Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie Sie das Parkettformat in der Pipeline von Data Factory in Microsoft Fabric konfigurieren.
Unterstützte Funktionen
Das Parquet-Format wird für die folgenden Aktivitäten und Anschlüsse als Quelle und Ziel unterstützt.
| Kategorie | Connector/Aktivität |
|---|---|
| Unterstützter Connector | Amazon S3 |
| Amazon S3-kompatibel | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| Dateisystem | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Lakehouse-Dateien | |
| Oracle Cloud Storage | |
| SFTP | |
| Unterstützte Aktivität | Kopieraktivität (Quelle/Ziel) |
| Lookup-Aktivität | |
| GetMetadata-Aktivität | |
| Aktivität löschen |
Parquet-Format in Kopieraktivität
Um das Parquet-Format zu konfigurieren, wählen Sie Ihre Verbindung in der Quelle oder am Ziel einer Pipeline-Kopieraktivität aus und wählen Sie dann Parquet in der Dropdownliste des Dateiformats aus. Wählen Sie für die weitere Konfiguration dieses Formats Einstellungen aus.
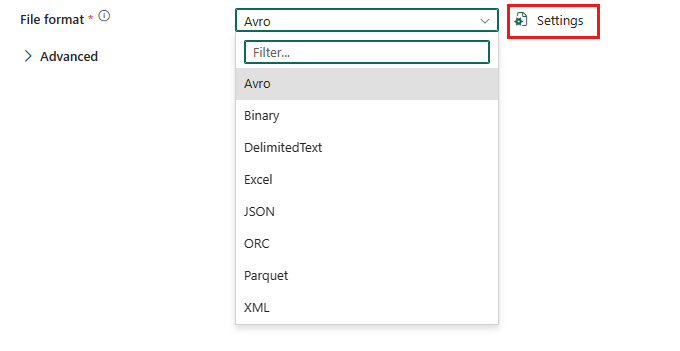
Parquet-Format als Quelle
Nachdem Sie im Abschnitt Dateiformat die Option Einstellungen ausgewählt haben, werden die folgenden Eigenschaften im Popupdialogfeld Dateiformateinstellungen angezeigt.
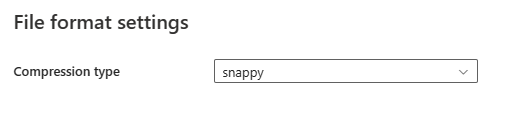
- Komprimierungstyp: Wählen Sie im Dropdownmenü den Codec für die Komprimierung aus, der zum Lesen von Parquet-Dateien verwendet wird. Sie haben folgende Auswahlmöglichkeiten: Keine, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2) oder lz4hadoop.
Parquet-Format als Ziel
Nach Auswahl von Einstellungen werden die folgenden Eigenschaften im Popupdialogfeld Dateiformateinstellungen angezeigt.
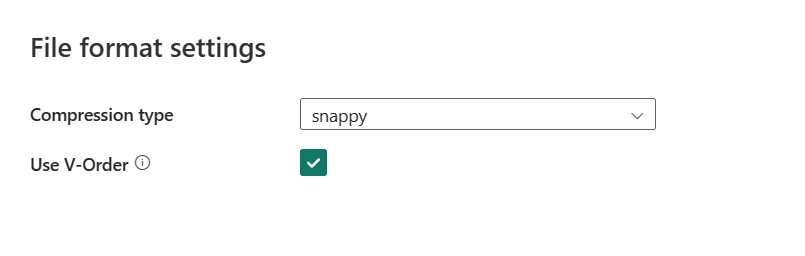
Komprimierungstyp: Wählen Sie im Dropdownmenü den Codec für die Komprimierung aus, der zum Schreiben von Parquet-Dateien verwendet wird. Sie haben folgende Auswahlmöglichkeiten: Keine, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2) oder lz4hadoop.
V-Reihenfolge verwenden: Aktiviert eine Optimierung der Schreibzeit für das Parquet-Dateiformat. Weitere Informationen finden Sie unter Delta Lake-Tabellenoptimierung und V-Reihenfolge. Sie ist standardmäßig aktiviert.
Auf der Registerkarte Ziel werden in den Einstellungen Erweitert die folgenden Eigenschaften zum Parquet-Format angezeigt.
- Max. Anzahl Zeilen pro Datei: Wenn Sie Daten in einen Ordner schreiben, können Sie wahlweise in mehrere Dateien schreiben und die maximale Anzahl von Zeilen pro Datei angeben. Geben Sie die maximalen Anzahl von Zeilen an, die Sie pro Datei schreiben möchten.
-
Dateinamenpräfix: Wird angewendet, wenn Max. Anzahl Zeilen pro Datei konfiguriert ist. Geben Sie das Dateinamenpräfix beim Schreiben von Daten in mehrere Dateien an, das zu diesem Muster führt:
<fileNamePrefix>_00000.<fileExtension>. Wenn keine Angabe erfolgt, wird das Dateinamenpräfix automatisch generiert. Diese Eigenschaft wird nicht angewendet, wenn die Quelle ein dateibasierter Speicher oder ein Datenspeicher mit aktivierter Partitionsoption ist.
Kartierung
Wenn Sie für die Konfiguration der Registerkarte "Zuordnung" kein Parquet-Format als Zieldatenspeicher anwenden, wechseln Sie zu "Zuordnung".
Bearbeiten von Zieldatentypen
Wenn Sie Daten im Parquet-Format in den Zielconnector kopieren, außer der Konfiguration von Zuordnung, können Sie bestimmte Zielspaltentypen angeben, nachdem die erweiterten Parquet-Typ-Einstellungen aktiviert wurden. Sie können auch die IsNullable-Option konfigurieren, um anzugeben, ob jede Parquet-Zielspalte Nullwerte zulässt. Der Standardwert für IsNullable ist true.
Die folgenden Zuordnungen werden von interimistischen Datentypen, die intern vom Dienst zur Bearbeitung unterstützt werden, auf Parquet-Datentypen vorgenommen.
| Zwischendienstdatentyp | Logischer Parketttyp | Parkett physischer Typ |
|---|---|---|
| DateTime | Option 1: NULL Option 2: ZEITSTEMPEL |
Option 1: INT96 (Standard) Option 2: INT64 (Einheit: MILLIS, MIKROS, NANOS (Standard)) |
| DateTimeOffset | Option 1: NULL Option 2: ZEITSTEMPEL |
Option 1: INT96 (Standard) Option 2: INT64 (Einheit: MILLIS, MIKROS, NANOS (Standard)) |
| TimeSpan | TIME | INT32 (Einheit: MILLIS) INT64 (Einheit: MICROS, NANOS (Standard)) |
| Decimal | DEZIMAL | INT32 (1 <= Genauigkeit <= 9) INT64 (9 < Genauigkeit <= 18) FIXED_LEN_BYTE_ARRAY (Genauigkeit > 18) (Standard) |
| GUID | Option 1: STRING Option 2: UUID |
Option 1: BYTE_ARRAY (Standardmäßig) Option 2: FIXED_LEN_BYTE_ARRAY (festgelegte Längenbytefolge) |
| Byte-Array | NULL | BYTE_ARRAY (Standard) oder FIXED_LEN_BYTE_ARRAY |
Der Typ für die Spalte "decimalData " in der Quelle wird z. B. in einen Zwischendiensttyp konvertiert: Dezimal. Gemäß der obigen Zuordnungstabelle wird der zugeordnete Typ für die Zielspalte automatisch entsprechend der angegebenen Genauigkeit bestimmt. Wenn die Genauigkeit 9 oder kleiner ist, wird sie INT32 zugeordnet. Bei Genauigkeitswerten über 9 und bis zu 18 wird sie INT64 zugeordnet. Wenn die Genauigkeit 18 überschreitet, wird sie FIXED_LEN_BYTE_ARRAY zugeordnet.
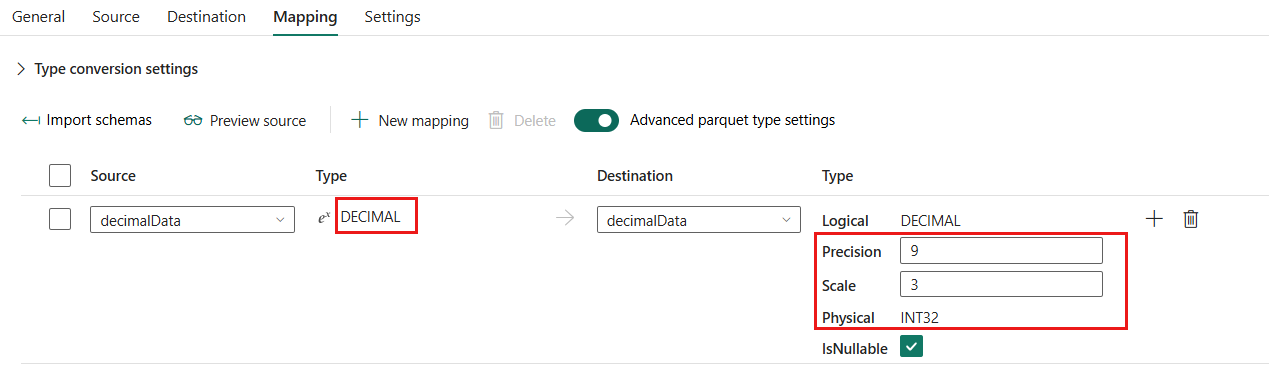
Datentypzuordnung für Parkett
Beim Kopieren von Daten aus dem Quellkonnektor im Parquet-Format werden die folgenden Zuordnungen von Parquet-Datentypen zu Zwischendatentypen verwendet, die vom Dienst intern genutzt werden.
| Logischer Parketttyp | Parkett physischer Typ | Zwischendienstdatentyp |
|---|---|---|
| NULL | BOOLEAN | Boolean |
| INT(8; true) | INT32 | SByte |
| INT(8, false) | INT32 | Byte |
| INT(16; wahr) | INT32 | Int16 |
| INT(16, false) | INT32 | UInt16 |
| INT(32; wahr) | INT32 | Int32 |
| INT(32, false) | INT32 | UInt32 |
| INT(64; wahr) | INT64 | Int64 |
| INT(64, false) | INT64 | UInt64 |
| NULL | FLOAT | Ledig |
| NULL | DOPPELT | Double |
| DEZIMAL | INT32, INT64, FIXED_LEN_BYTE_ARRAY oder BYTE_ARRAY | Decimal |
| DATE | INT32 | Datum |
| TIME | INT32 oder INT64 | DateTime |
| TIMESTAMP | INT64 | DateTime |
| ENUM | BYTE_ARRAY | String |
| UUID | FIXED_LEN_BYTE_ARRAY | GUID |
| NULL | BYTE_ARRAY | Byte-Array |
| STRING | BYTE_ARRAY | String |
Beim Kopieren von Daten in den Zielkonnektor im Parquet-Format werden die folgenden Zuordnungen von Zwischendatentypen, die der Dienst intern verwendet, zu Parquet-Datentypen genutzt.
| Zwischendienstdatentyp | Logischer Parketttyp | Parkett physischer Typ |
|---|---|---|
| Boolean | NULL | BOOLEAN |
| SByte | INT | INT32 |
| Byte | INT | INT32 |
| Int16 | INT | INT32 |
| UInt16 | INT | INT32 |
| Int32 | INT | INT32 |
| UInt32 | INT | INT32 |
| Int64 | INT | INT64 |
| UInt64 | INT | INT64 |
| Ledig | NULL | FLOAT |
| Double | NULL | DOPPELT |
| DateTime | NULL | INT96 |
| DateTimeOffset | NULL | INT96 |
| Datum | DATE | INT32 |
| TimeSpan | TIME | INT64 |
| Decimal | DEZIMAL | INT32, INT64 oder FIXED_LEN_BYTE_ARRAY |
| GUID | STRING | BYTE-ARRAY |
| String | STRING | Byte-Array |
| Byte-Array | NULL | BYTE_ARRAY |
Tabellenzusammenfassung
Parquet als Quelle
Die folgenden Eigenschaften werden im Abschnitt Quelle der Copy-Aktivität unterstützt, wenn das Parquet-Format verwendet wird.
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Dateiformat | Das Dateiformat aus, das Sie verwenden möchten. | Parquet | Ja | Typ (unter datasetSettings):Parquet |
| Komprimierungstyp | Der Kompressionscodec, der zum Lesen von Parquet-Dateien verwendet wird. | Folgende Optionen stehen zur Auswahl: None gzip (.gz) snappy lzo Brotli (BR) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
Nein | compressionCodec: gzip flott lzo Brotli zstd lz4 lz4frame bz2 lz4hadoop |
Parquet als Ziel
Die folgenden Eigenschaften werden im Abschnitt Ziel der Copy-Aktivität unterstützt, wenn das Parquet-Format verwendet wird.
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Dateiformat | Das Dateiformat aus, das Sie verwenden möchten. | Parquet | Ja | Typ (unter datasetSettings):Parquet |
| V-Reihenfolge verwenden | Eine Schreibzeitoptimierung für das Parquet-Dateiformat. | Ausgewählt oder nicht ausgewählt | Nein | enableVertiParquet |
| Komprimierungstyp | Der zum Schreiben von Parquet-Dateien verwendete Komprimierungs-Codec. | Folgende Optionen stehen zur Auswahl: None gzip (.gz) snappy lzo Brotli (BR) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
Nein | compressionCodec: gzip flott lzo Brotli zstd lz4 lz4frame bz2 lz4hadoop |
| Max. Anzahl Zeilen pro Datei | Wenn Sie Daten in einen Ordner schreiben, können Sie wahlweise in mehrere Dateien schreiben und die maximale Anzahl von Zeilen pro Datei angeben. Geben Sie die maximalen Anzahl von Zeilen an, die Sie pro Datei schreiben möchten. | <Ihr Wert für die max. Zeilenzahl pro Datei> | Nein | maximale Zeilen pro Datei |
| Dateinamenpräfix | Wird angewendet, wenn Max. Anzahl Zeilen pro Datei konfiguriert ist. Geben Sie das Dateinamenpräfix beim Schreiben von Daten in mehrere Dateien an, das zu diesem Muster führt: <fileNamePrefix>_00000.<fileExtension>. Wenn keine Angabe erfolgt, wird das Dateinamenpräfix automatisch generiert. Diese Eigenschaft wird nicht angewendet, wenn die Quelle ein dateibasierter Speicher oder ein Datenspeicher mit aktivierter Partitionsoption ist. |
<Ihr Dateinamenpräfix> | Nein | Dateinamenspräfix |