series_mv_oc_anomalies_fl()
The function series_mv_oc_anomalies_fl() is a user-defined function (UDF) that detects multivariate anomalies in series by applying the One Class SVM model from scikit-learn. The function accepts a set of series as numerical dynamic arrays, the names of the features columns and the expected percentage of anomalies out of the whole series. The function trains one class SVM for each series and marks the points that fall outside the hyper sphere as anomalies.
Prerequisites
- The Python plugin must be enabled on the cluster. This is required for the inline Python used in the function.
- The Python plugin must be enabled on the database. This is required for the inline Python used in the function.
Syntax
T | invoke series_mv_oc_anomalies_fl(features_cols, anomaly_col [, score_col [, anomalies_pct ]])
Learn more about syntax conventions.
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| features_cols | dynamic |
✔️ | An array containing the names of the columns that are used for the multivariate anomaly detection model. |
| anomaly_col | string |
✔️ | The name of the column to store the detected anomalies. |
| score_col | string |
The name of the column to store the scores of the anomalies. | |
| anomalies_pct | real |
A real number in the range [0-50] specifying the expected percentage of anomalies in the data. Default value: 4%. |
Function definition
You can define the function by either embedding its code as a query-defined function, or creating it as a stored function in your database, as follows:
Define the function using the following let statement. No permissions are required.
Important
A let statement can't run on its own. It must be followed by a tabular expression statement. To run a working example of series_mv_oc_anomalies_fl(), see Example.
let series_mv_oc_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.svm import OneClassSVM
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
svm = OneClassSVM(nu=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
svm.fit(dffe)
df.loc[i, anomaly_col] = (svm.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = svm.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Write your query to use the function.
Example
The following example uses the invoke operator to run the function.
To use a query-defined function, invoke it after the embedded function definition.
let series_mv_oc_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.svm import OneClassSVM
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
svm = OneClassSVM(nu=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
svm.fit(dffe)
df.loc[i, anomaly_col] = (svm.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = svm.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Usage
normal_2d_with_anomalies
| extend anomalies=dynamic(null), scores=dynamic(null)
| invoke series_mv_oc_anomalies_fl(pack_array('x', 'y'), 'anomalies', 'scores', anomalies_pct=6)
| extend anomalies=series_multiply(80, anomalies)
| render timechart
Output
The table normal_2d_with_anomalies contains a set of 3 time series. Each time series has two-dimensional normal distribution with daily anomalies added at midnight, 8am, and 4pm respectively. You can create this sample dataset using an example query.
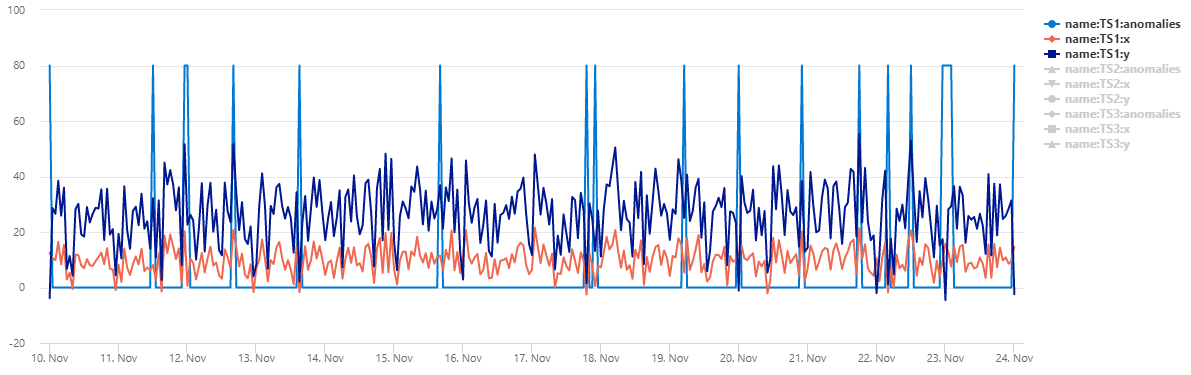
To view the data as a scatter chart, replace the usage code with the following:
normal_2d_with_anomalies
| extend anomalies=dynamic(null)
| invoke series_mv_oc_anomalies_fl(pack_array('x', 'y'), 'anomalies')
| where name == 'TS1'
| project x, y, anomalies
| mv-expand x to typeof(real), y to typeof(real), anomalies to typeof(string)
| render scatterchart with(series=anomalies)
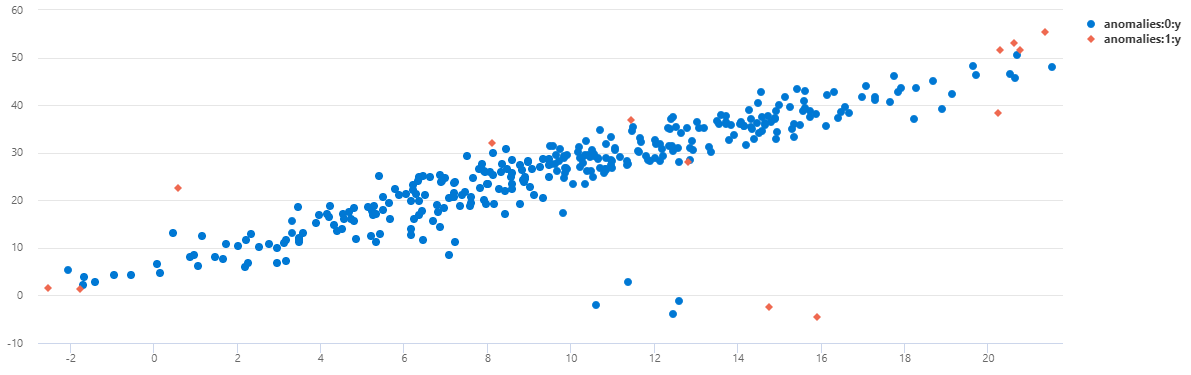
You can see that on TS1 most of the anomalies occurring at midnights were detected using this multivariate model.
This feature isn't supported.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for