Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In dieser Schnellstartanleitung verwenden Sie den Assistenten zum Importieren und Vektorisieren von Daten im Azure-Portal, um mit der integrierten Vektorisierung zu beginnen. Der Assistent blöcket Ihre Inhalte und ruft ein Einbettungsmodell auf, um die Blöcke zur Indizierung und Abfragezeit zu vektorisieren.
In dieser Schnellstartanleitung werden textbasierte PDF-Dateien aus dem Azure-Search-Beispieldaten-Repository verwendet. Sie können jedoch Bilder verwenden und diese Schnellstartanleitung trotzdem abschließen.
Voraussetzungen
Ein Azure-Konto mit einem aktiven Abonnement. Sie können kostenlos ein Konto erstellen.
Ein Azure AI Search-Dienst. Wir empfehlen den Tarif „Basic“ oder höher.
Eine unterstützte Datenquelle.
Vertrautheit mit dem Assistenten. Siehe Importieren von Daten-Assistenten im Azure-Portal.
Unterstützte Datenquellen
Der Assistent zum Importieren und Vektorisieren von Datenunterstützt eine Vielzahl von Azure-Datenquellen. In dieser Schnellstartanleitung werden jedoch nur die Datenquellen behandelt, die mit ganzen Dateien arbeiten, die in der folgenden Tabelle beschrieben werden.
| Unterstützte Datenquelle | Beschreibung |
|---|---|
| Azure Blob Storage | Diese Datenquelle funktioniert mit Blobs und Tabellen. Sie müssen ein Standardleistungskonto (general-purpose v2) verwenden. Zugriffsebenen können heiß, kühl oder kalt sein. |
| Azure Data Lake Storage (ADLS) Gen2 | Dies ist ein Azure Storage-Konto mit aktiviertem hierarchischen Namespace. Um zu bestätigen, dass Sie über Data Lake Storage verfügen, aktivieren Sie die Registerkarte "Eigenschaften " auf der Seite "Übersicht ".
|
| OneLake | Diese Datenquelle befindet sich momentan im Vorschau-Modus. Informationen zu Einschränkungen und unterstützten Tastenkombinationen finden Sie unter OneLake-Indizierung. |
Unterstützte Einbettungsmodelle
Für die integrierte Vektorisierung müssen Sie eines der folgenden Einbettungsmodelle auf einer Azure AI-Plattform verwenden. Bereitstellungsanweisungen werden in einem späteren Abschnitt bereitgestellt.
| Anbieter | Unterstützte Modelle |
|---|---|
| Azure OpenAI in Azure AI Foundry Models1, 2 | text-embedding-ada-002 text-embedding-3-small text-embedding-3-large |
| Azure KI Services-Ressource mit mehreren Diensten3 | Für Text und Bilder: Azure AI Vision multimodal4 |
| Modellkatalog von Azure KI Foundry | Für Text: Cohere-embed-v3-english Cohere-embed-v3-multilingual Für Bilder: Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-Bild-Einbettungen-ViT-Giant |
1 Der Endpunkt Ihrer Azure OpenAI-Ressource muss über eine benutzerdefinierte Unterdomäne verfügen, wie https://my-unique-name.openai.azure.com. Wenn Sie Ihre Ressource im Azure-Portal erstellt haben, wurde diese Unterdomäne während der Ressourceneinrichtung automatisch generiert.
2 Azure OpenAI-Ressourcen (mit Zugriff auf Einbettungsmodelle), die im Azure AI Foundry-Portal erstellt wurden, werden nicht unterstützt. Nur azure OpenAI-Ressourcen, die im Azure-Portal erstellt wurden, sind mit der Azure OpenAI Embedding-Fähigkeit kompatibel.
3 Zu Abrechnungszwecken müssen Sie Ihre Azure AI Multi-Service-Ressource an das Skillset in Ihrem Azure AI Search-Dienst anfügen. Sofern Sie keine schlüssellose Verbindung (Vorschau) zum Erstellen des Skillsets verwenden, müssen sich beide Ressourcen in derselben Region befinden.
4 Das multimodale Einbettungsmodell von Azure AI Vision ist in ausgewählten Regionen verfügbar.
Anforderungen an öffentliche Endpunkte
Für diesen Schnellstart muss für alle vorherigen Ressourcen der öffentliche Zugriff aktiviert sein, damit die Azure-Portal-Knoten darauf zugreifen können. Andernfalls tritt im Assistenten ein Fehler auf. Nachdem der Assistent ausgeführt wurde, können Sie Firewalls und private Endpunkte auf den Integrationskomponenten zur Gewährleistung der Sicherheit aktivieren. Weitere Informationen sehen Sie unter Sichere Verbindungen in den Importassistenten.
Wenn private Endpunkte bereits vorhanden sind und Sie diese nicht deaktivieren können, besteht die alternative Option darin, den entsprechenden End-to-End-Flow von einem Skript oder Programm auf einer VM auszuführen. Die VM muss sich im selben virtuellen Netzwerk wie der private Endpunkt befinden. Hier ist ein Python-Codebeispiel für die integrierte Vektorisierung. Im gleichen GitHub-Repository gibt es Beispiele in anderen Programmiersprachen.
Rollenbasierter Zugriff
Sie können Microsoft Entra-ID mit Rollenzuweisungen oder schlüsselbasierter Authentifizierung mit Vollzugriffsverbindungszeichenfolgen verwenden. Für Azure AI Search-Verbindungen mit anderen Ressourcen empfehlen wir Rollenzuweisungen. In diesem Schnellstart werden Rollen vorausgesetzt.
Kostenlose Suchdienste unterstützen rollenbasierte Verbindungen mit Azure AI Search. Sie unterstützen jedoch keine verwalteten Identitäten bei ausgehenden Verbindungen mit Azure Storage oder Azure AI Vision. Dieser Mangel an Unterstützung erfordert eine schlüsselbasierte Authentifizierung für Verbindungen zwischen kostenlosen Suchdiensten und anderen Azure-Ressourcen. Verwenden Sie für sicherere Verbindungen die Standardebene oder höher, und aktivieren Sie dann Rollen und konfigurieren Sie eine verwaltete Identität.
So konfigurieren Sie den empfohlenen rollenbasierten Zugriff:
Aktivieren Sie in Ihrem Suchdienst Rollen, und konfigurieren Sie eine vom System zugewiesene verwaltete Identität.
Weisen Sie sich selbst die folgenden Rollen zu:
Mitwirkender von Suchdienst
Mitwirkender an Suchindexdaten
Suchindexdatenleser
Erstellen Sie auf Ihrer Datenquellenplattform und beim Einbetten von Modellanbietern Rollenzuweisungen, mit denen Ihr Suchdienst auf Daten und Modelle zugreifen kann. Siehe Vorbereiten von Beispieldaten und Vorbereiten von Einbettungsmodellen.
Hinweis
Wenn Sie den Assistenten nicht durchlaufen können, da Optionen nicht verfügbar sind (beispielsweise können Sie keine Datenquelle oder kein Einbettungsmodell auswählen), überprüfen Sie die Rollenzuweisungen. Fehlermeldungen deuten darauf hin, dass Modelle oder Bereitstellungen nicht vorhanden sind, wenn die eigentliche Ursache darin besteht, dass der Suchdienst nicht über die Berechtigung zum Zugriff verfügt.
Überprüfen des Speicherplatzes
Wenn Sie mit dem kostenlosen Dienst beginnen, können Sie maximal drei Indizes, Datenquellen, Skillsets und Indexer verwenden. Der Basic-Tarif beschränkt Sie auf 15. Mit dieser Schnellstartanleitung wird eines der einzelnen Objekte erstellt. Stellen Sie daher sicher, dass Sie platz für zusätzliche Elemente haben, bevor Sie beginnen.
Vorbereiten der Beispieldaten
Dieser Abschnitt verweist auf den Inhalt, der für diese Schnellstartanleitung funktioniert. Bevor Sie fortfahren, stellen Sie sicher, dass Sie die Voraussetzungen für den rollenbasierten Zugriff abgeschlossen haben.
Melden Sie sich beim Azure-Portal an, und wählen Sie Ihr Azure Storage-Konto aus.
Wählen Sie im linken Bereich "Datenspeichercontainer>" aus.
Erstellen Sie einen Container, und laden Sie dann die PDF-Dokumente für den Gesundheitsplan hoch, die für diesen Schnellstart verwendet werden.
So weisen Sie Rollen zu:
Wählen Sie im linken Bereich die Zugriffssteuerung (IAM) aus.
Wählen Sie Hinzufügen>Rollenzuweisung hinzufügen.
Wählen Sie unter "Rollen der Auftragsfunktion" die Option "Storage Blob Data Reader" und dann "Weiter" aus.
Wählen Sie unter "Mitglieder" die Option "Verwaltete Identität" und dann "Mitglieder auswählen" aus.
Wählen Sie Ihr Abonnement und die verwaltete Identität Ihres Suchdiensts aus.
(Optional) Synchronisieren Sie Löschungen in Ihrem Container mit Löschungen im Suchindex. So konfigurieren Sie den Indexer für die Löscherkennung:
Aktivieren Sie das vorläufige Löschen für Ihr Speicherkonto. Wenn Sie native soft delete verwenden, ist der nächste Schritt nicht erforderlich.
Fügen Sie benutzerdefinierte Metadaten hinzu , die ein Indexer überprüfen kann, um zu bestimmen, welche Blobs zum Löschen markiert sind. Weisen Sie Ihrer benutzerdefinierten Eigenschaft einen beschreibenden Namen zu. Sie können beispielsweise die Eigenschaft "IsDeleted" benennen und auf "false" festlegen. Wiederholen Sie diesen Schritt für jeden Blob im Container. Wenn Sie das Blob löschen möchten, ändern Sie die Eigenschaft in "true". Weitere Informationen finden Sie unter Ändern und Löschen der Erkennung beim Indizieren aus Azure Storage.
Vorbereiten des Einbettungsmodells
Der Assistent kann Einbettungsmodelle verwenden, die aus Azure OpenAI, Azure AI Vision oder aus dem Modellkatalog im Azure AI Foundry-Portal bereitgestellt werden. Bevor Sie fortfahren, stellen Sie sicher, dass Sie die Voraussetzungen für den rollenbasierten Zugriff abgeschlossen haben.
Der Assistent unterstützt die Modelle text-embedding-ada-002, text-embedding-3-large und text-embedding-3-small. Intern ruft der Assistent den Skill AzureOpenAIEmbedding auf, um eine Verbindung mit Azure OpenAI herzustellen.
Melden Sie sich beim Azure-Portal an, und wählen Sie Ihre Azure OpenAI-Ressource aus.
So weisen Sie Rollen zu:
Wählen Sie im linken Bereich access control (IAM) aus.
Wählen Sie Hinzufügen>Rollenzuweisung hinzufügen.
Wählen Sie unter Stellenfunktionsrolle die Option Cognitive Services OpenAI-Benutzer und dann Weiter aus.
Wählen Sie unter "Mitglieder" die Option "Verwaltete Identität" und dann "Mitglieder auswählen" aus.
Wählen Sie Ihr Abonnement und die verwaltete Identität Ihres Suchdiensts aus.
So stellen Sie ein Einbettungsmodell bereit:
Melden Sie sich beim Azure AI Foundry-Portal an, und wählen Sie Ihre Azure OpenAI-Ressource aus.
Wählen Sie im linken Bereich den Modellkatalog aus.
Stellen Sie ein unterstütztes Einbettungsmodell bereit.
Starten des Assistenten
So starten Sie den Assistenten für die Vektorsuche:
Melden Sie sich beim Azure-Portal an, und wählen Sie Ihren Azure AI Search-Dienst aus.
Wählen Sie auf der Seite Übersicht die Option Importieren und Vektorisieren von Daten aus.

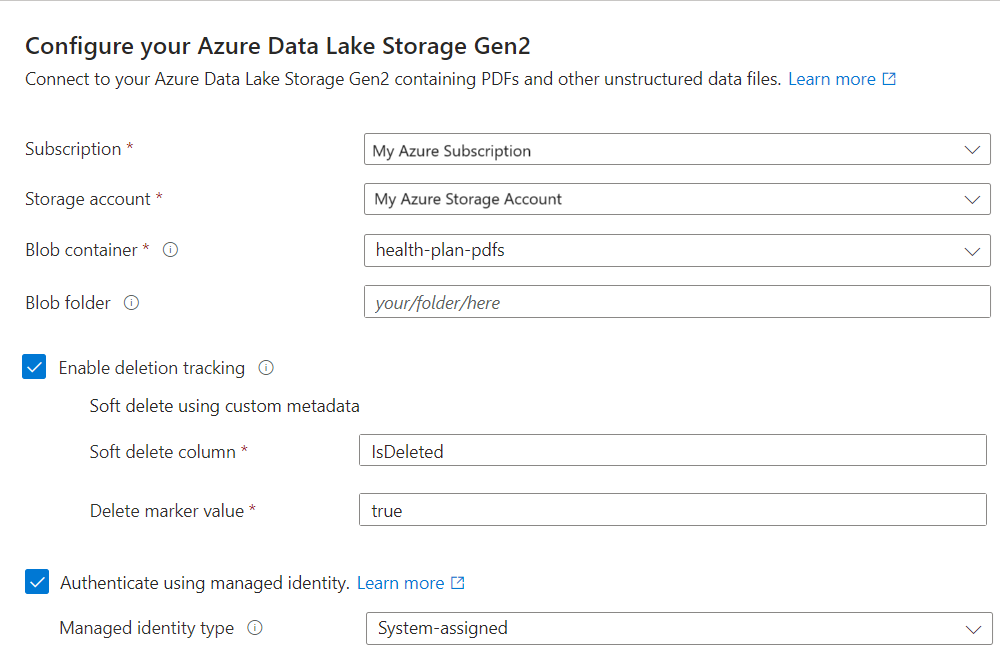
Wählen Sie Ihre Datenquelle aus: Azure Blob Storage, ADLS Gen2 oder OneLake.
Wählen Sie RAG aus.


Herstellen einer Verbindung mit Ihren Daten
Der nächste Schritt besteht darin, eine Verbindung mit einer Datenquelle herzustellen, die für den Suchindex verwendet werden soll.
Geben Sie auf der Seite "Mit Ihren Daten verbinden " das Azure-Abonnement an.
Wählen Sie das Speicherkonto und den Container aus, das die Beispieldaten bereitstellt.
Wenn Sie das vorläufige Löschen aktiviert und optional benutzerdefinierte Metadaten in " Beispieldaten vorbereiten" hinzugefügt haben, aktivieren Sie das Kontrollkästchen " Löschverfolgung aktivieren ".
Bei nachfolgenden Indizierungsläufen wird der Suchindex aktualisiert, um alle Suchdokumente basierend auf vorläufig gelöschten Blobs in Azure Storage zu entfernen.
Blobs unterstützen entweder das native vorläufige Löschen von Blobs oder das vorläufige Löschen mit benutzerdefinierten Metadaten.
Wenn Sie Ihre BLOBs für das vorläufige Löschen konfiguriert haben, stellen Sie das Name-Wert-Paar der Metadateneigenschaft bereit. Wir empfehlen IsDeleted. Wenn IsDeleted auf true für ein Blob festgelegt ist, verwirft der Indexer das entsprechende Suchdokument beim nächsten Indexerlauf.
Der Assistent überprüft Azure Storage nicht auf gültige Einstellungen, und er löst keinen Fehler aus, wenn die Anforderungen nicht erfüllt sind. Stattdessen funktioniert die Löscherkennung nicht, und Ihr Suchindex sammelt im Laufe der Zeit wahrscheinlich verwaiste Dokumente.
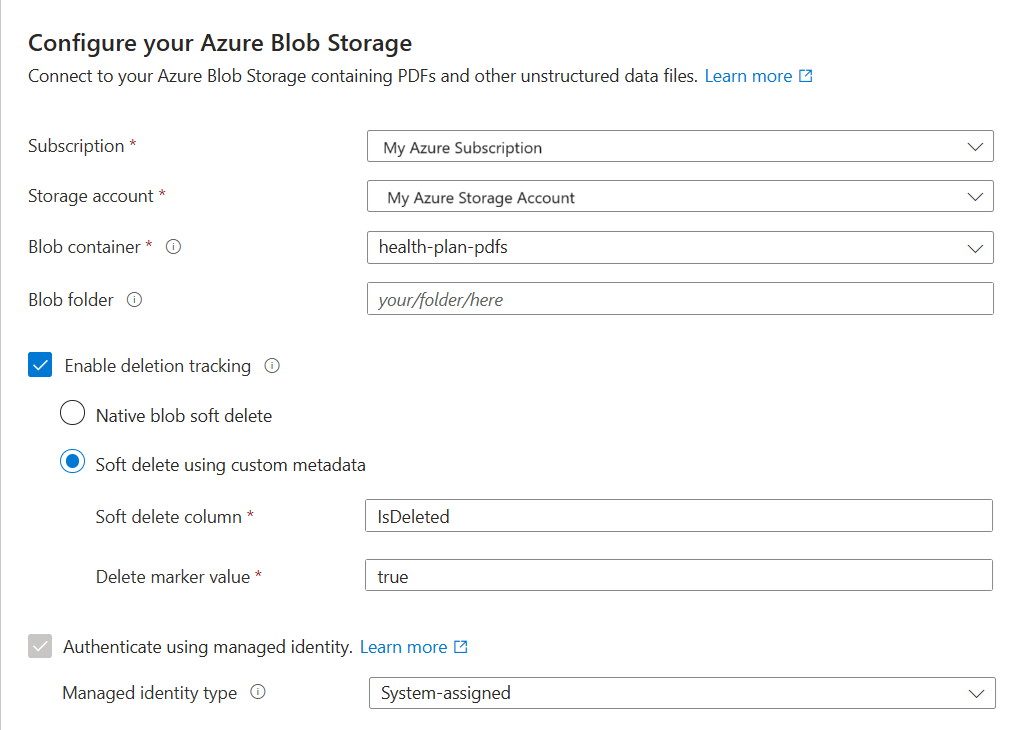
Aktivieren Sie das Kontrollkästchen "Authentifizieren mit verwalteter Identität ".
Wählen Sie für den Typ der verwalteten Identität die Option "System zugewiesen" aus.
Die Identität sollte in Azure Storage über die Rolle Storage-Blobdatenleser verfügen.
Überspringen Sie diesen Schritt nicht. Während der Indizierung tritt ein Verbindungsfehler auf, wenn der Assistent keine Verbindung mit Azure Storage herstellen kann.
Wählen Sie Weiter aus.
Vektorisieren Ihres Texts
In diesem Schritt geben Sie ein Einbettungsmodell zum Vektorisieren von datenblöcken an. Chunking ist eingebaut und nicht konfigurierbar. Die effektiven Einstellungen sind:
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
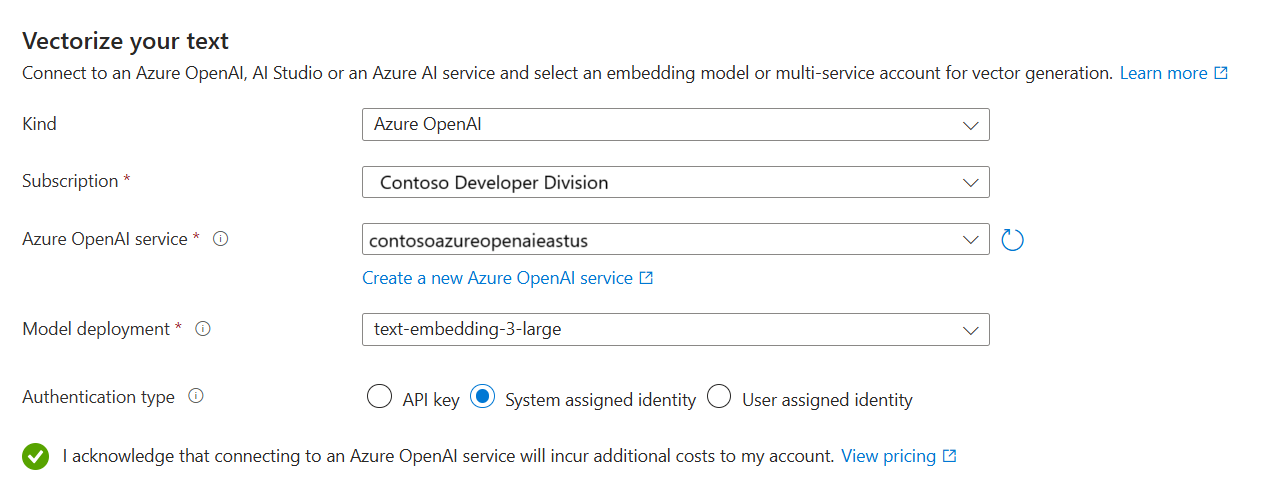
Wählen Sie auf der Seite "Vektorisieren" die Quelle ihres Einbettungsmodells aus:
Azure OpenAI
Modellkatalog von Azure KI Foundry
Azure AI Vision (über eine Azure AI Services Multi-Service-Ressource in derselben Region wie Azure AI Search)
Geben Sie das Azure-Abonnement an.
Treffen Sie je nach Ressource die folgende Auswahl:
Wählen Sie für Azure OpenAI das Modell aus, das Sie im Modell " Einbetten vorbereiten" bereitgestellt haben.
Wählen Sie für den KI Foundry-Modellkatalog das Modell aus, das Sie im Schritt Embedding-Modell vorbereiten bereitgestellt haben.
Wählen Sie für KI Vision multimodale Einbettungen Ihre Multi-Service-Ressource aus.
Wählen Sie für den Authentifizierungstyp die vom System zugewiesene Identität aus.
- Die Identität sollte über die Rolle Cognitive Services-Benutzende im Azure KI Services Multi-Service-Ressource verfügen.
Aktivieren Sie das Kontrollkästchen, das die Auswirkungen der Nutzung dieser Ressourcen auf die Abrechnung bestätigt.
Wählen Sie Weiter aus.
Vektorisieren und Anreichern Ihrer Bilder
Die PDFs für den Gesundheitsplan enthalten ein Unternehmenslogo, ansonsten gibt es keine Bilder. Sie können diesen Schritt überspringen, wenn Sie die Beispieldokumente verwenden.
Wenn Sie jedoch mit Inhalten arbeiten, die hilfreiche Bilder enthalten, können Sie KI auf zwei Arten anwenden:
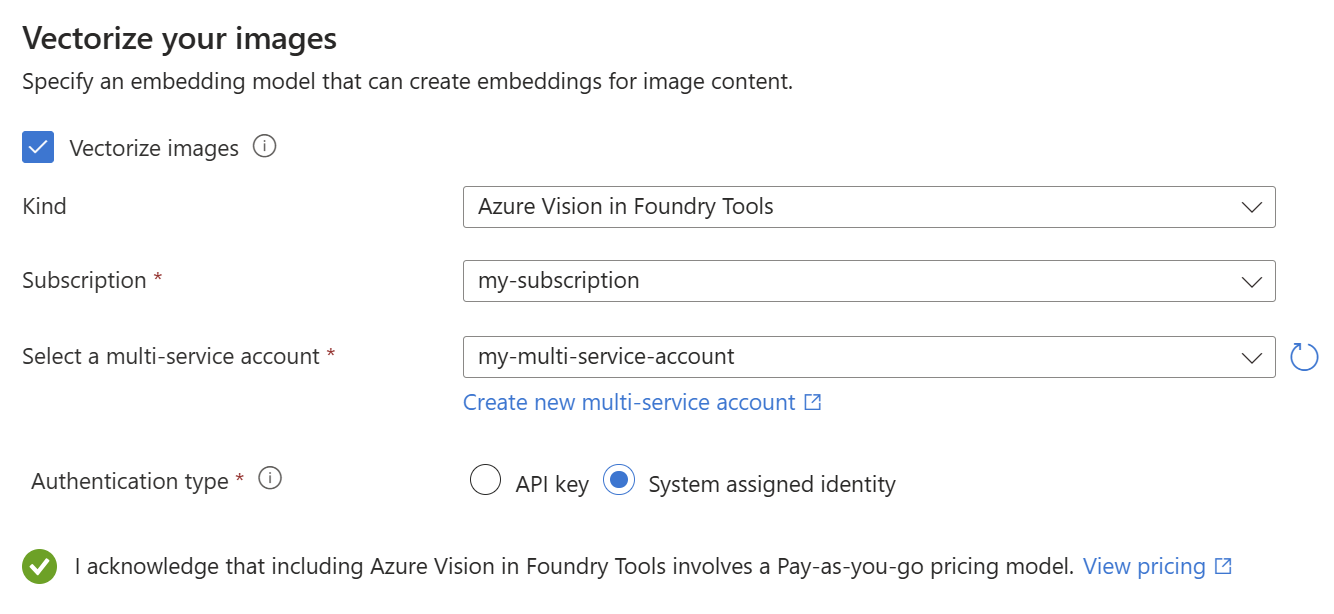
Verwenden Sie ein unterstütztes Bildeinbettungsmodell aus dem Katalog oder die azure AI Vision multimodale Einbettungs-API, um Bilder zu vektorisieren.
Verwenden Sie die optische Zeichenerkennung (Optical Character Recognition, OCR), um Text in Bildern zu erkennen. Diese Option ruft den Skill OCR zum Lesen von Text aus Bildern auf.
Azure KI-Suche und Ihre Azure KI-Ressource müssen sich in derselben Region befinden oder für schlüssellose Abrechnungsverbindungen konfiguriert sein.
Geben Sie auf der Seite Vektorisieren Sie Ihre Bilder die Art der Verbindung an, die der Assistent erstellen soll. Für die Bildvektorisierung kann der Assistent eine Verbindung mit Einbettungsmodellen im Azure AI Foundry-Portal oder in Azure KI Vision herstellen.
Geben Sie das Abonnement an.
Geben Sie für den Azure KI Foundry-Modellkatalog das Projekt und die Bereitstellung an. Weitere Informationen finden Sie unter "Vorbereiten von Einbettungsmodellen".
(Optional) Knacken Sie binäre Bilder, z. B. gescannte Dokumentdateien, und verwenden Sie OCR , um Text zu erkennen.
Aktivieren Sie das Kontrollkästchen, das die Auswirkungen der Nutzung dieser Ressourcen auf die Abrechnung bestätigt.
Wählen Sie Weiter aus.
Hinzufügen der Zuweisung einer semantischen Rangfolge
Auf der Seite Erweiterte Einstellungen können Sie optional eine semantische Rangfolge hinzufügen, um die Ergebnisse am Ende der Abfrageausführung erneut zu rangieren. Die erneute Rangierung verschiebt die semantisch relevantesten Übereinstimmungen nach oben.
Zuordnen neuer Felder
Wichtige Informationen zu diesem Schritt:
Das Indexschema stellt Vektor- und Nichtvektorfelder für datenblöcke bereit.
Sie können Felder hinzufügen, aber keine generierten Felder löschen oder ändern.
Der Modus „Dokumentanalyse“ erstellt Blöcke (ein Suchdokument pro Block).
Auf der Seite "Erweiterte Einstellungen " können Sie optional neue Felder hinzufügen, vorausgesetzt, die Datenquelle stellt Metadaten oder Felder bereit, die beim ersten Durchlauf nicht aufgenommen werden. Standardmäßig generiert der Assistent die in der folgenden Tabelle beschriebenen Felder.
| Feld | Gilt für: | Beschreibung |
|---|---|---|
| chunk_id | Text- und Bildvektoren | Generiertes Zeichenfolgenfeld. Durchsuchbar, abrufbar und sortierbar. Dies ist der Dokumentschlüssel für den Index. |
| Eltern-ID | Textvektoren | Generiertes Zeichenfolgenfeld. Abrufbar und filterbar. Gibt das übergeordnete Dokument an, aus dem der Block stammt. |
| Block | Text- und Bildvektoren | Zeichenfolgenfeld. Eine für Menschen lesbare Version des Datenblocks. Durchsuchbar und abrufbar, aber nicht filterbar, facettierbar oder sortierbar. |
| Titel | Text- und Bildvektoren | Zeichenfolgenfeld. Für Menschen lesbare Dokumenttitel oder Seitentitel oder Seitenzahlen. Durchsuchbar und abrufbar, aber nicht filterbar, facettierbar oder sortierbar. |
| Textvektor | Textvektoren | Collection(Edm.single). Vektordarstellung des Blocks. Durchsuchbar und abrufbar, aber nicht filterbar, facettierbar oder sortierbar. |
Sie können die generierten Felder oder deren Attribute nicht ändern, aber Sie können neue Felder hinzufügen, wenn ihre Datenquelle sie bereitstellt. Beispielsweise stellt Azure Blob Storage eine Sammlung von Metadatenfeldern bereit.
Wählen Sie Feld hinzufügen aus.
Wählen Sie ein Quellfeld aus den verfügbaren Feldern aus, geben Sie einen Feldnamen für den Index ein, und akzeptieren (oder überschreiben) Sie den Standarddatentyp.
Hinweis
Metadatenfelder sind durchsuchbar, aber nicht rückholbar, filterbar, facettierbar oder sortierbar.
Wenn Sie das Schema in seiner ursprünglichen Version wiederherstellen möchten, wählen Sie "Zurücksetzen" aus.
Planen der Indizierung
Auf der Seite "Erweiterte Einstellungen" können Sie auch einen optionalen Ausführungszeitplan für den Indexer angeben. Nachdem Sie ein Intervall aus der Dropdownliste ausgewählt haben, wählen Sie "Weiter" aus.
Beenden des Assistenten
Geben Sie auf der Seite Überprüfen Ihrer Konfiguration ein Präfix für die Objekte an, die der Assistent erstellt. Ein allgemeines Präfix hilft Ihnen, den Überblick zu behalten.
Klicken Sie auf Erstellen.
Wenn der Assistent die Konfiguration abschließt, erstellt er die folgenden Objekte:
Eine Datenquellenverbindung.
Ein Index mit Vektorfeldern, Vektorizern, Vektorprofilen und Vektoralgorithmen. Sie können den Standardindex während des Assistentenworkflows nicht entwerfen oder ändern. Indizes entsprechen der REST-API „2024-05-01-preview“.
Ein Skillset mit dem Skill „Textaufteilung“ für die Blockerstellung und dem Skill „Einbettung“ für die Vektorisierung. Der Einbettungs-Skill ist entweder der AzureOpenAIEmbeddingModel-Skill für Azure OpenAI oder der AML-Skill für den Azure KI Foundry-Modellkatalog. Das Skillset verfügt außerdem über die Indexprojektionen Konfiguration, die Daten aus einem Dokument in der Datenquelle den entsprechenden Blöcken in einem untergeordneten Index zuordnet.
Ein Indexer mit Feldzuordnungen und Ausgabefeldzuordnungen (falls zutreffend).
Tipp
Vom Assistenten erstellte Objekte verfügen über konfigurierbare JSON-Definitionen. Um diese Definitionen anzuzeigen oder zu ändern, wählen Sie die Suchverwaltung im linken Bereich aus, in dem Sie Ihre Indizes, Indexer, Datenquellen und Skillsets anzeigen können.
Überprüfen der Ergebnisse
Der Suchexplorer akzeptiert Textzeichenfolgen als Eingabe und vektorisiert dann den Text für die Ausführung von Vektorabfragen.
Wechseln Sie im Azure-Portal zu Suchverwaltungsindizes>, und wählen Sie dann Ihren Index aus.
Wählen Sie "Abfrageoptionen" und dann " Vektorwerte in Suchergebnissen ausblenden" aus. Dieser Schritt macht die Ergebnisse besser lesbar.
Wählen Sie im Menü "Ansicht " die JSON-Ansicht aus, damit Sie Text für Ihre Vektorabfrage im
textVektorabfrageparameter eingeben können.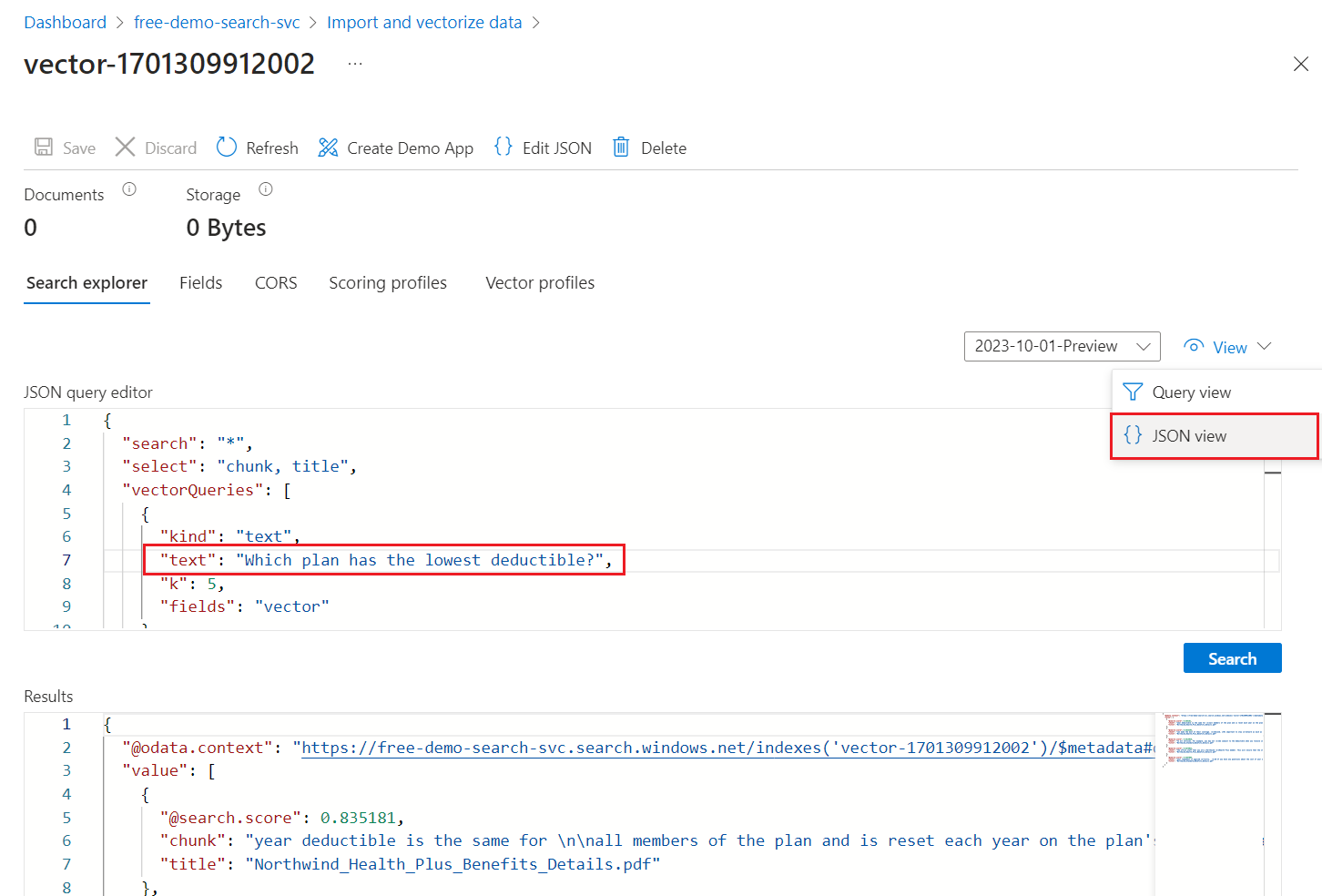
Die Standardabfrage ist eine leere Suche (
"*"), enthält jedoch Parameter für die Rückgabe der Anzahl übereinstimmungen. Es handelt sich um eine Hybridabfrage, die Text- und Vektorabfragen parallel ausführt. Außerdem enthält sie semantische Rangfolge und gibt an, welche Felder in den Ergebnissen über dieselectAnweisung zurückgegeben werden sollen.{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }Ersetzen Sie beide Platzhalter mit Sternchen (
*) durch eine Frage, die in Zusammenhang mit Gesundheitsplänen steht, z. B.Which plan has the lowest deductible?.{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }Um die Abfrage auszuführen, wählen Sie "Suchen" aus.
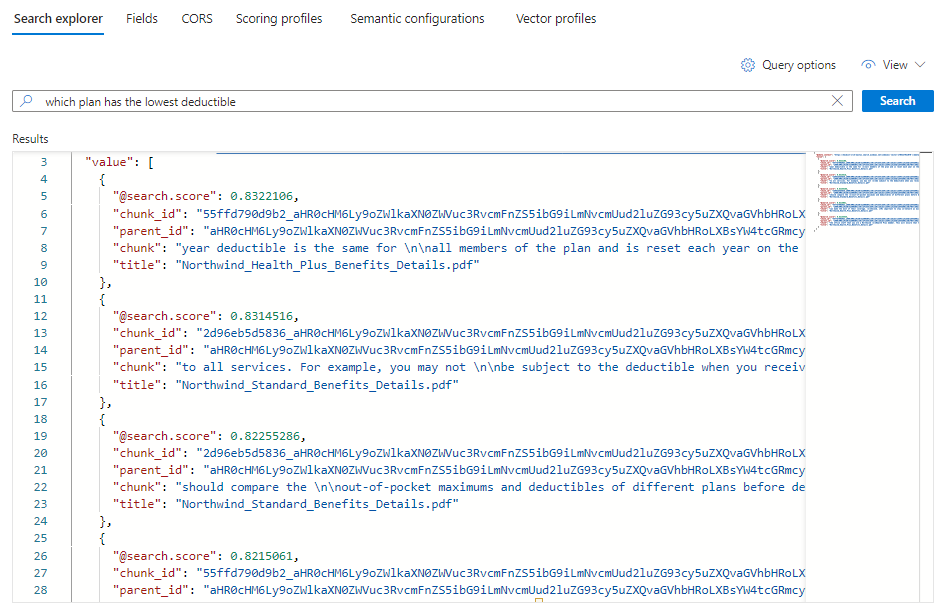
Jedes Dokument ist ein Block der ursprünglichen PDF-Datei. Das Feld
titlezeigt an, aus welcher PDF-Datei der Block stammt. Jedeschunkist lang. Sie können einen kopieren und in einen Text-Editor einfügen, um den gesamten Wert zu lesen.Um alle Blöcke aus einem bestimmten Dokument anzuzeigen, fügen Sie einen Filter für das Feld
title_parent_idfür eine bestimmte PDF-Datei hinzu. Sie können die Registerkarte "Felder " ihres Indexes überprüfen, um zu bestätigen, dass das Feld gefiltert werden kann.{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
Bereinigung
Azure AI Search ist eine kostenpflichtige Ressource. Wenn Sie dies nicht mehr benötigen, löschen Sie es aus Ihrem Abonnement, um Gebühren zu vermeiden.
Nächster Schritt
In dieser Schnellstartanleitung haben Sie den Assistenten zum Importieren und Vektorisieren von Daten eingeführt, der alle erforderlichen Objekte für die integrierte Vektorisierung erstellt. Informationen zu den einzelnen Schritten finden Sie unter Einrichten der integrierten Vektorisierung in Azure AI Search.