Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Verwenden Sie Azure Synapse Link für Dataverse, um Ihre Microsoft Dataverse-Daten im Delta-Lake-Format zu exportieren. Delta Lake ist das native Format für Microsoft Fabric und viele andere Tools wie Azure Databricks. Wenn Daten im Delta-Lake-Format direkt aus Dataverse exportiert werden, werden keine separaten Delta-Lake-Unterhaltungsprozesse mehr benötigt und die Zeit bis zum Erkenntnisgewinn verkürzt. Dieser Artikel enthält Informationen zu dieser Funktion und zeigt Ihnen, wie Sie die folgenden Aufgaben ausführen:
- Erklärt Delta Lake und Parquet und warum Sie Daten in diesem Format exportieren sollten.
- Exportieren Sie Ihre Dataverse-Daten mit Azure Synapse Link im Delta-Lake-Format in Ihren Azure Synapse Analytics-Arbeitsbereich.
- Überwachen Sie Azure Synapse Link und die Datenkonvertierung.
- Anzeigen Ihrer Daten aus Azure Data Lake Storage Gen2.
- Anzeigen Ihrer Daten aus dem Synapse-Arbeitsbereich.
- Tabellendaten in Microsoft Fabric anzeigen.
Was ist Delta Lake?
Delta Lake ist ein Open-Source-Projekt, das den Aufbau einer Lakehouse-Architektur auf Data Lakes ermöglicht. Delta Lake bietet zusätzlich zu bestehenden Data Lakes ACID-Transaktionen (Atomarität, Konsistenz, Isolation und Dauerhaftigkeit), skalierbare Metadatenverarbeitung und vereinheitlicht Streaming- und Stapelverarbeitungs-Datenverarbeitung. Azure Synapse Analytics ist mit Linux Foundation Delta Lake kompatibel. Die aktuelle Version von Delta Lake, die in Azure Synapse enthalten ist, bietet Sprachunterstützung für Scala, PySpark und .NET. Weitere Informationen: Was ist Delta Lake?. Weitere Informationen erhalten Sie auch im Video Einführung in Delta-Tabellen.
Apache Parquet ist das Basisformat für Delta Lake, mit dem Sie die effizienten Komprimierungs- und Codierungsschemata nutzen können, die für das Format systemeigen sind. Das Parquet-Dateiformat verwendet eine spaltenweise Komprimierung. Dies ist effizient und spart Speicherplatz. Abfragen, die bestimmte Spaltenwerte abrufen, müssen nicht die gesamten Zeilendaten lesen, wodurch die Leistung verbessert wird. Daher benötigt der serverlose SQL-Pool weniger Zeit und weniger Speicheranforderungen zum Lesen der Daten.
Warum sollte ich Delta Lake verwenden?
- Skalierbarkeit: Delta Lake baut auf der Open-Source-Apache-Lizenz auf, die entwickelt wurde, um Industriestandards für die Verarbeitung umfangreicher Datenverarbeitungs-Workloads zu erfüllen.
- Zuverlässigkeit: Delta Lake bietet ACID-Transaktionen und gewährleistet selbst bei Ausfällen oder gleichzeitigem Zugriff Datenkonsistenz und -zuverlässigkeit.
- Leistung: Delta Lake nutzt das spaltenweise Speicherformat von Parquet und bietet bessere Komprimierungs- und Codierungstechniken, die im Vergleich zu CSV-Abfragedateien zu einer verbesserten Abfrageleistung führen können.
- Kostengünstig: Das Dateiformat Delta Lake ist eine hochkomprimierte Datenspeichertechnologie, die Unternehmen erhebliche potenzielle Speichereinsparungen bietet. Dieses Format wurde speziell entwickelt, um die Datenverarbeitung zu optimieren und möglicherweise die Gesamtmenge der verarbeiteten Daten oder die für On-Demand-Computing erforderliche Laufzeit zu reduzieren.
- Compliance mit Datenschutzvorschriften: Delta Lake mit Azure Synapse Link bietet Tools und Features, einschließlich vorläufiges und endgültiges Löschen, um verschiedene Datenschutzgesetze einzuhalten, einschließlich der Datenschutz-Grundverordnung (DSGVO).
Wie funktioniert Delta Lake mit Azure Synapse Link für Dataverse?
Wenn Sie einen Azure Synapse Link für Dataverse einrichten, können Sie das Feature Nach Delta Link exportieren aktivieren und eine Verbindung mit einem Synapse-Arbeitsbereich und Spark-Pool herstellen. Azure Synapse Link exportiert die ausgewählten Dataverse-Tabellen im CSV-Format in festgelegten Zeitintervallen und verarbeitet sie über einen Spark-Auftrag für die Delta-Lake-Konvertierung. Nach Abschluss dieses Konvertierungsprozesses werden die CSV-Daten zwecks Speicherplatzeinsparung bereinigt. Darüber hinaus ist eine Reihe von Wartungsaufträgen geplant, die täglich ausgeführt werden und automatisch Komprimierungs- und Bereinigungsprozesse durchführen, um Datendateien zusammenzuführen und zu bereinigen, um die Speicherung weiter zu optimieren und die Abfrageleistung zu verbessern.
Wichtig
- Wenn Sie ein Upgrade von CSV auf Delta Lake mit vorhandenen benutzerdefinierten Ansichten durchführen, empfehlen wir, das Skript zu aktualisieren, um alle partitionierten Tabellen durch non_partitioned zu ersetzen. Suchen Sie dazu nach Instanzen von
_partitionedund ersetzen Sie diese durch eine leere Zeichenfolge. - Für die Dataverse-Konfiguration ist „Nur anhängen“ standardmäßig aktiviert, um CSV-Daten im
appendonly-Modus zu exportieren. Die Delta Lake-Tabelle verfügt über eine direkte Aktualisierungsstruktur, da die Delta Lake-Konvertierung mit einem regelmäßigen Zusammenführungsprozess einhergeht. - Sie müssen einen Spark-Pool (Computeressourcen) in Ihrem eigenen Azure-Abonnement für die Deltakonvertierung bereitstellen. Dieser Spark-Pool wird verwendet, um regelmäßige Delta-Konvertierungen basierend auf dem von Ihnen gewählten Zeitintervall durchzuführen.
- Bei der Erstellung von Spark-Pools fallen keine Kosten an. Gebühren fallen erst an, wenn ein Spark-Auftrag im Ziel-Spark-Pool ausgeführt und die Spark-Instanz bei Bedarf instanziiert wird. Diese Kosten beziehen sich auf die Nutzung des Spark des Azure Synapse workspace und werden monatlich abgerechnet. Die Kosten für die Durchführung von Spark-Berechnungen hängen hauptsächlich vom Zeitintervall für die inkrementelle Aktualisierung und den Datenmengen ab. Weitere Informationen: Azure Synapse Analytics Preisgestaltung
- Sie müssen einen Spark-Pool mit Version 3.4 erstellen. Wenn Sie diese Funktion bereits mit Spark Version 3.3 verwenden, müssen Sie ein direktes Upgrade für Ihre vorhandenen Profile durchführen. Weitere Informationen: Direktes Upgrade auf Apache Spark 3.4 mit Delta Lake 2.4
Anmerkung
Der Azure Synapse Link-Status in Power Apps (make.powerapps.com) spiegelt den Delta Lake-Konvertierungsstatus wider:
-
Countzeigt die Gesamtanzahl der Datensätze in der Delta-Lake-Tabelle an. -
Last synchronized onDatetime stellt den Zeitstempel der letzten erfolgreichen Konvertierung dar. -
Sync statuswird als aktiv angezeigt, sobald die Datensynchronisierung und die Delta-Lake-Konvertierung abgeschlossen sind, was bedeutet, dass die Daten verwendet werden können.
Anforderungen
- Dataverse: Sie müssen über die Sicherheitsrolle Dataverse Systemadministrator verfügen. Darüber hinaus muss bei Tabellen, die Sie über Azure Synapse Link exportieren möchten, die Eigenschaft Änderungen nachverfolgen aktiviert sein. Weitere Informationen: Erweiterte Optionen
- Azure Data Lake Storage Gen2: Sie brauchen ein Azure Data Lake Storage Gen2-Konto und müssen als Besitzer und Storage-Blob-Datenmitwirkender Zugriff haben. Ihr Speicherkonto muss Hierarchischer Namespace und Öffentlicher Netzwerkzugriff sowohl für die Ersteinrichtung als auch für die Deltasynchronisierung aktivieren. Speicherkontoschlüsselzugriff zulassen ist nur für die Ersteinrichtung erforderlich.
- Synapse Arbeitsbereich: Sie müssen über einen Synapse Arbeitsbereich und die Besitzer Rolle in der Zugriffssteuerung (IAM) und die Synapse Administrator Rolle Zugriff innerhalb des Synapse Studios haben. Der Synapse-Arbeitsbereich muss sich in derselben Region befinden wie Ihr Azure Data Lake Storage Gen2-Konto. Das Speicherkonto muss als verknüpfter Dienst innerhalb von Synapse Studio hinzugefügt werden. Um einen Synapse-Arbeitsbereich zu erstellen, gehen Sie zu Einen Synapse-Arbeitsbereich erstellen.
- Ein Apache Spark Pool im verbundenen Azure Synapse workspace mit Apache Spark Version 3.4 verbunden, der diese empfohlene Spark-Poolkonfiguration verwendet. Informationen darüber, wie Sie eine Lösung mit einem Spark Pool erstellen, finden Sie unter Neuen Apache Spark Pool erstellen.
- Für die Verwendung dieses Features ist mindestens die Microsoft Dynamics 365-Version 9.2.22082 erforderlich. Weitere Informationen: Updates für den Vorabzugang abonnieren
Empfohlene Spark-Pool-Konfiguration
Diese Konfiguration kann als Bootstrap-Schritt für durchschnittliche Anwendungsfälle betrachtet werden.
- Knotengröße: klein (4 virtuelle Kerne/32 GB)
- Autoskalierung: Aktiviert
- Anzahl der Knoten: drei bis zehn (oder 20 bei Bedarf. 1Weitere Informationen finden Sie weiter unten.)
- Automatisches Anhalten: Aktiviert
- Leerlauf in Minuten: 5
- Apache Spark: 3.4
- Ausführende dynamisch zuweisen: Aktiviert
- Standardanzahl der Ausführenden: 1 bis 9
Wichtig
- Verwenden Sie den Spark-Pool ausschließlich für Delta Lake-Unterhaltungsoperationen mit Synapse Link für Dataverse. Um eine optimale Zuverlässigkeit und Leistung zu erzielen, sollten Sie keine anderen Spark-Aufträge mit demselben Spark-Pool ausführen.
- Möglicherweise müssen Sie die Anzahl der Knoten des Spark-Pools erhöhen, wenn Sie erwarten, dass eine große Anzahl von Zeilen verarbeitet wird. Wenn die Größe des Spark-Pools nicht ausreicht, können Deltakonvertierungsaufträge fehlschlagen
- Derselbe Spark-Pool wird vom System verwendet, um einen nächtlichen Auftrag auszuführen, der Delta-Dateien im Lake komprimiert. Das System bestimmt anhand des Standorts Ihrer Dataverse-Umgebung, zu welcher Zeit der Auftrag nachts ausgeführt werden soll. Sie können kein bestimmtes Zeitfenster angeben. Diese Option reduziert die Größe von Delta-Dateien, indem sie Dateien zusammenführt. Dies wird „Komprimierung“ bezeichnet werden. In seltenen Fällen kann dieser Auftrag den inkrementellen Konvertierungsauftrag beeinträchtigen. Sie können die Anzahl der Knoten auf 20 erhöhen, falls Sie diese Fehler bemerken.
- Ihnen werden nur die tatsächlich genutzten Sparkpoolknoten in Rechnung gestellt. Eine Erhöhung der Anzahl von Knoten führt möglicherweise nicht zu höheren Gebühren.
Dataverse mit dem Synapse-Arbeitsbereich verbindung und Daten im Delta Lake-Format exportieren
Melden Sie sich in Power Apps an und wählen Sie die gewünschte Umgebung aus.
Wählen Sie im linken Navigationsbereich Azure Synapse Link aus. Wenn sich das Element nicht im linken Seitenbereich befindet, wählen Sie …Mehr und dann das gewünschte Element aus.
Wählen Sie auf der Befehlsleiste + Neuer Link
Wählen Sie Mit Ihrem Azure Synapse Analytics-Arbeitsbereich verbinden und dann Abonnement, Ressourcengruppe und Arbeitsbereichsname aus.
Wählen Sie Spark-Pool zur Verarbeitung verwenden und wählen Sie dann den vorab erstellten Spark-Pool und das Speicherkonto aus.
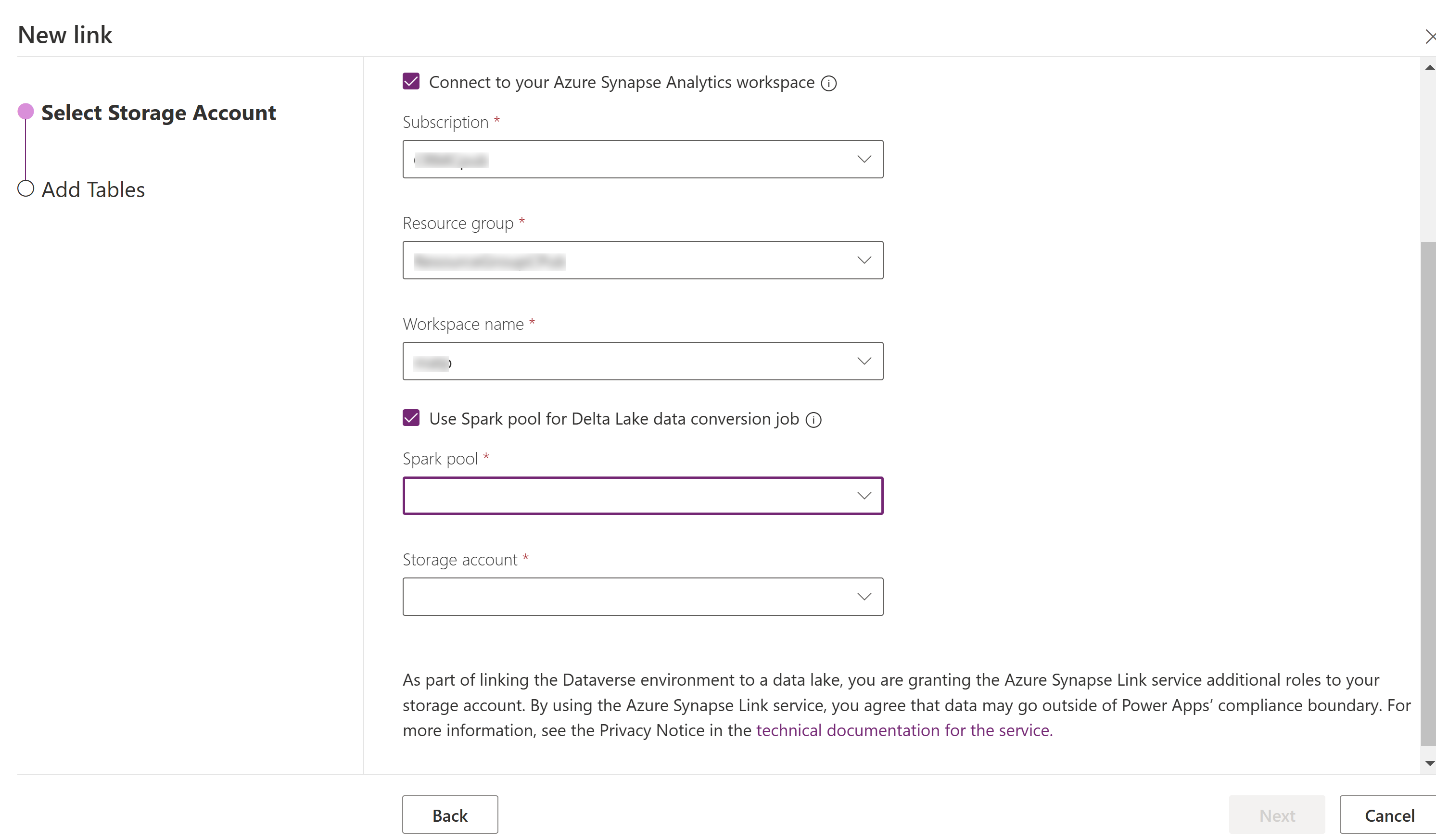
Wählen Sie Weiter.
Fügen Sie die Tabellen hinzu, die Sie exportieren möchten, und wählen Sie dann Erweitert aus.
Wählen Sie andernfalls Erweiterte Konfigurationseinstellungen anzeigen aus und geben Sie den Zeitraum in Minuten ein, wie oft die inkrementellen Updates erfasst werden sollen.
Wählen Sie Speichern.
Azure Synapse Link und die Datenkonvertierung überwachen
- Wählen Sie den gewünschten Azure Synapse Link und dann den Zum Azure Synapse Analytics-Arbeitsbereich wechseln in der Befehlszeile aus.
- Wählen Sie Überwachen>Apache Spark Anwendungen. Weitere Informationen: Verwenden Sie Synapse Studio, um Ihre Apache Spark Anwendungen zu überwachen
Anzeigen Ihrer Daten aus dem Synapse-Arbeitsbereich
- Wählen Sie den gewünschten Azure Synapse Link und dann den Zum Azure Synapse Analytics-Arbeitsbereich wechseln in der Befehlszeile aus.
- Erweitern Sie Lake Datenbanken im linken Bereich, wählen Sie Dataverse-dataverse-environmentNameorganizationUniqueName und erweitern Sie dann Tabellen. Alle Parquet-Datentabellen werden aufgelistet und stehen für die Analyse mit der Namenskonvention DataverseTableName(Non_partitioned Tabelle)zur Verfügung.
Anmerkung
Verwenden Sie keine Tabellen mit der Namenskonvention _partitioned. Wenn Sie Delta Parquet als Format wählen, werden Tabellen mit der Namenskonvention _partition als Staging-Tabellen verwendet und entfernt, nachdem sie vom System verwendet wurden.
Anzeigen Ihrer Daten aus Azure Data Lake Storage Gen2
- Wählen Sie den gewünschten Azure Synapse Link und dann Zu Azure Data Lake wechseln in der Befehlsleiste aus.
- Wählen Sie die Container unter Datenspeicher aus.
- Wählen Sie *dataverse- *environmentName-organizationUniqueName aus. Alle Parquet-Dateien werden im Ordner deltalake gespeichert.
Direktes Upgrade auf Apache Spark 3.4 mit Delta Lake 2.4
In Übereinstimmung mit der Synapse-Richtlinie für den Lebenszyklus der Laufzeit für Apache Spark, wird die Azure Synapse-Laufzeit für Apache Spark 3.3 zum 31. März 2025 eingestellt und deaktiviert. Nach dem Ende des Supports sind die eingestellten Laufzeiten für neue Spark-Pools nicht mehr verfügbar, und vorhandene Workflows mit Spark 3.3-Pools werden nicht ausgeführt, während Metadaten vorübergehend im Synapse-Arbeitsbereich verbleiben. Weitere Informationen: Azure Synapse Rundtime für Apache Spark 3.3 (EOSA).
Um sicherzustellen, dass Ihre vorhandenen Synapse-Link-Profile weiterhin Daten verarbeiten, müssen Sie Synapse-Link-Profile mithilfe des Prozesses für direkte Upgrades aktualisieren, sodass Spark-3.4-Pools verwendet werden.
Voraussetzungen für ein direktes Upgrade
- Sie müssen über ein vorhandenes Delta-Lake-Profil für Azure Synapse Link für Dataverse verfügen, das mit Synapse Spark der Version 3.3 ausgeführt wird.
- Sie müssen einen neuen Synapse Spark-Pool mit Spark Version 3.4 erstellen und dabei die gleiche oder eine höhere Knotenhardwarekonfiguration innerhalb desselben Synapse-Arbeitsbereichs verwenden. Informationen darüber, wie Sie eine Lösung mit einem Spark-Pool erstellen, finden Sie unter Neuen Apache Spark-Pool erstellen. Dieser Spark-Pool sollte unabhängig vom aktuellen 3.3-Pool erstellt werden. Löschen Sie Ihren Spark-3.3-Pool nicht und erstellen Sie keinen Spark-3.4-Pool mit demselben Namen.
Direktes Upgrade auf Spark 3.4
- Melden Sie sich bei Power Apps an und wählen Sie Ihre bevorzugte Umgebung aus.
- Wählen Sie im linken Navigationsbereich Azure Synapse Link aus. Wenn sich das Element nicht im linken Navigationsbereich befindet, wählen Sie …Mehr und dann das gewünschte Element aus.
- Öffnen Sie das Azure Synapse Link-Profil und wählen Sie dann Upgrade auf Apache Spark 3.4 mit Delta Lake 2.4 aus.
- Wählen Sie den verfügbaren Spark-Pool aus der Liste und dann Aktualisieren aus.
Anmerkung
- Das Upgrade des Spark-Pools erfolgt nur, wenn ein neuer Spark-Auftrag für die Delta-Lake-Konvertierung ausgelöst wird. Stellen Sie sicher, dass Sie nach der Auswahl von Aktualisieren mindestens eine Datenänderung vorgenommen haben.
- Sie können den älteren Spark 3.3-Pool löschen, nachdem Sie sich vergewissert haben, dass Delta-Konvertierungsaufträge den neuen Pool verwenden.