Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Microsoft Fabric bietet Tools für erweiterte Analysen, maschinelles Lernen (ML) und KI-Modell-Operationalisierung, alles innerhalb einer einzigen einheitlichen Plattform. Die Data Science-Workload wurde für Datenwissenschaftler und Analysten entwickelt, um Daten zu untersuchen, vorzubereiten und zu analysieren, ML-Modelle zu erstellen und nachzuverfolgen und KI-Workflows zu operationalisieren. Fabric IQ Data Agents, Operations Agents und Copilot in Power BI verbessern die Interaktion mit Daten durch natürliche Sprache, Automatisierung und einblickegesteuerte Aktionen.
In diesem Artikel erfahren Sie mehr über die folgenden Themen:
- KI-Agents für konversationelle Analytik und operationelle Automatisierung
- Data Science-Workflows für Modellschulungen, Tracking und Bereitstellung
- Entwickler- und Benutzerzugriffsoptionen mit GraphQL und Copilot
KI-Agenten
KI-Agents in Microsoft Fabric helfen Teams beim Wechsel von passiver Berichterstellung zu aktiver Entscheidungsunterstützung. Daten-Agents erleichtern das Untersuchen von geregelten Daten durch Fragen in natürlicher Sprache, während Operations Agents Geschäftsbedingungen überwachen und Aktionen auslösen, wenn Regeln erfüllt sind. Gemeinsam verbinden sie Einblicke und Automatisierung, damit Teams schneller reagieren, manuelle Anstrengungen reduzieren und Entscheidungen mit mehr Kontext treffen können.
Daten-Agent
Fabric Data Agents ermöglichen Unterhaltungs-Q&A über Unternehmensdaten mithilfe von generativer KI. Benutzer können einfache englische Fragen stellen und strukturierte, sichere, schreibgeschützte Antworten erhalten, ohne SQL, DAX oder KQL zu benötigen. Daten-Agents verwenden Azure OpenAI-Assistenten-APIs, um relevante OneLake-Datenquellen zu identifizieren, einschließlich Lakehouses, Warehouses, Power BI-Semantikmodelle, KQL-Datenbanken und Ontologien. Sie können Agents mit benutzerdefinierten Anweisungen, Beispielen und domänenspezifischen Anleitungen konfigurieren, um die Antwortrelevanz zu verbessern.
Daten-Agents integrieren sich mit Microsoft Foundry, Copilot Studio und Microsoft 365 Copilot, um die Möglichkeiten von Konversationsanalysen bis hin zu KI-Workflows zu erweitern.
Foundry IQ bietet eine freigegebene Kontextebene, in der Daten-Agents strukturierte Geschäftseinblicke zusammen mit anderen Agents beitragen, wodurch mehrstufiges Denken und Orchestrierung über Unternehmenssysteme hinweg ermöglicht wird.
Mit Copilot Studio können Sie diese Agents als benutzerdefinierte Fähigkeiten in Teams, Web-Apps oder Branchenanwendungen einbetten, den Live-Geschäftskontext in Copilot-Eingabeaufforderungen einfügen und Q&A mit Workflowautomatisierung kombinieren.
Die Integration mit Microsoft 365 Copilot ermöglicht es diesen Agenten, gesteuerte, ontologiegetriebene Einblicke direkt innerhalb von Produktivitätstools wie Outlook, Excel und Teams sichtbar zu machen und Unterhaltungsanalysen mit Workflowautomatisierung zu kombinieren.
Betriebsagent
Operations Agents sind autonome, ontologiegesteuerte KI-Komponenten, die Echtzeitdatenströme überwachen, Ereignisse interpretieren und Aktionen ausführen oder empfehlen. Sie verwenden die Ontologie, um Regeln und Ziele anzuwenden und proaktive Entscheidungen zu ermöglichen und nicht reaktive Reaktionen. Sie integrieren sich mit Aktivator und Power Automate, um Workflows in ERP-, CRM- und anderen Systemen auszulösen, während Teams für Benachrichtigungen und menschliche Genehmigungen sorgt. Im Gegensatz zu Daten-Agents, die sich auf die Beantwortung von Fragen konzentrieren, reagieren Operations Agents kontinuierlich auf Livebedingungen, lernen von Ergebnissen, um zukünftige Entscheidungen zu verbessern und Vorgänge in adaptive, kontextabhängige Automatisierung umzuwandeln.
Das folgende Diagramm zeigt, wie Daten-Agents und Operations-Agents in Fabric IQ verwaltete Unternehmensdaten und Automatisierungsdienste nutzen, um Einblicke zu gewinnen und Aktionen auszulösen.
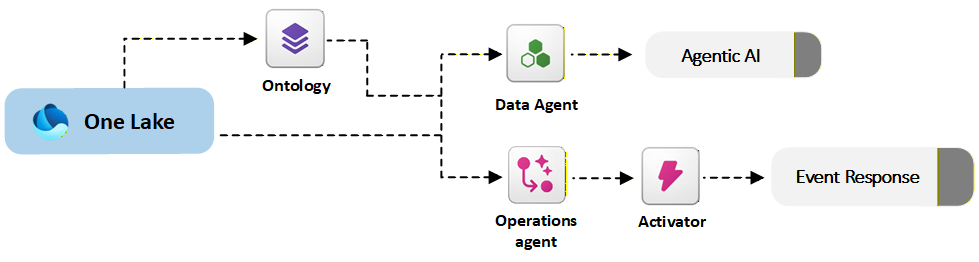
Auswählen zwischen Daten-Agents und Operations-Agents
Daten-Agents und Operations Agents in Microsoft Fabric IQ dienen unterschiedlichen Rollen. Daten-Agents bieten konversationelle Analysen, indem sie Benutzerfragen in natürlicher Sprache beantworten und die Ontologie zur semantischen Verankerung verwenden. Dabei werden mehrere Quellen wie Lakehouses, Warehouses und Power BI-Modelle abgefragt. Sie werden extern über Teams, Copilot Studio und benutzerdefinierte Apps für die Bereitstellung von Einblicken integriert.
Im Gegensatz dazu konzentrieren sich Operations Agents auf autonome Entscheidungsfindung. Sie überwachen Echtzeitdatenströme anhand von ontologiebasierten Regeln, um Aktionen auszulösen oder zu empfehlen. Sie integrieren sich in Power Automate (über Aktivator), Teams für Warnungen und Genehmigungen sowie externe Betriebssysteme wie ERP oder CRM. Daten-Agents demokratisieren den Datenzugriff für Erkenntnisse, während Operations Agents proaktive, bedingte Automatisierung für die Betriebsoptimierung fördern.
Datenwissenschaft-Workflows
Fabric Data Science deckt den gesamten ML-Lebenszyklus ab: Datenerkundung, Vorbereitung, Modellexperimente, Tracking, Bereitstellung und Verbrauch. Tools, die Sie benötigen, sind Notizbücher, Apache Spark, MLflow und AutoML, alles innerhalb einer einheitlichen Plattform. Data Scientists können ML-Modelle zusammen mit Dateningenieuren und Analysten an einem zentralen Ort entwickeln und operationalisieren.
Nachverfolgen von Experimenten mit MLflow
Experimente in Microsoft Fabric organisieren und verfolgen Modelltrainingsläufe. Ein Experiment in Fabric funktioniert wie ein MLflow-Experiment, es enthält eine Sammlung von Läufen, wobei jede Ausführung eine Ausführung von Modellschulungscode ist. Da Fabric in MLflow integriert ist, kann jede Ausführung relevante Informationen wie Hyperparameter, Metriken, Tags, Codeversion und Ausgabeelemente automatisch protokollieren , ohne dass benutzerdefinierter Protokollierungscode erforderlich ist. Die MLflow-Nachverfolgung ist nativ in Fabric-Notizbücher und Spark-Aufträge integriert, sodass Data Scientists MLflow-APIs oder die Benutzeroberfläche von Fabric verwenden können, um Experimente zu erstellen und Läufe aufzuzeichnen.
Registrieren und Bereitstellen von ML-Modellen
ML-Modelle in Fabric sind registrierte Machine Learning-Modelle. Die Modellverwaltung von Fabric verwendet MLflow-basierte Registrierungen zum Speichern, Version und Nachverfolgen von Modellen. Nachdem Sie den besten Experimentlauf ausgewählt haben, registrieren Sie das Modell in Fabric, um Metadaten wie Hyperparameter, Metriken und Umgebungsdetails zu speichern. Modelle werden in einem standardisierten MLflow-Format gespeichert, das die Interoperabilität in Spark- und Python-Umgebungen ermöglicht.
Modelle können für die Batchbewertung in Spark oder über Echtzeitendpunkte für Vorhersagen mit geringer Latenz bereitgestellt werden.
Das folgende Diagramm zeigt den End-to-End Data Science-Workflow in Fabric, von der Datenvorbereitung und -experimentierung bis hin zur Modellregistrierung und -bereitstellung.
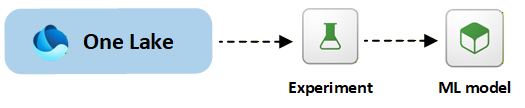
Entwicklerdatenzugriff mit GraphQL
Die API für GraphQL bietet einen einzelnen, flexiblen Endpunkt zum Abfragen mehrerer Fabric-Datenquellen, einschließlich Warehouses, SQL-Datenbanken, Lakehouses und gespiegelten Datenbanken. Es unterstützt Schemaermittlung, generierte Abfragen, Beziehungsmodellierung und interaktive Abfragetests. Es erleichtert das Verfügbarmachen bestimmter Tabellen, Ansichten und Felder, während der schnelle, clientgesteuerte Datenzugriff in Fabric-Umgebungen ermöglicht wird.
Copilot in Power BI
Copilot in Power BI ermöglicht die Interaktion von Daten in natürlicher Sprache. Benutzer können Daten untersuchen, Einblicke generieren, visuelle Elemente erstellen und DAX-Ausdrücke generieren.
Die eigenständige Copilot-Erfahrung unterstützt die elementübergreifende Konversationsanalyse, wobei automatisch eine relevante Datenquelle, wie ein Bericht, ein semantisches Modell oder ein Fabric-Datenagent, ausgewählt wird, auf die Benutzer zugreifen können. Er stellt bei Bedarf Klarstellungsfragen und kann sofort Einblicke liefern, sobald er den richtigen Bericht oder Modell auswählt. Das Vorbereiten von Daten für KI und die Genehmigung semantischer Modelle verbessert die Genauigkeit und stellt qualitativ hochwertige Antworten sicher.