Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird erläutert, wie Sie einen vorhandenen Index in Azure KI-Suche mit Schemaänderungen oder Inhaltsänderungen durch inkrementelle Indizierung aktualisieren. Es werden die Umstände erläutert, unter denen eine Neuerstellung erforderlich ist. Außerdem werden Empfehlungen bereitgestellt, wie die Auswirkungen von Neuerstellungen auf laufende Abfrageanforderungen auf ein Mindestmaß reduziert werden können.
Während der aktiven Entwicklung ist es üblich, Indizes abzulegen und neu zu erstellen, wenn Sie das Design des Indexes überarbeiten. Die meisten Entwickler arbeiten mit einem kleinen repräsentativen Beispiel ihrer Daten, um die Neuindizierung zu beschleunigen.
Für Schemaänderungen an Anwendungen, die sich bereits in der Produktion befindet, wird empfohlen, einen neuen Index zu erstellen und zu testen, der parallel zu einem vorhandenen Index ausgeführt wird. Verwenden Sie einen Indexalias, um den neuen Index auszutauschen und dabei Änderungen am Anwendungscode zu vermeiden.
Aktualisieren von Inhalten
Die inkrementelle Indizierung und Synchronisierung eines Indexes mit Änderungen an Quelldaten ist für die meisten Suchanwendungen von grundlegender Bedeutung. In diesem Abschnitt wird der Workflow zum Hinzufügen, Entfernen oder Überschreiben des Inhalts eines Suchindexes über die REST-API erläutert, aber die Azure-SDKs bieten gleichwertige Funktionen.
Der Anforderungstext enthält ein oder mehrere zu indizierende Dokumente. Innerhalb der Anforderung lautet jedes Dokument im Index:
- Identifiziert durch einen eindeutigen Schlüssel mit Groß-/Kleinschreibung.
- Verbunden mit einer Aktion: "upload", "delete", "merge" oder "mergeOrUpload".
- Aufgefüllt mit einer Reihe von Namen-Wert-Paaren für jedes Feld, das Sie hinzufügen oder aktualisieren.
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (name/value pairs matching index schema)
...
},
...
]
}
Verwenden Sie zunächst die APIs zum Laden von Dokumenten, z. B. Documents – Index (REST) oder eine entsprechende API aus den Azure SDKs. Weitere Informationen zu Indizierungstechniken finden Sie unter Laden von Dokumenten.
Für ein großes Update wird die Batchverarbeitung (bis zu 1.000 Dokumente oder etwa 16 MB pro Batch, je nachdem, welcher Grenzwert zuerst erreicht wird) empfohlen, mit der die Indizierungsleistung erheblich verbessert wird.
Legen Sie den
@search.action-Parameter in der API fest, um den Effekt auf vorhandene Dokumente zu bestimmen.Handlung Auswirkung löschen Entfernt das gesamte Dokument aus dem Index. Wenn Sie ein einzelnes Feld entfernen möchten, verwenden Sie stattdessen merge und legen das betreffende Feld auf NULL fest. Gelöschte Dokumente und Felder geben nicht sofort Speicherplatz im Index frei. Alle paar Minuten führt ein Hintergrundprozess den physischen Löschvorgang durch. Unabhängig davon, ob Sie das Azure-Portal oder eine API zum Zurückgeben von Indexstatistiken verwenden, müssen Sie eine kleine Verzögerung einplanen, bevor der Löschvorgang im Azure-Portal und über APIs sichtbar ist. zusammenführen Aktualisiert ein bereits vorhandenes Dokument und schlägt fehl, wenn das Dokument nicht gefunden werden kann. Merge ersetzt vorhandene Werte. Achten Sie deshalb darauf, nach Sammlungsfeldern zu suchen, die mehrere Werte enthalten, z. B. Felder vom Typ Collection(Edm.String). Wenn beispielsweise eintags-Feld mit dem Wert["budget"]beginnt und Sie eine Zusammenführung mit["economy", "pool"]durchführen, lautet der Wert für dastags-Feld am Ende des Vorgangs["economy", "pool"]. Der Wert lautet nicht etwa["budget", "economy", "pool"].
Das gleiche Verhalten gilt für komplexe Auflistungen. Wenn das Dokument ein komplexes Auflistungsfeld mit dem Namen „Rooms“ (Räume) mit dem Wert[{ "Type": "Budget Room", "BaseRate": 75.0 }]enthält und Sie eine Zusammenführung mit dem Wert[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]ausführen, lautet der Endwert des Felds „Rooms“[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]. Es werden keine neuen und vorhandenen Werte angefügt oder zusammengeführt.zusammenführenOderHochladen Verhält sich wie Zusammenführen, wenn das Dokument vorhanden ist, und wie Hochladen, wenn das Dokument neu ist. Dies ist die häufigste Aktion für inkrementelle Updates. hochladen Ähnelt einem „Upsert“, bei dem das Dokument eingefügt wird, wenn es neu ist, und aktualisiert oder ersetzt wird, wenn es bereits vorhanden ist. Wenn im Dokument Werte fehlen, die der Index benötigt, wird der Wert des Dokumentfelds auf NULL festgelegt.
Abfragen werden während der Indizierung weiterhin ausgeführt, aber wenn Sie vorhandene Felder aktualisieren oder entfernen, sollten Sie gemischte Ergebnisse und eine höhere Inzidenz der Drosselung erwarten.
Hinweis
Es gibt keine Garantien für die Reihenfolge, in der die Aktionen im Anforderungstext ausgeführt werden. Es wird nicht empfohlen, in einem einzigen Anforderungstext mehrere Zusammenführungsaktionen zu verwenden, die mit demselben Dokument verknüpft sind. Wenn für dasselbe Dokument mehrere Zusammenführungsaktionen erforderlich sind, führen Sie die Zusammenführungsaktion auf der Clientseite aus, bevor Sie das Dokument im Suchindex aktualisieren.
Antworten
Der Statuscode 200 wird bei einer erfolgreichen Antwort zurückgegeben und bedeutet, dass alle Elemente dauerhaft gespeichert wurden und ihre Indizierung beginnt. Die Indizierung wird im Hintergrund ausgeführt und macht wenige Sekunden nach Abschluss des Indizierungsvorgangs neue Dokumente verfügbar (also abfragefähig und durchsuchbar). Die tatsächliche Verzögerung hängt von der Last des Diensts ab.
Eine erfolgreiche Indizierung ist daran zu erkennen, dass die status-Eigenschaft für alle Elemente auf TRUE und die statusCode-Eigenschaft auf „201“ (für neu hochgeladene Dokumente) oder „200“ (für zusammengeführte oder gelöschte Dokumente) festgelegt ist:
{
"value": [
{
"key": "unique_key_of_new_document",
"status": true,
"errorMessage": null,
"statusCode": 201
},
{
"key": "unique_key_of_merged_document",
"status": true,
"errorMessage": null,
"statusCode": 200
},
{
"key": "unique_key_of_deleted_document",
"status": true,
"errorMessage": null,
"statusCode": 200
}
]
}
Der Statuscode 207 wird zurückgegeben, wenn mindestens ein Element nicht erfolgreich indiziert wurde. Bei Elemente, die nicht indiziert wurden, wird das Statusfeld auf FALSE festgelegt. Die Eigenschaften errorMessage und statusCode geben den Grund für den Indizierungsfehler an:
{
"value": [
{
"key": "unique_key_of_document_1",
"status": false,
"errorMessage": "The search service is too busy to process this document. Please try again later.",
"statusCode": 503
},
{
"key": "unique_key_of_document_2",
"status": false,
"errorMessage": "Document not found.",
"statusCode": 404
},
{
"key": "unique_key_of_document_3",
"status": false,
"errorMessage": "Index is temporarily unavailable because it was updated with the 'allowIndexDowntime' flag set to 'true'. Please try again later.",
"statusCode": 422
}
]
}
Die errorMessage-Eigenschaft gibt nach Möglichkeit den Grund für den Indizierungsfehler an.
Die folgende Tabelle erläutert die verschiedenen Statuscodes pro Dokument, die in der Antwort zurückgegeben werden können. Beachten Sie, dass einige Statuscodes auf Probleme mit der Anforderung selbst hinweisen, andere hingegen auf temporäre Fehler. Das Letztere sollten Sie nach einer Verzögerung erneut versuchen.
| Statuscode | Bedeutung | Wiederholbar | Hinweise |
|---|---|---|---|
| 200 | Dokument wurde erfolgreich geändert oder gelöscht. | – | Löschvorgänge sind idempotent. Das bedeutet, dass auch wenn im Index kein Dokumentschlüssel vorhanden ist, der Versuch, einen Löschvorgang mit diesem Schlüssel durchzuführen, zum Statuscode „200“ führt. |
| 201 | Dokument wurde erfolgreich erstellt. | – | |
| 400 | Das Dokument enthielt einen Fehler, der die Indizierung verhindert hat. | Nein | Die Fehlermeldung in der Antwort weist darauf hin, was am Dokument fehlerhaft ist. |
| 404 | Das Dokument konnte nicht zusammengeführt werden, da der angegebene Schlüssel nicht im Index vorhanden ist. | Nein | Dieser Fehler tritt nicht bei Uploads auf, da dabei neue Dokumente erstellt werden, und auch nicht bei Löschungen, da sie idempotent sind. |
| 409 | Ein Versionskonflikt wurde erkannt, als Sie versuchten, ein Dokument zu indizieren. | Ja | Dies kann vorkommen, wenn Sie versuchen, mehr als einmal gleichzeitig das gleiche Dokument zu indizieren. |
| 422 | Der Index ist vorübergehend nicht verfügbar, da er aktualisiert wurde, als das Flag „allowIndexDowntime“ auf „true“ gesetzt war. | Ja | |
| 429 | Zu viele Anforderungen | Ja | Wenn Sie diesen Fehlercode während der Indizierung erhalten, bedeutet dies in der Regel, dass Sie wenig Speicher haben. Während Sie speichergrenzbar sind, kann der Dienst einen Zustand eingeben, in dem Sie einige Dokumente erst hinzufügen oder aktualisieren können, wenn Sie einige Dokumente löschen. Weitere Informationen finden Sie unter "Planen und Verwalten von Kapazität ", wenn Sie mehr Speicherplatz benötigen oder Speicherplatz freigeben möchten, indem Sie Dokumente löschen. |
| 503 | Ihr Suchdienst ist vorübergehend nicht verfügbar, möglicherweise aufgrund starker Auslastung. | Ja | Der Code sollte in diesem Fall vor Wiederholungsversuchen warten, oder es besteht das Risiko, dass die Nichtverfügbarkeit des Diensts verlängert wird. |
Wenn für Ihren Clientcode häufig die Antwort „207“ auftritt, ist möglicherweise das System ausgelastet. Sie können zur Bestätigung die statusCode-Eigenschaft auf „503“ überprüfen. Wenn der Statuscode 503 ist, empfehlen wir, die Indizierungsanforderungen zu drosseln. Nimmt der Indizierdatenverkehr nicht ab, kann dies dazu führen, dass alle Anforderungen mit dem Fehler "503" abgelehnt werden.
Statuscode 429 gibt an, dass Sie Ihr Kontingent für die Anzahl der Dokumente pro Index überschritten haben. Sie müssen entweder ein Upgrade für höhere Kapazitätsbeschränkungen durchführen oder einen neuen Index erstellen.
Hinweis
Wenn Sie DateTimeOffset-Werte mit Zeitzoneninformationen in Ihren Index hochladen, normalisiert Azure KI-Suche diese Werte in UTC (koordinierte Weltzeit). So wird 2024-01-13T14:03:00-08:00 beispielsweise als 2024-01-13T22:03:00Z gespeichert. Wenn Sie Zeitzoneninformationen speichern müssen, fügen Sie Ihrem Index für diesen Datenpunkt eine zusätzliche Spalte hinzu.
Tipps für die inkrementelle Indizierung
Indexer automatisieren die inkrementelle Indizierung. Wenn Sie einen Indexer verwenden können und die Datenquelle die Änderungsnachverfolgung unterstützt, können Sie den Indexer für einen wiederkehrenden Zeitplan ausführen, um durchsuchbare Inhalte hinzuzufügen, zu aktualisieren oder zu überschreiben, damit sie mit Ihren externen Daten synchronisiert wird.
Wenn Sie Indexaufrufe direkt über die Push-API ausführen, verwenden Sie
mergeOrUploadals Suchaktion.Die Nutzlast muss die Schlüssel oder Bezeichner jedes Dokuments enthalten, das Sie hinzufügen, aktualisieren oder löschen möchten.
Wenn Ihr Index Vektorfelder enthält und Sie die Eigenschaft
storedauf „false“ festlegen, stellen Sie sicher, dass Sie den Vektor in der teilweisen Dokumentaktualisierung bereitstellen, auch wenn der Wert unverändert ist. Ein Nebeneffekt der Einstellung vonstoredauf „false“ besteht darin, dass Vektoren bei einem Neuindizierungsvorgang verworfen werden. Durch die Bereitstellung des Vektors in der Dokumentnutzlast wird dies verhindert.Um den Inhalt einfacher Felder und Unterfelder in komplexen Typen zu aktualisieren, listen Sie nur die Felder auf, die Sie ändern möchten. Wenn Sie beispielsweise nur ein Beschreibungsfeld aktualisieren müssen, sollte die Nutzlast aus dem Dokumentschlüssel und der geänderten Beschreibung bestehen. Wenn andere Felder weggelassen werden, bleiben ihre vorhandenen Werte erhalten.
Um Inlineänderungen in einer Zeichenfolgensammlung zusammenzuführen, geben Sie den gesamten Wert an. Erinnern Sie sich an das
tags-Feldbeispiel aus dem vorherigen Abschnitt. Bei neuen Werten werden die alten Werte für ein gesamtes Feld überschrieben, und es gibt keine Zusammenführung innerhalb des Inhalts eines Felds.
Hier ist ein REST-API-Beispiel, in dem diese Tipps veranschaulicht werden:
### Get Stay-Kay City Hotel by ID
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
### Change the description, city, and tags for Stay-Kay City Hotel
POST {{baseUrl}}/indexes/hotels-vector-quickstart/docs/search.index?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"value": [
{
"@search.action": "mergeOrUpload",
"HotelId": "1",
"Description": "I'm overwriting the description for Stay-Kay City Hotel.",
"Tags": ["my old item", "my new item"],
"Address": {
"City": "Gotham City"
}
}
]
}
### Retrieve the same document, confirm the overwrites and retention of all other values
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Aktualisieren von Indexschemas
Das Indexschema definiert die physischen Datenstrukturen, die im Suchdienst erstellt wurden, sodass es nicht viele Schemaänderungen gibt, die Sie vornehmen können, ohne dass eine vollständige Neuerstellung entsteht.
Updates ohne Neuerstellung
In der folgenden Liste werden die Schemaänderungen aufgelistet, die nahtlos in einen vorhandenen Index eingeführt werden können. Im Allgemeinen enthält die Liste neue Felder und Funktionen, die während der Abfrageausführung verwendet werden.
- Hinzufügen einer Indexbeschreibung (Vorschau)
- Hinzufügen eines neuen Felds
- Festlegen des
retrievable-Attributs für ein vorhandenes Feld - Aktualisieren von
searchAnalyzerauf einem Feld mit einem vorhandenenindexAnalyzer - Hinzufügen einer neuen Analysedefinition in einem Index (die auf neue Felder angewendet werden kann)
- Hinzufügen, Aktualisieren oder Löschen von Bewertungsprofilen
- Hinzufügen, Aktualisieren oder Löschen von synonymMaps
- Hinzufügen, Aktualisieren oder Löschen von semantischen Konfigurationen
- Hinzufügen, Aktualisieren oder Löschen von CORS-Einstellungen
Die Reihenfolge der Vorgänge lautet:
Überarbeiten Sie das Schema mit Aktualisierungen aus der vorherigen Liste.
Aktualisieren des Indexschemas für den Suchdienst.
Aktualisieren des Indexinhalts, damit er Ihrem überarbeiteten Schema entspricht, wenn Sie ein neues Feld hinzugefügt haben. Bei allen anderen Änderungen wird der bestehende indizierte Inhalt unverändert verwendet.
Wenn Sie ein Indexschema so aktualisieren, dass ein neues Feld eingeschlossen ist, erhalten die bereits im Index vorhandenen Dokumente für dieses Feld den Wert NULL. Beim nächsten Indizierungsauftrag werden die von Azure KI-Suche hinzugefügten NULL-Werte durch externe Quelldaten ersetzt.
Während der Aktualisierungen sollten keine Abfrageunterbrechungen auftreten, aber die Abfrageergebnisse variieren, wenn die Aktualisierungen wirksam werden.
Updates, die eine Neuerstellung erfordern
Einige Änderungen erfordern eine Indexlöschung und -neuerstellung, bei der ein aktueller Index durch einen neuen ersetzt wird.
| Handlung | Beschreibung |
|---|---|
| Löschen eines Felds | Um alle Spuren eines Felds physisch entfernen zu können, müssen Sie den Index neu erstellen. Wenn eine sofortige Neuerstellung nicht praktikabel ist, können Sie den Anwendungscode so ändern, dass der Zugriff von einem veralteten Feld weggeleitet wird, oder die searchFields verwenden und Abfrageparameter auswählen, um auszuwählen, welche Felder durchsucht und zurückgegeben werden. Die Felddefinition und die Inhalte bleiben physisch bis zur nächsten Neuerstellung im Index, wenn Sie ein Schema verwenden, bei dem das betreffende Feld ausgelassen wird. |
| Ändern einer Felddefinition | Für Überarbeitungen eines Feldnamens, Datentyps oder spezifischer Indexattribute (durchsuchbar, filterbar, sortierbar, facettenreich) ist eine vollständige Neuerstellung erforderlich. |
| Ein Analysetool einem Feld zuweisen | Analyzers werden in einem Index definiert, Feldern zugewiesen und dann während der Indizierung aufgerufen, um zu informieren, wie Token erstellt werden. Sie können einem Index jederzeit eine neue Analysetooldefinition hinzufügen, aber Sie können ein Analysetool nur zuweisen, wenn das Feld erstellt wird. Dies gilt sowohl für das Analysetool als auch die indexAnalyzer-Eigenschaften. Die searchAnalyzer-Eigenschaft ist eine Ausnahme (Sie können diese Eigenschaft einem vorhandenen Feld zuweisen). |
| Aktualisieren oder Löschen einer Analysetooldefinition in einem Index | Sie können eine bestehende Analysetoolkonfiguration (Analysetool, Tokenizer, Tokenfilter oder Zeichenfilter) im Index nicht löschen oder ändern, es sei denn, Sie erstellen den gesamten Index neu. |
| Hinzufügen eines Felds zu einer Vorschlagsfunktion | Wenn ein Feld bereits vorhanden ist, und Sie es einer Vorschlagsfunktion hinzufügen möchten, müssen Sie den Index neu erstellen. |
| Aktualisieren Ihres Diensts oder Ihrer Stufe | Wenn Sie mehr Kapazität benötigen, überprüfen Sie, ob Sie Ihren Dienst aktualisieren oder zu einem höheren Preisniveau wechseln können. Andernfalls müssen Sie einen neuen Dienst erstellen und die Indizes von Grund auf neu erstellen. Um diesen Prozess zu automatisieren, können Sie ein Codebeispiel verwenden, mit dem Ihr Index in einer Reihe von JSON-Dateien gesichert wird. Anschließend können Sie den Index in einem von Ihnen angegebenen Suchdienst neu erstellen. |
Die Reihenfolge der Vorgänge lautet:
Rufen Sie eine Indexdefinition für den Fall ab, dass Sie diese in Zukunft als Referenz benötigen, oder um sie als Grundlage für eine neue Version zu verwenden.
Erwägen Sie die Verwendung einer Sicherungs- und Wiederherstellungslösung, um eine Kopie von Indexinhalten beizubehalten. Es gibt Lösungen in C# und in Python. Wir empfehlen die Python-Version, da sie aktueller ist.
Wenn Sie über ausreichend Kapazität für Ihren Suchdienst verfügen, behalten Sie den vorhandenen Index beim Erstellen und Testen des neuen Index bei.
Legen Sie den vorhandenen Index ab. Abfragen, die sich an diesen Index richten, werden sofort gelöscht. Denken Sie daran, dass das Löschen eines Indexes nicht rückgängig gemacht werden kann. Der physische Speicher für die Feldsammlung und andere Konstrukte wird zerstört.
Veröffentlichen Sie einen überarbeiteten Index, wobei der Text der Anforderung geänderte oder modifizierte Felddefinitionen und -konfigurationen enthält.
Laden Sie den Index mit Dokumenten aus einer externen Quelle. Dokumente werden mithilfe der Felddefinitionen und Konfigurationen des neuen Schemas indiziert.
Wenn Sie den Index erstellen, wird physischer Speicher für jedes Feld im Indexschema zugewiesen, wobei für jedes durchsuchbare Feld ein invertierter Index und für jedes Vektorfeld ein Vektorindex erstellt wird. Nicht durchsuchbare Felder können in Filtern oder Ausdrücken verwendet werden, besitzen aber keine invertierten Indizes und können nicht mit der Volltext- oder Fuzzysuche durchsucht werden. Bei einer Indexneuerstellung werden diese invertierten Indizes und Vektorindizes gelöscht und basierend auf dem von Ihnen angegebenen Indexschema neu erstellt.
Um Unterbrechungen des Anwendungscodes zu minimieren, sollten Sie einen Indexalias erstellen. Der Anwendungscode verweist auf den Alias, Sie können jedoch den Namen des Index aktualisieren, auf den der Alias verweist.
Hinzufügen einer Indexbeschreibung (Vorschau)
Ab der REST-API-Version 2025-05-01-preview wird jetzt eine ddescription unterstützt. Dieser lesbare Text ist unschätzbar, wenn ein System auf mehrere Indizes zugreifen muss und basierend auf der Beschreibung eine Entscheidung treffen muss. Erwägen Sie einen MCP-Server (Model Context Protocol), der zur Laufzeit den richtigen Index auswählen muss. Die Entscheidung kann auf der Beschreibung und nicht allein auf dem Indexnamen basieren.
Eine Indexbeschreibung ist eine Schemaaktualisierung, und Sie können sie hinzufügen, ohne den gesamten Index neu erstellen zu müssen.
- Die Zeichenfolgenlänge beträgt maximal 4.000 Zeichen.
- Inhalte müssen in Unicode lesbar sein. Ihr Anwendungsfall sollte bestimmen, welche Sprache verwendet werden soll.
Unterstützung für eine Indexbeschreibung wird in der Vorschau-REST-API, dem Azure-Portal oder in einem Vorabversions-Azure SDK-Paket bereitgestellt, das das Feature bereitstellt.
Das Azure-Portal unterstützt die neueste Vorschau-API.
Melden Sie sich beim Azure-Portal an, und suchen Sie Ihren Suchdienst.
Wählen Sie unter "Suchverwaltungsindizes>" einen Index aus.
Wählen Sie JSON bearbeiten aus.
Fügen Sie
"description"gefolgt von der Beschreibung ein. Der Wert muss kleiner als 4.000 Zeichen und in Unicode sein.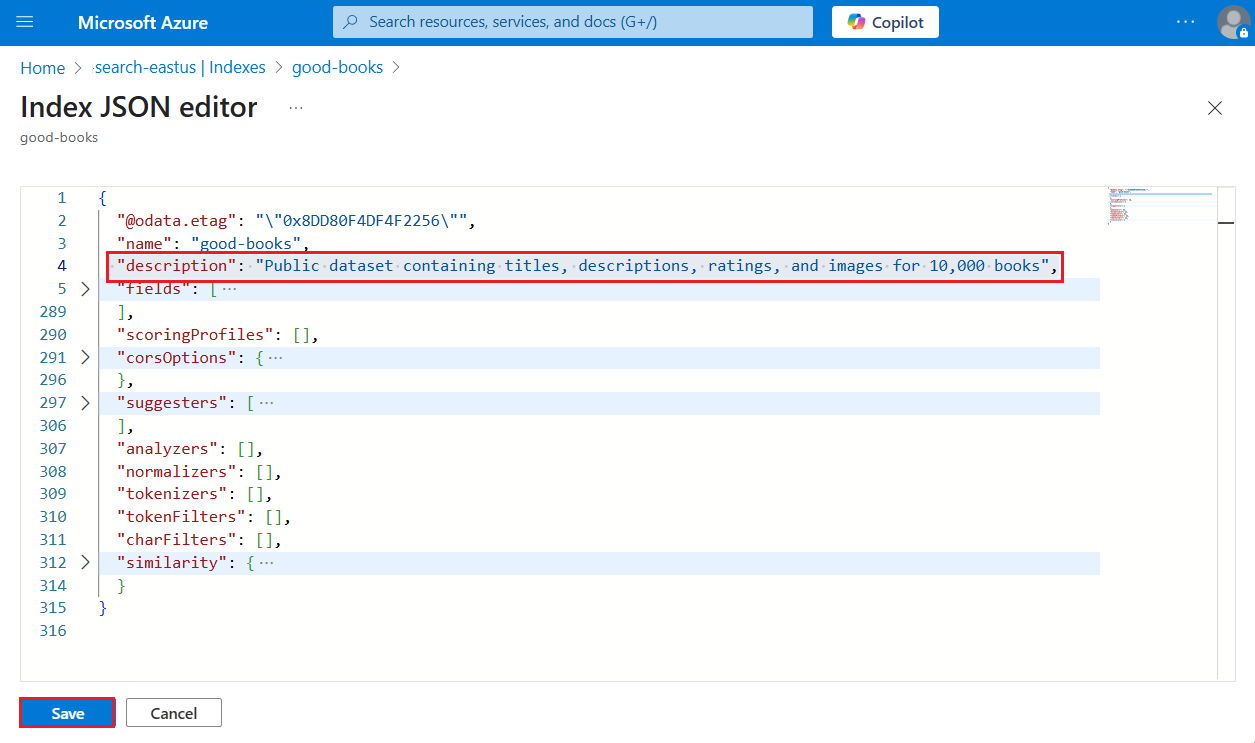
Speichern Sie den Index.
Ausgleichen von Workloads
Die Indizierung erfolgt nicht im Hintergrund, aber der Suchdienst gleicht alle Indizierungsaufträge mit laufenden Abfragen aus. Während der Indizierung können Sie Abfrageanforderungen im Azure-Portal überwachen, um sicherzustellen, dass die Abfragen innerhalb eines angemessenen Zeitraums abgeschlossen werden.
Wenn die Indizierung von Workloads zu nicht akzeptablen Abfragewartezeiten führt, führen Sie eine Leistungsanalyse durch, und überprüfen Sie diese Leistungstipps auf mögliche Entschärfungen.
Nach Updates suchen
Sie können mit der Abfrage eines Indexes beginnen, sobald das erste Dokument geladen wurde. Wenn Sie die ID eines Dokuments kennen, gibt die REST-API zur Dokumentsuche das jeweilige Dokument zurück. Für umfangreichere Testvorgänge sollten Sie warten, bis der Index vollständig geladen wurde, und anschließend den erwarteten Kontext anhand von Abfragen überprüfen.
Sie können den Suchexplorer oder einen REST-Client verwenden, um nach aktualisierten Inhalten zu suchen.
Wenn Sie ein Feld hinzugefügt oder umbenannt haben, verwenden Sie select, um dieses Feld zurückzugeben:
"search": "*",
"select": "document-id, my-new-field, some-old-field",
"count": true
Das Azure-Portal stellt die Indexgröße und die Vektorindexgröße bereit. Sie können diese Werte nach dem Aktualisieren eines Indexes überprüfen, aber denken Sie daran, eine kleine Verzögerung zu erwarten, da der Dienst die Änderung verarbeitet und die Aktualisierungsraten des Portals berücksichtigt, was einige Minuten dauern kann.
Löschen verwaister Dokumente
Azure AI Search unterstützt Operationen auf Dokumentenebene, so dass Sie ein bestimmtes Dokument isoliert nachschlagen, aktualisieren und löschen können. Das folgende Beispiel zeigt den Löschvorgang eines Dokuments.
Durch das Löschen eines Dokuments wird nicht sofort Speicherplatz im Index freigegeben. Alle paar Minuten führt ein Hintergrundprozess den physischen Löschvorgang durch. Unabhängig davon, ob Sie das Azure-Portal oder eine API zum Zurückgeben von Indexstatistiken verwenden, müssen Sie eine kleine Verzögerung einplanen, bevor der Löschvorgang im Azure-Portal und über API-Metriken sichtbar ist.
Identifizieren Sie, welches Feld der Dokumentschlüssel ist. Sie können die Felder der einzelnen Indizes im Azure-Portal anzeigen. Dokumentschlüssel sind Zeichenfolgenfelder und mit einem Schlüsselsymbol gekennzeichnet, damit sie leichter zu erkennen sind.
Überprüfen Sie die Werte des Dokumentschlüsselfelds:
search=*&$select=HotelId. Eine einfache Zeichenfolge ist unproblematisch, aber wenn der Index ein Base-64-codiertes Feld verwendet oder wenn Suchdokumente über eineparsingMode-Einstellung generiert wurden, arbeiten Sie möglicherweise mit Werten, mit denen Sie nicht vertraut sind.Suchen Sie das Dokument, um den Wert der Dokument-ID zu verifizieren und seinen Inhalt zu überprüfen, bevor Sie es löschen. Geben Sie den Schlüssel oder die Dokument-ID in der Anforderung an. Die folgenden Beispiele zeigen eine einfache Zeichenfolge für den Beispielindex „Hotels“ und eine Base-64-codierte Zeichenfolge für den Schlüssel „metadata_storage_path“ des Index „cog-search-demo“.
GET https://[service name].search.windows.net/indexes/hotel-sample-index/docs/1111?api-version=2024-07-01GET https://[service name].search.windows.net/indexes/cog-search-demo/docs/aHR0cHM6Ly9oZWlkaWJsb2JzdG9yYWdlMi5ibG9iLmNvcmUud2luZG93cy5uZXQvY29nLXNlYXJjaC1kZW1vL2d1dGhyaWUuanBn0?api-version=2024-07-01Löschen Sie das Dokument mithilfe eines Löschvorgangs
@search.action, um es aus dem Suchindex zu entfernen.POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/index?api-version=2024-07-01 Content-Type: application/json api-key: [admin key] { "value": [ { "@search.action": "delete", "id": "1111" } ] }