Tutorial Teil 2: Untersuchen und Visualisieren von Daten mithilfe von Microsoft Fabric-Notebooks
In diesem Tutorial erfahren Sie, wie Sie explorative Datenanalysen (EDA) durchführen, um die Daten zu erforschen und zu untersuchen, während Sie ihre wichtigsten Merkmale mithilfe von Datenvisualisierungstechniken zusammenfassen.
Sie werden die Python-Datenvisualisierungsbibliothek seaborn verwenden, die eine allgemeine Schnittstelle zum Erstellen von Visuals für Dataframes und Arrays bietet. Weitere Informationen zu seaborn finden Sie im Artikel zur Visualisierung statistischer Daten mit Seaborn.
Sie verwenden auch Data Wrangler, ein Notebook-basiertes Tool, das Ihnen eine immersive Erfahrung bietet, um explorative Datenanalyse und Reinigung durchzuführen.
Die wichtigsten Schritte in diesem Tutorial sind:
- Lesen von Daten, die in einer Deltatabelle im Lakehouse gespeichert sind.
- Konvertieren eines Spark-Dataframes in einen Pandas-Dataframe, den Python-Visualisierungsbibliotheken unterstützen.
- Verwenden von Data Wrangler, um die anfängliche Datenreinigung und -transformation durchzuführen.
- Durchführen einer explorativen Datenanalyse mithilfe von
seaborn.
Voraussetzungen
Erwerben Sie ein Microsoft Fabric-Abonnement. Registrieren Sie sich alternativ für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabric an.
Wechseln Sie zur Synapse-Data Science-Benutzeroberfläche, indem Sie den Umschalter für die Benutzeroberfläche auf der linken Seite Ihrer Homepage verwenden.

Dies ist Teil 2 von 5 in der Reihe von Tutorials. Um dieses Tutorial erfolgreich abzuschließen, führen Sie zunächst Folgendes durch:
Notebook für das Tutorial
2-explore-cleanse-data.ipynb ist das Notebook, das dieses Tutorial begleitet.
Um das zugehörige Notebook für dieses Tutorial zu öffnen, befolgen Sie die Anweisungen unter Vorbereiten Ihres Systems für Data-Science-Tutorials zum Importieren des Notebooks in Ihren Arbeitsbereich.
Wenn Sie den Code lieber von dieser Seite kopieren und einfügen möchten, können Sie auch ein neues Notebook erstellen.
Fügen Sie unbedingt ein Lakehouse an das Notebook an, bevor Sie mit der Ausführung von Code beginnen.
Wichtig
Fügen Sie dasselbe Lakehouse an, das Sie in Teil 1 verwendet haben.
Lesen von Rohdaten aus dem Lakehouse
Dieser Code liest Rohdaten aus dem Datei-Abschnitt des Lakehouses. Sie haben diese Daten im vorherigen Notebook hochgeladen. Stellen Sie sicher, dass Sie dasselbe Lakehouse, das Sie in Teil 1 verwendet haben, an dieses Notebook angefügt haben, bevor Sie diesen Code ausführen.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Erstellen eines Pandas-DataFrames aus dem Datenset
Konvertieren Sie den Spark-DataFrame in einen Pandas-DataFrame, um die Verarbeitung und Visualisierung zu vereinfachen.
df = df.toPandas()
Anzeigen der Rohdaten
Untersuchen Sie die Rohdaten mit display, stellen Sie einige grundlegende Statistiken auf und zeigen Sie Diagrammansichten an. Beachten Sie, dass Sie zuerst die erforderlichen Bibliotheken wie Numpy, Pnadas, Seaborn und Matplotlib für Datenanalyse und Visualisierung importieren müssen.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Verwenden von Data Wrangler zum Durchführen der anfänglichen Datenbereinigung
Starten Sie Data Wrangler direkt über das Notebook, um Pandas-DataFrames zu untersuchen und zu transformieren.
Hinweis
Data Wrangler kann nicht geöffnet werden, während der Notebookkernel ausgelastet ist. Die Zellausführung muss vor dem Starten von Data Wrangler abgeschlossen werden.
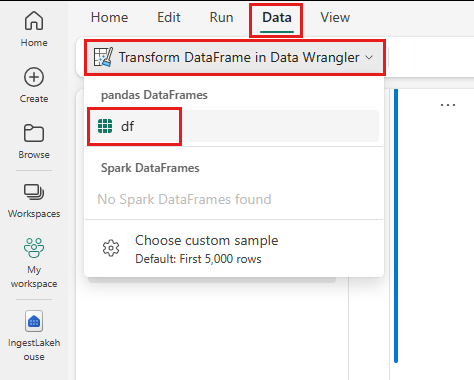
- Wählen Sie auf der Notebook-Registerkarte Daten die Option Daten-Wrangler starten aus. Es wird eine Liste der aktivierten Pandas DataFrames angezeigt, die zur Bearbeitung verfügbar sind.
- Wählen Sie den DataFrame aus, den Sie in Data Wrangler öffnen möchten. Da dieses Notebook nur einen DataFrame enthält, nämlich
df, wählen Siedfaus.
Data Wrangler startet und generiert einen beschreibenden Überblick über Ihre Daten. Die Tabelle in der Mitte zeigt jede Datenspalte an. Im Zusammenfassungsbereich neben der Tabelle werden Informationen zum DataFrame angezeigt. Wenn Sie eine Spalte in der Tabelle auswählen, wird die Zusammenfassung mit Informationen zur ausgewählten Spalte aktualisiert. In einigen Fällen sind die angezeigten und zusammengefassten Daten eine abgeschnittene Ansicht Ihres DataFrames. In diesem Fall wird im Zusammenfassungsbereich das Warnbild angezeigt. Zeigen Sie mit der Maus auf diese Warnung, um einen Text anzuzeigen, der die Situation erklärt.

Jeder Vorgang kann mit wenigen Klicks angewendet werden, indem die Datenanzeige in Echtzeit aktualisiert und Code generiert wird. Dieser kann als wiederverwendbare Funktion im Notebook gespeichert werden.
Der Rest dieses Abschnitts führt Sie durch die Schritte zum Durchführen der Datenreinigung mit Data Wrangler.
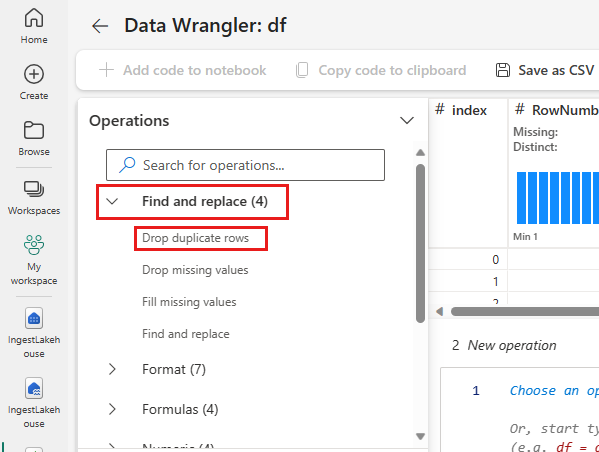
Doppelte Zeilen löschen
Im linken Bereich befindet sich eine Liste der Vorgänge (z. B. Suchen und Ersetzen, Format, Formeln, Numerisch), die Sie auf das Dataset anwenden können.
Erweitern Sie Suchen und Ersetzen und wählen Sie Doppelte Zeilen entfernen aus.
Es wird ein Bereich angezeigt, in dem Sie die Liste der Spalten auswählen möchten, die Sie vergleichen möchten, um eine doppelte Zeile zu definieren. Wählen Sie RowNumber und CustomerId aus.
Im mittleren Bereich befindet sich eine Vorschau der Ergebnisse dieses Vorgangs. Unter der Vorschau befindet sich der Code zum Ausführen des Vorgangs. In diesem Fall scheinen die Daten unverändert zu sein. Da Sie jedoch eine abgeschnittene Ansicht betrachten, ist es ratsam, den Vorgang trotzdem anzuwenden.
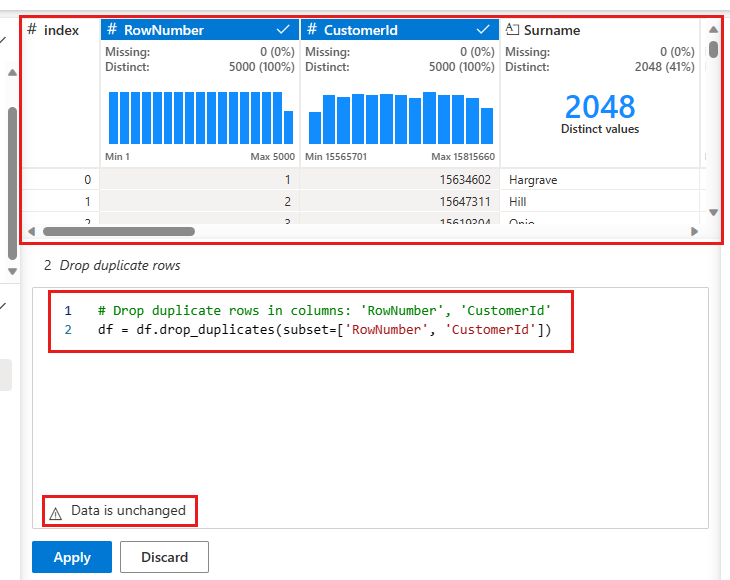
Wählen Sie Übernehmen (entweder an der Seite oder unten) aus, um zum nächsten Schritt zu wechseln.

Zeilen mit fehlenden Daten entfernen
Verwenden Sie Data Wrangler, um Zeilen mit fehlenden Daten in allen Spalten zu entfernen.
Wählen Sie Fehlende Werte löschen aus Suchen und Ersetzen aus.
Wählen Sie Alle auswählen aus den Zielspalten aus.
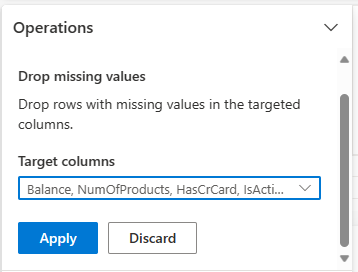
Wählen Sie Übernehmen aus, um zum nächsten Schritt zu gehen.

Löschen von Spalten
Verwenden Sie Data Wrangler zum Ablegen von Spalten, die Sie nicht benötigen.
Erweitern Sie das Schema und wählen Sie Spalten entfernen aus.
Wählen Sie RowNumber, CustomerId, Surname aus. Diese Spalten werden in der Vorschau rot angezeigt, um anzuzeigen, dass sie vom Code geändert wurden (in diesem Fall gelöscht.)
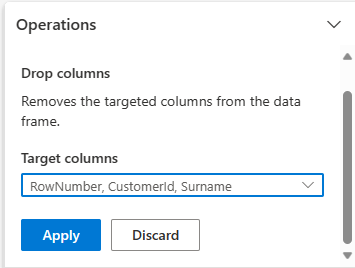
Wählen Sie Übernehmen aus, um zum nächsten Schritt zu gehen.

Hinzufügen von Code zum Notebook
Jedes Mal, wenn Sie Übernehmen auswählen, wird im Bereich Reinigungsschritte unten links ein neuer Schritt erstellt. Wählen Sie unten im Bereich den Vorschaucode für alle Schritte aus, um eine Kombination aller separaten Schritte anzuzeigen.
Wählen Sie oben links Code zum Notebook hinzufügen aus, um Data Wrangler zu schließen und den Code automatisch hinzuzufügen. Code zum Notizbuchs hinzufügen umschließt den Code in einer Funktion und ruft dann die Funktion auf.
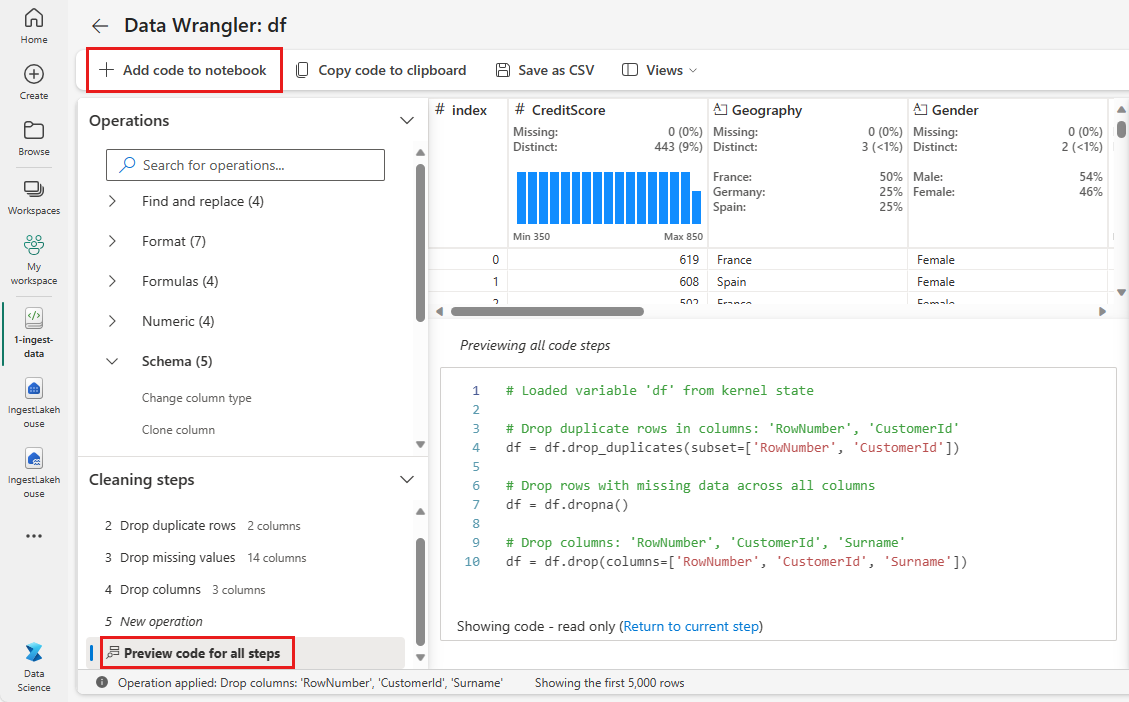
Tipp
Der von Data Wrangler generierte Code wird erst angewendet, wenn Sie die neue Zelle manuell ausführen.
Wenn Sie Data Wrangler nicht verwendet haben, können Sie stattdessen diese nächste Codezelle verwenden.
Dieser Code ähnelt dem Code, der von Data Wrangler erstellt wird, fügt jedoch jedem der generierten Schritte das Argument inplace=True hinzu. Durch festlegen von inplace=True, überschreibt Pandas das ursprüngliche DataFrame, anstatt einen neuen DataFrame als Ausgabe zu erzeugen.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Untersuchen der Daten
Zeigen Sie einige Zusammenfassungen und Visualisierungen der bereinigten Daten an.
Bestimmen von kategorisierten, numerischen und Zielattributen
Verwenden Sie diesen Code, um kategorisierte, numerische und Zielattribute zu ermitteln.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
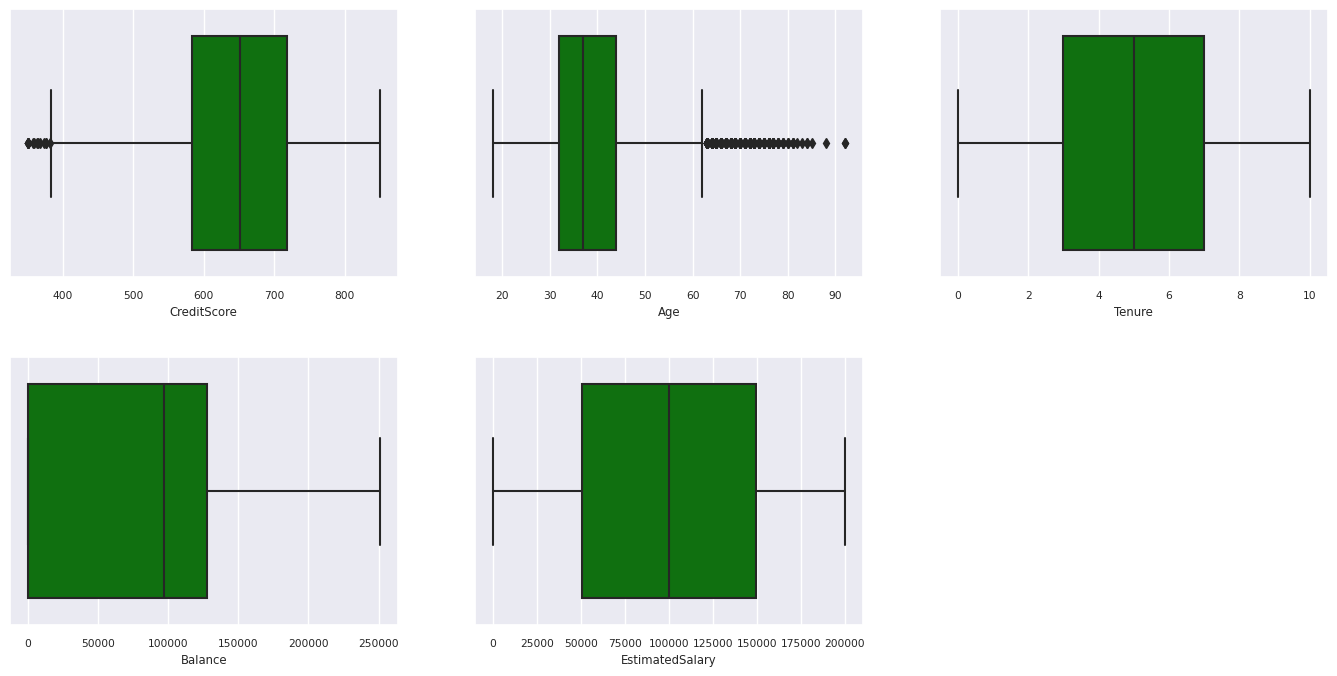
Die fünfzahlige Zusammenfassung
Zeigen Sie die fünfzahlige Zusammenfassung (die Mindestbewertung, erstes Quartil, Median, drittes Quartil, die maximale Punktzahl) für die numerischen Attribute mithilfe von Boxplots an.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
Verteilung ausgeschiedener und nicht ausgeschiedener Kunden
Zeigen Sie die Verteilung ausgeschiedener und nicht ausgeschiedener Kunden über die kategorisierten Attribute hinweg an.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Verteilung numerischer Attribute
Zeigen Sie die Häufigkeitsverteilung numerischer Attribute mithilfe des Histogramms an.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Durchführen des Feature Engineerings
Führen Sie Featurekonstruktion aus, um neue Attribute basierend auf aktuellen Attributen zu generieren:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Verwenden von Data Wrangler zum Ausführen einer einseitigen Codierung
Daten-Wrangler können auch verwendet werden, um eine einseitige Codierung durchzuführen. Öffnen Sie dazu Data Wrangler erneut. Wählen Sie diesmal die df_clean-Daten aus.
- Erweitern Sie Formeln, und wählen Sie One-Hot-Encode aus.
- Es wird ein Bereich angezeigt, in dem Sie die Liste der Spalten auswählen möchten, für die Sie eine Codierung ausführen möchten. Wählen Sie Geografie und Geschlecht aus.
Sie könnten den generierten Code kopieren, Data Wrangler schließen, um zum Notebook zurückzukehren, und ihn dann in eine neue Zelle einfügen. Oder wählen Sie oben links Code zum Notebook hinzufügen aus, um Data Wrangler zu schließen und den Code automatisch hinzuzufügen.
Wenn Sie Data Wrangler nicht verwendet haben, können Sie stattdessen diese nächste Codezelle verwenden:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Zusammenfassung der Beobachtungen aus der explorativen Datenanalyse
- Die meisten Kunden stammen aus Frankreich im Vergleich zu Spanien und Deutschland, während Spanien gegenüber Frankreich und Deutschland die niedrigste Abwanderungsrate aufweist.
- Die meisten Kunden haben Kreditkarten.
- Es gibt Kunden, deren Alter bzw. deren Kreditwürdigkeit über 60 bzw. unter 400 liegen, aber sie können nicht als Ausreißer betrachtet werden.
- Sehr wenige Kunden verfügen über mehr als zwei Produkte der Bank.
- Kunden, die nicht aktiv sind, haben eine höhere Abwanderungsrate.
- Geschlecht und Dauer wirken sich nicht auf die Entscheidung des Kunden aus, das Bankkonto zu schließen.
Erstellen einer Delta-Tabelle für die bereinigten Daten
Sie werden diese Daten im nächsten Notizbuch dieser Reihe verwenden.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Nächster Schritt
Trainieren und Registrieren von Machine Learning-Modellen mit diesen Daten:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für