Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel erfahren Sie, wie Sie die Kopieraktivität in einer Datenpipeline verwenden, um Daten aus und in das Fabric Lakehouse zu kopieren. Standardmäßig werden Daten in der Lakehouse-Tabelle in V-Reihenfolge geschrieben, und Sie können zu Delta Lake-Tabellenoptimierung und V-Reihenfolge wechseln, um weitere Informationen zu erhalten.
Unterstütztes Format:
Lakehouse unterstützt die folgenden Dateiformate: Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Textformat mit Trennzeichen
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Unterstützte Konfiguration
Die Konfiguration der einzelnen Registerkarten unter der Copy-Aktivität finden Sie in den folgenden Abschnitten.
Allgemein
Wechseln Sie für die Konfiguration der Registerkarte Allgemein zu Allgemein.
Quelle
Die folgenden Eigenschaften werden für Lakehouse auf der Registerkarte Quelle einer Kopieraktivität unterstützt.

Die folgenden Eigenschaften sind erforderlich:
Verbindung: Wählen Sie in der Verbindungsliste eine Lakehouse-Verbindung aus. Wenn keine Verbindung vorhanden ist, erstellen Sie eine neue Lakehouse-Verbindung, indem Sie unten in der Verbindungsliste Mehr auswählen. Wenn Sie die Option Dynamischen Inhalt verwenden anwenden, um Ihr Lakehouse anzugeben, fügen Sie einen Parameter hinzu, und geben Sie die Lakehouse-Objekt-ID als Parameterwert an. Um Ihre Lakehouse-Objekt-ID abzurufen, öffnen Sie Ihr Lakehouse in Ihrem Arbeitsbereich. Die ID befindet sich hinter
/lakehouses/Ihrer URL.
Stammordner: Wählen Sie Tabellen oder Dateien aus, um die virtuelle Ansicht des verwalteten oder nicht verwalteten Bereichs in Ihrem Lake anzugeben. Weitere Informationen finden Sie unter Einführung in Lakehouse.
Wenn Sie Tabellen auswählen:
Tabellenname: Wählen Sie eine vorhandene Tabelle aus der Tabellenliste aus, oder geben Sie einen Tabellennamen als Quelle an. Sie können auch Neu auswählen, um eine neue Tabelle zu erstellen.

Tabelle: Wenn Sie Lakehouse mit Schemata in der Verbindung anwenden, wählen Sie eine vorhandene Tabelle mit einem Schema aus der Tabellenliste aus, oder geben Sie eine Tabelle mit einem Schema als Quelle an. Sie können auch Neu auswählen, um eine neue Tabelle mit einem Schema zu erstellen. Wenn Sie keinen Schemanamen angeben, verwendet der Dienst dbo als Standardschema.

Unter Erweitert können Sie die folgenden Felder angeben:
- Zeitstempel: Geben Sie an, dass eine ältere Momentaufnahme nach Zeitstempel abgefragt werden soll.
- Version: Geben Sie an, dass eine ältere Momentaufnahme nach Version abgefragt werden soll.
- Zusätzliche Spalten: Fügen Sie zusätzliche Datenspalten hinzu, um den relativen Pfad oder statischen Wert der Quelldateien zu speichern. Für Letzteres wird ein Ausdruck unterstützt.
Wenn Sie Dateien auswählen:
Dateipfadtyp: Sie können Dateipfad, Platzhalterdateipfad oder Liste der Dateien als Dateipfadtyp auswählen. In der folgenden Liste wird die Konfiguration der einzelnen Einstellungen beschrieben:

Dateipfad: Wählen Sie Durchsuchen aus, um die Datei auszuwählen, die Sie kopieren möchten, oder geben Sie den Pfad manuell ein.
Platzhalterdateipfad: Geben Sie den Ordner- oder Dateipfad mit Platzhalterzeichen unter dem von Ihnen angegebenen nicht verwalteten Bereich von Lakehouse (unter „Dateien“) an, um Ihre Quellordner oder -dateien zu filtern. Folgende Platzhalter sind zulässig:
*(entspricht null oder mehr Zeichen) und?(entspricht null oder einem einzelnen Zeichen). Verwenden Sie^als Escapezeichen, wenn Ihr Ordner- oder Dateiname einen Platzhalter oder dieses Escapezeichen enthält.Platzhalterordnerpfad: Der Pfad zu dem Ordner unter dem angegebenen Container. Wenn Sie einen Platzhalter verwenden möchten, um den Ordner zu filtern, überspringen Sie diese Einstellung, und geben Sie diese Informationen in den entsprechenden Aktivitätsquelleneinstellungen an.
Platzhalterdateiname: Der Dateiname unter dem angegebenen nicht verwalteten Bereich von Lakehouse (unter „Dateien“) und dem Ordnerpfad.

Liste der Dateien: Gibt an, dass ein bestimmter Dateisatz kopiert werden soll.
- Ordnerpfad: Zeigt auf einen Ordner, der Dateien enthält, die Sie kopieren möchten.
- Pfad zu Dateiliste: Zeigt auf eine Textdatei, die eine Liste der Dateien enthält, die Sie kopieren möchten, und zwar eine Datei pro Zeile, die den relativen Pfad zum konfigurierten Dateipfad darstellt.

Rekursiv: Gibt an, ob die Daten rekursiv aus den Unterordnern oder nur aus dem angegebenen Ordner gelesen werden. Wenn diese Option aktiviert ist, werden alle Dateien im Eingabeordner und seinen Unterordnern rekursiv verarbeitet. Diese Eigenschaft gilt nicht, wenn Sie Ihren Dateipfadtyp als Liste der Dateien konfigurieren.
Dateiformat: Wählen Sie Ihr Dateiformat aus der Dropdownliste aus. Wählen Sie die Schaltfläche Einstellungen aus, um das Dateiformat zu konfigurieren. Detaillierte Informationen zu den Einstellungen der verschiedenen Dateiformate finden Sie in den Artikeln unter Unterstützte Formate.
Unter Erweitert können Sie die folgenden Felder angeben:
-
Nach der letzten Änderung filtern: Dateien werden nach dem Datum der letzten Änderung gefiltert. Diese Eigenschaft gilt nicht, wenn Sie Ihren Dateipfadtyp als Liste der Dateien konfigurieren.
- Startzeit: Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer oder gleich der konfigurierten Zeit ist.
- Endzeit: Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung kleiner als die konfigurierte Zeit ist.
-
Partitionsermittlung aktivieren: Geben Sie für partitionierte Dateien an, ob die Partitionen aus dem Dateipfad analysiert und als zusätzliche Quellspalten hinzugefügt werden sollen.
- Stammverzeichnis der Partition: Wenn die Partitionsermittlung aktiviert ist, geben Sie den absoluten Stammverzeichnispfad an, um partitionierte Ordner als Datenspalten zu lesen.
- Maximale Anzahl gleichzeitiger Verbindungen: Gibt die Obergrenze der gleichzeitigen Verbindungen zum Datenspeicher an, die während des Ausführens der Aktivität hergestellt werden. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten.
-
Nach der letzten Änderung filtern: Dateien werden nach dem Datum der letzten Änderung gefiltert. Diese Eigenschaft gilt nicht, wenn Sie Ihren Dateipfadtyp als Liste der Dateien konfigurieren.



Ziel
Die folgenden Eigenschaften werden für Lakehouse auf der Registerkarte Ziel einer Kopieraktivität unterstützt.

Die folgenden Eigenschaften sind erforderlich:
Verbindung: Wählen Sie in der Verbindungsliste eine Lakehouse-Verbindung aus. Wenn keine Verbindung vorhanden ist, erstellen Sie eine neue Lakehouse-Verbindung, indem Sie unten in der Verbindungsliste Mehr auswählen. Wenn Sie die Option Dynamischen Inhalt verwenden anwenden, um Ihr Lakehouse anzugeben, fügen Sie einen Parameter hinzu, und geben Sie die Lakehouse-Objekt-ID als Parameterwert an. Um Ihre Lakehouse-Objekt-ID abzurufen, öffnen Sie Ihr Lakehouse in Ihrem Arbeitsbereich. Die ID befindet sich hinter
/lakehouses/Ihrer URL.
Stammordner: Wählen Sie Tabellen oder Dateien aus, um die virtuelle Ansicht des verwalteten oder nicht verwalteten Bereichs in Ihrem Lake anzugeben. Weitere Informationen finden Sie unter Einführung in Lakehouse.
Wenn Sie Tabellen auswählen:
Tabellenname: Wählen Sie eine vorhandene Tabelle aus der Tabellenliste aus, oder geben Sie einen Tabellennamen als Ziel an. Sie können auch Neu auswählen, um eine neue Tabelle zu erstellen.
Tabelle: Wenn Sie Lakehouse mit Schemata in der Verbindung anwenden, wählen Sie eine vorhandene Tabelle mit einem Schema aus der Tabellenliste aus, oder geben Sie eine Tabelle mit einem Schema als Ziel an. Sie können auch Neu auswählen, um eine neue Tabelle mit einem Schema zu erstellen. Wenn Sie keinen Schemanamen angeben, verwendet der Dienst dbo als Standardschema.
Hinweis
Der Tabellenname muss mindestens ein Zeichen lang sein, darf weder „/“ noch „\“ enthalten, keinen abschließenden Punkt und keine führenden oder abschließenden Leerzeichen haben.
- Unter "Erweitert" können Sie die folgenden Felder angeben:
Tabellenaktionen: Geben Sie den Vorgang für die ausgewählte Tabelle an.
Anfügen: Fügen Sie neue Werte an die bestehende Tabelle an.
-
Partition aktivieren: Mit dieser Auswahl können Sie Partitionen in einer Ordnerstruktur basierend auf einer oder mehreren Spalten erstellen. Jeder eindeutige Spaltenwert (Paar) ist eine neue Partition. Beispiel: „year=2000/month=01/file“.
- Partitionierungsspaltenname: Wählen Sie diesen aus den Zielspalten in der Schemazuordnung aus, wenn Sie Daten an eine neue Tabelle anhängen. Wenn Sie Daten an eine bestehende Tabelle anhängen, die bereits Partitionen hat, werden die Partitionierungsspalten automatisch von der bestehenden Tabelle abgeleitet. Unterstützte Datentypen sind String, Integer, Boolean und DateTime. Das Format respektiert die Einstellungen für die Typkonvertierung unter der Registerkarte Zuordnung.
-
Partition aktivieren: Mit dieser Auswahl können Sie Partitionen in einer Ordnerstruktur basierend auf einer oder mehreren Spalten erstellen. Jeder eindeutige Spaltenwert (Paar) ist eine neue Partition. Beispiel: „year=2000/month=01/file“.
Überschreiben: Überschreiben Sie die vorhandenen Daten und das Schema in der Tabelle mithilfe der neuen Werte. Wenn dieser Vorgang ausgewählt ist, können Sie die Partitionierung Ihrer Zieltabelle aktivieren.
-
Partition aktivieren: Mit dieser Auswahl können Sie Partitionen in einer Ordnerstruktur basierend auf einer oder mehreren Spalten erstellen. Jeder eindeutige Spaltenwert (Paar) ist eine neue Partition. Beispiel: „year=2000/month=01/file“.
- Spaltenname der Partition: Wählen Sie aus den Zielspalten in der Schemazuordnung aus. Unterstützte Datentypen sind String, Integer, Boolean und DateTime. Das Format respektiert die Einstellungen für die Typkonvertierung unter der Registerkarte Zuordnung.
Es unterstützt Ortswechsel in der angegebenen Zeit für Delta Lake. Die überschriebene Tabelle enthält Deltaprotokolle für die vorherigen Versionen, auf die Sie in Ihrem Lakehouse zugreifen können. Sie können auch die vorherige Versionstabelle aus Lakehouse kopieren, indem Sie Version in der Copy-Aktivitätsquelle angeben.
-
Partition aktivieren: Mit dieser Auswahl können Sie Partitionen in einer Ordnerstruktur basierend auf einer oder mehreren Spalten erstellen. Jeder eindeutige Spaltenwert (Paar) ist eine neue Partition. Beispiel: „year=2000/month=01/file“.
Upsert (Vorschau):Fügen Sie neue Werte in vorhandene Tabelle ein, und aktualisieren Sie vorhandene Werte. Upsert wird nicht unterstützt, wenn partitionierte Lakehouse-Tabellen verwendet werden.
- Schlüsselspalten: Wählen Sie aus, welche Spalte verwendet wird, um zu bestimmen, ob eine Zeile aus der Quelle einer Zeile vom Ziel entspricht. Eine Dropdownliste, die alle Zielspalten zeigt. Sie können eine oder mehrere Spalten auswählen, die beim Schreiben in lakehouse Table als Schlüsselspalten behandelt werden sollen.
Maximale Anzahl gleichzeitiger Verbindungen: Die Obergrenze der gleichzeitigen Verbindungen zum Datenspeicher, die während des Ausführens der Aktivität hergestellt werden. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten.
Wenn Sie Dateien auswählen:
Dateipfad: Wählen Sie Durchsuchen aus, um die Datei auszuwählen, die Sie kopieren möchten, oder geben Sie den Pfad manuell ein.

Dateiformat: Wählen Sie Ihr Dateiformat aus der Dropdownliste aus. Wählen Sie Einstellungen aus, um das Dateiformat zu konfigurieren. Detaillierte Informationen zu den Einstellungen der verschiedenen Dateiformate finden Sie in den Artikeln unter Unterstützte Formate.
Unter Erweitert können Sie die folgenden Felder angeben:
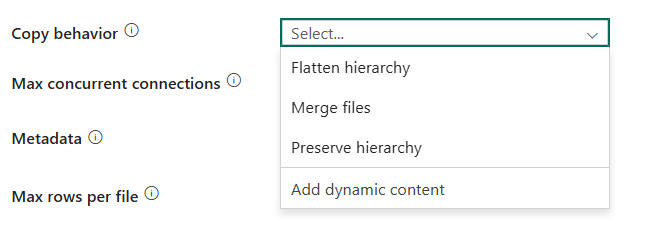
Kopierverhalten: Definiert das Kopierverhalten, wenn es sich bei der Quelle um Dateien aus einem dateibasierten Datenspeicher handelt. Als Kopierverhalten können Sie Hierarchie vereinfachen, Dateien zusammenführen, Hierarchie beibehalten oder Dynamischen Inhalt hinzufügen wählen. Die Konfiguration der einzelnen Einstellungen ist:
Hierarchie vereinfachen: Alle Dateien aus dem Quellordner befinden sich auf der ersten Ebene des Zielordners. Die Zieldateien haben automatisch generierte Namen.
MergeFiles: Alle Dateien aus dem Quellordner werden in einer Datei zusammengeführt. Wenn der Dateiname angegeben wurde, entspricht der zusammengeführte Dateiname dem angegebenen Namen. Ansonsten handelt es sich um einen automatisch generierten Dateinamen.
Hierarchie beibehalten: Behält die Dateihierarchie im Zielordner bei. Der relative Pfad einer Quelldatei zum Quellordner ist mit dem relativen Pfad einer Zieldatei zum Zielordner identisch.
Dynamischen Inhalt hinzufügen: Um einen Ausdruck für einen Eigenschaftswert anzugeben, wählen Sie Dynamischen Inhalt hinzufügen aus. Dieses Feld öffnet den Ausdrucks-Generator, in dem Sie Ausdrücke aus unterstützten Systemvariablen, Aktivitätsausgaben, Funktionen und benutzerdefinierten Variablen oder Parametern erstellen können. Weitere Informationen zur Ausdruckssprache finden Sie unter Ausdrücke und Funktionen.
Maximale Anzahl gleichzeitiger Verbindungen: Die Obergrenze der gleichzeitigen Verbindungen zum Datenspeicher, die während des Ausführens der Aktivität hergestellt werden. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten.
Blockgröße (MB): Geben Sie die Blockgröße in MB an, wenn Sie Daten für Lakehouse schreiben. Der zulässige Wert liegt zwischen 4 und 100 MB.
Metadaten: Legen Sie benutzerdefinierte Metadaten beim Kopieren in den Zieldatenspeicher fest. Jedes Objekt unter dem Array
metadatastellt eine zusätzliche Spalte dar.namedefiniert den Namen des Metadatenschlüssels, undvaluegibt den Datenwert dieses Schlüssels an. Wenn das Feature zum Beibehalten von Attributen verwendet wird, werden die angegebenen Metadaten mit den Metadaten der Quelldatei vereint/überschrieben. Die zulässigen Datenwerte sind:$$LASTMODIFIED: Eine reservierte Variable gibt an, dass der Zeitpunkt der letzten Änderung der Quelldateien gespeichert werden soll. Nur auf eine dateibasierte Quelle im Binärformat anwenden.Ausdruck
Statischer Wert




Zuordnung
Wenn Sie für die Konfiguration der Registerkarte Zuordnung keine Lakehouse-Tabelle als Zieldatenspeicher verwenden, wechseln Sie zu Zuordnung.
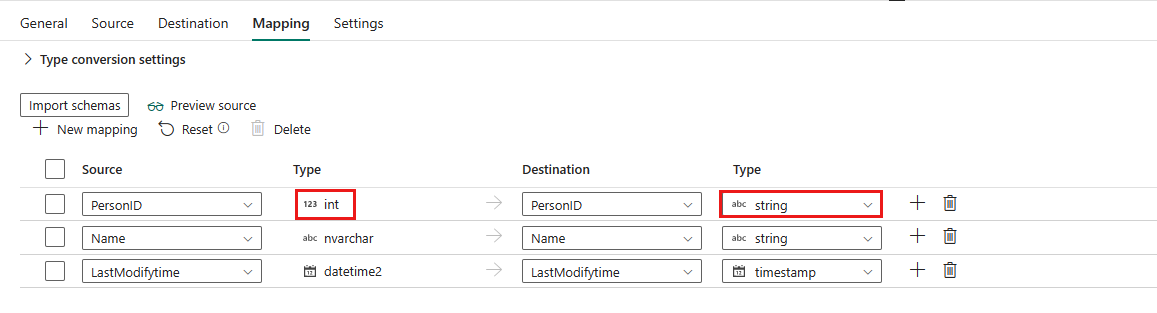
Wenn Sie eine Lakehouse-Tabelle als Zieldatenspeicher verwenden, können Sie mit Ausnahme der Konfiguration in Zuordnung den Typ für Ihre Zielspalten bearbeiten. Nach dem Auswählen von Importschemas können Sie den Spaltentyp in Ihrem Ziel angeben.
Der Typ für die Spalte PersonID in der Quelle ist z. B. „int“, und Sie können ihn beim Zuordnen zur Zielspalte in den Typ „string“ ändern.
Hinweis
Das Bearbeiten des Zieltyps wird derzeit nicht unterstützt, wenn die Quelle vom Typ „decimal“ ist.
Wenn Sie „Binär“ als Dateiformat auswählen, wird die Zuordnung nicht unterstützt.
Einstellungen
Wechseln Sie für die Konfiguration der Registerkarte Einstellungen zu Einstellungen.
Delta Lake Tabellenunterstützung
In den folgenden Abschnitten finden Sie detaillierte Informationen zur Unterstützung für Delta Lake-Tabellen sowohl für die Quelle als auch für das Ziel.
Quelle
Leser Version 1 wird unterstützt. Die entsprechenden unterstützten Delta Lake-Features finden Sie in diesem Artikel.
Die Delta-Spaltenzuordnung wird unterstützt, wenn Sie die Reader-Version 2 oder 3 in der Lakehouse-Tabelle mit columnMapping in readerFeatures anwenden.
Die Spaltenzuordnungsfunktion der Delta-Tabelle ermöglicht eine flexiblere Schemaentwicklung, wodurch sichergestellt wird, dass Änderungen in der Tabellenstruktur keine Datenworkflows stören. Mit der Spaltenzuordnung können Sie Daten aus einer vorhandenen Delta Lake-Tabelle lesen, bei der delta.columnMapping.mode auf name oder id gesetzt ist.
Vektoren zum Löschen werden unterstützt, wenn Sie die Reader-Version 3 mit deletionVectors in readerFeatures in Ihrer Lakehouse-Tabelle anwenden. Vorläufig gelöschte Zeilen werden in Vektordateien zum Löschen gekennzeichnet und beim Lesen der Delta Lake-Tabelle übersprungen.
Ziel
Writer Version 2 wird unterstützt. Die entsprechenden unterstützten Delta Lake-Features finden Sie in diesem Artikel.
Die Delta-Spaltenzuordnung wird unterstützt. Diese Funktion ermöglicht eine flexiblere Schemaentwicklung, um sicherzustellen, dass Änderungen in der Tabellenstruktur keine Datenworkflows stören. Mit der Spaltenzuordnung können Sie Folgendes ausführen:
- Schreiben von Daten in eine vorhandene Delta Lake-Tabelle, wobei
delta.columnMapping.modeaufnameoderidfestgelegt ist - Automatisches Erstellen einer Tabelle mit
delta.columnMapping.modefestgelegt aufname, wenn die Zieltabelle nicht vorhanden ist und die Quellspalten Sonderzeichen und Leerzeichen enthalten - Automatisches Erstellen einer Tabelle mit
delta.columnMapping.modefestgelegt aufname, wenn die Tabellenaktion „überschrieben“ lautet, und die Spalten im Quelldatensatz Sonderzeichen und Leerzeichen enthalten
Tabellenzusammenfassung
Die folgenden Tabellen enthalten weitere Informationen zu einer Kopieraktivität in Lakehouse.
Quellinformationen
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Verbindung | Der Abschnitt zur Auswahl Ihrer Verbindung. | < Ihre Lakehouse-Verbindung> | Ja | Arbeitsbereichs-ID artifactId |
| Stammordner | Der Typ des Stammordners. | • Tabellen • Dateien |
Nein | rootFolder: Tabelle oder Dateien |
| Tabellenname | Der Name der Tabelle, aus der Sie Daten lesen möchten. | <Ihr Tabellenname> | Ja, wenn Sie Tabellen im Root-Verzeichnis auswählen | Tabelle |
| Tabelle | Der Name der Tabelle mit einem Schema, von dem Sie Daten lesen möchten, wenn Sie Lakehouse mit Schemata als Verbindung verwenden. | <Ihre Tabelle mit einem Schema> | Ja, wenn Sie Tabellen im Root-Verzeichnis auswählen | / |
| Für Tabelle | ||||
| Schemaname | Der Name des Schemas. |
< Ihr Schemaname > (Der Standardwert ist dbo.) |
Nein |
(unter source ->datasetSettings ->typeProperties)Schema |
| Tabellenname | Der Name der Tabelle. | <Ihr Tabellenname> | Ja | Tabelle |
| Zeitstempel | Der Zeitstempel zum Abfragen einer älteren Momentaufnahme. | <Zeitstempel> | Nein | timestampAsOf |
| Version | Die Version zum Abfragen einer älteren Momentaufnahme. | <Version> | Nein | versionAsOf |
| Zusätzliche Spalten | Zusätzliche Datenspalten, um den relativen Pfad oder statischen Wert der Quelldateien zu speichern. Für Letzteres wird ein Ausdruck unterstützt. | • Name • Wert |
Nein | zusätzlicheSpalten: • Name • Wert |
| Dateipfadtyp | Der Typ des Dateipfads, den Sie verwenden. | • Dateipfad • Platzhalterdateipfad • Dateiliste |
Ja, wenn Sie Dateien in Stammordner auswählen | / |
| Dateipfad | Kopieren Sie aus dem Pfad in einen Ordner/Datei unter Quelldatenspeicher. | <Dateipfad> | Ja, wenn Sie Dateipfad auswählen | • folderPath • Dateiname |
| Platzhalterpfade | Der Ordnerpfad mit Platzhalterzeichen unter dem Quelldatenspeicher, der zum Filtern von Quellordnern konfiguriert wurde. | <Platzhalterpfade> | Ja, wenn Sie Platzhalterdateipfad auswählen | • wildcardFolderPath • PlatzhalterDateiname |
| Ordnerpfad | Zeigt auf einen Ordner, der Dateien enthält, die Sie kopieren möchten. | <Ordnerpfad> | Nein | folderPath |
| Pfad zur Dateiliste | Gibt an, dass eine bestimmte Dateigruppe kopiert werden soll. Verweisen Sie auf eine Textdatei, die eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile. Dies ist der relative Pfad zu dem konfigurierten Pfad. | <Pfad zur Dateiliste> | Nein | Dateilistepfad |
| Rekursiv | Verarbeiten Sie alle Dateien im Eingabeordner und seinen Unterordnern rekursiv oder nur die Dateien im ausgewählten Ordner. Diese Einstellung ist deaktiviert, wenn eine einzelne Datei ausgewählt ist. | Auswählen oder abwählen | Nein | Rekursiv: wahr oder falsch |
| Dateiformat | Das Dateiformat der Quelldaten. Detaillierte Informationen zu den verschiedenen Dateiformate finden Sie in den Artikeln unter Unterstützte Formate. | / | Ja, wenn Sie Dateien in Stammordner auswählen | / |
| Nach der letzten Änderung filtern | Die Dateien mit dem Zeitpunkt der letzten Änderung im Bereich [Startzeit, Endzeit] werden für die weitere Verarbeitung gefiltert. Die Zeitangabe wird auf die UTC-Zeitzone im Format yyyy-mm-ddThh:mm:ss.fffZ angewendet.Diese Eigenschaft kann übersprungen werden, was bedeutet, dass kein Dateiattributfilter angewendet wird. Diese Eigenschaft gilt nicht, wenn Sie Ihren Dateipfadtyp als Liste der Dateien konfigurieren. |
• Startzeit • Endzeit |
Nein | GeändertDatumZeitStart modifiedDatetimeEnde |
| Partitionsermittlung aktivieren | Gibt an, ob die Partitionen aus dem Dateipfad analysiert und als zusätzliche Quellspalten hinzugefügt werden sollen. | Ausgewählt oder nicht ausgewählt | Nein | enablePartitionDiscovery: Partitionserkennung aktivieren TRUE oder FALSE (Standardwert) |
| Partitionsstammpfad | Der absolute Stammpfad der Partition zum Lesen von partitionierten Ordnern als Datenspalten. | <Ihr Partitionsstammpfad> | Nein | partitionRootPfad |
| Maximal zulässige Anzahl paralleler Verbindungen | Die Obergrenze der gleichzeitig hergestellten Verbindungen zum Datenspeicher während der Aktivitätsausführung. Ein Wert wird nur benötigt, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | <Maximal zulässige Anzahl paralleler Verbindungen> | Nein | maximale gleichzeitige Verbindungen |
Zielinformationen
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Verbindung | Der Abschnitt zur Auswahl Ihrer Verbindung. | < Ihre Lakehouse-Verbindung> | Ja | Arbeitsbereichs-ID artifactId |
| Stammordner | Der Typ des Stammordners. | • Tabellen • Dateien |
Ja | rootFolder: Tabelle oder Dateien |
| Tabellenname | Der Name der Tabelle, in die Sie Daten schreiben möchten. | <Ihr Tabellenname> | Ja, wenn Sie Tabellen im Root-Verzeichnis auswählen | Tabelle |
| Tabelle | Der Name der Tabelle mit einem Schema, in das Sie Daten schreiben möchten, wenn Sie Lakehouse mit Schemas als Verbindung anwenden. | <Ihre Tabelle mit einem Schema> | Ja, wenn Sie Tabellen im Root-Verzeichnis auswählen | / |
| Für Tabelle | ||||
| Schemaname | Der Name des Schemas. |
< Ihr Schemaname > (Der Standardwert ist dbo.) |
Nein |
(unter sink ->datasetSettings ->typeProperties)Schema |
| Tabellenname | Der Name der Tabelle. | <Ihr Tabellenname> | Ja | Tabelle |
| Tabellenaktion | Fügen Sie neue Werte an eine vorhandene Tabelle an, überschreiben Sie die vorhandenen Daten und das Schema in der Tabelle mithilfe der neuen Werte, oder fügen Sie neue Werte in vorhandene Tabellen ein, und aktualisieren Sie vorhandene Werte. | • Anfügen • Überschreiben • Upsert |
Nein | tableActionOption: •Anfügen • SchemaÜberschreiben • Upsert (Aktualisieren oder Einfügen) |
| Partitionen aktivieren | Mit dieser Auswahl können Sie Partitionen in einer Ordnerstruktur basierend auf einer oder mehreren Spalten erstellen. Jeder eindeutige Spaltenwert (Paar) ist eine neue Partition. Beispiel: „year=2000/month=01/file“. | Ausgewählt oder nicht ausgewählt | Nein | Partitionierungsoption: PartitionByKey oder None |
| Partitionsspalten | Die Zielspalten in der Schemazuordnung | <Ihre Partitionsspalten> | Nein | PartitionNamensListe |
| Schlüsselspalten | Wählen Sie aus, welche Spalte verwendet wird, um zu bestimmen, ob eine Zeile aus der Quelle mit einer Zeile vom Ziel übereinstimmt. | <Ihre Schlüsselspalten> | Ja | Schlüsselspalten |
| Dateipfad | Schreiben Sie Daten in den Pfad zu einem Ordner/einer Datei unter Zieldatenspeicher. | <Dateipfad> | Nein | • folderPath • Dateiname |
| Dateiformat | Das Dateiformat für Ihre Zieldaten. Detaillierte Informationen zu den verschiedenen Dateiformate finden Sie in den Artikeln unter Unterstützte Formate. | / | Ja, wenn Sie Dateien in Stammordner auswählen | / |
| Kopierverhalten | Das Kopierverhalten, das definiert ist, wenn die Quelle Dateien aus einem dateibasierten Datenspeicher enthält. | • Hierarchie vereinfachen • Zusammenführen von Dateien • Hierarchie beibehalten • Dynamischen Inhalt hinzufügen |
Nein | Kopierverhalten: • FlattenHierarchy • MergeFiles • Hierarchie beibehalten |
| Maximal zulässige Anzahl paralleler Verbindungen | Die Obergrenze der gleichzeitig hergestellten Verbindungen zum Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | <Maximal zulässige Anzahl paralleler Verbindungen> | Nein | maximale gleichzeitige Verbindungen |
| Blockgröße (MB) | Die Blockgröße in MB, die zum Schreiben von Daten in Lakehouse verwendet wird. Der zulässige Wert liegt zwischen 4 und 100 MB. | <Blockgröße> | Nein | BlockgrößeInMB |
| Metadaten | Die benutzerdefinierten Metadaten, die beim Kopieren an ein Ziel festgelegt werden | • $$LASTMODIFIED• Ausdruck • Statischer Wert |
Nein | Metadaten |