Deploy Azure File Sync
Use Azure File Sync to centralize your organization's file shares in Azure Files, while keeping the flexibility, performance, and compatibility of an on-premises file server. Azure File Sync transforms Windows Server into a quick cache of your Azure file share. You can use any protocol that's available on Windows Server to access your data locally, including SMB, NFS, and FTPS. You can have as many caches as you need across the world.
We strongly recommend that you read Planning for an Azure Files deployment and Planning for an Azure File Sync deployment before you complete the steps described in this article.
Prerequisites
An Azure file share in the same region that you want to deploy Azure File Sync. For more information, see:
- Region availability for Azure File Sync.
- Create a file share for a step-by-step description of how to create a file share.
The following storage account settings must be enabled to allow Azure File Sync access to the storage account:
- SMB security settings must allow SMB 3.1.1 protocol version, NTLM v2 authentication and AES-128-GCM encryption. To check the SMB security settings on the storage account, see SMB security settings.
- Allow storage account key access must be Enabled. To check this setting, navigate to your storage account and select Configuration under the Settings section.
At least one supported instance of Windows Server to sync with Azure File Sync. For more information about supported versions of Windows Server and recommended system resources, see Windows file server considerations.
Optional: If you intend to use Azure File Sync with a Windows Server Failover Cluster, the File Server for general use role must be configured prior to installing the Azure File Sync agent on each node in the cluster. For more information on how to configure the File Server for general use role on a Failover Cluster, see Deploying a two-node clustered file server.
Note
The only scenario supported by Azure File Sync is Windows Server Failover Cluster with Clustered Disks. See Failover Clustering for Azure File Sync.
Although cloud management can be done with the Azure portal, advanced registered server functionality is provided through PowerShell cmdlets that are intended to be run locally in either PowerShell 5.1 or PowerShell 6+. On Windows Server 2012 R2, you can verify that you're running at least PowerShell 5.1.* by looking at the value of the PSVersion property of the $PSVersionTable object:
$PSVersionTable.PSVersionIf your PSVersion value is less than 5.1.*, you'll need to upgrade by downloading and installing Windows Management Framework (WMF) 5.1. The appropriate package to download and install for Windows Server 2012 R2 is Win8.1AndW2K12R2-KB*******-x64.msu.
PowerShell 6+ can be used with any supported system, and can be downloaded via its GitHub page.
Prepare Windows Server to use with Azure File Sync
For each server that you intend to use with Azure File Sync, including each server node in a Failover Cluster, disable Internet Explorer Enhanced Security Configuration. This is required only for initial server registration. You can re-enable it after the server has been registered.
Note
You can skip this step if you're deploying Azure File Sync on Windows Server Core.
- Open Server Manager.
- Click Local Server:
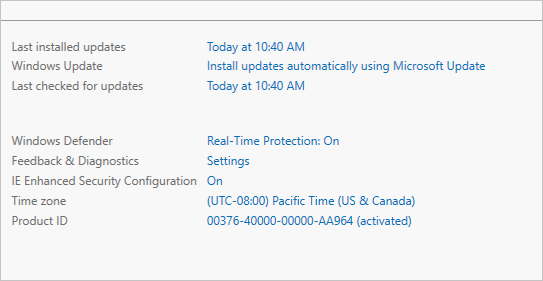
- On the Properties subpane, select the link for IE Enhanced Security Configuration.
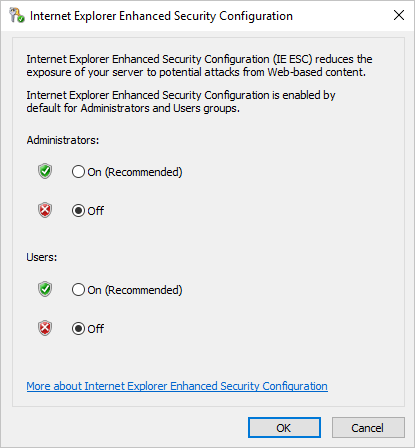
- In the Internet Explorer Enhanced Security Configuration dialog box, select Off for Administrators and Users:
Deploy the Storage Sync Service
The deployment of Azure File Sync starts with placing a Storage Sync Service resource into a resource group of your selected subscription. We recommend provisioning as few of these as needed. You'll create a trust relationship between your servers and this resource. A server can only be registered to one Storage Sync Service. As a result, we recommend deploying as many storage sync services as you need to separate groups of servers. Keep in mind that servers from different storage sync services can't sync with each other.
Note
The Storage Sync Service inherits access permissions from the subscription and resource group it has been deployed into. We recommend that you carefully check who has access to it. Entities with write access can start syncing new sets of files from servers registered to this storage sync service and cause data to flow to Azure storage that is accessible to them.
To deploy a Storage Sync Service, go to the Azure portal, select Create a resource, and then search for Azure File Sync. In the search results, select Azure File Sync, and then select Create to open the Deploy Storage Sync tab.
On the pane that opens, enter the following information:
- Name: A unique name (per region) for the Storage Sync Service.
- Subscription: The subscription in which you want to create the Storage Sync Service. Depending on your organization's configuration strategy, you might have access to one or more subscriptions. An Azure subscription is the most basic container for billing for each cloud service (such as Azure Files).
- Resource group: A resource group is a logical group of Azure resources, such as a storage account or a Storage Sync Service. You can create a new resource group or use an existing resource group for Azure File Sync. We recommend using resource groups as containers to isolate resources logically for your organization, such as grouping HR resources or resources for a specific project.
- Location: The region in which you want to deploy Azure File Sync. Only supported regions are available in this list.
When you're finished, select Create to deploy the Storage Sync Service.
Install the Azure File Sync agent
The Azure File Sync agent is a downloadable package that enables Windows Server to be synced with an Azure file share.
You can download the agent from the Microsoft Download Center. When the download is finished, double-click the MSI package to start the Azure File Sync agent installation or to silently install the agent, see How to perform a silent installation for a new Azure File Sync agent installation.
Important
If you're using Azure File Sync with a Failover Cluster, the Azure File Sync agent must be installed on every node in the cluster. Each node in the cluster must be registered to work with Azure File Sync.
We recommend that you do the following:
- Leave the default installation path (C:\Program Files\Azure\StorageSyncAgent) to simplify troubleshooting and server maintenance.
- Enable Microsoft Update to keep Azure File Sync up to date. All updates to the Azure File Sync agent, including feature updates and hotfixes, occur from Microsoft Update. We recommend installing the latest update to Azure File Sync. For more information, see Azure File Sync update policy.
When the Azure File Sync agent installation is finished, the Server Registration UI automatically opens. You must have a Storage Sync Service before registering; see the next section on how to create a Storage Sync Service.
Register Windows Server with Storage Sync Service
Registering your Windows Server with a Storage Sync Service establishes a trust relationship between your server (or cluster) and the Storage Sync Service. A server can only be registered to one Storage Sync Service and can sync with other servers and Azure file shares associated with the same Storage Sync Service.
Note
Server registration uses your Azure credentials to create a trust relationship between the Storage Sync Service and your Windows Server. Subsequently, the server creates and uses its own identity that is valid as long as the server stays registered and the current Shared Access Signature (SAS) token is valid. A new SAS token can't be issued to the server once the server is unregistered, thus removing the server's ability to access your Azure file shares, stopping any sync.
The administrator registering the server must be a member of the management roles Owner or Contributor for the given Storage Sync Service. This can be configured under Access Control (IAM) in the Azure portal for the Storage Sync Service.
It's also possible to differentiate administrators able to register servers from those allowed to also configure sync in a Storage Sync Service. To do this, you must create a custom role where you list the administrators that are only allowed to register servers and give your custom role the following permissions:
- "Microsoft.StorageSync/storageSyncServices/registeredServers/write"
- "Microsoft.StorageSync/storageSyncServices/read"
- "Microsoft.StorageSync/storageSyncServices/workflows/read"
- "Microsoft.StorageSync/storageSyncServices/workflows/operations/read"
The Server Registration UI should open automatically after the Azure File Sync agent installs. If it doesn't, you can open it manually from its file location: C:\Program Files\Azure\StorageSyncAgent\ServerRegistration.exe. When the Server Registration UI opens, select Sign-in to begin.
After you sign in, you're prompted for the following information:
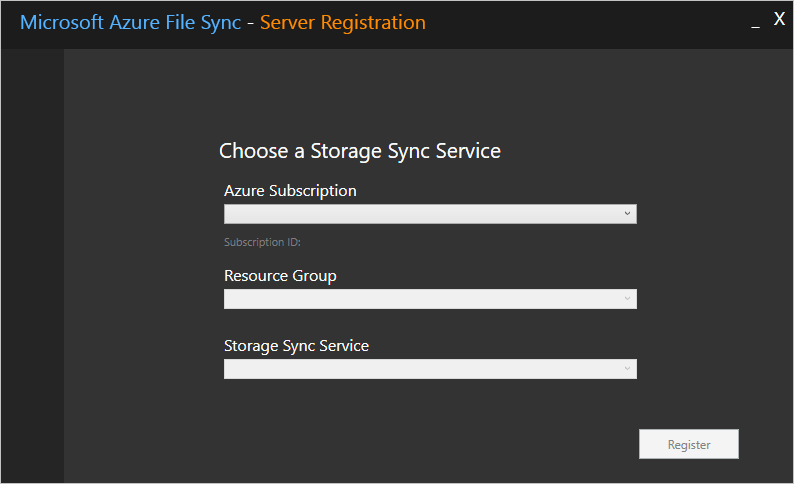
- Azure Subscription: The subscription that contains the Storage Sync Service (see Deploy the Storage Sync Service).
- Resource Group: The resource group that contains the Storage Sync Service.
- Storage Sync Service: The name of the Storage Sync Service with which you want to register.
Select the appropriate information and then select Register to complete the server registration. As part of the registration process, you're prompted for an additional sign-in.
Create a sync group and a cloud endpoint
A sync group defines the sync topology for a set of files. Endpoints within a sync group are kept in sync with each other. A sync group must contain one cloud endpoint, which represents an Azure file share and one or more server endpoints. A server endpoint represents a path on a registered server. A server can have server endpoints in multiple sync groups. You can create as many sync groups as you need to appropriately describe your desired sync topology.
A cloud endpoint is a pointer to an Azure file share. All server endpoints will sync with a cloud endpoint, making the cloud endpoint the hub. The storage account for the Azure file share must be located in the same region as the Storage Sync Service. The entirety of the Azure file share will be synced, with one exception: A special folder, comparable to the hidden "System Volume Information" folder on an NTFS volume, will be provisioned. This directory is called ".SystemShareInformation". It contains important sync metadata that won't sync to other endpoints. Don't use or delete it!
Important
You can make changes to any cloud endpoint or server endpoint in the sync group and have your files synced to the other endpoints in the sync group. If you make a change to the cloud endpoint (Azure file share) directly, changes first need to be discovered by an Azure File Sync change detection job. A change detection job is initiated for a cloud endpoint only once every 24 hours. For more information, see Azure Files frequently asked questions.
The administrator creating the cloud endpoint must be a member of the management role Owner for the storage account that contains the Azure file share the cloud endpoint is pointing to. Configure this under Access Control (IAM) in the Azure portal for the storage account.
To create a sync group, in the Azure portal, go to your Storage Sync Service, and then select + Sync group:
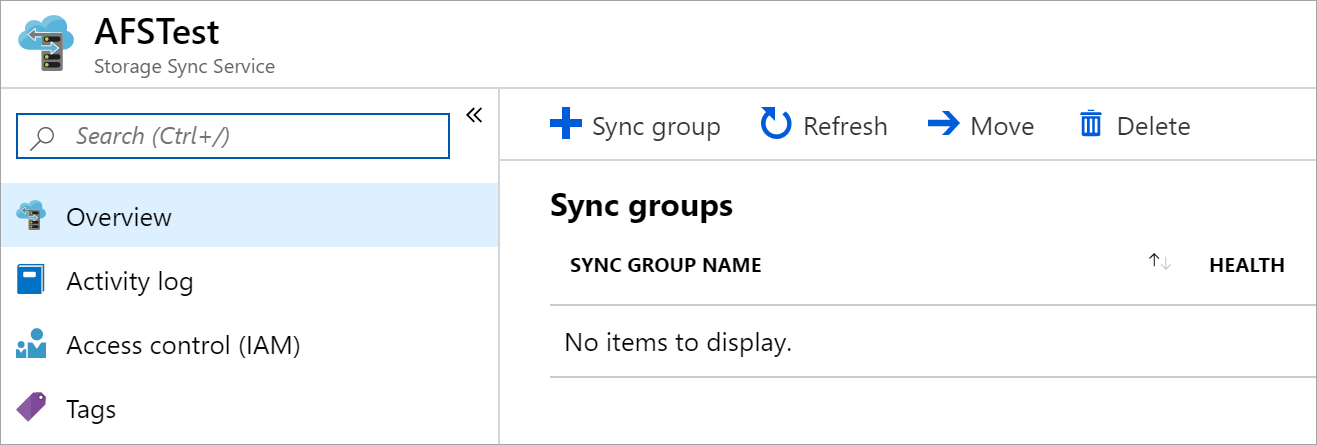
In the pane that opens, enter the following information to create a sync group with a cloud endpoint:
- Sync group name: The name of the sync group to be created. This name must be unique within the Storage Sync Service, but can be any name that is logical for you.
- Subscription: The subscription where you deployed the Storage Sync Service in Deploy the Storage Sync Service.
- Storage account: If you select Select storage account, another pane appears in which you can select the storage account that has the Azure file share that you want to sync with.
- Azure file share: The name of the Azure file share with which you want to sync.
Create a server endpoint
A server endpoint represents a specific location on a registered server, such as a folder on a server volume. A server endpoint is subject to the following conditions:
- A server endpoint must be a path on a registered server (rather than a mounted share). Network attached storage (NAS) isn't supported.
- Although the server endpoint can be on the system volume, server endpoints on the system volume can't use cloud tiering.
- Changing the path or drive letter after you established a server endpoint on a volume isn't supported. Make sure you're using a final path on your registered server.
- A registered server can support multiple server endpoints. However, a sync group can only have one server endpoint per registered server at any given time. Other server endpoints within the sync group must be on different registered servers.
To add a server endpoint, go to the newly created sync group. Under Server endpoints, select +Add server endpoint. The Add server endpoint blade opens. Enter the following information to create a server endpoint:
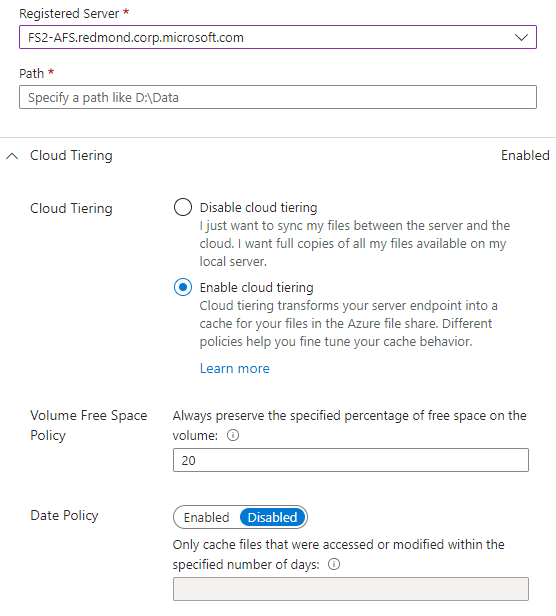
- Registered server: The name of the server or cluster where you want to create the server endpoint.
- Path: The path on the Windows Server to be synced to the Azure file share. The path can be a folder (for example, D:\Data), volume root (for example, D:\), or volume mount point (for example, D:\Mount).
- Cloud Tiering: A switch to enable or disable cloud tiering. With cloud tiering, infrequently used or accessed files can be tiered to Azure Files. When you enable cloud tiering, there are two policies that you can set to inform Azure File Sync when to tier cool files: the Volume Free Space Policy and the Date Policy.
- Volume Free Space: The amount of free space to reserve on the volume on which the server endpoint is located. For example, if volume free space is set to 50% on a volume that has only one server endpoint, roughly half the amount of data is tiered to Azure Files. Regardless of whether cloud tiering is enabled, your Azure file share always has a complete copy of the data in the sync group.
- Date Policy: Files are tiered to the cloud if they haven't been accessed (that is, read or written to) for the specified number of days. For example, if you noticed that files that have gone more than 15 days without being accessed are typically archival files, you should set your date policy to 15 days.
- Initial Sync: The Initial Sync section is available only for the first server endpoint in a sync group (section changes to Initial Download when creating more than one server endpoint in a sync group). Within the Initial Sync section, you can select the Initial Upload and Initial Download behavior.
Initial Upload: You can select how the server initially uploads the data to the Azure file share:
- Option #1: Merge the content of this server path with the content in the Azure file share. Files with the same name and path will lead to conflicts if their content is different. Both versions of those files will be stored next to each other. If your server path or Azure file share is empty, always choose this option.
- Option #2: Authoritatively overwrite files and folders in the Azure file share with content in this server’s path. This option avoids file conflicts.
To learn more, see Initial sync.
Initial Download: You can select how the server initially downloads the Azure file share data. This setting is important when the server is connecting to an Azure file share with files in it. "Namespace" stands for the file and folder structure without the file content. File content of "tiered files" is recalled from the cloud to the server by local access or policy.
- Option #1: Download the namespace first and then recall the file content, as much as will fit on the local disk.
- Option #2: Download the namespace only. The file content will be recalled when accessed.
- Option #3: Avoid tiered files. Files will only appear on the server once they're fully downloaded.
To learn more, see Initial download.
To add the server endpoint, select Create. Your files are now kept in sync across your Azure file share and Windows Server.
Note
Azure Files Sync takes a snapshot of the Azure file share as a backup before creating the server endpoint. This snapshot can be used to restore the share to the state before the server endpoint was created. The snapshot is not removed automatically after the server endpoint is created, so you can delete it manually if you don't need it. You can find the snapshots created by Azure File Sync by looking at the snapshots for the Azure file share and checking for AzureFileSync in the Initiator column.
Optional: Configure firewall and virtual network settings
Portal
If you'd like to configure Azure File Sync to work with firewall and virtual network settings, do the following:
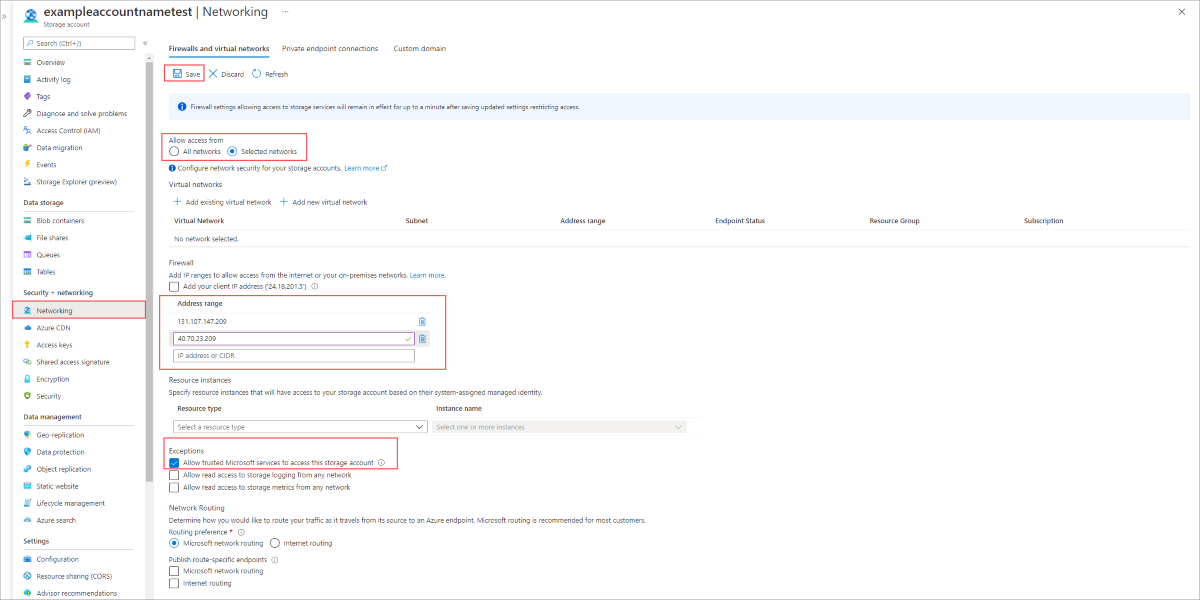
From the Azure portal, navigate to the storage account you want to secure.
Select Networking on the left menu.
Under Selected networks under Allow access from.
Make sure your servers IP or virtual network is listed under the Address range section.
Make sure Allow trusted Microsoft services to access this storage account is checked.
Select Save to save your settings.
Optional: Self-service restore through Previous Versions and VSS (Volume Shadow Copy Service)
Previous Versions is a Windows feature that allows you to utilize server-side VSS snapshots of a volume to present restorable versions of a file to an SMB client. This enables a powerful scenario, commonly referred to as self-service restore, directly for information workers instead of depending on the restore from an IT admin.
VSS snapshots and Previous Versions work independently of Azure File Sync. However, cloud tiering must be set to a compatible mode. Many Azure File Sync server endpoints can exist on the same volume. You have to make the following PowerShell call per volume that has even one server endpoint where you plan to or are using cloud tiering.
Import-Module '<SyncAgentInstallPath>\StorageSync.Management.ServerCmdlets.dll'
Enable-StorageSyncSelfServiceRestore [-DriveLetter] <string> [[-Force]]
VSS snapshots are taken of an entire volume. By default, up to 64 snapshots can exist for a given volume, as long as there's enough space to store the snapshots. VSS handles this automatically. The default snapshot schedule takes two snapshots per day, Monday through Friday. That schedule is configurable via a Windows Scheduled Task. The above PowerShell cmdlet does two things:
- It configures Azure File Sync's cloud tiering on the specified volume to be compatible with previous versions and guarantees that a file can be restored from a previous version, even if it was tiered to the cloud on the server.
- It enables the default VSS schedule. You can then decide to modify it later.
Note
There are two important things to note:
- If you use the -Force parameter, and VSS is currently enabled, then it will overwrite the current VSS snapshot schedule and replace it with the default schedule. Ensure you save your custom configuration before running the cmdlet.
- If you're using this cmdlet on a cluster node, you must also run it on all the other nodes in the cluster.
In order to see if self-service restore compatibility is enabled, you can run the following cmdlet:
Get-StorageSyncSelfServiceRestore [[-Driveletter] <string>]
It will list all volumes on the server as well as the number of cloud tiering compatible days for each. This number is automatically calculated based on the maximum possible snapshots per volume and the default snapshot schedule. So by default, all previous versions presented to an information worker can be used to restore from. The same is true if you change the default schedule to take more snapshots. However, if you change the schedule in a way that will result in an available snapshot on the volume that is older than the compatible days value, then users won't be able to use this older snapshot (previous version) to restore from.
Note
Enabling self-service restore can have an impact on your Azure storage consumption and bill. This impact is limited to files currently tiered on the server. Enabling this feature ensures that there is a file version available in the cloud that can be referenced via a previous versions (VSS snapshot) entry.
If you disable the feature, the Azure storage consumption will slowly decline until the compatible days window has passed. There is no way to speed this up.
The default maximum number of VSS snapshots per volume (64) as well as the default schedule to take them, result in a maximum of 45 days of previous versions an information worker can restore from, depending on how many VSS snapshots you can store on your volume.
If a maximum of 64 VSS snapshots per volume isn't the correct setting for you, then change that value via a registry key. For the new limit to take effect, you need to re-run the cmdlet to enable previous version compatibility on every volume it was previously enabled, with the -Force flag to take the new maximum number of VSS snapshots per volume into account. This will result in a newly calculated number of compatible days. This change will only take effect on newly tiered files and will overwrite any customizations on the VSS schedule you might have made.
VSS snapshots by default can consume up to 10% of the volume space. To adjust the amount of storage that can be used for VSS snapshots, use the vssadmin resize shadowstorage command.
Optional: Proactively recall new and changed files from an Azure file share
Azure File Sync has a mode that allows globally distributed companies to have the server cache in a remote region pre-populated even before local users access any files. When enabled on a server endpoint, this mode will cause the server to recall files that have been created or changed in the Azure file share.
Scenario
A globally distributed company has branch offices in the US and in India. In the morning (US time), information workers create a new folder and new files for a brand new project and work all day on it. Azure File Sync will sync folder and files to the Azure file share (cloud endpoint). Information workers in India will continue working on the project in their timezone. When they arrive in the morning, the local Azure File Sync enabled server in India needs to have these new files available locally, such that the India team can efficiently work off of a local cache. Enabling this mode prevents the initial file access from being slower because of on-demand recall and enables the server to proactively recall the files as soon as they're changed or created in the Azure file share.
Important
Tracking changes in the Azure file share that closely on the server can increase your egress traffic and bill from Azure. If files recalled to the server aren't actually needed locally, then unnecessary recall to the server isn't recommended. Only use this mode when you know pre-populating the cache on a server with recent changes in the cloud will have a positive effect on users or applications using the files on that server.
Enable a server endpoint to proactively recall what changed in an Azure file share
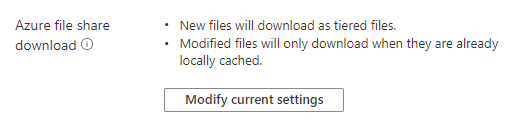
- In the Azure portal, go to your Storage Sync Service, select the correct sync group, and then identify the server endpoint for which you want to closely track changes in the Azure file share (cloud endpoint).
- In the cloud tiering section, find the Azure file share download topic. You'll see the currently selected mode, and you can change it to track Azure file share changes more closely and proactively recall them to the server.
Optional: SMB over QUIC on a server endpoint
Although the Azure file share (cloud endpoint) is a full SMB endpoint capable of direct access from the cloud or on-premises, customers that desire accessing the file share data cloud-side often deploy an Azure File Sync server endpoint on a Windows Server instance hosted on an Azure VM. The most common reason to have an additional server endpoint rather than accessing the Azure file share directly is that changes made directly on the Azure file share can take up to 24 hours or longer to be discovered by Azure File Sync, while changes made on a server endpoint are discovered nearly immediately and synced to all other server and cloud endpoints.
This configuration is extremely common in environments where a substantial portion of users are remote. Traditionally, accessing any file share with SMB over the public internet, including both file shares hosted on Windows File Server or on Azure Files directly, can be difficult because many organizations and ISPs block port 445. You can work around this limitation with private endpoints and VPNs, however Windows Server 2022 Azure Edition provides an additional access strategy: SMB over the QUIC transport protocol.
SMB over QUIC communicates over port 443, which most organizations and ISPs have open to support HTTPS traffic. Using SMB over QUIC greatly simplifies the networking required to access a file share hosted on an Azure File Sync server endpoint for clients using Windows 11 or greater. To learn more about how to setup and configure SMB over QUIC on Windows Server Azure Edition, see SMB over QUIC for Windows File Server.
Onboarding with Azure File Sync
The recommended steps to onboard on Azure File Sync for the first time with zero downtime while preserving full file fidelity and access control list (ACL) are as follows:
- Deploy a Storage Sync Service.
- Create a sync group.
- Install Azure File Sync agent on the server with the full data set.
- Register that server and create a server endpoint on the share.
- Let sync do the full upload to the Azure file share (cloud endpoint).
- After the initial upload is complete, install Azure File Sync agent on each of the remaining servers.
- Create new file shares on each of the remaining servers.
- Create server endpoints on new file shares with cloud tiering policy, if desired. (This step requires additional storage to be available for the initial setup.)
- Let Azure File Sync agent do a rapid restore of the full namespace without the actual data transfer. After the full namespace sync, sync engine will fill the local disk space based on the cloud tiering policy for the server endpoint.
- Ensure sync completes and test your topology as desired.
- Redirect users and applications to this new share.
- You can optionally delete any duplicate shares on the servers.
If you don't have extra storage for initial onboarding and would like to attach to the existing shares, you can pre-seed the data in the Azure file shares using another data transfer tool instead of using the Storage Sync Service to upload the data. The pre-seeding approach is only suggested if you can accept downtime and absolutely guarantee no data changes on the server shares during the initial onboarding process.
- Ensure that data on any of the servers can't change during the onboarding process.
- Pre-seed Azure file shares with the server data using any data transfer tool over SMB, such as Robocopy, or AzCopy over REST. If using Robocopy, make sure you mount the Azure file share(s) using the storage account access key; don't use a domain identity. If using AzCopy, be sure to set the appropriate switches to preserve ACL timestamps and attributes.
- Create Azure File Sync topology with the desired server endpoints pointing to the existing shares.
- Let sync finish reconciliation process on all endpoints.
- Once reconciliation is complete, you can open shares for changes.
Currently, pre-seeding has a few limitations:
- Data changes on the server before the sync topology is fully up and running can cause conflicts on the server endpoints.
- After the cloud endpoint is created, Azure File Sync runs a process to detect the files in the cloud before starting the initial sync. The time it takes to complete this process varies depending on factors like network speed, available bandwidth, and the number of files and folders. For the rough estimation in the preview release, the detection process runs approximately at 10 files/sec. Hence, even if pre-seeding runs fast, the overall time to get a fully running system can be significantly longer when data is pre-seeded in the cloud.
Migrate a DFS Replication (DFS-R) deployment to Azure File Sync
To migrate a DFS-R deployment to Azure File Sync:
- Create a sync group to represent the DFS-R topology you're replacing.
- Start on the server that has the full set of data in your DFS-R topology to migrate. Install Azure File Sync on that server.
- Register that server and create a server endpoint for the first server to be migrated. Don't enable cloud tiering.
- Let all of the data sync to your Azure file share (cloud endpoint).
- Install and register the Azure File Sync agent on each of the remaining DFS-R servers.
- Disable DFS-R.
- Create a server endpoint on each of the DFS-R servers. Don't enable cloud tiering.
- Ensure sync completes and test your topology as desired.
- Retire DFS-R.
- You may now enable cloud tiering on any server endpoint as desired.
For more information, see Azure File Sync interop with Distributed File System (DFS).
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for