Konzepte für die Notfallwiederherstellung von Azure Virtual Desktop
Azure Virtual Desktop hat sich in den letzten Jahren zu einer wichtigen Lösung für Remote- und Hybridarbeit entwickelt. Da inzwischen sehr viele Benutzer remote arbeiten, benötigen Unternehmen Lösungen, die schnell bereitgestellt werden können und die Kosten senken. Darüber hinaus benötigen die Benutzer eine Remotearbeitsumgebung mit garantierter Verfügbarkeit und Resilienz, die ihnen auch in Notfallsituationen den Zugriff auf ihre virtuellen Computer (VMs) ermöglicht. In diesem Dokument werden Notfallpläne beschrieben, die wir zur Aufrechterhaltung des Betriebs in Ihrer Organisation empfehlen.
Um Systemausfälle oder Ausfallzeiten zu vermeiden, muss jedes System und jede Komponente in Ihrer Azure Virtual Desktop-Bereitstellung fehlertolerant sein. Von Fehlertoleranz spricht man, wenn eine Kopie der Konfiguration oder des Systems in einer anderen Azure-Region vorhanden ist, die bei einem Ausfall für die Hauptkonfiguration den Betrieb übernimmt. Diese sekundäre Konfiguration bzw. dieses System verringert die Auswirkungen eines lokal begrenzten Ausfalls. Es gibt viele Möglichkeiten zum Einrichten von Fehlertoleranz, dieser Artikel konzentriert sich jedoch nur auf die derzeit in Azure verfügbaren Methoden.
Azure Virtual Desktop-Infrastruktur
Um herauszufinden, für welche Bereiche Fehlertoleranz benötigt wird, muss zunächst geklärt werden, wer für die Wartung der einzelnen Bereiche verantwortlich ist. Sie können die Verantwortung für den Azure Virtual Desktop-Dienst in zwei Bereiche unterteilen: von Microsoft verwaltet und kundenseitig verwaltet. Metadaten wie Hostpools, Anwendungsgruppen und Arbeitsbereiche werden von Microsoft kontrolliert. Die Metadaten sind immer verfügbar und müssen vom Kunden nicht extra eingerichtet werden, um Hostpooldaten oder Konfigurationen zu replizieren. Die Gatewayinfrastruktur, die Benutzer mit ihren Sitzungshosts verbindet, wurde als globaler, hochgradig resilienter Dienst konzipiert, der von Microsoft verwaltet wird. Zu den kundenseitig verwalteten Bereichen gehören die virtuellen Computer (VMs), die in Azure Virtual Desktop verwendet werden, sowie die Einstellungen und Konfigurationen, die speziell für die Kundenbereitstellung gelten. Die folgende Tabelle gibt einen genaueren Überblick darüber, welche Bereiche von welcher Partei verwaltet werden.
| Von Microsoft verwaltet | Vom Kunden verwaltet |
|---|---|
| Load Balancer | Netzwerk |
| Sitzungsbroker | Sitzungshosts |
| Gateway | Speicher |
| Diagnose | Benutzerprofildaten |
| Cloud-Identitätsplattform | Identität |
In diesem Artikel konzentrieren wir uns auf die vom Kunden verwalteten Komponenten, da dies Einstellungen sind, die Sie selbst konfigurieren können.
Grundlagen der Notfallwiederherstellung
In diesem Abschnitt werden Maßnahmen und Entwurfsprinzipien erörtert, die Ihre Daten schützen und verhindern können, dass Sie nach einem kleineren Ausfall oder bei einem schweren Notfall große Anstrengungen zur Datenwiederherstellung unternehmen müssen. Bei weniger umfangreichen Ausfällen kann das Befolgen bestimmter kleinerer Schritte dazu beitragen, dass sie sich nicht zu größeren Notfällen ausweiten. Im Folgenden werden einige grundlegende Begriffe erläutert, die Sie beim Einrichten Ihres Notfallwiederherstellungsplans unterstützen.
Wenn Sie einen Notfallwiederherstellungsplan erarbeiten, sollten Sie die folgenden drei Dinge im Auge behalten:
- Hohe Verfügbarkeit: Verteilung der Infrastruktur, sodass kleinere, lokal begrenzte Ausfälle nicht zu einer Unterbrechung für die gesamte Bereitstellung führen. Ein Entwurf mit Berücksichtigung von Hochverfügbarkeit kann die Auswirkungen von Ausfällen minimieren und die Notwendigkeit einer vollständigen Notfallwiederherstellung vermeiden.
- Geschäftskontinuität: Die Frage, wie ein Unternehmen den Betrieb bei Ausfällen jeder Größenordnung aufrechterhalten kann.
- Notfallwiederherstellung: Der Prozess zur Wiederaufnahme des Betriebs nach einem vollständigen Ausfall.
Azure umfasst zahlreiche integrierte, kostenlose Features, die Hochverfügbarkeit auf vielen Ebenen bieten können. Das erste Feature sind Verfügbarkeitsgruppen, die VMs auf verschiedene Fehler- und Updatedomänen innerhalb von Azure verteilen. Als Nächstes folgen Verfügbarkeitszonen, bei denen es sich um physisch isolierte und geografisch verteilte Gruppen mit Rechenzentren handelt, die die Auswirkungen eines Ausfalls verringern können. Und schließlich sorgt die Verteilung von Sitzungshosts auf mehrere Azure-Regionen für eine noch bessere geografische Verteilung, wodurch die Auswirkungen von Ausfällen weiter reduziert werden. Alle drei Features bieten ein gewisses Maß an Schutz innerhalb von Azure Virtual Desktop, und Sie sollten sie zusammen mit etwaigen Kostenauswirkungen sorgfältig abwägen.
Grundsätzlich besteht die von uns empfohlene Strategie zur Notfallwiederherstellung für Azure Virtual Desktop darin, Ressourcen auf mehrere Verfügbarkeitszonen innerhalb einer Region zu verteilen. Wenn Sie mehr Schutz benötigen, können Sie Ressourcen auch über mehrere gekoppelte Azure-Regionen hinweg bereitstellen.
Aktiv/Passiv- und Aktiv/Aktiv-Bereitstellungen
Ein weiterer Punkt, den Sie beachten sollten, ist der Unterschied zwischen Aktiv/Passiv- und Aktiv/Aktiv-Plänen. Aktiv/Passiv-Pläne sind Pläne, bei denen Sie eine Region mit einem Satz aktiver Ressourcen verwenden sowie eine Region, die deaktiviert ist, bis sie benötigt wird (passiv). Wenn die aktive Region durch einen Notfall offline geht, kann die Organisation zur passiven Region wechseln, indem sie diese aktiviert und alle Benutzer dorthin verschiebt.
Eine andere Option ist eine Aktiv/Aktiv-Bereitstellung, bei der Sie beide Infrastrukturgruppen gleichzeitig verwenden. Auch wenn einige Benutzer von den Ausfällen betroffen sind, beschränken sich die Auswirkungen auf Benutzer in der Region, die ausgefallen ist. Benutzer in der anderen Region, die weiterhin online ist, sind nicht betroffen, und die Wiederherstellung ist auf die Benutzer in der betroffenen Region beschränkt, die sich erneut mit der funktionierenden aktiven Region verbinden. Aktiv/Aktiv-Bereitstellungen können viele Formen annehmen, darunter:
- Überbereitstellung der Infrastruktur in jeder Region, um die betroffenen Benutzer bei einem Ausfall in einer der Regionen aufzunehmen. Ein potenzieller Nachteil dieser Methode besteht darin, dass die zusätzlichen Ressourcen mehr kosten.
- Verwenden zusätzlicher Sitzungshosts in beiden aktiven Regionen, deren Zuordnung aufgehoben wird, wenn sie nicht benötigt werden, wodurch die Kosten sinken.
- Bereitstellen neuer Infrastrukturen nur während der Notfallwiederherstellung und Ermöglichen, dass die betroffenen Benutzer eine Verbindung mit den neu bereitgestellten Sitzungshosts herstellen. Diese Methode erfordert regelmäßige Tests mit Infrastructure-as-Code-Tools, damit Sie die neue Infrastruktur während eines Notfalls so schnell wie möglich bereitstellen können.
Empfohlene Methoden für die Notfallwiederherstellung
Wir empfehlen folgende Methoden für die Notfallwiederherstellung:
Konfigurieren und Bereitstellen von Azure-Ressourcen in mehreren Verfügbarkeitszonen.
Konfigurieren und Bereitstellen von Azure-Ressourcen in mehreren Regionen, entweder in Aktiv/Aktiv- oder Aktiv/Passiv-Konfigurationen. Diese Konfigurationen werden typischerweise für freigegebene Hostpools genutzt.
Für persönliche Hostpools mit dedizierten VMs sollten Sie die VMs mithilfe von Azure Site Recovery in eine andere Region replizieren.
Konfigurieren eines separaten Hostpools für die Notfallwiederherstellung in der sekundären Region Bei einem Notfall können Sie die Benutzer auf die sekundäre Region umschalten.
In den folgenden Abschnitten gehen wir näher auf die beiden Hauptmethoden für freigegebene und persönliche Hostpools ein.
Notfallwiederherstellung für freigegebene Hostpools
In diesem Abschnitt befassen wir uns mit freigegebenen (oder „gepoolten“) Hostpools, die einen Aktiv/Passiv-Ansatz verfolgen. Beim Aktiv/Passiv-Ansatz unterteilen Sie die vorhandenen Ressourcen in eine primäre und eine sekundäre Region. Normalerweise würde Ihre Organisation die gesamte Arbeit in der primären (oder „aktiven“) Region erledigen, aber bei einem Notfall müssen Sie lediglich die Ressourcen in der sekundären (oder „passiven“) Region abschalten (sofern dies möglich ist, je nach Ausmaß des Ausfalls) und die Ressourcen in der sekundären Region einschalten, um auf die sekundäre Region umzuschalten.
Das folgende Diagramm zeigt ein Beispiel für eine Bereitstellung mit redundanter Infrastruktur in einer sekundären Region. „Redundant“ bedeutet, dass eine Kopie der ursprünglichen Infrastruktur in dieser anderen Region vorhanden ist. Dies ist bei Bereitstellungen Standard, um Resilienz für alle Komponenten zu gewährleisten. Unterhalb einer Microsoft Entra ID-Instanz gibt es zwei Regionen: „USA, Westen“ und „USA, Osten“. Jede Region verfügt über zwei Sitzungshosts, auf denen ein Multisession-Betriebssystem (OS) ausgeführt wird, einen Server, auf dem Microsoft Entra Connect ausgeführt wird, einen Active Directory-Domänencontroller, eine Azure Files Premium-Dateifreigabe für FSLogix-Profile, ein Speicherkonto und ein virtuelles Netzwerk (VNET). In der primären Region (West US) sind alle Ressourcen aktiviert. In der sekundären Region (USA, Osten) sind die Sitzungshosts im Hostpool entweder deaktiviert oder befinden sich im Ausgleichsmodus, und der Microsoft Entra Connect-Server befindet sich im Stagingmodus. Die zwei VNETs in beiden Regionen sind per Peering miteinander verbunden.
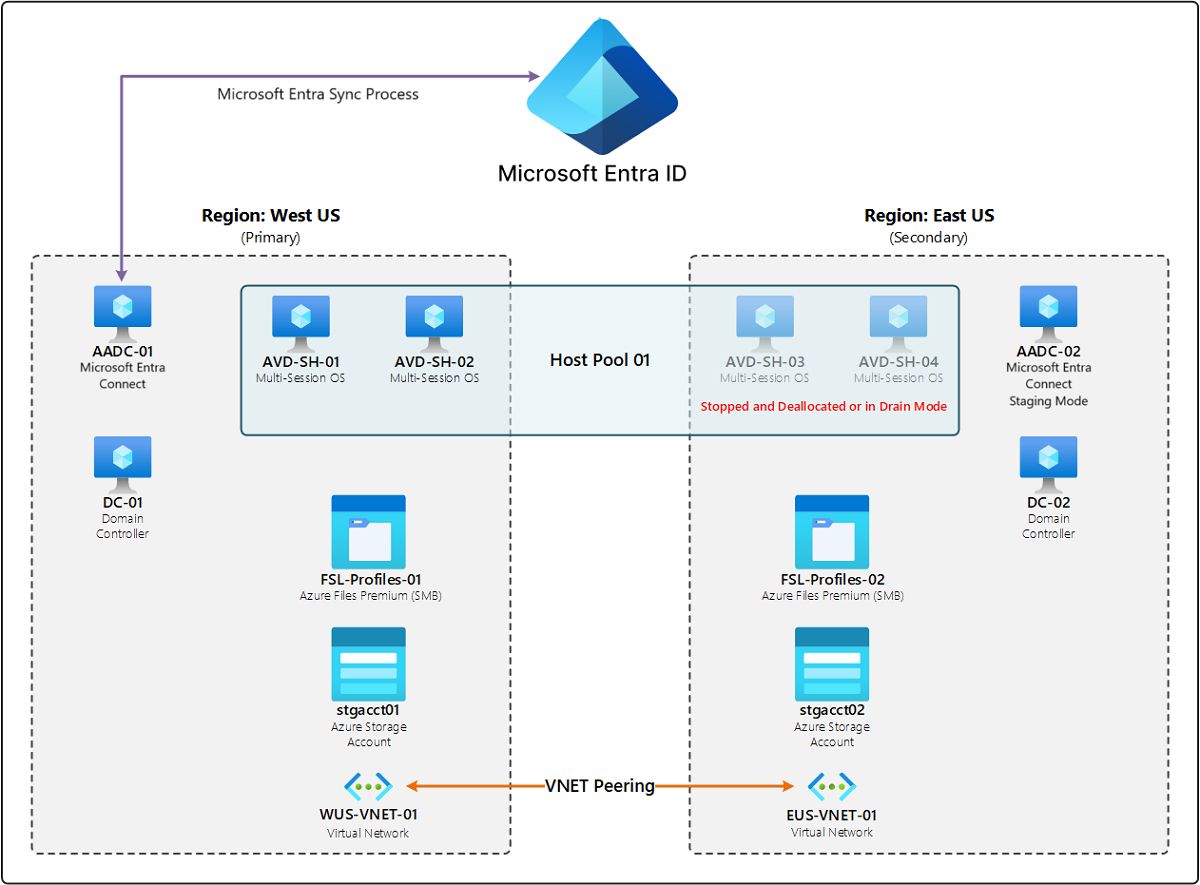
Wenn eine Komponente ausfällt oder die primäre Region nicht verfügbar ist, muss der Kunde in den meisten Fällen lediglich die Hosts aktivieren oder den Ausgleichsmodus in der sekundären Region aufheben, um Endbenutzerverbindungen zu ermöglichen. Dieses Szenario konzentriert sich auf die Verkürzung der Ausfallzeiten. Ein auf Redundanz basierender Notfallwiederherstellungsplan kann jedoch mehr kosten, da diese zusätzlichen Komponenten in der sekundären Region gewartet werden müssen.
Die potenziellen Vorteile dieses Plans sind folgende:
- Weniger Zeitaufwand für die Wiederherstellung nach Notfällen. So verbringen Sie beispielsweise weniger Zeit mit der Bereitstellung, Konfiguration, Integration und Überprüfung von neu bereitgestellten Ressourcen.
- Sie müssen keine komplizierten Verfahren anwenden.
- Das Failover kann problemlos auch außerhalb von Notfällen getestet werden.
Die potenziellen Nachteile sind folgende:
- Die Kosten können höher liegen, da mehr Infrastruktur verwaltet werden muss, z. B. Speicherkonten, Hosts usw.
- Sie müssen mehr Zeit für die Konfiguration Ihrer Bereitstellung aufwenden, um diesen Plan umzusetzen.
- Sie müssen die zusätzlich eingerichtete Infrastruktur auch dann warten, wenn Sie sie nicht benötigen.
Wichtige Informationen für die Wiederherstellung eines freigegebenen Hostpools
Wenn Sie diese Strategie zur Notfallwiederherstellung anwenden, sollten Sie die folgenden Dinge beachten:
Wenn mehrere Sitzungshosts in verschiedenen Regionen online sind, kann dies die Benutzerfreundlichkeit beeinträchtigen. Der verwaltete Netzwerklastenausgleich berücksichtigt nicht die geografische Nähe, sondern behandelt alle Hosts in einem Hostpool gleich.
Während eines Notfalls erstellen Benutzer neue Profile in der sekundären Region. Sie sollten alle geschäfts- oder unternehmenskritischen Daten auf OneDrive (mithilfe der bekannten Ordnerumleitung) oder SharePoint speichern. Wenn Sie Daten hier speichern, haben Benutzer bei geringen Beeinträchtigungen der Benutzerfreundlichkeit schnellen Zugriff auf ihre Anwendungen.
Stellen Sie sicher, dass Sie die VMs innerhalb Ihres Hostpools auf genau dieselbe Weise konfigurieren. Stellen Sie außerdem sicher, dass alle VMs in Ihrem Hostpool die gleiche Größe aufweisen. Wenn Ihre VMs nicht gleich sind, verteilt der verwaltete Netzwerklastenausgleich die Benutzerverbindungen gleichmäßig auf alle verfügbaren VMs. Kleinere VMs können im Vergleich zu größeren VMs früher als erwartet an ihre Ressourcengrenzen stoßen, was sich negativ auf das Benutzererlebnis auswirkt.
Die Verfügbarkeit der Region wirkt sich auf die Überwachung von Daten oder Arbeitsbereichen aus. Wenn eine Region nicht verfügbar ist, kann der Dienst bei einem Notfall alle historischen Überwachungsdaten verlieren. Wir empfehlen, einen benutzerdefinierten Export oder eine Sicherungskopie der historischen Überwachungsdaten zu verwenden.
Sie sollten Ihre Sitzungshosts mindestens einmal im Monat aktualisieren. Diese Empfehlung gilt für Sitzungshosts, die über einen längeren Zeitraum deaktiviert bleiben.
Testen Sie Ihre Bereitstellung, indem Sie mindestens einmal alle sechs Monate ein kontrolliertes Failover durchführen. Im Rahmen des kontrollierten Failovers wird Ihr sekundärer Standort bis zum nächsten kontrollierten Failover ggf. zum primären Standort. Wenn Sie Ihren sekundären Standort in den primären ändern, können die Benutzer bei einer echten Katastrophe über nahezu identische Profile verfügen.
Die folgende Tabelle enthält Bereitstellungsempfehlungen zu den Notfallwiederherstellungsstrategien für Hostpools:
| Technologie | Empfehlungen |
|---|---|
| Netzwerk | Erstellen und implementieren Sie ein sekundäres virtuelles Netzwerk in einer anderen Region, und konfigurieren Sie ein Azure-Peering mit Ihrem primären virtuellen Netzwerk. |
| Sitzungshosts | Erstellen und implementieren Sie einen freigegebenen Azure Virtual Desktop-Hostpool mit Multisession-Betriebssystem-SKU, und schließen Sie VMs aus anderen Verfügbarkeitszonen und einer anderen Region ein. |
| Speicher | Erstellen Sie Speicherkonten in mehreren Regionen mit Konten des Premium-Tarifs. |
| Benutzerprofildaten | Erstellen Sie in mehreren Regionen SMB-Speicherorte. |
| Identität | Active Directory-Domänencontroller aus demselben Verzeichnis. |
Notfallwiederherstellung für persönliche Hostpools
Für persönliche Hostpools sollte Ihre Notfallwiederherstellungsstrategie die Replikation Ihrer Ressourcen in eine sekundäre Region mit einem Azure Site Recovery Services-Tresor beinhalten. Wenn Ihre primäre Region bei einem Notfall offline geht, kann Azure Site Recovery ein Failover durchführen und die Ressourcen in Ihrer sekundären Region aktivieren.
Nehmen wir zum Beispiel an, Sie verfügen über eine Bereitstellung mit einer primären Region in „West US“ und einer sekundären Region in „East US“. Die primäre Region umfasst einen persönlichen Hostpool mit jeweils zwei Sitzungshosts. Jeder Sitzungshost verfügt über einen eigenen lokalen Datenträger mit den Benutzerprofildaten und über ein eigenes VNET, das nicht mit anderen Systemen gekoppelt ist. Bei einem Notfall können Sie mit Azure Site Recovery ein Failover auf die sekundäre Region in „East US“ (oder auf eine andere Verfügbarkeitszone in derselben Region) durchführen. Anders als die primäre Region verfügt die sekundäre Region über keine lokalen Computer oder Datenträger. Während des Failovers nutzt Azure Site Recovery die replizierten Daten aus dem Azure Site Recovery-Tresor, um zwei neue VMs zu erstellen. Hierbei handelt es sich um Kopien der ursprünglichen Sitzungshosts, einschließlich des lokalen Datenträgers und der Benutzerprofildaten. Die sekundäre Region verfügt über ein eigenes, unabhängiges VNET, sodass der Ausfall des VNET in der primären Region keine Auswirkungen auf die Funktionalität hat.
Das folgende Diagramm zeigt die soeben beschriebene Beispielbereitstellung.

Zu den Vorteilen dieses Plans gehören niedrigere Gesamtkosten und keinerlei Wartungsaufwand für Patches oder Updates, da die Ressourcen nur dann bereitgestellt werden, wenn Sie sie benötigen. Ein potenzieller Nachteil ist jedoch, dass Sie mehr Zeit für die Bereitstellung, Integration und Überprüfung der Failoverinfrastruktur aufwenden müssen als beim Einrichten einer Notfallwiederherstellung mit einem freigegebenen Hostpool.
Wichtige Informationen für die Wiederherstellung eines persönlichen Hostpools
Wenn Sie diese Strategie zur Notfallwiederherstellung anwenden, sollten Sie die folgenden Dinge beachten:
Es gelten möglicherweise bestimmte Anforderungen, die die VMs im Hostpool erfüllen müssen, um am sekundären Standort zu funktionieren, z. B. virtuelle Netzwerke, Subnetze, Netzwerksicherheit oder VPNs für den Zugriff auf ein Verzeichnis wie lokales Active Directory.
Hinweis
Mit einer in Microsoft Entra eingebundenen VM werden einige dieser Anforderungen automatisch erfüllt.
Es kann zu Problemen bei der Integration oder der Leistung von Ressourcen oder zu Ressourcenkonflikten kommen, wenn sich ein Notfall von großem Ausmaß auf mehrere Kunden oder Mandanten auswirkt.
Persönliche Hostpools verwenden VMs, die einem Benutzer zugeordnet sind. Das bedeutet, dass die Regeln für den Lastenausgleich mit Affinität alle Benutzersitzungen an eine bestimmte VM zurückleiten. Diese 1:1-Zuordnung zwischen Benutzer und VM bewirkt, dass sich der Benutzer bei einem Ausfall einer VM erst dann erneut anmelden kann, wenn die VM wieder online ist bzw. wenn die VM nach Abschluss der Notfallwiederherstellung wiederhergestellt wurde.
VMs in einem persönlichen Hostpool speichern das Benutzerprofil auf Laufwerk C, d. h. FSLogix wird nicht benötigt.
Die Verfügbarkeit der Region wirkt sich auf die Überwachung von Daten oder Arbeitsbereichen aus. Wenn eine Region nicht verfügbar ist, kann der Dienst bei einem Notfall alle historischen Überwachungsdaten verlieren. Wir empfehlen, einen benutzerdefinierten Export oder eine Sicherungskopie der historischen Überwachungsdaten zu verwenden.
Es wird empfohlen, FSLogix nicht zu verwenden, wenn Sie eine Konfiguration mit persönlichen Hostpools verwenden.
Die Bereitstellung virtueller Computer in der Failoverregion ist nicht garantiert.
Führen Sie mindestens einmal alle sechs Monate ein kontrolliertes Failover und Failbacktests durch.
Die folgende Tabelle enthält Bereitstellungsempfehlungen zu den Notfallwiederherstellungsstrategien für Hostpools:
| Technologie | Empfehlungen |
|---|---|
| Netzwerk | Erstellen und implementieren Sie ein sekundäres virtuelles Netzwerk in einer anderen Region, um benutzerdefinierte Namenskonventionen oder Sicherheitsanforderungen außerhalb des Standardnamensschemas von Azure Site Recovery zu erfüllen. |
| Sitzungshosts | Aktivieren und konfigurieren Sie Azure Site Recovery für VMs. Optional können Sie ein Image manuell vorbereiten oder den Azure Image Builder-Dienst für die fortlaufende Bereitstellung verwenden. |
| Speicher | Für die Speicherung von Profilen kann optional ein Azure Storage-Konto erstellt werden. |
| Benutzerprofildaten | Benutzerprofildaten werden lokal auf Laufwerk C gespeichert. |
| Identität | Active Directory-Domänencontroller aus demselben Verzeichnis über mehrere Regionen hinweg. |
Nächste Schritte
Ausführlichere Informationen zur Notfallwiederherstellung in Azure finden Sie in diesen Artikeln:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für