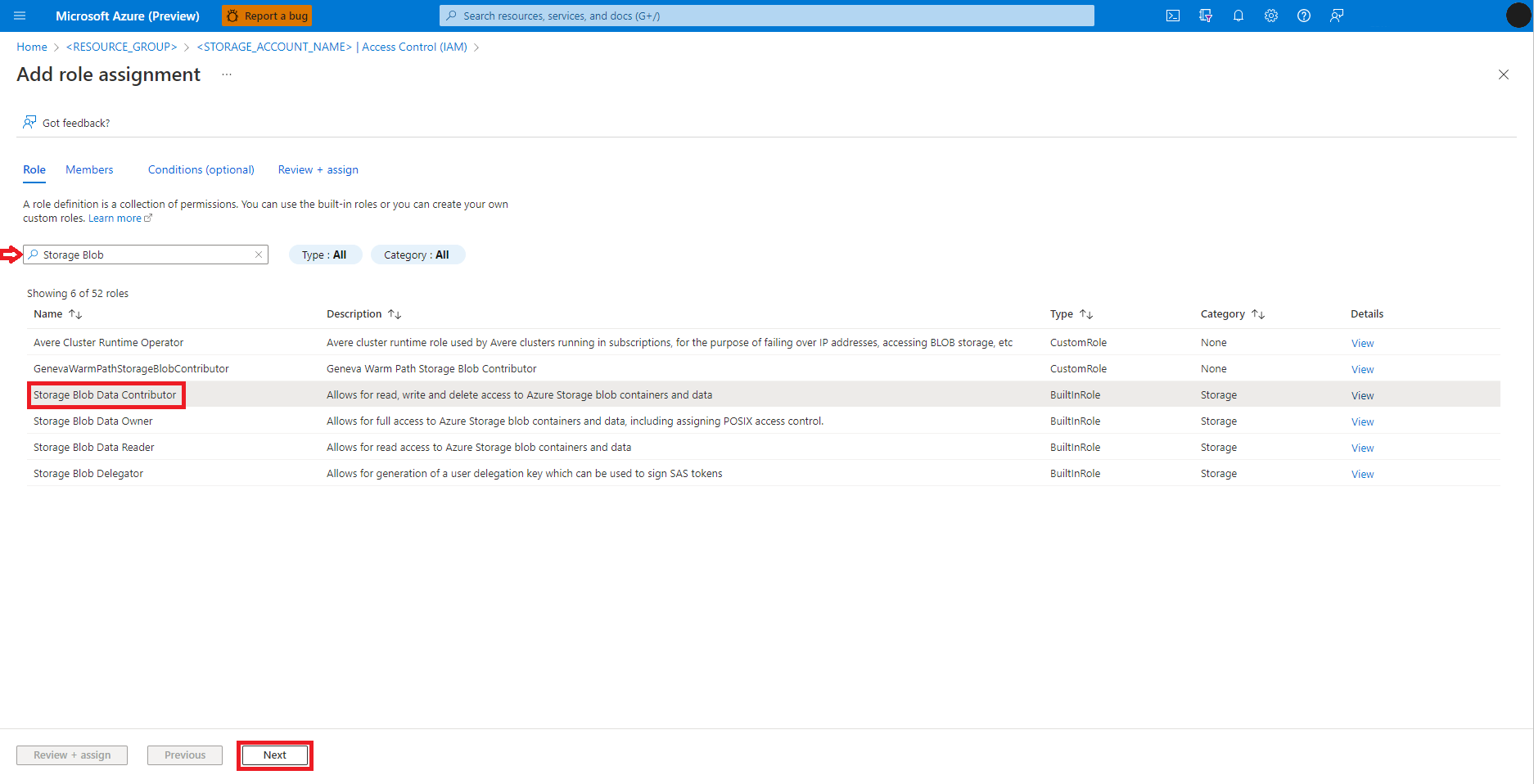
Wählen Sie User, group, or service principal (Benutzer, Gruppe oder Dienstprinzipal) aus.
Wählen Sie + Mitglieder auswählen aus.
Suchen Sie im Textfeld unter Auswählen nach der Benutzeridentität.
Wählen Sie die Benutzeridentität in der Liste aus, sodass sie unter Ausgewählte Mitglieder angezeigt wird.
Wählen Sie die entsprechende Benutzeridentität aus.
Wählen Sie Weiter aus.
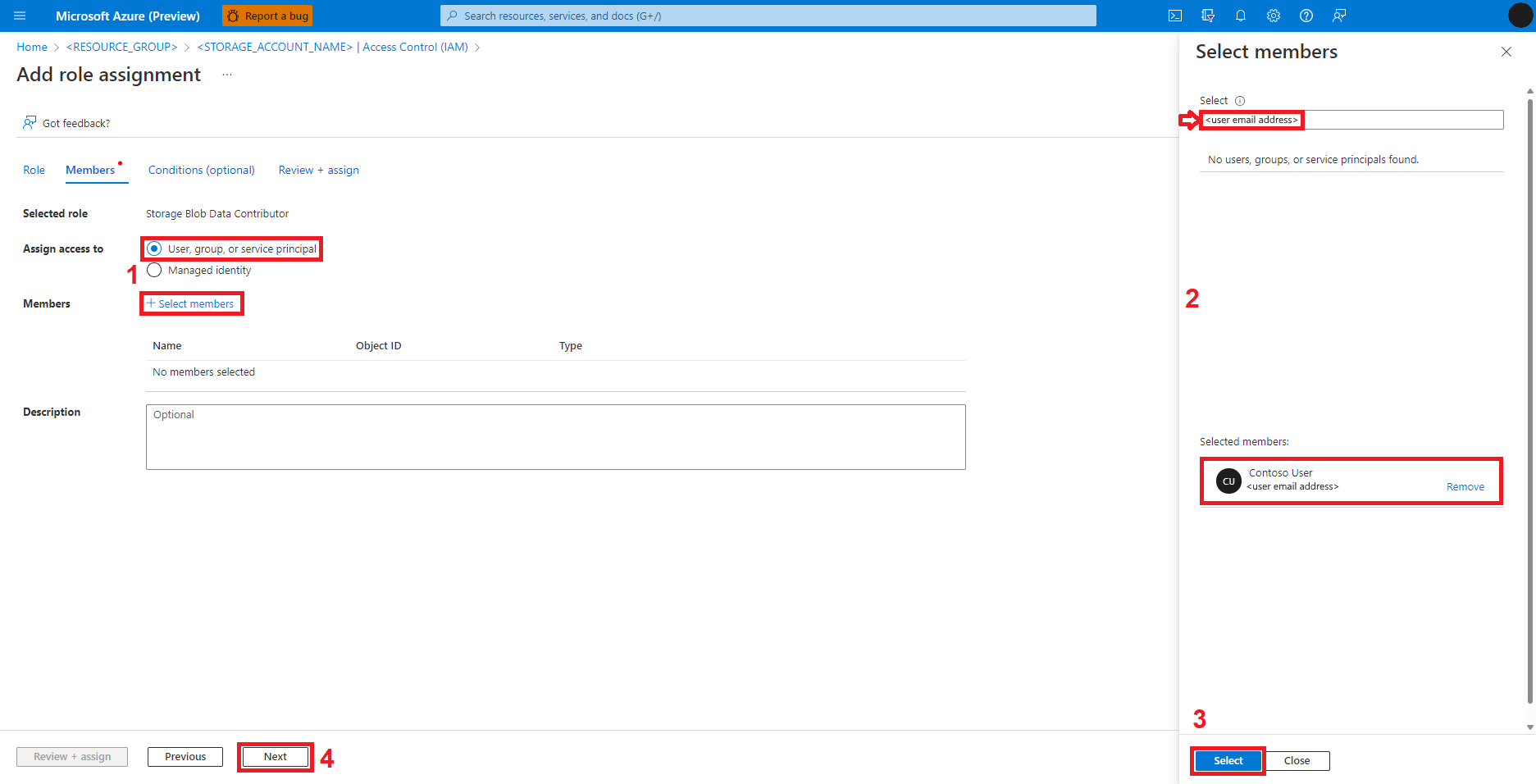
Wählen Sie Überprüfen und zuweisen aus.
Wiederholen Sie die Schritte 2 bis 13 für die Zuweisung der Rolle Storage Blob-Mitwirkender.






Die Daten im Azure Data Lake Storage (ADLS) Gen2-Speicherkonto sollten zugänglich werden, sobald der Benutzeridentität die entsprechenden Rollen zugewiesen wurden.
Erstellen von parametrisiertem Python-Code
Ein Spark-Auftrag erfordert ein Python-Skript, das Argumente akzeptiert. Um dieses Skript zu erstellen, können Sie den Python-Code ändern, der aus interaktivem Data Wrangling entwickelt wurde. Ein Python-Beispielskript wird hier gezeigt:
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Hinweis
- Dieses Python-Codebeispiel verwendet
pyspark.pandas, das nur durch die Spark-Runtimeversion 3.2 unterstützt wird. - Stellen Sie sicher, dass die Datei
titanic.pyin einen Ordner namenssrchochgeladen wird. Der Ordnersrcsollte sich im selben Verzeichnis befinden, in dem Sie das Python-Skript/Notebook oder die YAML-Spezifikationsdatei erstellt haben, die den eigenständigen Spark-Auftrag definiert.
Das Skript akzeptiert zwei Argumente: --titanic_data und --wrangled_data. Diese Argumente übergeben den Eingabedatenpfad bzw. den Ausgabeordner. Das Skript verwendet die titanic.csv-Datei (hier verfügbar). Laden Sie diese Datei in einen Container hoch, der im Azure Data Lake Storage (ADLS) Gen 2-Speicherkonto erstellt wurde.
Übermitteln eines eigenständigen Spark-Auftrags
GILT FÜRAzure CLI-ML-Erweiterung v2 (aktuell)
Tipp
Sie können einen Spark-Auftrag an folgenden Stellen übermitteln:
- das Terminal einer Azure Machine Learning-Compute-Instanz.
- das Terminal von Visual Studio Code, verbunden mit einer Azure Machine Learning-Compute-Instanz.
- Auf Ihrem lokalen Computer mit installierter Azure Machine Learning CLI
Diese YAML-Beispielspezifikation zeigt einen eigenständigen Spark-Auftrag. Es verwendet eine serverlose Spark-Compute-Instanz von Azure Machine Learning, ein Passthrough der Benutzeridentität und einen URI für Eingabe-/Ausgabedaten im Format abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>. Hier entspricht <FILE_SYSTEM_NAME> dem Containernamen.
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./src
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.2"
In der obigen YAML-Spezifikationsdatei:
- Die Eigenschaft
codedefiniert den relativen Pfad des Ordners, der eine parametrisiertetitanic.py-Datei enthält. - die
resource-Eigenschaft definiert deninstance_typeund die Apache Spark-Werteruntime_version, die von serverlosem Spark-Compute verwendet werden. Diese Werte für Instanztypen werden derzeit unterstützt:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
Die gezeigte YAML-Dateie kann im Befehl az ml job create mit dem Parameter --file verwendet werden, um einen eigenständigen Spark-Auftrag wie dargestellt zu erstellen:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Tipp
Möglicherweise verfügen Sie über einen vorhandenen Synapse Spark-Pool in Ihrem Azure Synapse-Arbeitsbereich. Wenn Sie einen vorhandenen Synapse Spark-Pool verwenden möchten, befolgen Sie die Anweisungen zum Anfügen eines Synapse Spark-Pools in einen Azure Machine Learning-Arbeitsbereich.
Nächste Schritte
- Apache Spark in Azure Machine Learning
- Schnellstart: Interaktives Data Wrangling mit Apache Spark
- Anfügen und Verwalten eines Synapse Spark-Pools in Azure Machine Learning
- Interaktives Data Wrangling mit Apache Spark in Azure Machine Learning
- Übermitteln von Spark-Aufträgen in Azure Machine Learning
- Codebeispiele für Spark-Aufträge mithilfe der Azure Machine Learning-CLI
- Codebeispiele für Spark-Aufträge mit dem Azure Machine Learning Python-SDK