Azure Data Lake Storage migration guidelines and patterns
You can migrate your data, workloads, and applications from Azure Data Lake Storage Gen1 to Azure Data Lake Storage Gen2. This article explains the recommended migration approach and covers the different migration patterns and when to use each. For easier reading, this article uses the term Gen1 to refer to Azure Data Lake Storage Gen1, and the term Gen2 to refer to Azure Data Lake Storage Gen2.
Note
Azure Data Lake Storage Gen1 is now retired. See the retirement announcement here. Data Lake Storage Gen1 resources are no longer accessible. If you require special assistance, please contact us.
Azure Data Lake Storage Gen2 is built on Azure Blob storage and provides a set of capabilities dedicated to big data analytics. Data Lake Storage Gen2 combines features from Azure Data Lake Storage Gen1, such as file system semantics, directory, and file level security and scale with low-cost, tiered storage, high availability/disaster recovery capabilities from Azure Blob storage.
Note
Because Gen1 and Gen2 are different services, there is no in-place upgrade experience. To simplify the migration to Gen2 by using the Azure portal, see Migrate Azure Data Lake Storage from Gen1 to Gen2 by using the Azure portal.
Recommended approach
To migrate from Gen1 to Gen2, we recommend the following approach.
Step 1: Assess readiness
Step 2: Prepare to migrate
Step 3: Migrate data and application workloads
Step 4: Cutover from Gen1 to Gen2
Step 1: Assess readiness
Learn about the Data Lake Storage Gen2 offering; its benefits, costs, and general architecture.
Compare the capabilities of Gen1 with those of Gen2.
Review a list of known issues to assess any gaps in functionality.
Gen2 supports Blob storage features such as diagnostic logging, access tiers, and Blob storage lifecycle management policies. If you're interesting in using any of these features, review current level of support.
Review the current state of Azure ecosystem support to ensure that Gen2 supports any services that your solutions depend upon.
Step 2: Prepare to migrate
Identify the data sets that you'll migrate.
Take this opportunity to clean up data sets that you no longer use. Unless you plan to migrate all of your data at one time, Take this time to identify logical groups of data that you can migrate in phases.
Perform an Ageing Analysis (or similar) on your Gen1 account to identify which files or folders stay in inventory for a long time or are perhaps becoming obsolete.
Determine the impact that a migration will have on your business.
For example, consider whether you can afford any downtime while the migration takes place. These considerations can help you to identify a suitable migration pattern, and to choose the most appropriate tools.
Create a migration plan.
We recommend these migration patterns. You can choose one of these patterns, combine them together, or design a custom pattern of your own.
Step 3: Migrate data, workloads, and applications
Migrate data, workloads, and applications by using the pattern that you prefer. We recommend that you validate scenarios incrementally.
Create a storage account and enable the hierarchical namespace feature.
Migrate your data.
Configure services in your workloads to point to your Gen2 endpoint.
For HDInsight clusters, you can add storage account configuration settings to the %HADOOP_HOME%/conf/core-site.xml file. If you plan to migrate external Hive tables from Gen1 to Gen2, then make sure to add storage account settings to the %HIVE_CONF_DIR%/hive-site.xml file as well.
You can modify the settings each file by using Apache Ambari. To find storage account settings, see Hadoop Azure Support: ABFS — Azure Data Lake Storage Gen2. This example uses the
fs.azure.account.keysetting to enable Shared Key authorization:<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>For links to articles that help you configure HDInsight, Azure Databricks, and other Azure services to use Gen2, see Azure services that support Azure Data Lake Storage Gen2.
Update applications to use Gen2 APIs. See these guides:
Update scripts to use Data Lake Storage Gen2 PowerShell cmdlets, and Azure CLI commands.
Search for URI references that contain the string
adl://in code files, or in Databricks notebooks, Apache Hive HQL files or any other file used as part of your workloads. Replace these references with the Gen2 formatted URI of your new storage account. For example: the Gen1 URI:adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfilemight becomeabfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfile.Configure the security on your account to include Azure roles, file and folder level security, and Azure Storage firewalls and virtual networks.
Step 4: Cutover from Gen1 to Gen2
After you're confident that your applications and workloads are stable on Gen2, you can begin using Gen2 to satisfy your business scenarios. Turn off any remaining pipelines that are running on Gen1 and decommission your Gen1 account.
Gen1 vs Gen2 capabilities
This table compares the capabilities of Gen1 to that of Gen2.
Gen1 to Gen2 patterns
Choose a migration pattern, and then modify that pattern as needed.
| Migration pattern | Details |
|---|---|
| Lift and Shift | The simplest pattern. Ideal if your data pipelines can afford downtime. |
| Incremental copy | Similar to lift and shift, but with less downtime. Ideal for large amounts of data that take longer to copy. |
| Dual pipeline | Ideal for pipelines that can't afford any downtime. |
| Bidirectional sync | Similar to dual pipeline, but with a more phased approach that is suited for more complicated pipelines. |
Let's take a closer look at each pattern.
Lift and shift pattern
This is the simplest pattern.
Stop all writes to Gen1.
Move data from Gen1 to Gen2. We recommend Azure Data Factory or by using the Azure portal. ACLs copy with the data.
Point ingest operations and workloads to Gen2.
Decommission Gen1.
Check out our sample code for the lift and shift pattern in our Lift and Shift migration sample.
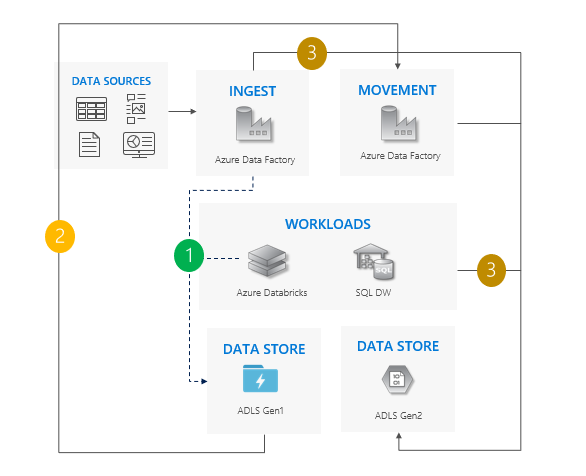
Considerations for using the lift and shift pattern
Cutover from Gen1 to Gen2 for all workloads at the same time.
Expect downtime during the migration and the cutover period.
Ideal for pipelines that can afford downtime and all apps can be upgraded at one time.
Tip
Consider using the Azure portal to shorten downtime and reduce the number of steps required by you to complete the migration.
Incremental copy pattern
Start moving data from Gen1 to Gen2. We recommend Azure Data Factory. ACLs copy with the data.
Incrementally copy new data from Gen1.
After all data is copied, stop all writes to Gen1, and point workloads to Gen2.
Decommission Gen1.
Check out our sample code for the incremental copy pattern in our Incremental copy migration sample.
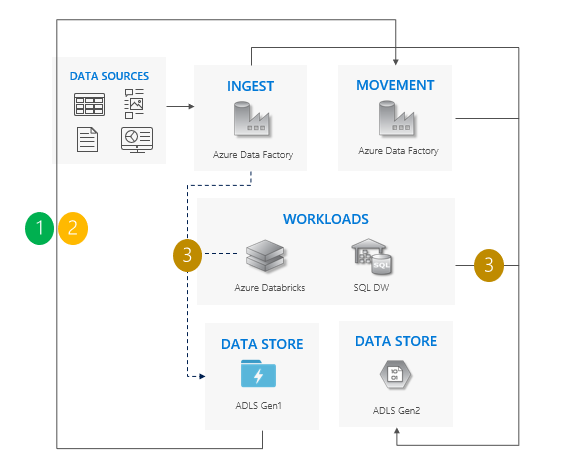
Considerations for using the incremental copy pattern
Cutover from Gen1 to Gen2 for all workloads at the same time.
Expect downtime during cutover period only.
Ideal for pipelines where all apps upgraded at one time, but the data copy requires more time.
Dual pipeline pattern
Move data from Gen1 to Gen2. We recommend Azure Data Factory. ACLs copy with the data.
Ingest new data to both Gen1 and Gen2.
Point workloads to Gen2.
Stop all writes to Gen1 and then decommission Gen1.
Check out our sample code for the dual pipeline pattern in our Dual Pipeline migration sample.
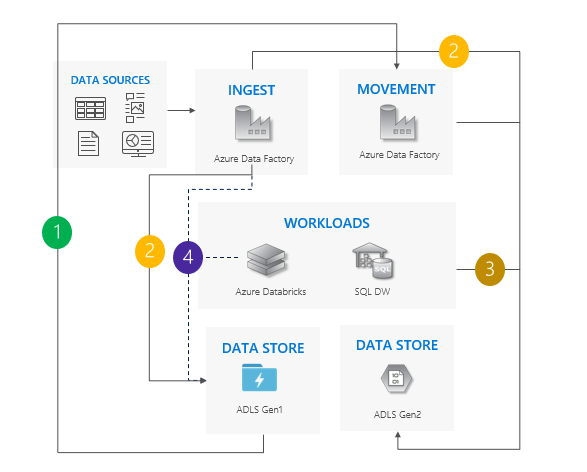
Considerations for using the dual pipeline pattern
Gen1 and Gen2 pipelines run side-by-side.
Supports zero downtime.
Ideal in situations where your workloads and applications can't afford any downtime, and you can ingest into both storage accounts.
Bi-directional sync pattern
Set up bidirectional replication between Gen1 and Gen2. We recommend WanDisco. It offers a repair feature for existing data.
When all moves are complete, stop all writes to Gen1 and turn off bidirectional replication.
Decommission Gen1.
Check out our sample code for the bidirectional sync pattern in our Bidirectional Sync migration sample.
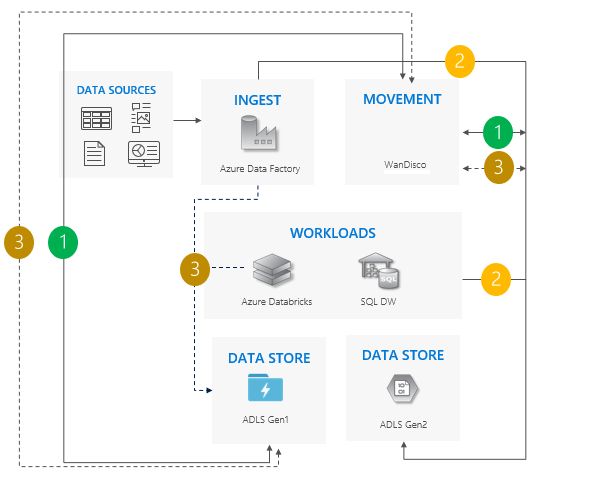
Considerations for using the bi-directional sync pattern
Ideal for complex scenarios that involve a large number of pipelines and dependencies where a phased approach might make more sense.
Migration effort is high, but it provides side-by-side support for Gen1 and Gen2.
Next steps
- Learn about the various parts of setting up security for a storage account. For more information, see Azure Storage security guide.
- Optimize the performance for your Data Lake Store. See Optimize Azure Data Lake Storage Gen2 for performance
- Review the best practices for managing your Data Lake Store. See Best practices for using Azure Data Lake Storage Gen2
See also
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for