Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Mit dem Azure Synapse Analytics-Arbeitsbereich können Sie zwei Arten von Datenbanken auf Basis eines Spark Data Lake erstellen:
- Lake-Datenbanken, in denen Sie Tabellen auf Basis von Lake Data mithilfe von Apache Spark-Notebooks, Datenbankvorlagen oder Microsoft Dataverse (zuvor Common Data Service) definieren können. Diese Tabellen können mithilfe der Sprache „T-SQL“ (Transact-SQL) unter Verwendung des serverlosen SQL-Pools abgefragt werden.
- SQL-Datenbanken, in denen Sie Ihre eigenen Datenbanken und Tabellen direkt mithilfe des serverlosen SQL-Pools definieren können. Sie können T-SQL CREATE DATABASE, CREATE EXTERNAL TABLE verwenden, um die Objekte zu definieren und zusätzliche SQL-Ansichten, Prozeduren und Inlinetabellen-Wertfunktionen auf Grundlage der Tabellen hinzuzufügen.
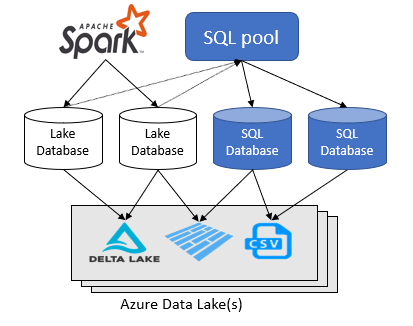
Dieser Artikel konzentriert sich auf Lake-Datenbanken in einem serverlosen SQL-Pool in Azure Synapse Analytics.
Azure Synapse Analytics ermöglicht Es Ihnen, Lake-Datenbanken und -Tabellen mithilfe von Spark oder dem Datenbank-Designer zu erstellen und dann Daten in den Lake-Datenbanken mithilfe des serverlosen SQL-Pools zu analysieren. Die (Parquet- oder CSV-gesicherten) Lake-Datenbanken und -Tabellen, die in den Apache Spark-Pools, den Lake-Datenbankvorlagen oder in Dataverse erstellt werden, sind automatisch für Abfragen mit der serverlosen SQL-Pool-Engine verfügbar. Die Lake-Datenbanken und -Tabellen, die geändert werden, sind nach einiger Zeit im serverlosen SQL-Pool verfügbar. Es gibt eine Verzögerung, bis die in Spark oder im Datenbank-Designer vorgenommenen Änderungen im serverlosen SQL-Pool angezeigt werden.
Verwalten von Lake-Datenbanken
Zum Verwalten von Lake-Datenbanken, die über Spark erstellt wurden, können Sie Apache Spark-Pools oder den Datenbank-Designer verwenden. Erstellen oder löschen Sie beispielsweise eine Lake-Datenbank über einen Spark-Poolauftrag. Sie können keine Lake-Datenbanken oder die Objekte in den Lake-Datenbanken mithilfe des serverlosen SQL-Pools erstellen.
Die Spark-default-Datenbank ist im Kontext des serverlosen SQL-Pools als Lake-Datenbank namens default verfügbar.
Hinweis
Sie können weder Lake- noch SQL-Datenbanken im serverlosen SQL-Pool mit demselben Namen erstellen.
Tabellen in den Lake-Datenbanken können nicht von einem serverlosen SQL-Pool geändert werden. Verwenden Sie den Datenbank-Designer oder Apache Spark-Pools, um eine Lake-Datenbank zu ändern. Mit dem serverlosen SQL-Pool können Sie die folgenden Änderungen in einer Lake-Datenbank mithilfe von T-SQL-Befehlen vornehmen:
- Hinzufügen, Ändern und Ablegen von Ansichten, Prozeduren, Inline-Tabellenwertfunktionen in einer Lake-Datenbank.
- Hinzufügen und Entfernen von Microsoft Entra-Benutzern im Datenbankbereich.
- Hinzufügen oder Entfernen von Microsoft Entra-Datenbankbenutzer*innen zur Rolle db_datareader. Microsoft Entra-Datenbankbenutzer in der Rolle db_datareader verfügen über die Berechtigung zum Lesen aller Tabellen in der Lake-Datenbank, können aber keine Daten aus anderen Datenbanken lesen.
Sicherheitsmodell
Die Lake-Datenbanken und -tabellen werden auf zwei Ebenen gesichert:
- Auf der zugrunde liegenden Speicherebene, indem Microsoft Entra-Benutzer*innen eines der Folgenden zugewiesen wird:
- Rollenbasierte Zugriffssteuerung von Azure (Azure RBAC)
- Attributbasierte Zugriffssteuerung in Azure (Azure ABAC)
- Berechtigungen für Zugriffssteuerungslisten (Access Control List, ACL)
- Auf der SQL-Ebene, auf der Sie einen Microsoft Entra-Benutzer definieren und SQL-Berechtigungen für das
SELECTvon Daten aus Tabellen erteilen können, die auf die Lake-Daten verweisen.
Lake-Sicherheitsmodell
Der Zugriff auf Lake-Datenbankdateien wird mithilfe der Lake-Berechtigungen auf Speicherebene gesteuert. Nur Microsoft Entra-Benutzer*innen können Tabellen in den Lake-Datenbanken verwenden, und sie können mithilfe ihrer eigenen Identitäten auf die Daten im Lake zugreifen.
Sie können Sicherheitsprinzipalen Zugriff auf die zugrunde liegenden Daten gewähren, die für externe Tabellen verwendet werden, z. B. Benutzer*innen, Microsoft Entra-Anwendungen mit zugewiesenem Dienstprinzipal oder Sicherheitsgruppen. Erteilen Sie für den Datenzugriff beide der folgenden Berechtigungen:
- Gewähren Sie
read (R)-Berechtigung für Dateien (z. B. die zugrunde liegenden Datendateien der Tabelle). - Gewähren Sie die
execute (X)-Berechtigung für den Ordner, in dem die Dateien gespeichert sind, und für jeden übergeordneten Ordner bis zum Stamm. Weitere Informationen zu diesen Berechtigungen finden Sie unter Zugriffssteuerungslisten (ACLs).
In https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/ benötigen Sicherheitsprinzipale beispielsweise:
-
execute (X)-Berechtigungen für alle Ordner beginnend ab<fs>bismyparquettable. -
read (R)-Berechtigungen fürmyparquettableund Dateien in diesem Ordner, um eine Tabelle in einer Datenbank lesen zu können (synchronisiert oder Original).
Wenn ein Sicherheitsprinzipal Objekte in einer Datenbank erstellen oder löschen können muss, sind zusätzliche Berechtigungen vom Typ write (W) für die Ordner und Dateien im Ordner warehouse erforderlich. Das Ändern von Objekten in einer Datenbank ist nicht über serverlose SQL-Pools möglich, sondern nur über Spark-Pools oder den Datenbank-Designer.
SQL-Sicherheitsmodell
Der Azure Synapse-Arbeitsbereich bietet einen T-SQL-Endpunkt, über den Sie die Lake-Datenbank mithilfe des serverlosen SQL-Pools abfragen können. Zusätzlich zum Datenzugriff können Sie über die SQL-Schnittstelle steuern, wer auf die Tabellen zugreifen kann. Sie müssen es einem Benutzer ermöglichen, mithilfe des serverlosen SQL-Pools auf die freigegebenen Lake-Datenbanken zuzugreifen. Es gibt zwei Arten von Benutzern, die auf die Lake-Datenbank zugreifen können:
- Administratoren: Weisen Sie die Arbeitsbereichsrolle Synapse SQL-Administrator oder die Rolle sysadmin auf Serverebene innerhalb des serverlosen SQL-Pools zu. Diese Rolle besitzt Vollzugriff auf alle Datenbanken. Die Rollen Synapse-Administrator und Synapse SQL-Administrator verfügen ebenfalls standardmäßig über alle Berechtigungen für alle Objekte in einem serverlosen SQL-Pool.
- Arbeitsbereichsleser: Gewähren Sie dem serverlosen SQL-Pool die Berechtigungen GRANT CONNECT ANY DATABASE und GRANT SELECT ALL USER SECURABLES auf Serverebene für eine Anmeldung, mit der die Anmeldung auf eine beliebige Datenbank zugreifen und diese lesen kann. Dies kann eine gute Wahl sein, um einem Benutzer den Leser- bzw. Nicht-Administrator-Zugriff zu erteilen.
- Datenbankleser: Erstellen Sie Datenbankbenutzer aus Microsoft Entra ID in Ihrer Lake-Datenbank, und fügen Sie sie der Rolle db_datareader hinzu, sodass sie Daten in der Lake-Datenbank lesen können.
Erfahren Sie mehr über das Festlegen der Zugriffssteuerung für freigegebene Datenbanken.
Benutzerdefinierte SQL-Objekte in Lake-Datenbanken
Lake-Datenbanken erlauben die Erstellung von benutzerdefinierten T-SQL-Objekten wie Schemas, Prozeduren, Sichten und die Inlinetabellen-Wertfunktionen (iTVFs). Um benutzerdefinierte SQL-Objekte zu erstellen, MÜSSEN Sie ein Schema erstellen, in dem Sie die Objekte platzieren. Benutzerdefinierte SQL-Objekte können nicht im dbo-Schema platziert werden, weil dieses für die Lake-Tabellen reserviert ist, die in Spark, Datenbank-Designer oder Dataverse definiert sind.
Wichtig
Sie müssen ein benutzerdefiniertes SQL-Schema erstellen, in dem Sie Ihre SQL-Objekte platzieren. Die benutzerdefinierten SQL-Objekte können nicht im dbo-Schema platziert werden. Das dbo-Schema ist für die Lake-Tabellen reserviert, die ursprünglich in Spark oder im Datenbank-Designer erstellt wurden.
Beispiele
Erstellen eines SQL-Datenbanklesers in der Lake-Datenbank
In diesem Beispiel fügen wir einen Microsoft Entra-Benutzer in der Lake-Datenbank hinzu, der Daten mithilfe von freigegebenen Tabellen lesen kann. Die Benutzer werden in der Lake-Datenbank über den serverlosen SQL-Pool hinzugefügt. Dann weisen Sie dem Benutzer die Rolle db_datareader zu, damit er die Daten lesen kann.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Erstellen Sie einen Datenleser auf Arbeitsbereichsebene
Eine Anmeldung mit GRANT CONNECT ANY DATABASE- und GRANT SELECT ALL USER SECURABLES-Berechtigungen kann alle Tabellen lesen, die den serverlosen SQL-Pool verwenden, kann aber keine SQL-Datenbanken erstellen oder die darin enthaltenen Objekte ändern.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Mit diesem Skript können Sie Benutzer ohne Administratorrechte erstellen, die alle Tabellen in Lake-Datenbanken lesen können.
Erstellen einer Spark-Datenbank mit einem serverlosen SQL-Pool und Herstellen einer Verbindung mit dieser Datenbank
Erstellen Sie zunächst unter Verwendung eines Spark-Clusters, den Sie bereits in Ihrem Arbeitsbereich erstellt haben, eine neue Spark-Datenbank mit dem Namen mytestlakedb. Hierzu können Sie beispielsweise ein Spark-C#-Notebook mit der folgenden Anweisung vom Typ „.NET für Spark“ verwenden:
spark.sql("CREATE DATABASE mytestlakedb")
Nach einer kurzen Verzögerung wird die Lake-Datenbank aus dem serverlosen SQL-Pool angezeigt. Führen Sie beispielsweise die folgende Anweisung über den serverlosen SQL-Pool aus:
SELECT * FROM sys.databases;
Vergewissern Sie sich, dass mytestlakedb in den Ergebnissen enthalten ist.
Erstellen benutzerdefinierter SQL-Objekte in Lake-Datenbanken
Das folgende Beispiel zeigt, wie Sie eine benutzerdefinierte Sicht, Prozedur und Inlinetabellen-Wertfunktion (iTVF) im reports-Schema erstellen:
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Zugehöriger Inhalt
- Azure Synapse Analytics: Gemeinsam genutzte Metadaten
- Azure Synapse Analytics: Gemeinsam genutzte Metadatentabellen
- Schnellstart: Erstellen einer neuen Lake-Datenbank anhand von Datenbankvorlagen
- Tutorial: Verwenden eines serverlosen SQL-Pools mit Power BI Desktop und Erstellen eines Berichts
- Synchronisieren von Apache Spark für externe Azure Synapse-Tabellendefinitionen im serverlosen SQL-Pool
- Tutorial: Untersuchen und Analysieren von Data Lakes mit einem serverlosen SQL-Pool