OneLake, the OneDrive for data
OneLake is a single, unified, logical data lake for your whole organization. A data Lake processes large volumes of data from various sources. Like OneDrive, OneLake comes automatically with every Microsoft Fabric tenant and is designed to be the single place for all your analytics data. OneLake brings customers:
- One data lake for the entire organization
- One copy of data for use with multiple analytical engines
One data lake for the entire organization
Before OneLake, it was easier for customers to create multiple lakes for different business groups rather than collaborating on a single lake, even with the extra overhead of managing multiple resources. OneLake focuses on removing these challenges by improving collaboration. Every customer tenant has exactly one OneLake. There can never be more than one and if you have Fabric, there can never be zero. Every Fabric tenant automatically provisions OneLake, with no extra resources to set up or manage.
Governed by default with distributed ownership for collaboration
The concept of a tenant is a unique benefit of a SaaS service. Knowing where a customer’s organization begins and ends provides a natural governance and compliance boundary, which is under the control of a tenant admin. Any data that lands in OneLake is governed by default. While all data is within the boundaries set by the tenant admin, it's important that this admin doesn't become a central gatekeeper preventing other parts of the organization from contributing to OneLake.
Within a tenant, you can create any number of workspaces. Workspaces enable different parts of the organization to distribute ownership and access policies. Each workspace is part of a capacity that is tied to a specific region and is billed separately.
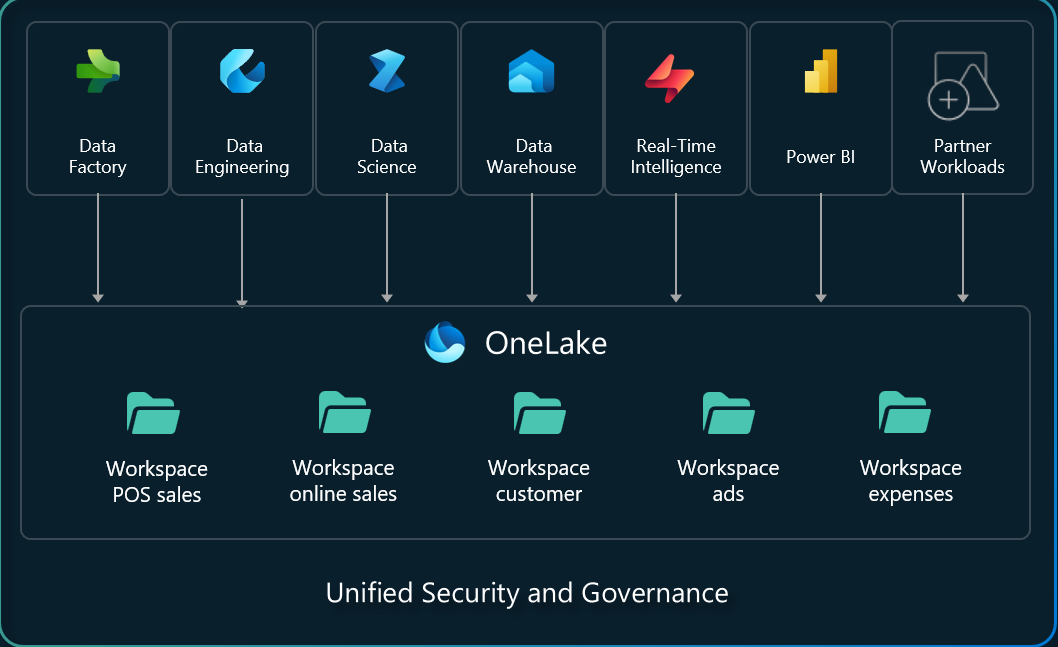
Within a workspace, you can create data items and you access all data in OneLake through data items. Similar to how Office stores Word, Excel, and PowerPoint files in OneDrive, Fabric stores lakehouses, warehouses, and other items in OneLake. Items can give tailored experiences for each persona, such the Apache Spark developer experience in a lakehouse.
For more information on how to get started using OneLake, see Creating a lakehouse with OneLake.
Open at every level
OneLake is open at every level. OneLake is built on top of Azure Data Lake Storage (ADLS) Gen2 and can support any type of file, structured or unstructured. All Fabric data items like data warehouses and lakehouses store their data automatically in OneLake in Delta Parquet format. If a data engineer loads data into a lakehouse using Apache Spark, and then a SQL developer uses T-SQL to load data in a fully transactional data warehouse, both are contributing to the same data lake. OneLake stores all tabular data in Delta Parquet format.
OneLake supports the same ADLS Gen2 APIs and SDKs to be compatible with existing ADLS Gen2 applications, including Azure Databricks. You can address data in OneLake as if it's one big ADLS storage account for the entire organization. Every workspace appears as a container within that storage account, and different data items appear as folders within those containers.

For more information on APIs and endpoints, see OneLake access and APIs. For examples of OneLake integrations with Azure, see Azure Synapse Analytics, Azure storage explorer, Azure Databricks, and Azure HDInsight articles.
OneLake file explorer for Windows
OneLake is the OneDrive for data. Just like OneDrive, you can easily explore OneLake data from Windows using the OneLake file explorer for Windows. You can navigate all your workspaces and data items, easily uploading, downloading, or modifying files just like you do in Office. The OneLake file explorer simplifies working with data lakes, allowing even nontechnical business users to use them.
For more information, see OneLake file explorer.
One copy of data
OneLake aims to give you the most value possible out of a single copy of data without data movement or duplication. You no longer need to copy data just to use it with another engine or to break down silos so you can analyze the data with data from other sources.
Shortcuts connect data across domains without data movement
Shortcuts allow your organization to easily share data between users and applications without having to move and duplicate information unnecessarily. When teams work independently in separate workspaces, shortcuts enable you to combine data across different business groups and domains into a virtual data product to fit a user’s specific needs.
A shortcut is a reference to data stored in other file locations. These file locations can be within the same workspace or across different workspaces, within OneLake or external to OneLake in ADLS, S3, or Dataverse — with more target locations coming soon. No matter the location, shortcuts make files and folders look like you have them stored locally.

For more information on how to use shortcuts, see OneLake shortcuts.
One copy of data with multiple analytical engines
While applications might have separation of storage and computing, the data is often optimized for a single engine, which makes it difficult to reuse the same data for multiple applications. With Fabric, the different analytical engines (T-SQL, Apache Spark, Analysis Services, etc.) store data in the open Delta Parquet format to allow you to use the same data across multiple engines.
There's no longer a need to copy data just to use it with another engine. You're always able to choose the best engine for the job that you're trying to do. For example, imagine you have a team of SQL engineers building a fully transactional data warehouse. They can use the T-SQL engine and all the power of T-SQL to create tables, transform data, and load the data to tables. If a data scientist wants to make use of this data, they no longer need to go through a special Spark/SQL driver. OneLake stores all data in Delta Parquet format. Data scientists can use the full power of the Spark engine and its open-source libraries directly over the data.
Business users can build Power BI reports directly on top of OneLake using the new Direct Lake mode in the Analysis Services engine. The Analysis Services engine is what powers Power BI semantic models, and it has always offered two modes of accessing data: import and direct query. Direct Lake mode gives users all the speed of import without needing to copy the data, combining the best of import and direct query. For more information, see Direct Lake.

Example diagram showing loading data using Spark, querying using T-SQL, and viewing the data in a Power BI report.