Der TDSP ist eine flexible, iterative Data Science-Methodik, die Sie zur effizienten Bereitstellung von Predictive Analytics-Lösungen und KI-Anwendungen verwenden können. Der TDSP verbessert die Teamzusammenarbeit und das Lernen, indem optimale Möglichkeiten für die Zusammenarbeit zwischen Teamrollen empfohlen werden. Das TDSP enthält bewährte Methoden und Frameworks von Microsoft und anderen Branchenführern, um Ihr Team bei der effektiven Implementierung von Data Science-Initiativen zu unterstützen. Der TDSP ermöglicht Ihnen, die Vorteile Ihres Analyseprogramms vollständig zu nutzen.
Dieser Artikel bietet eine Übersicht über den TDSP und seine Hauptkomponenten. Er enthält Anleitungen für die Implementierung des TDSP mit Microsoft-Tools und -Infrastruktur. Sie finden im Artikel auch Informationen zu ausführlicheren Ressourcen.
Hauptkomponenten des TDSP
Der TDSP umfasst die folgenden Hauptkomponenten:
- Definition des Data Science-Lebenszyklus
- Standardisierte Projektstruktur
- Infrastruktur und Ressourcen, die für Data Science-Projekte ideal sind
- Verantwortungsbewusste K:: und Engagement für die Weiterentwicklung der KI, unterstützt von ethischen Prinzipien
Data Science-Lebenszyklus
Der TDSP stellt einen Lebenszyklus bereit, mit dem Sie die Entwicklung Ihrer Data Science-Projekte strukturieren können. Der Lebenszyklus beschreibt sämtliche Schritte für erfolgreiche Projekte.
Sie können den aufgabenbasierten TDSP mit anderen Data Science-Lebenszyklen kombinieren, z. B.dem Cross Industry Standard Process for Data Mining (CRISP-DM), dem Knowledge Discovery in Databases (KDD)-Prozess oder anderen, benutzerdefinierten Prozessen. Auf allgemeiner Ebene haben diese verschiedenen Methodiken viel gemeinsam.
Verwenden Sie diesen Lebenszyklus, wenn Sie an einem Data Science-Projekt arbeiten, das Teil einer intelligenten Anwendung ist. Intelligente Anwendungen stellen Machine-Learning- oder KI-Modelle für Predictive Analytics bereit. Sie können diesen Prozess auch für explorative Data Science-Projekte und improvisierte Analyseprojekte verwenden.
Der TDSP-Lebenszyklus besteht aus fünf Hauptphasen, die von Ihrem Team immer wieder durchgeführt werden. Diese Phasen umfassen:
Dies ist eine visuelle Darstellung des TDSP-Lebenszyklus:
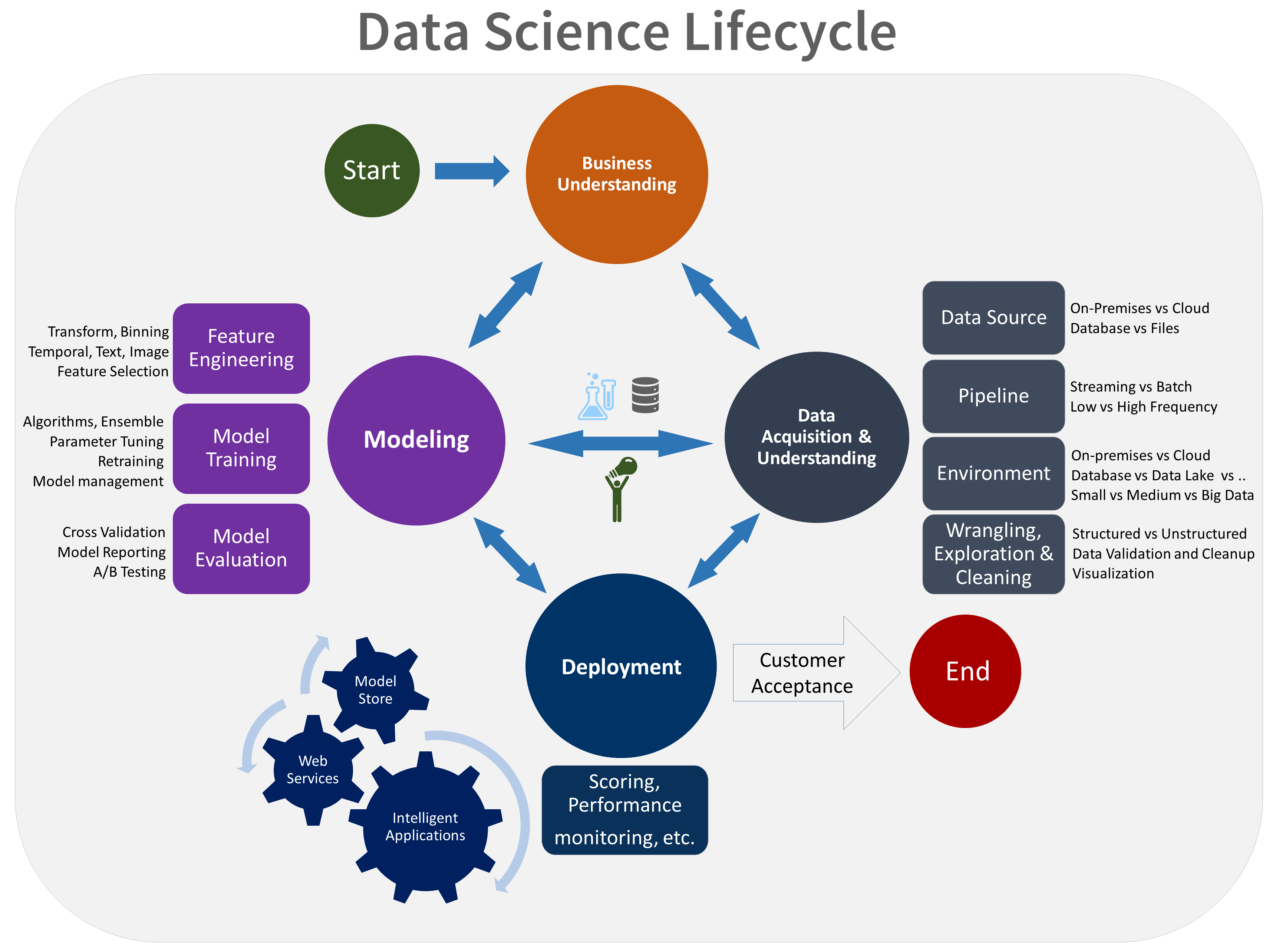
Weitere Informationen zu den Zielen, Aufgaben und Dokumentationsartefakten für jede Phase finden Sie unter Der TDSP-Lebenszyklus.
Diese Aufgaben und Artefakte sind Projektrollen zugeordnet, wie etwa:
- Lösungsarchitekt
- Projektmanager
- Datentechniker
- Data Scientist
- Anwendungsentwickler
- Projektleiter
Das folgende Diagramm zeigt die Aufgaben (blau) und Artefakte (grün), die den einzelnen Phasen des Lebenszyklus entsprechen, auf der horizontalen Achse und für die Rollen auf der vertikalen Achse.

Standardisierte Projektstruktur
Ihr Team kann zur Organisation Ihrer Data Science-Ressourcen die Azure-Infrastruktur verwenden.
Azure Machine Learning unterstützt das Open-Source-MLflow-Modell. Wir empfehlen, für die Verwaltung von Data Science- und KI-Projekten MLflow zu verwenden. MLflow wurde für die Verwaltung des gesamten Machine Learning-Lebenszyklus entwickelt. Die Lösung trainiert und implementiert Modelle auf verschiedenen Plattformen, so dass Sie einen konsistenten Satz von Tools verwenden können – unabhängig von der Umgebung, in der Ihre Experimente ausgeführt werden. Sie können MLflow lokal auf Ihrem Computer, auf einem Remote-Computeziel, auf einem virtuellen Computer oder auf einer Machine Learning Compute-Instanz verwenden.
MLflow besitzt mehrere wichtige Funktionen:
Nachverfolgen von Experimenten: Mit MLflow können Sie Experimente nachverfolgen, einschließlich Parametern, Codeversionen, Metriken und Ausgabedateien. Mithilfe dieser Funktion können Sie verschiedene Ausführungen vergleichen und den Experimentierprozess effizient verwalten.
Paketcode: Dieser stellt ein standardisiertes Format zum Paketieren von Machine Learning-Code bereit, das Abhängigkeiten und Konfigurationen umfasst. Diese Paketierung vereinfacht das Reproduzieren von Ausführungen und Teilen von Code mit anderen Mitgliedern des Teams.
Management von Modellen: MLflow stellt Funktionen zum Management und für die Versionierung von Modellen bereit. Die Lösung unterstützt verschiedene Machine Learning-Frameworks, so dass Sie Modelle speichern, versionieren und bereitstellen können.
Bereitstellen von Modellen: MLflow integriert Funktionen für die Bereitstellung von Modellen, so dass Sie Modelle problemlos in verschiedenen Umgebungen bereitstellen können.
Registrieren von Modellen: Sie können den Lebenszyklus eines Modells verwalten, einschließlich Versionsverwaltung, Phasenübergängen und Anmerkungen. Mit MLflow können Sie in einer Teamumgebung einen zentralen Modellspeicher vorhalten.
Verwenden einer API und Benutzeroberfläche: In Azure ist MLflow in Machine Learning API Version 2 gebündelt, sodass Sie programmgesteuert mit dem System interagieren können. Sie können für die Interaktion mit einer Benutzeroberfläche das Azure-Portal verwenden.
MLflow vereinfacht und standardisiert die Machine Learning-Entwicklung, vom Experiment bis zur Bereitstellung.
Machine Learning ist in Git-Repositorys integriert, so dass Sie mit Git kompatible Services verwenden können wie GitHub, GitLab, Bitbucket, Azure DevOps oder einen anderen mit Git kompatiblen Service. Zusätzlich zu den Ressourcen, die im Machine Learning bereits nachverfolgt werden, kann Ihr Team eine eigene Taxonomie innerhalb des mit Git kompatiblen Services entwickeln, um weitere Projektdaten zu speichern, z. B.:
- Dokumentation
- Projektdaten: z. B. der endgültige Projektbericht
- Datenbericht: z. B. Datenwörterbuch oder Berichte zur Datenqualität
- Modell: z. B. Modellberichte
- Code
- Datenaufbereitung
- Modellentwicklung
- Operationalisierung, einschließlich Sicherheit und Compliance
Infrastruktur und Ressourcen
Das TDSP enthält Empfehlungen für das Management von gemeinsam genutzten Analyse- und Speicherinfrastrukturen in den folgenden Kategorien:
- Cloud-Dateisysteme zum Speichern von Datasets
- Cloud-Datenbanken
- Big Data-Cluster, die SQL oder Spark verwenden
- KI- und Machine Learning-Dienste
Cloud-Dateisysteme zum Speichern von Datasets
Cloud-Dateisysteme sind aus verschiedenen Gründen für das TDSP von entscheidender Bedeutung:
Zentralisierte Datenspeicherung: Cloud-Dateisysteme bieten einen zentralisierten Speicherort zum Speichern von Datasets, was für die Zusammenarbeit zwischen den Mitgliedern des Data Science-Teams unerlässlich ist. Durch die Zentralisierung wird sichergestellt, dass alle Teammitglieder auf die aktuellsten Daten zugreifen können, und das Risiko verringert, mit veralteten oder inkonsistenten Datasets zu arbeiten.
Skalierbarkeit: Cloud-Dateisysteme können große Datenmengen verarbeiten, wie sie in Data Science-Projekten üblich sind. Die Dateisysteme bieten skalierbare Speicherlösungen, die mit den Anforderungen des Projekts wachsen. Sie ermöglichen Teams, sehr große Datasets zu speichern und zu verarbeiten, ohne sich Gedanken über Hardwareeinschränkungen machen zu müssen.
Zugänglichkeit: Mit Cloud-Dateisystemen können Sie von überall aus über eine Internetverbindung auf Daten zugreifen. Dies ist wichtig für verteilte Teams, oder wenn Teammitglieder an anderen Standorten arbeiten müssen. Cloud-Dateisysteme unterstützen die nahtlose Zusammenarbeit und stellen sicher, dass Daten immer zugänglich sind.
Sicherheit und Compliance: Cloud-Anbieter implementieren häufig robuste Sicherheitsmaßnahmen, einschließlich Verschlüsselung, Zugriffskontrollen und der Einhaltung von Branchenstandards und -vorschriften. Starke Sicherheitsmaßnahmen können vertrauliche Daten schützen und Ihrem Team dabei helfen, rechtliche und behördliche Anforderungen zu erfüllen.
Versionssteuerung: Cloud-Dateisysteme beinhalten häufig Versionssteuerungsfeatures, mit denen Teams Änderungen an Datasets im Laufe der Zeit nachverfolgen können. Die Versionssteuerung ist sehr wichtig, um die Integrität der Daten zu wahren und die Ergebnisse in Data Science-Projekten reproduzieren zu können. Außerdem hilft sie dabei, auftretende Probleme zu überwachen und zu beheben.
Integration mit Tools: Cloud-Dateisysteme können nahtlos in verschiedene Data Science-Tools und -Plattformen integriert werden. Die Tool-Integration unterstützt eine einfachere Datenerfassung, Datenverarbeitung und Datenanalyse. Azure Storage lässt sich beispielsweise gut in Machine Learning, Azure Databricks und andere Data Science-Tools integrieren.
Zusammenarbeit und Freigabe: Cloud-Dateisysteme erleichtern das Freigeben von Datasets für andere Teammitglieder oder Projektbeteiligte. Diese Systeme unterstützen Features für die Zusammenarbeit wie freigegebene Ordner und die Berechtigungsverwaltung. Features für die Zusammenarbeit erleichtern die Teamarbeit und stellen sicher, dass stets die richtigen Personen Zugriff auf die benötigten Daten haben.
Kosteneffizienz: Cloud-Dateisysteme können kostengünstiger sein als lokale Speicherlösungen. Cloud-Anbieter bieten flexible Preismodelle mit Pay-as-you-go-Optionen, die dabei helfen können, Kosten basierend auf den tatsächlichen Nutzungs- und Speicheranforderungen Ihres Data Science-Projekts zu verwalten.
Notfallwiederherstellung: Cloud-Dateisysteme beinhalten in der Regel Features für die Datensicherung und Notfallwiederherstellung. Dies tragen zum Schutz der Daten vor Hardwarefehlern, versehentlichen Löschungen und anderen Katastrophen bei. Sie bieten Ruhe und unterstützen die Kontinuität bei Data Science-Operationen.
Automatisierungs- und Workflow-Integration: Cloud-Speichersysteme können in automatisierte Workflows integriert werden, die die nahtlose Datenübertragung zwischen verschiedenen Phasen des Data Science-Prozesses ermöglichen. Die Automatisierung kann dazu beitragen, die Effizienz zu verbessern und den erforderlichen manuellen Aufwand für die Verwaltung von Daten zu verringern.
Empfohlene Azure-Ressourcen für Cloud-Dateisysteme
- Azure Blob Storage – Umfassende Dokumentation zu Azure Blob Storage, einem skalierbaren Objektspeicherservice für unstrukturierte Daten.
- Azure Data Lake Storage – Informationen zu Azure Data Lake Storage Gen2, entwickelt für Big Data Analytics und die Unterstützung sehr großer Datasets.
- Azure Files - Details zu Azure Files, das vollständig verwaltete Dateifreigaben in der Cloud bereitstellt.
Zusammenfassend sind Cloud-Dateisysteme für von entscheidender Bedeutung für TDSP, da sie skalierbare, sichere und zugängliche Speicherlösungen bereitstellen, die den gesamten Datenlebenszyklus unterstützen. Cloud-Dateisysteme ermöglichen die nahtlose Datenintegration aus unterschiedlichen Quellen, was die umfassende Datenerfassung und das Verständnis der Daten unterstützt. Data Scientists können Cloud-Dateisysteme verwenden, um große Datasets effizient zu speichern, zu verwalten und darauf zuzugreifen. Diese Funktionalität ist für das Training und die Bereitstellung von Machine Learning-Modellen unerlässlich. Diese Systeme verbessern auch die Zusammenarbeit dadurch, dass Teammitglieder Daten in einer einheitlichen Umgebung freigeben und gleichzeitig daran arbeiten können. Cloud-Dateisysteme bieten robuste Sicherheitsfeatures, die dazu beitragen, Daten zu schützen und die Einhaltung gesetzlicher Anforderungen zu gewährleisten, was für die Aufrechterhaltung der Datenintegrität und des Vertrauens von entscheidender Bedeutung ist.
Cloud-Datenbanken
Cloud-Datenbanken spielen aus mehreren Gründen eine wichtige Rolle im TDSP:
Skalierbarkeit: Cloud-Datenbanken bieten skalierbare Lösungen, die leicht wachsen können, um den zunehmenden Datenanforderungen eines Projekts gerecht zu werden. Skalierbarkeit ist für Data Science-Projekte, die häufig große und komplexe Datasets verarbeiten, von entscheidender Bedeutung. Cloud-Datenbanken können unterschiedliche Workloads verarbeiten, ohne dass manuelle Eingriffe oder Hardwareupgrades erforderlich sind.
Leistungsoptimierung: Entwickler*innen optimieren Cloud-Datenbanken für die Leistung mithilfe von Funktionen wie automatische Indizierung, Abfrageoptimierung und Lastenausgleich. Diese Features tragen dazu bei, dass das Abrufen und Verarbeiten von Daten schnell und effizient vor sich geht, was für Data Science-Aufgaben von entscheidender Bedeutung ist, die Echtzeit- oder Nahezu-Echtzeit-Datenzugriff erfordern.
Zugänglichkeit und Zusammenarbeit: Teams können von jedem Ort aus auf in Cloud-Datenbanken gespeicherte Daten zugreifen. Dies fördert die Zusammenarbeit zwischen Teammitgliedern, die geographisch verteilt arbeiten. Zugänglichkeit und Zusammenarbeit sind wichtig für verteilte Teams oder Personen, die an anderen Standorten arbeiten. Cloud-Datenbanken unterstützen Mehrbenutzerumgebungen mit gleichzeitigem Zugriff und Zusammenarbeitsmöglichkeiten.
Integration mit Data Science-Tools: Cloud-Datenbanken lassen sich nahtlos in verschiedene Data Science-Tools und -Plattformen integrieren. Beispielsweise können Azure-Cloud-Datenbanken sehr gut in Machine Learning-, Power BI- und andere Datenanalysetools integriert werden. Diese Integration optimiert die Datenpipeline von der Datenaufnahme und Speicherung bis hin zu Analyse und Visualisierung.
Sicherheit und Compliance: Cloud-Anbieter implementieren robuste Sicherheitsmaßnahmen, einschließlich Verschlüsselung, Zugriffskontrollen und der Einhaltung von Branchenstandards und -vorschriften. Sicherheitsmaßnahmen schützen vertrauliche Daten und helfen Ihrem Team dabei, rechtliche und behördliche Anforderungen zu erfüllen. Sicherheitsfeatures sind für die Aufrechterhaltung der Datenintegrität und des Datenschutzes von entscheidender Bedeutung.
Kosteneffizienz: Cloud-Datenbanken verwenden häufig ein Pay-as-you-go-Modell, das kostengünstiger sein kann als die Nutzung lokaler Datenbanksysteme. Diese Preisflexibilität ermöglicht Organisationen, ihre Budgets effektiv zu verwalten und nur für die von ihnen wirklich verwendeten Speicher- und Computeressourcen zu bezahlen.
Automatische Sicherungen und Notfallwiederherstellung: Cloud-Datenbanken bieten automatische Sicherungs- und Notfallwiederherstellungslösungen. Diese Lösungen verhindern Datenverluste, wenn Hardwarefehler, versehentliche Löschungen oder andere Katastrophen auftreten. Zuverlässigkeit ist von entscheidender Bedeutung für die Aufrechterhaltung der Datenkontinuität und Integrität in Data Science-Projekten.
Datenverarbeitung in Echtzeit: Viele Cloud-Datenbanken unterstützen die Datenverarbeitung und -analyse in Echtzeit, was für Data Science-Aufgaben, die immer die aktuellsten Informationen erfordern, unerlässlich ist. Dies hilft Datenwissenschaftlern, zeitnahe Entscheidungen basierend auf den neuesten verfügbaren Daten zu treffen.
Datenintegration: Cloud-Datenbanken können problemlos in andere Datenquellen, Datenbanken, Data Lakes und externe Datenfeeds integriert werden. Die Integration hilft Datenwissenschaftlern dabei, Daten aus mehreren Quellen zu kombinieren und ermöglicht eine umfassende Ansicht sowie anspruchsvollere Analysen.
Flexibilität und Vielfalt: Cloud-Datenbanken können verschiedene Formen haben, wie etwa relationale Datenbanken, NoSQL-Datenbanken und Data Warehouses. Mit dieser Vielfalt können Data Science-Teams den besten Datenbanktyp für ihre spezifischen Anforderungen auswählen, unabhängig davon, ob sie die Speicherung strukturierter Daten, den Umgang mit unstrukturierten Daten oder umfangreiche Datenanalysen benötigen.
Unterstützung für erweiterte Analysen: Cloud-Datenbanken bieten häufig integrierte Unterstützung für erweiterte Analysen und maschinelles Lernen. Beispielsweise stellt Azure SQL Database integrierte Machine Learning Services bereit. Diese helfen Datenwissenschaftlern dabei, erweiterte Analysen direkt in der Datenbankumgebung durchzuführen.
Empfohlene Azure-Ressourcen für Cloud-Datenbanken
- Azure SQL Database – Dokumentation zu Azure SQL Database, einem vollständig verwalteten relationalen Datenbankservice.
- Azure Cosmos DB - Informationen zu Azure Cosmos DB, einem global verteilten, multimodellbasierten Datenbankservice.
- Azure Database for PostgreSQL - Leitfaden zu Azure Database for PostgreSQL, einem verwalteten Datenbankservice f+r die Entwicklung und Bereitstellung von Apps
- Azure Database for MySQL - Details zu Azure Database for MySQL, einem verwalteten Service für MySQL-Datenbanken.
Zusammenfassend sind Cloud-Datenbanken für TDSP von entscheidender Bedeutung, da sie skalierbare, zuverlässige und effiziente Datenspeicher- und Verwaltungslösungen bereitstellen, die datengesteuerte Projekte unterstützen. Sie ermöglichen die nahtlose Datenintegration, die Datenwissenschaftler dabei unterstützt, große Datasets aus unterschiedlichen Quellen zu erfassen, vorzuverarbeiten und zu analysieren. Cloud-Datenbanken ermöglichen schnelle Abfragen und Datenverarbeitung, die für die Entwicklung, Prüfung und Bereitstellung von Machine Learning-Modellen unerlässlich sind. Darüber hinaus verbessern Cloud-Datenbanken die Zusammenarbeit durch die Bereitstellung einer zentralen Plattform für Teammitglieder für den gleichzeitigen Zugriff und die gleichzeitige Arbeit mit Daten. Und schließlich bieten Cloud-Datenbanken erweiterte Sicherheitsfeatures und Compliance-Unterstützung, um Daten geschützt und mit gesetzlichen Standards kompatibel zu halten, was für die Aufrechterhaltung der Datenintegrität und des Vertrauens von entscheidender Bedeutung ist.
Big Data-Cluster, die SQL oder Spark verwenden
Big Data-Cluster, z. B. solche, die SQL oder Spark verwenden, sind aus verschiedenen Gründen grundlegend für TDSP:
Umgang mit großen Datenmengen: Big Data-Cluster sind so konzipiert, dass sehr große Datenmengen effizient verarbeitet werden können. Zu Data Science-Projekten gehören häufig sehr große Datasets, die die Kapazität herkömmlicher Datenbanken überschreiten. SQL-basierte Big Data-Cluster und Spark können solche Daten in großem Umfang verwalten und verarbeiten.
Verteiltes Computing: Big Data-Cluster verwenden verteiltes Computing, um Daten und Computing-Aufgaben über mehrere Knoten hinweg zu verteilen. Die parallele Verarbeitungsfunktion beschleunigt Datenverarbeitungs- und Analyseaufgaben erheblich, was unerlässlich ist, um in Data Science-Projekten zeitnahe Erkenntnisse zu erhalten.
Skalierbarkeit: Big Data-Cluster bieten hohe Skalierbarkeit, sowohl horizontal durch Hinzufügen weiterer Knoten, als auch vertikal durch die Erhöhung der Leistung vorhandener Knoten. Die Skalierbarkeit trägt dazu bei, dass die Dateninfrastruktur mit den Anforderungen des Projekts wächst, indem die Datengrößen und -komplexität erhöht werden.
Integration mit Data Science-Tools: Big Data-Cluster sind gut in verschiedene Data Science-Tools und -Plattformen integrierbar. So lässt sich Spark beispielsweise nahtlos in Hadoop integrieren, und SQL-Cluster arbeiten mit verschiedenen Datenanalysetools zusammen. Die Integration erleichtert einen reibungslosen Workflow von der Datenerfassung bis hin zur Analyse und Visualisierung.
Erweiterte Analysen: Big Data-Cluster unterstützen erweiterte Analysen und maschinelles Lernen. So stellt Spark beispielsweise die folgenden integrierten Bibliotheken bereit:
- Machine Learning, MLlib
- Graph-Verarbeitung, GraphX
- Streamverarbeitung, Spark Streaming
Diese Funktionen helfen Datenwissenschaftlern dabei, komplexe Analysen direkt im Cluster durchzuführen.
Datenverarbeitung in Echtzeit: Big Data-Cluster, insbesondere solche, die Spark verwenden, unterstützen die Datenverarbeitung in Echtzeit. Die ist von entscheidender Bedeutung für Projekte , die minutengenaue Datenanalysen und Entscheidungsfindung erfordern. Die Echtzeitverarbeitung hilft in Szenarien wie Betrugserkennung, Echtzeitempfehlungen und dynamischer Preisgestaltung.
Datentransformation und Extrahieren, Transformieren, Laden (ETL): Big Data-Cluster eignen sich ideal für Datentransformations- und ETL-Prozesse. Sie können komplexe Datentransformationen, Bereinigungs- und Aggregierungsaufgaben effizient verarbeiten, die häufig erforderlich sind, bevor Daten analysiert werden können.
Kosteneffizienz: Big Data-Cluster können kosteneffizient sein, insbesondere wenn Sie cloudbasierte Lösungen wie Azure Databricks und andere Cloud-Services verwenden. Diese Services bieten flexible Preismodelle, einschließlich Pay-as-you-go, was kostengünstiger sein kann als das Vorhalten einer lokalen Big Data-Infrastruktur.
Fehlertoleranz: Big Data-Cluster werden unter Berücksichtigung der Fehlertoleranz konzipiert. Sie replizieren Daten über Knoten hinweg, um sicherzustellen, dass das System auch dann funktionsfähig bleibt, wenn einige Knoten ausfallen. Diese Zuverlässigkeit ist entscheidend für die Aufrechterhaltung der Datenintegrität und Verfügbarkeit in Data Science-Projekten.
Data Lake-Integration: Big Data-Cluster lassen sich häufig nahtlos in Data Lakes integrieren, mit denen Datenwissenschaftler auf einheitliche Weise auf verschiedene Datenquellen zugreifen und diese analysieren können. Die Integration unterstützt umfassendere Analysen mit einer Kombination aus strukturierten und unstrukturierten Daten.
SQL-basierte Verarbeitung: Für Datenwissenschaftler, die mit SQL vertraut sind, bieten Big Data-Cluster, die mit SQL-Abfragen arbeiten, z. B. Spark SQL oder SQL auf Hadoop, eine vertraute Schnittstelle zum Abfragen und Analysieren von Big Data. Diese Benutzerfreundlichkeit kann den Analyseprozess beschleunigen und für eine breitere Palette von Benutzern zugänglich machen.
Zusammenarbeit und Freigabe: Big Data-Cluster unterstützen zusammenarbeitsorientierte Umgebungen, in denen mehrere Datenwissenschaftler und Analysten an denselben Datasets miteinander arbeiten können. Sie bieten Features zum Freigeben von Code, Notebooks und Ergebnissen, die Teamarbeit und Wissensaustausch fördern.
Sicherheit und Compliance: Big Data-Cluster bieten robuste Sicherheitsfeatures wie Datenverschlüsselung, Zugriffssteuerungen und Compliance mit Branchenstandards. Die Sicherheitsfeatures schützen vertrauliche Daten und helfen Ihrem Team, behördliche Anforderungen zu erfüllen.
Empfohlene Azure-Ressourcen für Big Data-Cluster
- Apache Spark in Machine Learning: Die Machine Learning-Integration in Azure Synapse Analytics ermöglicht den einfachen Zugriff auf verteilte Computingnressourcen über das Apache Spark-Framework.
- Azure Synapse Analytics: Umfassende Dokumentation für Azure Synapse Analytics, die Big Data und Data Warehousing integriert.
Zusammenfassend sind Big Data-Cluster, ob SQL oder Spark, für TDSP von entscheidender Bedeutung, da sie die Computingleistung und die Skalierbarkeit bereitstellen, die erforderlich sind, um große Datenmengen effizient zu verarbeiten. Big Data Cluster ermöglichen Datenwissenschaftlern, komplexe Abfragen und erweiterte Analysen für sehr große Datasets durchzuführen, die tiefe Einblicke ermöglichen und eine präzise Modellentwicklung ermöglichen. Wenn Sie verteiltes Computing verwenden, ermöglichen diese Cluster eine schnelle Datenverarbeitung und -analyse, wodurch der gesamte Data Science-Workflow beschleunigt wird. Big Data-Cluster unterstützen auch die nahtlose Integration mit unterschiedlichen Datenquellen und Tools, wodurch die Fähigkeit zum Erfassen, Verarbeiten und Analysieren von Daten aus mehreren Umgebungen verbessert wird. Dazu unterstützen Big Data-Cluster fördern die Zusammenarbeit und Reproduzierbarkeit, indem sie eine einheitliche Plattform bereitstellen, auf der Teams Ressourcen, Workflows und Ergebnisse effektiv gemeinsam nutzen können.
KI- und Machine Learning-Dienste
KI- und Machine Learning (ML)-Services sind aus verschiedenen Gründen integraler Bestandteil des TDSP:
Erweiterte Analysen: KI- und ML-Services ermöglichen erweiterte Analysen. Datenwissenschaftler können erweiterte Analysetechniken verwenden, um komplexe Muster aufzudecken, Vorhersagen zu erstellen und Erkenntnisse zu gewinnen, die mit herkömmlichen Analysemethoden nicht möglich sind. Diese erweiterten Funktionen sind von entscheidender Bedeutung für die Erstellung von Data Science-Lösungen mit großen positiven Auswirkungen.
Automatisierung sich wiederholender Aufgaben: KI- und ML-Services können sich wiederholende Aufgaben wie Datenbereinigung, Feature Engineering und Modelltraining automatisieren. Automatisierung spart Zeit und hilft Datenwissenschaftlern dabei, sich auf strategischere Aspekte ihres Projekts zu konzentrieren, was die Gesamtproduktivität verbessert.
Verbesserte Präzision und Leistung: ML-Modelle können die Präzision und Leistung von Prognosen und Analysen verbessern, indem sie aus Daten lernen. Diese Modelle können kontinuierlich verbessert werden, da sie immer mehr Daten ausgesetzt sind, was kontinuierlich zu besseren Entscheidungen und zuverlässigeren Ergebnissen führt.
Skalierbarkeit: KI- und ML-Dienste, die von Cloud-Plattformen wie Machine Learning bereitgestellt werden, sind hoch skalierbar. Sie können große Datenmengen und komplexe Berechnungen verarbeiten, mit denen Data Science-Teams ihre Lösungen skalieren können, um stetig zunehmenden Anforderungen gerecht zu werden, ohne sich Gedanken über Beschränkungen der zugrunde liegenden Infrastruktur machen zu müssen.
Integration mit anderen Tools: KI- und ML-Services können nahtlos in andere Tools und Services innerhalb des Microsoft-Ökosystems integriert werden, z. B. Azure Data Lake, Azure Databricks und Power BI. Die Integration unterstützt einen optimierten Workflow von der Datenerfassung und -verarbeitung bis hin zur Modellimplementierung und Visualisierung.
Modellimplementierung und -management: KI- und ML-Services bieten robuste Tools zum Bereitstellen und Verwalten von Machine Learning-Modellen in Produktionsumgebungen. Features wie Versionssteuerung, Überwachung und automatisiertes erneutes Training sorgen dafür, dass Modelle im Laufe der Zeit präzise und effektiv bleiben. Dies vereinfacht die Wartung von ML-Lösungen.
Verarbeitung in Echtzeit: KI- und ML-Services unterstützen die Datenverarbeitung und Entscheidungsfindung in Echtzeit. Die Verarbeitung in Echtzeit ist für Anwendungen, die sofortige Einblicke und Maßnahmen erfordern, unerlässlich, etwa für Betrugserkennung, dynamische Preisgestaltung und Empfehlungssysteme.
Anpassbarkeit und Flexibilität: KI- und ML-Services bieten eine Reihe anpassbarer Optionen, von vordefinierten Modellen und APIs bis hin zu Frameworks zum Erstellen von benutzerdefinierten Modellen von Grund auf. Diese Flexibilität hilft Data Science-Teams dabei, Lösungen auf bestimmte Geschäftsanforderungen und Anwendungsfälle abzustimmen.
Zugang zu modernsten Algorithmen: KI- und ML-Services bieten Datenwissenschaftlern Zugriff auf modernste Algorithmen und Technologien, die von führenden Forschern entwickelt wurden. Dieser Zugang stellt sicher, dass Teams immer die neuesten Fortschritte in den Bereichen KI und ML für ihre Projekte nutzen können.
Zusammenarbeit und Freigabe: KI- und ML-Plattformen unterstützen Entwicklungsumgebungen für die Zusammenarbeit, in denen mehrere Teammitglieder an demselben Projekt zusammenarbeiten, Code freigeben und Experimente reproduzieren können. Die Zusammenarbeit verbessert die Teamarbeit und sorgt für Konsistenz bei der Modellentwicklung.
Kosteneffizienz: KI- und ML-Services in der Cloud können kostengünstiger sein als das Erstellen und Verwalten von Lösungen vor Ort. Cloud-Anbieter bieten flexible Preismodelle, u.a. mit Pay-as-you-go-Optionen, die Kosten reduzieren und die Ressourcennutzung optimieren können.
Verbesserte Sicherheit und Compliance: KI- und ML-Services verfügen über robuste Sicherheitsfeatures, die Datenverschlüsselung, sichere Zugriffskontrollen und die Einhaltung von Branchenstandards und -vorschriften beinhalten. Diese Features tragen zum Schutz Ihrer Daten und Modelle bei und erfüllen gesetzliche und behördliche Anforderungen.
Vordefinierte Modelle und APIs: Viele KI- und ML-Services bieten vorgefertigte Modelle und APIs für allgemeine Aufgaben wie die linguistische Datenverarbeitung, Bilderkennung und Anomalieerkennung. Die vorgefertigten Lösungen können Entwicklung und Bereitstellung beschleunigen und Teams dabei helfen, KI-Funktionen schnell in ihre Anwendungen zu integrieren.
Experimente und Prototyperstellung: KI- und ML-Plattformen bieten Umgebungen für schnelle Experimente und Prototypenerstellungen. Datenwissenschaftler können schnell unterschiedliche Algorithmen, Parameter und Datasets testen, um die optimale Lösung zu finden. Experimente und Prototyperstellung unterstützen iterative Konzepte für die Modellentwicklung.
Empfohlene Azure-Ressourcen für KI- und ML-Services
Machine Learning ist die wichtigste Ressource, die wir für Data Science-Anwendungen und TDSP empfehlen. Darüber hinaus stellt Azure KI-Services bereit, die KI-Modelle für spezifische Anwendungen verwenden können.
- Machine Learning: Die zentrale Dokumentationsseite für Machine Learning mit Einrichtung, Modelltraining, bereitstellung usw.
- Azure KI Services: Informationen zu KI-Services, die vorgefertigte KI-Modelle für Vision, Speech, Sprache und Entscheidungsfindung bereitstellen.
Zusammenfassend sind KI- und ML-Services von entscheidender Bedeutung für TDSP, da sie leistungsstarke Tools und Frameworks bereitstellen, die Entwicklung, Training und Bereitstellung von Machine Learning-Modellen optimieren. Diese Services automatisieren komplexe Aufgaben wie Algorithmusauswahl und Hyperparameteroptimierung, wodurch der Modellentwicklungsprozess erheblich beschleunigt wird. Sie bieten auch eine skalierbare Infrastruktur, die Datenwissenschaftlern dabei hilft, große Datasets effizient zu verarbeiten und computingintensive Aufgaben zu bewältigen. KI- und ML-Tools werden nahtlos in andere Azure-Dienste integriert und verbessern die Datenerfassung, Vorverarbeitung und Modellimplementierung. Die Integration sorgt für einen reibungslosen durchgängigen Workflow. Darüber hinaus fördern diese Services Zusammenarbeit und Reproduzierbarkeit. Teams können Erkenntnisse miteinander teilen und effektiv mit Ergebnissen und Modellen experimentieren, während hohe Sicherheitsstandards und Compliance gewährleistet bleiben.
Verantwortungsvolle KI
Mit KI- oder ML-Lösungen fördert Microsoft verantwortungsbewusste KI-Tools. Diese Tools unterstützen den Microsoft Responsible AI Standard. Ihr Workload muss weiterhin individuell KI-bezogene Gefahren berücksichtigen.
Peer-geprüfte Referenzen
TDSP ist eine bewährte Methode, die Teams über Microsoft-Engagements hinweg verwenden. TDSP ist gut dokumentiert und Gegenstand von Fachliteratur nach akademischen Standards (Peer Review). Die Referenzen bieten die Möglichkeit, TDSP-Funktionen und -Anwendungen näher kennenzulernen. Weitere Informationen und eine Liste von Referenzen finden Sie in Der TDSP-Lebenszyklus.