Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Schnellstart erstellen Sie einen Wissensspeicher, der als Repository für die Ausgabe dient, die aus einer KI-Anreicherungspipeline in Azure AI Search erstellt wurde. Ein Wissensspeicher stellt generierte Inhalte in Azure Storage für andere Workloads als Suchen zur Verfügung.
Zunächst richten Sie einige Beispieldaten in Azure Storage ein. Als Nächstes führen Sie den Datenimport-Assistenten aus, um eine Anreicherungspipeline zu erstellen, die ebenfalls einen Wissensspeicher generiert. Der Wissensspeicher enthält Originalquelleniknhalt, der aus der Datenquelle (Kundenbewertungen eines Hotels) stammt, sowie mittels KI generierte Inhalte, die eine Stimmungsbezeichnung, Schlüsselbegriffsextraktion und Textübersetzung nicht englischsprachiger Kundenkommentare enthalten.
Voraussetzungen
Bevor Sie beginnen können, müssen die folgenden Voraussetzungen erfüllt werden:
Ein Azure-Konto mit einem aktiven Abonnement. Sie können kostenlos ein Konto erstellen.
Azure AI Search. Erstellen Sie einen Dienst, oder suchen Sie in Ihrem Konto nach einem vorhandenen Dienst. Für diesen Schnellstart können Sie einen kostenlosen Dienst verwenden.
Azure Storage. Erstellen Sie ein Konto, oder suchen Sie ein vorhandenes Konto. Der Kontotyp muss StorageV2 (universell, V2) lauten.
In Azure Storage gehostete Beispieldaten:
Laden Sie „HotelReviews_Free.csv“ herunter. Diese CSV-Datei enthält 19 Einträge mit Kundenfeedback zu einem einzigen Hotel (aus Kaggle.com). Die Datei befindet sich in einem Repository mit anderen Beispieldaten. Wenn Sie nicht das gesamte Repository brauchen, kopieren Sie den unformatierten Inhalt, und fügen Sie ihn in eine Tabellenkalkulations-App auf Ihrem Gerät ein.
Laden Sie die Datei in einen Blobcontainer in Azure Storage hoch.
In dieser Schnellstartanleitung wird außerdem Azure AI Services für die KI-Anreicherung verwendet. Aufgrund der geringen Workloadgröße wird Azure AI Services im Hintergrund für die kostenlose Verarbeitung von bis zu 20 Transaktionen genutzt. Das bedeutet, dass Sie diese Übung durchführen können, ohne eine zusätzliche Azure AI-Ressource für mehrere Dienste erstellen zu müssen.
Starten des Assistenten
Melden Sie sich mit Ihrem Azure-Konto beim Azure-Portal an.
Suchen Sie Ihren Suchdienst, und wählen Sie auf der Übersichtsseite auf der Befehlsleiste Daten importierenaus, um in vier Schritten einen Wissensspeicher zu erstellen.

Schritt 1: Erstellen einer Datenquelle
Da die Daten aus mehreren Zeilen in einer CSV-Datei bestehen, legen Sie den Analysemodus fest, um ein Suchdokument für jede Zeile zu erhalten.
Wählen Sie unter Mit Ihren Daten verbinden die Option Azure Blob Storage aus.
Geben Sie unter Name den Namen „hotel-reviews-ds“ ein.
Wählen Sie für Zu extrahierende Daten die Option Inhalt und Metadaten aus.
Wählen Sie unter Analysemodus die Option Durch Trennzeichen getrennter Text aus, und aktivieren Sie anschließend das Kontrollkästchen Erste Zeile enthält Überschrift. Vergewissern Sie sich, dass unter Trennzeichen ein Komma (,) angegeben ist.
Wählen Sie für Verbindungszeichenfolge eine vorhandene Verbindung aus, wenn das Speicherkonto Teil desselben Abonnements ist. Fügen Sie anderenfalls eine Verbindungszeichenfolge für Ihr Azure Storage-Konto ein.
Verbindungszeichenfolgen können Vollzugriff bieten. Sie weisen das folgende Format auf:
DefaultEndpointsProtocol=https;AccountName=<YOUR-ACCOUNT-NAME>;AccountKey=<YOUR-ACCOUNT-KEY>;EndpointSuffix=core.windows.netEine Verbindungszeichenfolge kann auch auf eine verwaltete Identität verweisen, sofern sie konfiguriert und einer Rolle in Azure Storage zugewiesen ist:
ResourceId=/subscriptions/<YOUR-SUBSCRIPTION-ID>/resourceGroups/<YOUR-RESOURCE-GROUP-NAME>/providers/Microsoft.Storage/storageAccounts/<YOUR-ACCOUNT-NAME>;Geben Sie unter Container den Namen des Blobcontainers ein, der die Daten enthält (hotel-reviews).
Ihre Seite sollte in etwa dem folgenden Screenshot entsprechen.
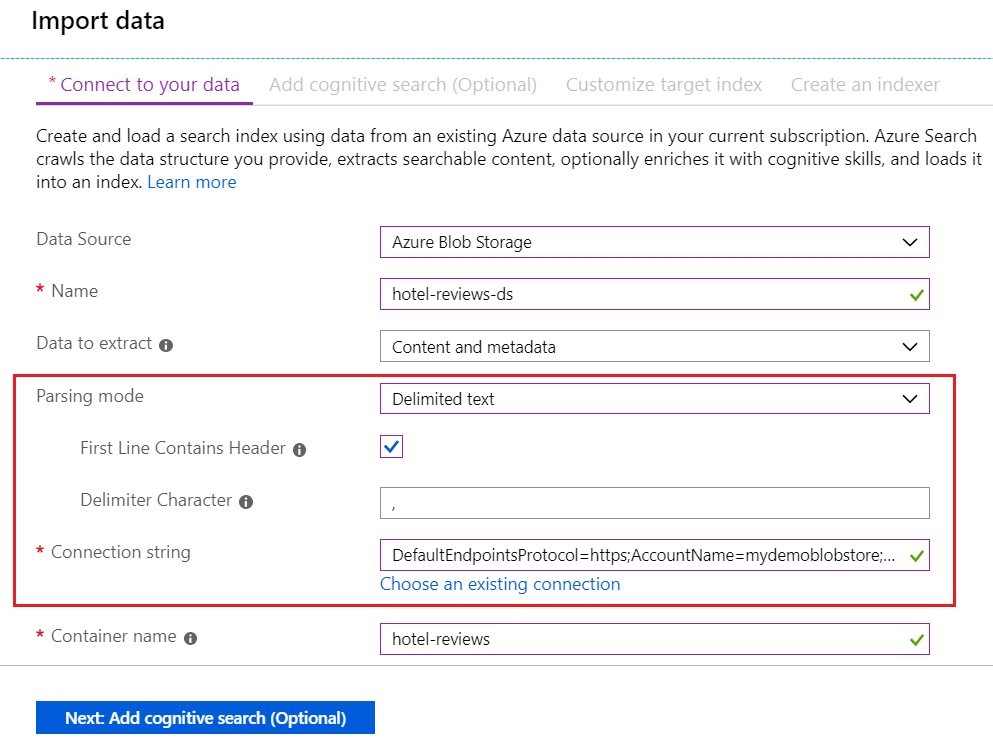
Wechseln Sie zur nächsten Seite.
Schritt 2: Hinzufügen von Qualifikationen
Fügen Sie in diesem Schritt des Assistenten Qualifikationen für die KI-Anreicherung hinzu. Die Quelldaten bestehen aus Kundenbewertungen in englischer und französischer Sprache. Zu den Qualifikationen, die für dieses Dataset relevant sind, gehören die Schlüsselwortextraktion, die Stimmungserkennung und die Textübersetzung. Diese Anreicherungen werden in einem späteren Schritt als Azure-Tabellen in einen Wissensspeicher „projiziert“.
Erweitern Sie Azure AI Services anfügen. Standardmäßig ist Free (begrenzte Anreicherung) ausgewählt. Da die Datei „HotelReviews-Free.csv“ 19 Datensätze enthält und mit der kostenlosen Ressource 20 Transaktionen pro Tag möglich sind, können Sie diese Ressource verwenden.
Erweitern Sie Anreicherungen hinzufügen.
Geben Sie unter Skillsetname den Namen „hotel-reviews-ss“ ein.
Wählen Sie unter Quelldatenfeld die Option reviews_text aus.
Wählen Sie unter Granularitätsebene für Anreicherung die Option Seiten (5.000 Zeichenblöcke) aus.
Wählen Sie für Kognitive Fähigkeiten für Text die folgenden Qualifikationen aus:
- How to extract key phrases in Text Analytics (Extrahieren von Schlüsselbegriffen mithilfe der Textanalyse)
- Übersetzen von Text
- Sprachenerkennung
- Stimmung erkennen
Ihre Seite sollte wie im folgenden Screenshot aussehen:
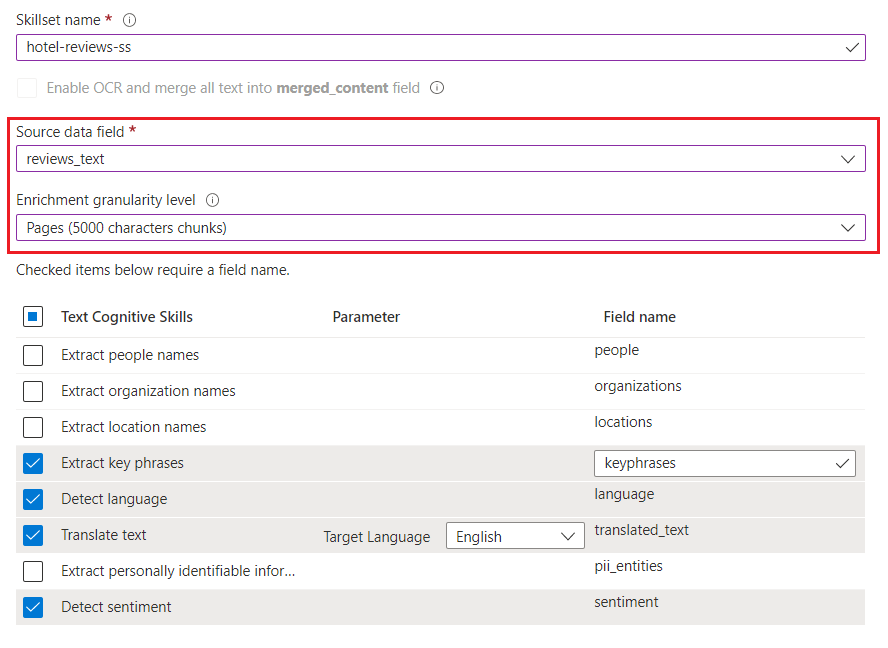
Scrollen Sie nach unten, und erweitern Sie Anreicherungen in einem Wissensspeicher speichern.
Wählen Sie Vorhandene Verbindung auswählen und anschließend ein Azure Storage-Konto aus. Die Seite „Container“ wird angezeigt, damit Sie einen Container für Projektionen erstellen können. Es wird empfohlen, eine Präfixnamenskonvention wie „kstore-hotel-reviews“ einzuführen, um zwischen Quell- und Wissensspeicherinhalten zu unterscheiden.
Kehren Sie zum Datenimport-Assistenten zurück, und wählen Sie die folgenden Azure-Tabellenprojektionen aus. Der Assistent bietet stets die Projektion Dokumente. Je nach den von Ihnen ausgewählten Qualifikationen (z. B. Schlüsselbegriffe) oder Granularität der Anreicherung (Seiten) werden andere Projektionen angeboten:
- Dokumente
- Seiten
- Schlüsselbegriffe
Der folgende Screenshot zeigt die Auswahl der Tabellenprojektion im Assistenten:
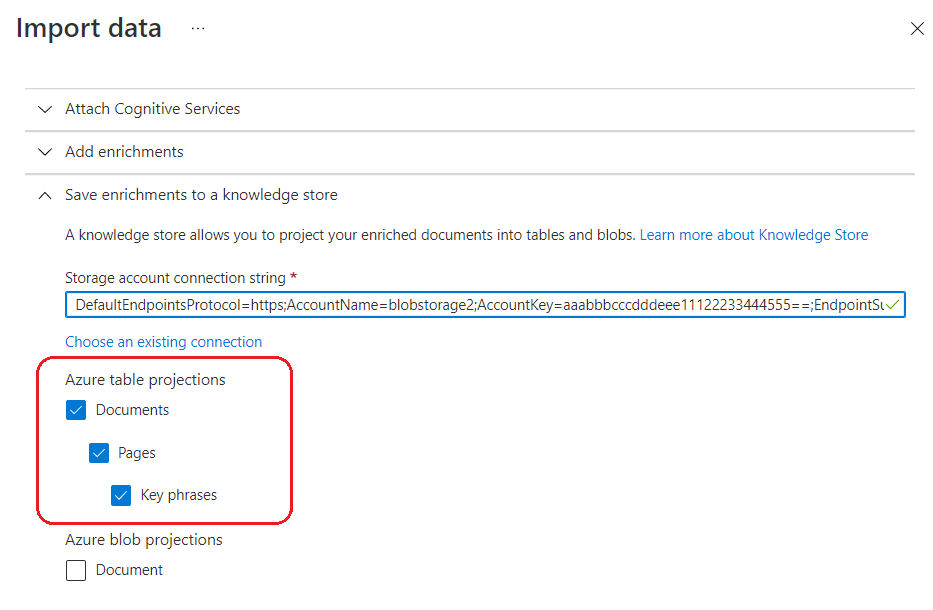
Wechseln Sie zur nächsten Seite.
Schritt 3: Konfigurieren des Index
In diesem Schritt des Assistenten konfigurieren Sie einen Index für optionale Volltextsuchabfragen. Sie benötigen keinen Suchindex für einen Wissensspeicher. Für die Ausführung des Indexers ist jedoch ein Suchindex erforderlich.
In diesem Schritt analysiert der Assistent Ihre Datenquelle, um Felder und Datentypen abzuleiten. Sie müssen lediglich die Attribute für das gewünschte Verhalten auswählen. Mit dem Attribut Abrufbar kann der Suchdienst beispielsweise einen Feldwert zurückgeben. Das Attribut Suchbar ermöglicht dagegen eine Volltextsuche für das Feld.
Geben Sie unter Indexname den Namen „hotel-reviews-idx“ ein.
Übernehmen Sie für Attribute die Standardauswahl: Abrufbar und Durchsuchbar für die neuen Felder, die von der Pipeline erstellt werden.
Ihr Index sollte in etwa wie in der folgenden Abbildung aussehen: Aufgrund der Länger der Liste sind in der Abbildung nicht alle Felder zu sehen.
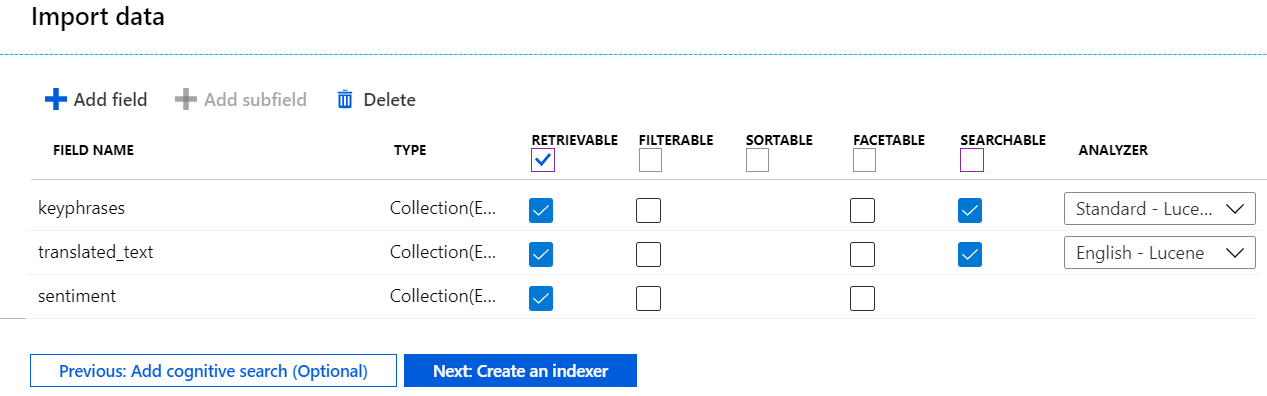
Wechseln Sie zur nächsten Seite.
Schritt 4: Konfigurieren und Ausführen des Indexers
In diesem Schritt des Assistenten konfigurieren Sie einen Indexer, der die Datenquelle, das Skillset und den Index aus den vorherigen Schritten zusammenführt.
Geben Sie unter Name den Namen „hotel-reviews-idxr“ ein.
Behalten Sie unter Zeitplan den Standardwert Einmalig bei.
Wählen Sie Senden aus, um den Indexer auszuführen. In diesem Schritt werden die Datenextraktion und die Indizierung durchgeführt und die kognitiven Qualifikationen angewendet.
Schritt 5: Überprüfen des Status
Öffnen Sie in der Mitte der Seite Übersicht die Registerkarte Indexer, und wählen Sie dann hotels-reviews-idxr aus. Innerhalb von ein oder zwei Minuten sollte sich der Status von „In Bearbeitung“ ohne Fehler und Warnungen in „Erfolgreich“ ändern.
Überprüfen von Tabellen im Azure-Portal
Öffnen Sie das Speicherkonto, das Sie zum Erstellen des Wissensspeichers verwendet haben, im Azure-Portal.
Wählen Sie im linken Navigationsbereich des Speicherkontos die Option Speicherbrowser aus, um die neuen Tabellen anzuzeigen.
Sie sollten drei Tabellen sehen, und zwar eine für jede Projektion, die im Abschnitt „Anreicherungen speichern“ auf der Seite „Anreicherungen hinzufügen“ angeboten wurde.
„hotelReviewssDocuments“ enthält alle Knoten der ersten Ebene der Anreicherungsstruktur eines Dokuments, die keine Sammlungen sind.
„hotelReviewssKeyPhrases“ enthält eine lange Liste mit nur den Schlüsselbegriffen, die aus allen Bewertungen extrahiert wurden. Skills, die Sammlungen (Arrays) ausgeben, z. B. Schlüsselbegriffe und Entitäten, senden die Ausgabe an eine eigenständige Tabelle.
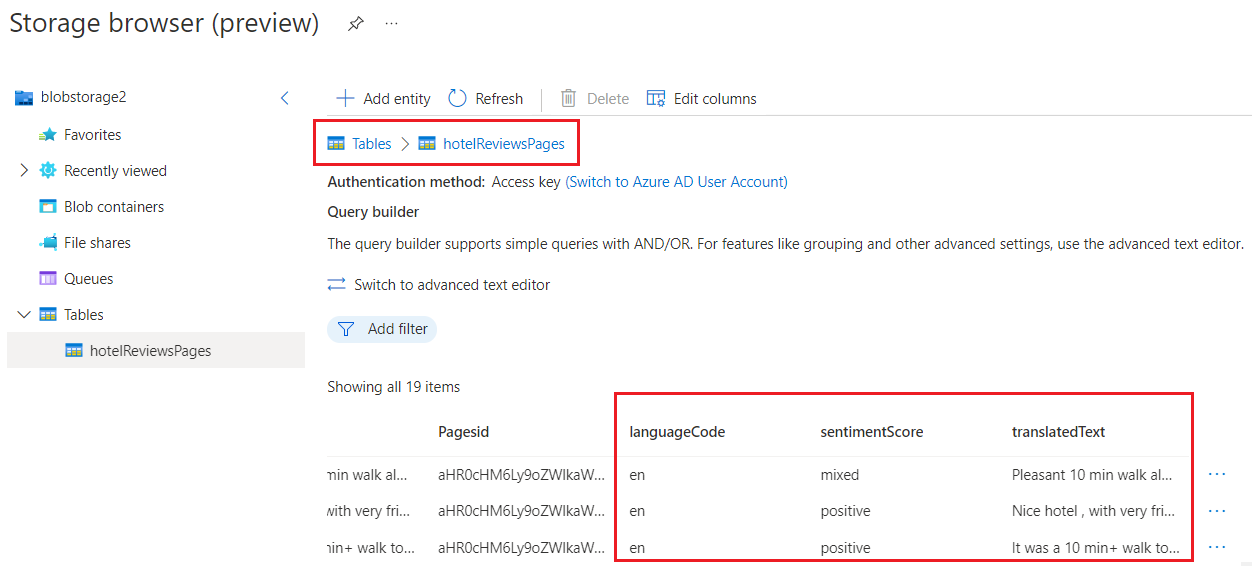
„hotelReviewssPages“ enthält angereicherte Felder, die auf jeder Seite erstellt wurden, die vom Dokument getrennt wurde. In diesem Skillset und dieser Datenquelle bestehen die Anreicherungen auf Seitenebene aus Stimmungsbezeichnungen und übersetztem Text. Eine Seitentabelle (oder eine Sätzetabelle, wenn Sie diese spezielle Granularitätsstufe angeben) wird erstellt, wenn Sie die Granularität „Seiten“ in der Skillsetdefinition auswählen.
Alle diese Tabellen enthalten ID-Spalten, um Tabellenbeziehungen in anderen Tools und Apps zu unterstützen. Scrollen Sie beim Öffnen einer Tabelle über diese Felder, um die von der Pipeline hinzugefügten Inhaltsfelder anzuzeigen.
In dieser Schnellstartanleitung sollte die Tabelle für „hotelReviewssPages“ etwa wie auf dem folgenden Screenshot aussehen:
Bereinigen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, sollten Sie sich am Ende eines Projekts überlegen, ob Sie die erstellten Ressourcen noch benötigen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können einzelne Ressourcen oder die gesamte Ressourcengruppe mit allen darin enthaltenen Ressourcen löschen.
Sie können Ressourcen im Azure-Portal über den Link Alle Ressourcen oder Ressourcengruppen im linken Navigationsbereich suchen und verwalten.
Denken Sie bei Verwendung eines kostenlosen Diensts an die Beschränkung auf maximal drei Indizes, Indexer und Datenquellen. Sie können einzelne Elemente über das Azure-Portal löschen, um unter dem Grenzwert zu bleiben.
Tipp
Wenn Sie diese Übung wiederholen oder eine andere exemplarische Vorgehensweise für die KI-Anreicherung ausprobieren möchten, löschen Sie den Indexer hotel-reviews-idxr und die zugehörigen Objekte, um sie neu zu erstellen. Durch das Löschen des Indexers wird der Zähler für kostenlose Transaktionen pro Tag auf Null zurückgesetzt.
Nächste Schritte
Nach der Einführung in Wissensspeicher können Sie sich die einzelnen Schritte genauer ansehen, indem Sie zur exemplarischen Vorgehensweise für die REST-API wechseln. Aufgaben, die der Assistent intern verarbeitet hat, werden in der exemplarischen Vorgehensweise zu REST erläutert.