Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Microsoft Fabric bietet mehrere Möglichkeiten, Daten in Ihre Analyseumgebung zu integrieren. Unabhängig davon, ob Sie Streamingereignisse in Echtzeit verarbeiten, operative Datenbanken replizieren, Batchpipelines koordinieren oder auf Daten zugreifen müssen, ohne sie zu kopieren, bietet Fabric integrierte Funktionen, um jedes Szenario zu unterstützen.
In diesem Artikel werden die primären Datenaufnahme- und Datenverschiebungsoptionen in Fabric beschrieben. Es umfasst:
- Echtzeitdatenaufnahme mit Eventstreams und Eventhouse
- Batch-Orchestrierung mit Data Factory-Pipelines und Kopiervorgang
- Nahezu echtzeitbasierte Replikation mit Spiegelung
- Datenvirtualisierung mit OneLake-Verknüpfungen
Verwenden Sie diese Übersicht, um zu verstehen, wie jeder Ansatz funktioniert, und wählen Sie die Strategie aus, die Ihren Workloadanforderungen für Latenz, Transformation und betriebstechnische Komplexität am besten entspricht.
Dateneinbindung in Echtzeit
Eventstreams und Eventhouse-Elemente im Real-Time Intelligence-Workload unterstützen Streamingdatenszenarien. Eventstreams nehmen Echtzeitereignisse auf und verarbeiten sie, und Eventhouses speichern und fragen diese Ereignisse im großen Maßstab ab. In der Regel verwenden Sie einen Eventstream, um Daten an ein Eventhouse zu erfassen und weiterzuleiten. Sie können jede Funktion auch unabhängig nach Ihren Anforderungen verwenden. Das folgende Diagramm zeigt, wie Echtzeit-Datasets zu Eventstream und Eventhouse in Fabric fließen:
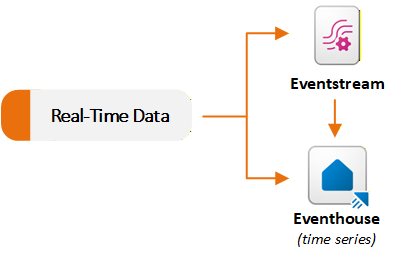
Mit Eventstream Ereignisse erfassen und weiterleiten
Eventstream bietet eine No-Code-Erfahrung zum Aufnehmen von Ereignissen in Fabric, Anwenden von In-Stream-Transformationen und Weiterleiten von Daten an mehrere Ziele. Ein Eventstream fungiert als Echtzeit-Aufnahmepipeline. Sie erstellen einen Eventstream und fügen einen oder mehrere Quellconnectors hinzu. Fabric unterstützt viele Streamingquellen, einschließlich interner Fabric-Ereignisse wie Fabric-Arbeitsbereichsereignisse, OneLake-Dateiereignisse und Pipelineauftragsereignisse.
Nachdem Ereignisse zu fließen beginnen, können Sie optionale Echtzeittransformationen über einen Drag-and-Drop-Editor anwenden. Sie können z. B. Ereignisse filtern, Zeitfensteraggregate berechnen, mehrere Datenströme verbinden oder Felder neu gestalten, ohne Code zu schreiben.
Sie können den verarbeiteten Datenstrom an ein oder mehrere unterstützte Ziele senden. Eventstreams können Apache Kafka-Endpunkte über benutzerdefinierte Endpunktquellen und Ziele verfügbar machen. Mit dieser Funktion können Kafka-Produzenten Ereignisse in Fabric- und Kafka-Consumer streamen, um Ereignisse von Fabric zu nutzen.
Eventstreams speichern keine Daten dauerhaft. Sie streamen Ereignisse über den Speicher und leiten sie an konfigurierte Ziele weiter. Dieses Design macht Eventstreams geeignet für Echtzeitextraktions-, Transformations-, Load-(ETL)-Szenarien und für die Verteilung von Streamingdaten an mehrere Ziele. Sie können z. B. Telemetrie von IoT-Sensoren (Internet of Things) erfassen, Daten in Echtzeit filtern und aggregieren, den optimierten Datenstrom für Analysen an ein Eventhouse senden und Anomalieereignisse zur Aktivierung an den Aktivierer weiterleiten.
Daten direkt in Eventhouse aufnehmen
Eventhouses können Daten direkt aus mehreren Quellen aufnehmen. Fabric enthält eine integrierte Daten abrufen Funktion in Eventhouse. Der Assistent stellt eine Verbindung mit Quellen wie lokalen Dateien, Azure Storage, Amazon S3, Azure Event Hubs und OneLake bereit. Mithilfe der Eventhouse-Benutzeroberfläche können Sie Daten in eine KQL-Datenbanktabelle (Kusto Query Language) in Echtzeit oder im Batchmodus laden.
Sie können auch einen vorhandenen Eventstream in Fabric als Quelle auswählen. Wenn Sie beispielsweise einen Eventstream verwenden, der Daten aus IoT Hub oder Kafka erfasst, können Sie die Ausgabe direkt an eine KQL-Datenbanktabelle ohne zusätzliche Konfiguration weiterleiten.
Batchdatenaufnahme
Data Factory bietet die primäre Erfahrung für herkömmliche Extrakt-, Transformations-, Last-, Transformations-(ELT)-Pipelines. Sie enthält eine große Konnektorbibliothek. Fabric Data Factory bietet eine Liste systemeigener Connectors für lokale und Cloud-Datenspeicher, einschließlich Datenbanken, Software as a Service(SaaS)-Anwendungen und dateibasierte Systeme. Diese Connectors helfen Ihnen bei der Verbindung mit fast jedem Quellsystem.
Koordinieren der Datenbewegung mit Pipelines
Sie können Pipelines erstellen, die diese Connectors verwenden, um Daten in OneLake oder analytische Speicher zu kopieren oder zu verschieben. Dieser Ansatz unterstützt:
- Unstrukturierte Datasets wie Bilder, Video und Audio
- Semistrukturierte Datasets wie JSON, CSV und XML
- Strukturierte Datasets aus unterstützten relationalen Datenbanksystemen
In einer Pipeline kombinieren Sie mehrere Orchestrierungskomponenten, einschließlich:
- Datenverschiebungsaktivitäten, z. B. Kopieren von Daten und Kopierauftrag
- Datentransformationsaktivitäten wie Dataflow Gen2, Löschen von Daten, Fabric Notebook und SQL-Skript
- Steuern von Flussaktivitäten, z. B. ForEach, Nachschlagen, Festlegen von Variablen und Webhook
Sie können eine Pipeline bei Bedarf, in einem Zeitplan oder als Reaktion auf Ereignisse ausführen. Sie können beispielsweise eine Pipeline so planen, dass sie alle zwei Stunden an Wochentagen ausgeführt wird, oder sie auslösen, wenn eine neue Datei in OneLake erstellt wird.
Vereinfachen Sie die Datenverschiebung mit dem Kopierauftrag
Der Kopierauftrag unterstützt mehrere Datenübermittlungsmuster, einschließlich Massenkopie, inkrementelle Kopie und Change Data Capture (CDC) Replikation. Sie können den Kopierauftrag verwenden, um Daten aus einer Quelle nach OneLake zu verschieben, ohne eine Pipeline zu erstellen, während Sie weiterhin auf erweiterte Konfigurationsoptionen zugreifen. Der Kopierauftrag unterstützt viele Quellen und Ziele. Es bietet mehr Kontrolle als Spiegelung und weniger Betriebskomplexität als das Verwalten von Pipelines, die die Kopieraktivität verwenden.
Replizieren von Daten mit Spiegelung
Die Spiegelung repliziert Daten aus externen Systemen in Fabric in nahezu Echtzeit mit automatisiertem Setup. Sie stellen eine Verbindung mit einem externen System her, z. B. Azure SQL-Datenbank, SQL Server, Oracle, SAP oder Snowflake. Fabric repliziert kontinuierlich Daten oder Metadaten in OneLake. Spiegelung unterstützt drei Typen:
- Die Datenbankspiegelung repliziert ganze Datenbanken und Tabellen.
- Die Metadatenspiegelung synchronisiert Metadaten wie Katalognamen, Schemas und Tabellen, anstatt daten physisch zu verschieben. Bei diesem Ansatz werden Abkürzungen verwendet, sodass Daten im Quellsystem verbleiben und weiterhin in Fabric zugänglich sind.
- Bei geöffneter Spiegelung wird das geöffnete Delta Lake-Tabellenformat verwendet. Entwickler können Anwendungsänderungen direkt in ein gespiegeltes Datenbankelement in OneLake schreiben, indem sie öffentliche APIs verwenden.
Fabric lauscht auf Quellsystemänderungen (durch Änderungsdatenerfassung oder ähnliche Methoden) und wendet diese Änderungen nahezu in Echtzeit auf die gespiegelte Kopie an. Das Ergebnis ist ein live abfragbares Dataset, das mit geringer Latenz ohne komplexe ETL-Pipelines synchronisiert bleibt.
Mirroring unterstützt derzeit verschiedene Quellen, einschließlich Azure SQL-Datenbank, SQL Managed Instance, Azure Cosmos DB, Azure Database for PostgreSQL, Google BigQuery, Oracle, SAP, Snowflake und SQL Server. Es unterstützt auch Datenquellen aus Partnerlösungen, die die Open Mirroring-API implementiert haben. Gespiegelte Daten werden in OneLake als up-to-date Delta-Tabellen gespeichert. Fabric verwaltet diese Tabellen automatisch, sodass Sie sie für Echtzeitanalysen verwenden oder mit anderen Fabric-Daten kombinieren können. Diese Funktion unterstützt hybride Transaktions- und Analyseverarbeitungsszenarien, bei denen operative Daten kontinuierlich in Ihre Analyseplattform fließen.
Durch Spiegelung wird die Notwendigkeit entfernt, inkrementelle Ladepipelines manuell zu erstellen. Aus der Perspektive der Spiegelungskosten verwenden Berechnungsvorgänge, die gespiegelte Datenbanken synchron halten, keine Kapazitätseinheiten (CUs) aus Ihrer Fabric-Kapazität. Gespiegelter Datenspeicher in OneLake ist auch bis zum Terabyte-Grenzwert in Ihrer Fabric-SKU frei (z. B. enthält F64 64 TB freien gespiegelten Datenbankspeicher).
Auf externe Daten mit Verknüpfungen zugreifen
Fabric stellt Abkürzungen zur Aktivierung der Datenvirtualisierung bereit. Eine Verknüpfung in OneLake verweist auf Daten, die in einem externen System gespeichert sind, z. B. Azure Data Lake Storage Gen2, Amazon S3 oder SharePoint. Anstatt Daten zu kopieren, ermöglichen Verknüpfungen OneLake, im Rahmen des einheitlichen Datensees auf externe Dateien zu verweisen. Sie können externe Daten mit lokalen Daten abfragen oder verknüpfen, ohne eine anfängliche Migration durchzuführen. Dieser Ansatz zur Erfassung ohne Kopie ist nützlich, wenn Datenhaltungsanforderungen oder Duplizierungsanforderungen das Verschieben von Daten verhindern. Das folgende Diagramm zeigt, wie Verknüpfungen externe Speichersysteme mit Fabric-Elementen verbinden, ohne Daten zu kopieren:
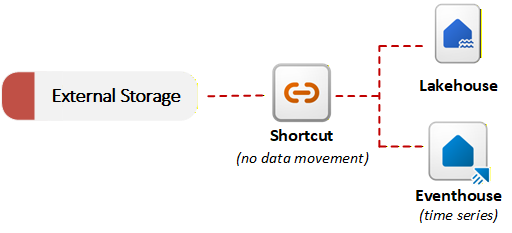
OneLake kann den Datentyp erkennen, auf den durch eine Verknüpfung verwiesen wird, und entweder Dateitransformationen oder KI-Transformationen anwenden, ohne dass eine Pipeline oder ein benutzerdefinierter Code erforderlich ist. OneLake hält die resultierende Delta-Tabelle automatisch mit der Quelle synchronisiert. Sie können beispielsweise .csv Dateien in Delta-Tabellen konvertieren oder eine KI-basierte Stimmungsanalyse auf .txt Dateien in einem Ordner anwenden.
In Verbindung mit dem Mirroring bieten Verknüpfungen flexible Möglichkeiten für den Datenzugriff. Sie können Daten mithilfe von Tastenkombinationen beibehalten oder Daten mithilfe der Spiegelung replizieren. In beiden Fällen sind Daten für Fabric-Analysetools ohne komplexe ETL bereit.
Entscheidungsleitfaden: Auswählen einer Datenbewegungsstrategie
Microsoft Fabric bietet mehrere Optionen zum Einbinden von Daten in Fabric, einschließlich Eventstreams für die Echtzeitverarbeitung, Spiegelung, Pipelines mit Kopieraktivitäten, Kopierauftrag und Verknüpfungen. Jede Option bietet eine andere Balance zwischen Steuerung, Automatisierung und Betriebskomplexität.
Anleitungen zum Auswählen des geeigneten Ansatzes für Ihr Szenario finden Sie im Microsoft Fabric-Entscheidungsleitfaden: Auswählen einer Datenbewegungsstrategie.