Implementieren und Überprüfen von SAP HANA mit Hochverfügbarkeit auf Azure-VMs
Für die lokale Entwicklung können Sie entweder die HANA-Systemreplikation oder freigegebenen Speicher verwenden, um Hochverfügbarkeit für SAP HANA einzurichten. Die HANA-Systemreplikation in Azure ist derzeit die einzige auf Azure-VMs unterstützte Hochverfügbarkeitsfunktion. Die SAP HANA-Replikation umfasst primären Knoten und mindestens einen sekundären Knoten. Änderungen an den Daten auf dem primären Knoten werden synchron oder asynchron an den sekundären Knoten repliziert.
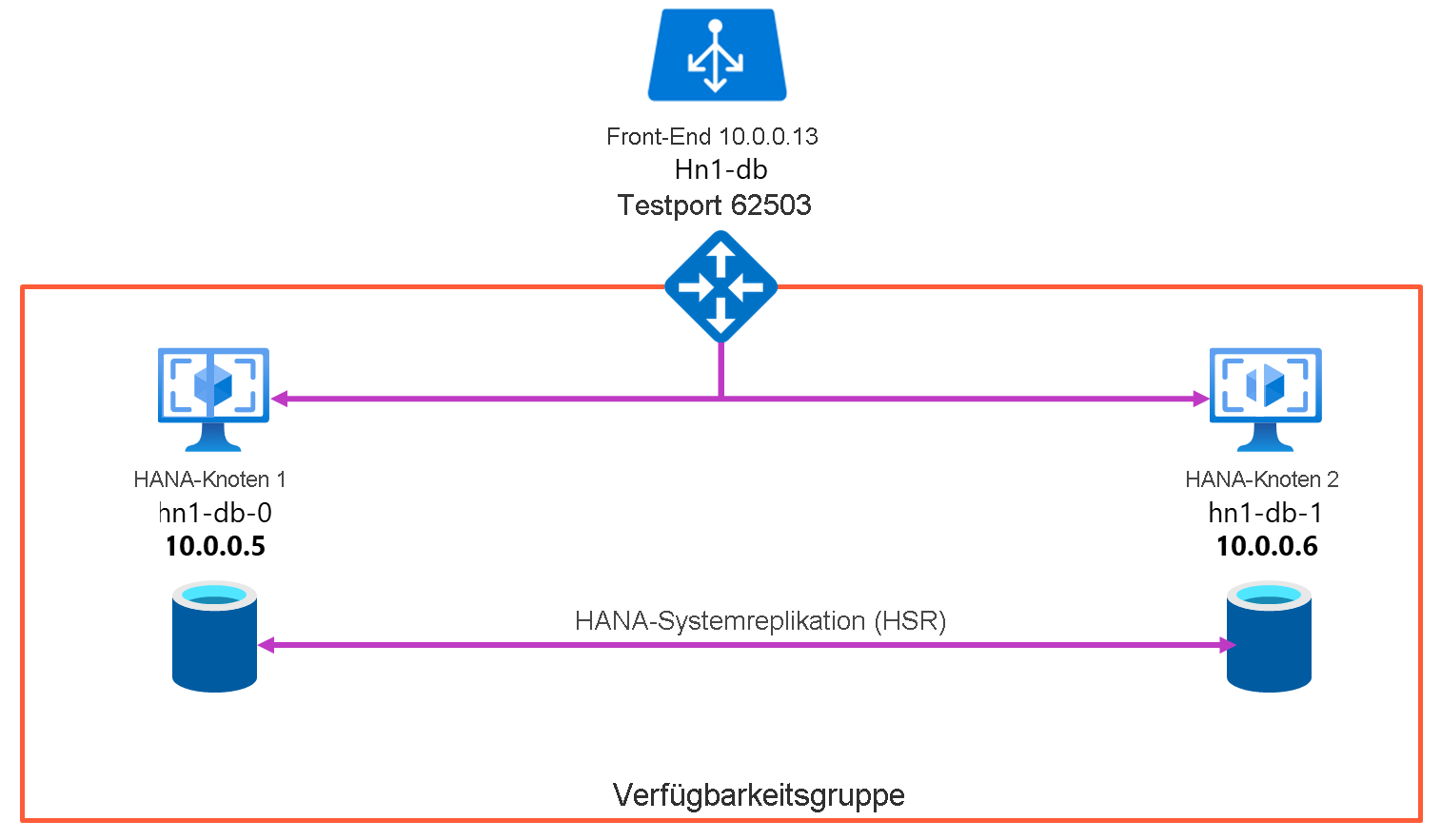
In den folgenden Schritten wird beschrieben, wie Sie Azure-VMs mit SUSE Linux Enterprise Server bereitstellen und konfigurieren, das Clusterframework installieren und die SAP HANA-Systemreplikation installieren und konfigurieren. In den Beispielkonfigurationen und Installationsbefehlen werden die Instanznummer 03 und HANA-System-ID HN1 verwendet. Die aktuellen detaillierten Schritte finden Sie im Artikel Hochverfügbarkeit für horizontal skalierte SAP HANA-Systeme mit HSR unter SUSE Linux Enterprise Server.
Eine Anleitung für das entsprechende Verfahren für Azure-VMs unter Red Hat Enterprise Linux finden Sie unter Hochverfügbarkeit von SAP HANA auf Azure-VMs unter Red Hat Enterprise Linux
Um hohe Verfügbarkeit zu erreichen, ist SAP HANA auf zwei virtuellen Computern installiert. Die Daten werden mit der HANA-Systemreplikation repliziert.
Das Setup der SAP HANA-Systemreplikation verwendet einen dedizierten virtuellen Hostnamen und virtuelle IP-Adressen. Für die Verwendung einer virtuellen IP-Adresse ist in Azure ein Lastenausgleich erforderlich. Die folgende Liste zeigt die Konfiguration des Lastenausgleichs:
- Front-End-Konfiguration: IP-Adresse 10.0.0.13 für „hn1-db“
- Back-End-Konfiguration: Mit primären Netzwerkschnittstellen von allen virtuellen Computern verbunden, die Teil der HANA-Systemreplikation sein sollen.
- Testport: Port 62503
- Lastenausgleichsregeln: 30313 TCP, 30315 TCP, 30317 TCP
Bereitstellen von Azure-Ressourcen
Der Ressourcen-Agent für SAP HANA ist im SUSE Linux Enterprise Server für SAP-Anwendungen enthalten. Der Azure Marketplace enthält ein Image für den SUSE Linux Enterprise Server for SAP Applications 12, das Sie zum Bereitstellen neuer virtueller Computer verwenden können.
Bereitstellen mit einer Vorlage
Sie können eine der Schnellstartvorlagen auf GitHub verwenden, um alle erforderlichen Ressourcen bereitzustellen. Führen Sie diese Schritte aus, um die Vorlage bereitzustellen:
Öffnen Sie die Datenbankvorlage oder die konvergierte Vorlage im Azure-Portal. Die Datenbankvorlage erstellt nur die Lastenausgleichsregeln für eine Datenbank. Die konvergierte Vorlage erstellt auch die Lastenausgleichsregeln für eine ASCS/SCS- und ERS-Instanz (nur Linux). Wenn Sie ein SAP NetWeaver-basiertes System installieren und die ASCS/SCS-Instanz auf denselben Computern installieren möchten, verwenden Sie die konvergierte Vorlage.
Legen Sie die folgenden Parameter fest:
- SAP-System-ID: Geben Sie die SAP-System-ID des SAP-Systems ein, das Sie installieren möchten. Die ID wird als Präfix für die Ressourcen verwendet, die bereitgestellt werden.
- Stapeltyp: (Dieser Parameter gilt nur, wenn Sie die konvergierte Vorlage verwenden.) Wählen Sie den SAP NetWeaver-Stapeltyp aus.
- Betriebssystemtyp: Wählen Sie eine der Linux-Distributionen aus. Wählen Sie für dieses Beispiel SLES 12 aus.
- DB-Typ: Wählen Sie HANA aus.
- SAP-Systemgröße: Geben Sie die SAPS-Anzahl an, die das neue System bereitstellen soll. Wenn Sie nicht sicher sind, welche SAPS-Anzahl für das System benötigt wird, können Sie sich an den SAP-Technologiepartner oder -Systemintegrator wenden.
- Systemverfügbarkeit: Wählen Sie HA (Hohe Verfügbarkeit).
- Administratorbenutzername und Administratorkennwort:: Ein neues Administratorbenutzerkonto, das für die Anmeldung beim Betriebssystem verwendet werden kann.
- Neues oder vorhandenes Subnetz: Legt fest, ob ein neues virtuelles Netzwerk und Subnetz erstellt oder ein bestehendes Subnetz verwendet werden soll. Wenn Sie bereits über ein virtuelles Netzwerk (VNet) verfügen, das mit Ihrem lokalen Netzwerk verbunden ist, wählen Sie hier die Option „Vorhanden“ aus.
- Subnetz-ID: Wenn Sie die VM in einem vorhandenen virtuellen Netzwerk bereitstellen möchten, in dem Sie ein Subnetz definiert haben, dem die VM zugewiesen werden soll, geben Sie die ID dieses spezifischen Subnetzes an. Die ID sieht normalerweise so aus:
/subscriptions/subscription ID/resourceGroups/resource group name/providers/Microsoft.Network/virtualNetworks/virtual network name/subnets/subnet name
Manuelle Bereitstellung (über das Azure-Portal)
Erstellen Sie eine Ressourcengruppe.
Erstellen Sie ein virtuelles Netzwerk.
Erstellen Sie eine Verfügbarkeitsgruppe.
- Legen Sie die maximalen Updatedomänen fest.
Erstellen Sie einen Load Balancer (intern).
- Wählen Sie das virtuelle Netzwerk aus, das Sie in Schritt 2 erstellt haben.
Erstellen Sie den virtuellen Computer 1.
- Verwenden Sie ein SLES4SAP-Image im Azure-Katalog, das für SAP HANA auf dem von Ihnen ausgewählten VM-Typ unterstützt wird.
- Wählen Sie die Verfügbarkeitsgruppe aus, die Sie in Schritt 3 erstellt haben.
Erstellen Sie den virtuellen Computer 2.
- Verwenden Sie ein SLES4SAP-Image im Azure-Katalog, das für SAP HANA auf dem von Ihnen ausgewählten VM-Typ unterstützt wird.
- Wählen Sie die Verfügbarkeitsgruppe aus, die Sie in Schritt 3 erstellt haben.
Fügen Sie Datenträger hinzu.
Konfigurieren Sie den Lastenausgleich. Erstellen Sie zunächst einen Front-End-IP-Pool.:
- Öffnen Sie den Lastenausgleich im Azure-Portal, wählen Sie den Front-End-IP-Pool und dann „Hinzufügen“ aus.
- Geben Sie den Namen des neuen Front-End-IP-Pools ein (z.B. hana-frontend).
- Legen Sie die Zuweisung auf Statisch fest, und geben Sie die IP-Adresse ein (z.B. 10.0.0.13).
- Notieren Sie nach Erstellen des neuen Front-End-IP-Pools dessen IP-Adresse.
Erstellen Sie als Nächstes einen Back-End-Pool:
- Öffnen Sie den Lastenausgleich, und wählen Sie Back-End-Pools und dann Hinzufügen aus.
- Geben Sie den Namen des neuen Back-End-Pools ein (z.B. hana-backend).
- Wählen Sie Virtuellen Computer hinzufügen aus.
- Wählen Sie die Verfügbarkeitsgruppe aus, die Sie in Schritt 3 erstellt haben.
- Wählen Sie die virtuellen Computer des SAP HANA-Clusters aus.
Erstellen Sie als Nächstes einen Integritätstest:
- Öffnen Sie den Lastenausgleich, und wählen Sie „Integritätstests“ und dann Hinzufügen aus.
- Geben Sie den Namen des neuen Integritätstests ein (z.B. hana-hp).
- Wählen Sie als Protokoll TCP und als Port 62503 aus. Behalten Sie für das Intervall den Wert „5“ und als Fehlerschwellenwert „2“ bei.
- Klicken Sie auf OK.
Erstellen Sie die Lastenausgleichsregeln für SAP HANA 1.0:
- Öffnen Sie den Lastenausgleich, und wählen Sie „Lastenausgleichsregeln“ und dann Hinzufügen aus.
- Geben Sie den Namen der neuen Lastenausgleichsregel ein (z.B. „hana-lb-30315“).
- Wählen Sie die Front-End-IP-Adresse, den Back-End-Pool und den Integritätstest, die Sie zuvor erstellt haben (z.B. hana-frontend), aus.
- Behalten Sie als Protokoll den Wert TCP bei, und geben Sie als Port 30315 ein.
- Erhöhen Sie die Leerlaufzeitüberschreitung auf 30 Minuten.
- Achten Sie darauf, dass Sie „Floating IP“ aktivieren.
- Wiederholen Sie diese Schritte für den Port 30317.
Erstellen Sie für SAP HANA 2.0 Lastenausgleichsregeln für die Systemdatenbank:
- Öffnen Sie den Lastenausgleich, und wählen Sie „Lastenausgleichsregeln“ und dann „Hinzufügen“ aus.
- Geben Sie den Namen der neuen Lastenausgleichsregel ein (z.B. „hana-lb-30313“).
- Wählen Sie die Front-End-IP-Adresse, den Back-End-Pool und den Integritätstest, die Sie zuvor erstellt haben (z.B. hana-frontend), aus.
- Behalten Sie als Protokoll den Wert TCP bei, und geben Sie als Port 30313 ein.
- Erhöhen Sie die Leerlaufzeitüberschreitung auf 30 Minuten.
- Achten Sie darauf, dass Sie „Floating IP“ aktivieren.
- Wiederholen Sie diese Schritte für den Port 30314.
Erstellen Sie für SAP HANA 2.0 Lastenausgleichsregeln für die Mandantendatenbank:
- Öffnen Sie den Lastenausgleich, und wählen Sie „Lastenausgleichsregeln“ und dann „Hinzufügen“ aus.
- Geben Sie den Namen der neuen Lastenausgleichsregel ein (z.B. „hana-lb-30340“).
- Wählen Sie die Front-End-IP-Adresse, den Back-End-Pool und den Integritätstest, die Sie zuvor erstellt haben (z.B. HANA-frontend) aus.
- Behalten Sie als Protokoll den Wert TCP bei, und geben Sie als Port 30340 ein.
- Erhöhen Sie die Leerlaufzeitüberschreitung auf 30 Minuten.
- Achten Sie darauf, dass Sie „Floating IP“ aktivieren.
- Wiederholen Sie diese Schritte für die Ports 30341 und 30342.
Weitere Informationen zu den erforderlichen Ports für SAP HANA finden Sie im SAP-Hinweis #2388694.
Wichtig
Aktivieren Sie keine TCP-Zeitstempel auf Azure-VMs, die sich hinter Azure Load Balancern befinden. Das Aktivieren von TCP-Zeitstempeln bewirkt, dass bei Integritätstests Fehler auftreten. Legen Sie den Parameter net.ipv4.tcp_timestamps auf 0 fest.
Erstellen eines Pacemaker-Clusters
Führen Sie die Schritte in Einrichten von Pacemaker unter Red Hat Enterprise Linux in Azure aus, um ein grundlegendes Pacemaker-Cluster für diesen HANA-Server zu erstellen. Sie können denselben Pacemaker-Cluster für SAP HANA und SAP NetWeaver (A)SCS verwenden.
Installieren von SAP HANA
Für die Schritte in diesem Abschnitt werden die folgenden Präfixe verwendet:
- [A] : Der Schritt gilt für alle Knoten.
- [1] : Der Schritt gilt nur für den Knoten 1.
- [2] : Der Schritt gilt nur für den Knoten 2 des Pacemaker-Clusters.
[A]: Richten Sie das Datenträgerlayout mit LVM (Logical Volume Manager) ein. Es wird empfohlen, LVM für Volumes zu verwenden, die Daten- und Protokolldateien speichern. Im folgenden Beispiel wird davon ausgegangen, dass die Azure-VMs über vier Datenträger verfügen, die zum Erstellen von zwei Volumes verwendet werden.
- Listen Sie alle verfügbaren Datenträger auf:
ls /dev/disk/azure/scsi1/lun*- Erstellen Sie physische Volumes für alle Datenträger, die Sie verwenden möchten:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3- Erstellen Sie eine Volumegruppe für die Datendateien. Verwenden Sie eine Volumegruppe für die Protokolldateien und eine für das freigegebene Verzeichnis von
SAP HANA:\.
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2- Erstellen Sie die logischen Volumes.
Ein lineares Volume wird erstellt, wenn Sie
lvcreateohne den Schalter-iverwenden. Es wird empfohlen, ein Stripesetvolume für eine bessere E/A-Leistung zu erstellen und die Stripegrößen an die in SAP HANA VM-Speicherkonfigurationen dokumentierten Werte anzupassen. Das-i-Argument sollte die Anzahl der zugrunde liegenden physischen Volumes und das-I-Argument die Stripegröße sein. In diesem Dokument werden zwei physische Volumes für das Datenvolume verwendet, daher wird das Argument für den Schalter-iauf 2 festgelegt. Die Stripegröße für das Datenvolume beträgt 256 KiB. Für das Protokollvolume wird ein physisches Volume verwendet, sodass keine-i- oder-I-Schalter explizit für die Protokollvolumebefehle verwendet werden.Wichtig
Verwenden Sie den Schalter
-i, und ändern Sie die Zahl in die Anzahl der zugrunde liegenden physischen Volumes, wenn Sie für die einzelnen Daten- oder Protokollvolumes mehrere physische Datenträger verwenden. Verwenden Sie den Schalter-I, um die Stripegröße festzulegen, wenn Sie ein Stripesetvolume erstellen.
Informationen zu empfohlenen Speicherkonfigurationen, einschließlich Stripegrößen und Anzahl der Datenträger, finden Sie unter SAP HANA VM-Speicherkonfigurationen.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log- Erstellen Sie die Bereitstellungsverzeichnisse, und kopieren Sie die UUID aller logischen Volumes.
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 sudo mkdir -p /hana/shared/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data, /dev/vg_hana_log_HN1/hana_log, and /dev/vg_hana_shared_HN1/hana_shared sudo blkid- Erstellen Sie fstab-Einträge für die drei logischen Volumes.
sudo vi /etc/fstab- Fügen Sie die folgenden Zeilen in die Datei /etc/fstab ein:
/dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2- Stellen Sie die neuen Volumes bereit:
sudo mount -a[A]: Richten Sie das Datenträgerlayout ein:
- Für Demosysteme können Sie Ihre HANA-Daten- und Protokolldateien auf einem Datenträger platzieren. Erstellen Sie auf „/dev/disk/azure/scsi1/lun0“ eine Partition, und formatieren Sie sie mit XFS:
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstab- Fügen Sie diese Zeile in die Datei /etc/fstab ein:
/dev/disk/by-uuid/[UUID] /hana xfs defaults,nofail 0 2- Erstellen Sie das Zielverzeichnis, und stellen Sie den Datenträger bereit:
sudo mkdir /hana sudo mount -a[A] Richten Sie die Hostnamensauflösung für alle Hosts ein. Sie können entweder einen DNS-Server verwenden oder die Datei „/etc/hosts“ auf allen Knoten ändern.
[A]: Installieren Sie die Pakete für SAP HANA mit Hochverfügbarkeit.
sudo zypper install SAPHanaSR[A]: Führen Sie das Programm hdblcm vom HANA-Installationsmedium aus. Geben Sie an der Eingabeaufforderung folgende Werte ein:
- Wählen Sie die Installation aus: Geben Sie 1 ein.
- Wählen Sie andere Komponenten für die Installation aus: Geben Sie 1 ein.
- Geben Sie den Installationspfad ein [/hana/shared]: Drücken Sie die EINGABETASTE.
- Enter Local Host Name [..]: Drücken Sie die EINGABETASTE.
- Möchten Sie dem System zusätzliche Hosts hinzufügen? (j/n) [n] : Drücken Sie die EINGABETASTE.
- Geben Sie die SAP HANA-System-ID ein: Geben Sie die HANA-SID ein, z.B.: HN1.
- Enter Instance Number [00]: Geben Sie die HANA-Instanznummer ein. Verwenden Sie 03, wenn Sie die Azure-Vorlage verwendet oder die in diesem Artikel beschriebene manuelle Bereitstellung durchgeführt haben.
- Datenbankmodus auswählen/Index eingeben [1]: Drücken Sie die EINGABETASTE.
- Wählen Sie die Systemnutzung / geben Sie den Index [ein 4]: Wählen Sie den Systemnutzungswert aus.
- Geben Sie den Speicherort der Datenvolumes ein [/hana/data/HN1]: Drücken Sie die EINGABETASTE.
- Geben Sie den Speicherort der Protokollvolumes ein [/hana/log/HN1]: Drücken Sie die EINGABETASTE.
- Möchten Sie die maximale Speicherbelegung beschränken? [n]: Drücken Sie die EINGABETASTE.
- Enter Certificate Host Name For Host '...' [...]: Drücken Sie die EINGABETASTE.
- Enter SAP Host Agent User (sapadm) Password: Geben Sie das Benutzerkennwort des Host-Agents ein.
- Confirm SAP Host Agent User (sapadm) Password: Geben Sie das Benutzerkennwort des Host-Agents zur Bestätigung erneut ein.
- Enter System Administrator (hdbadm) Password: Geben Sie das Systemadministratorkennwort ein.
- Confirm System Administrator (hdbadm) Password: Geben Sie das Systemadministratorkennwort zur Bestätigung erneut ein.
- Enter System Administrator Home Directory [/usr/sap/HN1/home]: Drücken Sie die EINGABETASTE.
- Wechseln Sie zur Anmelde-Shell für den Systemadministrator [/bin/sh]: Drücken Sie die EINGABETASTE.
- Enter System Administrator User ID [1001]: Drücken Sie die EINGABETASTE.
- Enter ID of User Group (sapsys) [79]: Drücken Sie die EINGABETASTE.
- Enter Database User (SYSTEM) Password: Geben Sie das Benutzerkennwort für die Datenbank ein.
- Confirm Database User (SYSTEM) Password: Geben Sie das Benutzerkennwort für die Datenbank zur Bestätigung erneut ein.
- Soll das System nach dem Neustart des Computers neu starten? [n]: Drücken Sie die EINGABETASTE.
- Möchten Sie fortfahren? (j/n): Überprüfen Sie die Zusammenfassung. Geben Sie y ein, um fortzufahren.
[A] Führen Sie ein Upgrade für den SAP-Host-Agent durch. Laden Sie das aktuelle SAP-Host-Agent-Archiv vom SAP Software Center herunter, und führen Sie den folgenden Befehl zum Aktualisieren des Agents aus. Ersetzen Sie den Pfad zum Archiv, um auf die Datei zu verweisen, die Sie heruntergeladen haben:
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive [path to SAP Host Agent SAR]
Konfigurieren der SAP HANA 2.0-Systemreplikation
[1] Erstellen Sie die Mandantendatenbank. Wenn Sie SAP HANA 2.0 oder MDC verwenden, erstellen Sie eine Mandantendatenbank für Ihr SAP NetWeaver-System. Ersetzen Sie NW1 durch die SID des SAP-Systems. Führen Sie den folgenden Befehl als
hanasidadmaus:hdbsql -u SYSTEM -p "passwd" -i 03 -d SYSTEMDB 'CREATE DATABASE NW1 SYSTEM USER PASSWORD "passwd"'[1] Konfigurieren Sie die Systemreplikation auf dem ersten Knoten.
- Sichern Sie die Datenbanken als
hanasidadm:
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')" hdbsql -d NW1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupNW1')"- Kopieren Sie die PKI-Systemdateien auf den sekundären Standort:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/- Erstellen Sie den primären Standort:
hdbnsutil -sr_enable --name=SITE1- Sichern Sie die Datenbanken als
[2]: Konfigurieren Sie die Systemreplikation auf dem zweiten Knoten. Registrieren Sie den zweiten Knoten zum Starten der Replikation. Führen Sie die folgende Befehle als Administrator
hanasidadmaus:sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
Konfigurieren der SAP HANA 1.0-Systemreplikation
[1] Erstellen Sie die erforderlichen Benutzer. Führen Sie den folgenden Befehl als root aus:
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbsql -u system -i 03 'CREATE USER hdbhasync PASSWORD "passwd"' hdbsql -u system -i 03 'GRANT DATA ADMIN TO hdbhasync' hdbsql -u system -i 03 'ALTER USER hdbhasync DISABLE PASSWORD LIFETIME'[A] Erstellen Sie den Keystoreeintrag. Führen Sie den folgenden Befehl als root aus, um einen neuen Keystoreeintrag zu erstellen:
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbuserstore SET hdbhaloc localhost:30315 hdbhasync passwd[1] Sichern Sie die Datenbank.
- Sichern Sie die Datenbanken als root:
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbsql -d SYSTEMDB -u system -i 03 "BACKUP DATA USING FILE ('initialbackup')"- Wenn Sie eine Installation mit mehreren Mandanten verwenden, sichern Sie auch die Mandantendatenbank:
hdbsql -d HN1 -u system -i 03 "BACKUP DATA USING FILE ('initialbackup')"[1] Konfigurieren Sie die Systemreplikation auf dem ersten Knoten. Erstellen Sie den primären Standort als
hanasidadm:su - hdbadm hdbnsutil -sr_enable –-name=SITE1[2] Konfigurieren Sie die Systemreplikation auf dem zweiten Knoten. Registrieren Sie den sekundären Standort als
hanasidadm:sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
Erstellen von SAP HANA-Clusterressourcen
Erstellen Sie zuerst die HANA-Topologie. Führen Sie die folgenden Befehle auf einem der Pacemaker-Clusterknoten aus:
sudo crm configure property maintenance-mode=true # Replace the bold string with your instance number and HANA system ID sudo crm configure primitive rsc_SAPHanaTopology_HN1_HDB03 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HN1_HDB03-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HN1" InstanceNumber="03" sudo crm configure clone cln_SAPHanaTopology_HN1_HDB03 rsc_SAPHanaTopology_HN1_HDB03 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"Erstellen Sie als Nächstes die HANA-Ressourcen.
Hinweis
Dieser Artikel enthält Verweise auf den Begriff Slave, einen Begriff, den Microsoft nicht mehr verwendet. Sobald der Begriff aus der Software entfernt wurde, wird er auch aus diesem Artikel entfernt.
# Replace the bold string with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer. sudo crm configure primitive rsc_SAPHana_HN1_HDB03 ocf:suse:SAPHana \ operations \$id="rsc_sap_HN1_HDB03-operations" \ op start interval="0" timeout="3600" \ op stop interval="0" timeout="3600" \ op promote interval="0" timeout="3600" \ op monitor interval="60" role="Master" timeout="700" \ op monitor interval="61" role="Slave" timeout="700" \ params SID="HN1" InstanceNumber="03" PREFER_SITE_TAKEOVER="true" \ DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false" sudo crm configure ms msl_SAPHana_HN1_HDB03 rsc_SAPHana_HN1_HDB03 \ meta is-managed="true" notify="true" clone-max="2" clone-node-max="1" \ target-role="Started" interleave="true" sudo crm configure primitive rsc_ip_HN1_HDB03 ocf:heartbeat:IPaddr2 \ meta target-role="Started" is-managed="true" \ operations \$id="rsc_ip_HN1_HDB03-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.0.0.13" sudo crm configure primitive rsc_nc_HN1_HDB03 anything \ params binfile="/usr/bin/nc" cmdline_options="-l -k 62503" \ op monitor timeout=20s interval=10 depth=0 sudo crm configure group g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 rsc_nc_HN1_HDB03 sudo crm configure colocation col_saphana_ip_HN1_HDB03 4000: g_ip_HN1_HDB03:Started \ msl_SAPHana_HN1_HDB03:Master sudo crm configure order ord_SAPHana_HN1_HDB03 Optional: cln_SAPHanaTopology_HN1_HDB03 \ msl_SAPHana_HN1_HDB03 # Clean up the HANA resources. The HANA resources might have failed because of a known issue. sudo crm resource cleanup rsc_SAPHana_HN1_HDB03 sudo crm configure property maintenance-mode=false sudo crm configure rsc_defaults resource-stickiness=1000 sudo crm configure rsc_defaults migration-threshold=5000Stellen Sie sicher, dass der Clusterstatus gültig ist und alle Ressourcen gestartet sind. Es ist nicht wichtig, auf welchem Knoten die Ressourcen ausgeführt werden.
sudo crm_mon -r # Online: [ hn1-db-0 hn1-db-1 ] # # Full list of resources: # # stonith-sbd (stonith:external/sbd): Started hn1-db-0 # rsc_st_azure (stonith:fence_azure_arm): Started hn1-db-1 # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] # Started: [ hn1-db-0 hn1-db-1 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] # Masters: [ hn1-db-0 ] # Slaves: [ hn1-db-1 ] # Resource Group: g_ip_HN1_HDB03 # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 # rsc_nc_HN1_HDB03 (ocf::heartbeat:anything): Started hn1-db-0
Hinzufügen eines dritten HSR-Standorts zu einem HANA Pacemaker-Cluster
SAP HANA unterstützt die Systemreplikation (HSR) mit mehr als zwei verbundenen Standorten. Sie können einem vorhandenen HSR-Paar, das von Pacemaker in einem hochverfügbaren Setup verwaltet wird, einen dritten Standort hinzufügen. Für Notfallwiederherstellungszwecke (Disaster Recovery, DR) können Sie einem HANA-Pacemaker-Cluster einen dritten HSR-Standort in einer zweiten Azure-Region hinzufügen. Es werden auch Besonderheiten von SUSE Linux Enterprise Server (SLES) und Red Hat Enterprise Linux (RHEL) behandelt.
Pacemaker und der HANA-Clusterressourcen-Agent verwalten die ersten beiden Standorte. Der Pacemaker-Cluster steuert nicht den dritten Standort.
SAP HANA unterstützt einen dritten Systemreplikationsstandort in zwei Modi:
- Mehrere Ziele: Datenänderungen werden vom primären auf mehrere Zielsysteme repliziert. Der dritte Standort ist mit dem primären Replikat in einer Sterntopologie verbunden.
- Mehrere Ebenen: Die Replikation erfolgt auf zwei Ebenen. Eine kaskadierende oder verkettete Einrichtung von drei verschiedenen HANA-Ebenen. Der dritte Standort stellt eine Verbindung mit der sekundären Ebene bereit.
Weitere konzeptionelle Details zu HANA HSR in einer und in mehreren Regionen finden Sie unter SAP HANA-Verfügbarkeit in verschiedenen Azure-Regionen.
Testen der Clustereinrichtung
Testen Sie die Migration. Bevor Sie mit dem Test beginnen, stellen Sie sicher, dass keine fehlerhaften Pacemaker-Aktionen vorhanden sind (mit „crm_mon -r“), dass keine unerwarteten Standorteinschränkungen gelten (z. B. durch Rückstände eines Migrationstests) und dass HANA synchron ist, z. B. mit „SAPHanaSR-showAttr“:
aspx-csharp SAPHanaSR-showAttr- Sie können den SAP HANA-Masterknoten migrieren, indem Sie den folgenden Befehl ausführen:
crm resource migrate msl_SAPHana_HN1_HDB03 hn1-db-1- Wenn Sie AUTOMATED_REGISTER="false" festlegen, sollte diese Befehlssequenz den SAP HANA-Hauptknoten und die Gruppe, die die virtuelle IP-Adresse enthält, zu hn1-db-1 migrieren. Nach Abschluss der Migration sieht die Ausgabe von „crm_mon -r“ wie folgt aus:
Online: [ hn1-db-0 hn1-db-1 ] Full list of resources: stonith-sbd (stonith:external/sbd): Started hn1-db-1 Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Stopped: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:anything): Started hn1-db-1 Failed Actions: * rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none', last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms- Die SAP HANA-Ressource auf „hn1-db-0“ wird nicht als sekundär gestartet. In diesem Fall konfigurieren Sie die HANA-Instanz als sekundär, indem Sie diesen Befehl ausführen:
su - hn1adm # Stop the HANA instance just in case it's running hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr 03 -function StopWait 600 10 hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1- Die Migration erstellt Speicherorteinschränkungen, die erneut gelöscht werden müssen:
# Switch back to root and clean up the failed state exit hn1-db-0:~ # crm resource unmigrate msl_SAPHana_HN1_HDB03- Darüber hinaus müssen Sie auch den Status der sekundären Knotenressource bereinigen:
hn1-db-0:~ # crm resource cleanup msl_SAPHana_HN1_HDB03 hn1- db-0- Sie überwachen den Status der HANA-Ressource mithilfe von crm_mon -r. Nachdem HANA auf hn1-db-0 gestartet wurde, sollte die Ausgabe wie folgt aussehen:
Online: [ hn1-db-0 hn1-db-1 ] Full list of resources: stonith-sbd (stonith:external/sbd): Started hn1-db-1 Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:anything): Started hn1-db-1Testen des Azure-Umgrenzungs-Agent (nicht SBD)
- Sie können die Einrichtung des Azure-Umgrenzungs-Agent testen, indem Sie die Netzwerkschnittstelle auf dem Knoten „hn1-db-0“ deaktivieren:
sudo ifdown eth0- Der virtuelle Computer sollte jetzt abhängig von Ihrer Clusterkonfiguration neu gestartet oder beendet werden. Wenn Sie die Einstellung „stonith-action“ auf „off“ festlegen, wird die VM beendet, und die Ressourcen werden zur ausgeführten VM migriert.
- Nachdem Sie die VM erneut gestartet haben, kann die SAP HANA-Ressource nicht als sekundäre Ressource gestartet werden, wenn Sie AUTOMATED_REGISTER="false" festlegen. In diesem Fall konfigurieren Sie die HANA-Instanz als sekundär, indem Sie diesen Befehl ausführen:
su - hn1adm # Stop the HANA instance just in case it's running sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1 # Switch back to root and clean up the failed state exit crm resource cleanup msl_SAPHana_HN1_HDB03 hn1-db-0Testen der SBD-Umgrenzung
- Sie können das Setup von SBD testen, indem Sie den inquisitor-Prozess beenden.
hn1-db-0:~ # ps aux | grep sbd root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8 root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd hn1-db-0:~ # kill -9 1912 Cluster node hn1-db-0 should be rebooted. The Pacemaker service might not get started afterward. Make sure to start it again.Testen eines manuellen Failovers
Sie können ein manuelles Failover testen, indem Sie den Pacemaker-Dienst auf dem Knoten hn1-db-0 beenden:
service pacemaker stopWichtig
Wenn Clusterknoten nicht miteinander kommunizieren können, besteht das Risiko eines Split-Brain-Szenarios. In solchen Situationen versuchen Clusterknoten, sich gleichzeitig zu umgrenzen, was zu einem Fence Race führt.
Beim Konfigurieren eines Fencinggeräts wird empfohlen, die
pcmk_delay_max-Eigenschaft zu konfigurieren. Im Fall eines Split-Brain-Szenarios fügt der Cluster der Fencing-Aktion auf jedem Knoten also eine zufällige Verzögerung bis zumpcmk_delay_max-Wert hinzu. Der Knoten mit der kürzesten Verzögerung wird für das Fencing ausgewählt.Um sicherzustellen, dass der Knoten, auf dem der HANA-Master ausgeführt wird, Vorrang hat und das Fence Race in einem Split-Brain-Szenario gewinnt, empfiehlt es sich, die
priority-fencing-delay-Eigenschaft in der Clusterkonfiguration festzulegen. Durch Aktivieren der priority-fencing-delay-Eigenschaft kann der Cluster eine zusätzliche Verzögerung in der Fencing-Aktion speziell für den Knoten einführen, der die HANA-Masterressource hostet, sodass der Knoten das Fence Race gewinnen kann.Nach dem Failover können Sie den Dienst erneut starten. Wenn Sie AUTOMATED_REGISTER="false" festlegen, kann die SAP HANA-Ressource auf dem Knoten hn1-db-0 nicht als sekundäre Ressource gestartet werden. In diesem Fall konfigurieren Sie die HANA-Instanz als sekundär, indem Sie diesen Befehl ausführen:
service pacemaker start su - hn1adm # Stop the HANA instance just in case it's running sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1 # Switch back to root and clean up the failed state exit crm resource cleanup msl_SAPHana_HN1_HDB03 hn1-db-0
SUSE-Tests
Führen Sie abhängig von Ihrem Anwendungsfall alle Testfälle aus, die im Szenario zur leistungsoptimierten SAP HANA-Systemreplikation oder zur kostenoptimierten SAP HANA-Systemreplikation aufgeführt werden. Die folgenden Tests sind eine Kopie der Testbeschreibungen des Szenarios SAP HANA SR Performance Optimized aus dem Leitfaden zu SUSE Linux Enterprise Server for SAP Applications 12 SP4. Eine aktuelle Version finden Sie stets in der Anleitung selbst. Stellen Sie immer sicher, dass HANA synchron ist, bevor Sie den Test starten, und dass die Pacemaker-Konfiguration korrekt ist. In den folgenden Testbeschreibungen wird von den folgenden Werten ausgegangen: PREFER_SITE_TAKEOVER="true" und AUTOMATED_REGISTER="false". HINWEIS: Die folgenden Tests sind dafür konzipiert, nacheinander ausgeführt zu werden, und hängen vom Endzustand der vorherigen Tests ab.
- TEST 1: BEENDEN DER PRIMÄREN DATENBANK AUF KNOTEN 1
- TEST 2: BEENDEN DER PRIMÄREN DATENBANK AUF KNOTEN 2
- TEST 3: ABSTURZ DER PRIMÄREN DATENBANK AUF KNOTEN 1
- TEST 4: ABSTURZ DER PRIMÄREN DATENBANK AUF KNOTEN 2
- TEST 5: ABSTURZ DES KNOTENS AM PRIMÄREN STANDORT (KNOTEN 1)
- TEST 6: ABSTURZ DES KNOTENS AM SEKUNDÄREN STANDORT (KNOTEN 2)
- TEST 7: BEENDEN DER SEKUNDÄREN DATENBANK AUF KNOTEN 2
- TEST 8: ABSTURZ DER SEKUNDÄREN DATENBANK AUF KNOTEN 2
- TEST 9: ABSTURZ DES KNOTENS AM SEKUNDÄREN STANDORT (KNOTEN 2), AUF DEM DIE SEKUNDÄRE HANA-DATENBANK AUSGEFÜHRT WIRD
Konfigurieren Sie Pacemaker für geplante Azure-Ereignisse
Azure verfügt über geplante Ereignisse. Geplante Ereignisse werden über den Metadatendienst gesendet und ermöglichen es der Anwendung, sich auf solche Ereignisse vorzubereiten.
Der Pacemaker-Ressourcen-Agent azure-events-az wird zur Überwachung auf geplante Azure-Ereignisse verwendet. Wenn Ereignisse erkannt werden und der Ressourcenagent feststellt, dass ein anderer Clusterknoten verfügbar ist, wird ein Clusterintegritätsattribut festgelegt.
Wenn das Clusterintegritätsattribut für einen Knoten festgelegt wird, wird die Standorteinschränkung ausgelöst, und alle Ressourcen, deren Name nicht mit health- beginnt, werden mit dem geplanten Ereignis vom Knoten weg migriert. Sobald der betroffene Clusterknoten frei von ausgeführten Clusterressourcen ist, wird das geplante Ereignis bestätigt und kann seine Aktion (beispielsweise einen Neustart) ausführen.