Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Microsoft Dataverse is the standard data platform for many Microsoft business application products, including Dynamics 365 Customer Engagement and Power Apps canvas apps, and also Dynamics 365 Customer Voice (formerly Microsoft Forms Pro), Power Automate approvals, Power Apps portals, and others.
This article provides guidance on how to create a Power BI data model that connects to Dataverse. It describes differences between a Dataverse schema and an optimized Power BI schema, and it provides guidance for expanding the visibility of your business application data in Power BI.
Because of its ease of setup, rapid deployment, and widespread adoption, Dataverse stores and manages an increasing volume of data in environments across organizations. That means there's an even greater need—and opportunity—to integrate analytics with those processes. Opportunities include:
- Report on all Dataverse data moving beyond the constraints of the built-in charts.
- Provide easy access to relevant, contextually filtered reports within a specific record.
- Enhance the value of Dataverse data by integrating it with external data.
- Take advantage of Power BI's built-in artificial intelligence (AI) without the need to write complex code.
- Increase adoption of Power Platform solutions by increasing their usefulness and value.
- Deliver the value of the data in your app to business decision makers.
Connect Power BI to Dataverse
Connecting Power BI to Dataverse involves creating a Power BI data model. You can choose from three methods to create a Power BI model.
- Import Dataverse data by using the Dataverse connector: This method caches (stores) Dataverse data in a Power BI model. It delivers fast performance thanks to in-memory querying. It also offers design flexibility to modelers, allowing them to integrate data from other sources. Because of these strengths, importing data is the default mode when creating a model in Power BI Desktop.
- Import Dataverse data by using Azure Synapse Link: This method is a variation on the import method, because it also caches data in the Power BI model, but does so by connecting to Azure Synapse Analytics. By using Azure Synapse Link for Dataverse, Dataverse tables are continuously replicated to Azure Synapse or Azure Data Lake Storage (ADLS) Gen2. This approach is used to report on hundreds of thousands or even millions of records in Dataverse environments.
- Create a DirectQuery connection by using the Dataverse connector: This method is an alternative to importing data. A DirectQuery model consists only of metadata defining the model structure. When a user opens a report, Power BI sends native queries to Dataverse to retrieve data. Consider creating a DirectQuery model when reports must show near real-time Dataverse data, or when Dataverse must enforce role-based security so that users can only see the data they have privileges to access.
Important
While a DirectQuery model can be a good alternative when you need near real-time reporting or enforcement of Dataverse security in a report, it can result in slow performance for that report.
You can learn about considerations for DirectQuery later in this article.
To determine the right method for your Power BI model, you should consider:
- Query performance
- Data volume
- Data latency
- Role-based security
- Setup complexity
Tip
For a detailed discussion on model frameworks (import, DirectQuery, or composite), their benefits and limitations, and features to help optimize Power BI data models, see Choose a Power BI model framework.
Query performance
Queries sent to import models are faster than native queries sent to DirectQuery data sources. That's because imported data is cached in memory and it's optimized for analytic queries (filter, group, and summarize operations).
Conversely, DirectQuery models only retrieve data from the source after the user opens a report, resulting in seconds of delay as the report renders. Additionally, user interactions on the report require Power BI to requery the source, further reducing responsiveness.
Data volume
When developing an import model, you should strive to minimize the data that's loaded into the model. It's especially true for large models, or models that you anticipate will grow to become large over time. For more information, see Data reduction techniques for import modeling.
A DirectQuery connection to Dataverse is a good choice when the report's query result isn't large. A large query result has more than 20,000 rows in the report's source tables, or the result returned to the report after filters are applied is more than 20,000 rows. In this case, you can create a Power BI report by using the Dataverse connector.
Note
The 20,000 row size isn't a hard limit. However, each data source query must return a result within 10 minutes. Later in this article you will learn how to work within those limitations and about other Dataverse DirectQuery design considerations.
You can improve the performance of larger semantic models by using the Dataverse connector to import the data into the data model.
Even larger semantic models—with several hundreds of thousand or even millions of rows—can benefit from using Azure Synapse Link for Dataverse. This approach sets up an ongoing managed pipeline that copies Dataverse data into ADLS Gen2 as CSV or Parquet files. Power BI can then query an Azure Synapse serverless SQL pool to load an import model.
Data latency
When the Dataverse data changes rapidly and report users need to see up-to-date data, a DirectQuery model can deliver near real-time query results.
Tip
You can create a Power BI report that uses automatic page refresh to show real-time updates, but only when the report connects to a DirectQuery model.
Import data models must complete a data refresh to allow reporting on recent data changes. Keep in mind that there are limitations on the number of daily scheduled data refresh operations. You can schedule up to eight refreshes per day on a shared capacity. On a Premium capacity or Microsoft Fabric capacity, you can schedule up to 48 refreshes per day, which can achieve a 15-minute refresh frequency.
Important
This article refers to Power BI Premium or its capacity subscriptions (P SKUs). Currently, Microsoft is consolidating purchase options and retiring the Power BI Premium per-capacity SKUs. New and existing customers should consider purchasing Fabric capacity subscriptions (F SKUs) instead.
For more information, see Important update coming to Power BI Premium licensing and Power BI Premium FAQ.
You can also consider using incremental refresh to achieve faster refreshes and near real-time performance (only available with Premium or Fabric).
Role-based security
When there's a need to enforce role-based security, it can directly influence the choice of Power BI model framework.
Dataverse can enforce complex role-based security to control access of specific records to specific users. For example, a salesperson might be permitted to see only their sales opportunities, while the sales manager can see all sales opportunities for all salespeople. You can tailor the level of complexity based on the needs of your organization.
A DirectQuery model based on Dataverse can connect by using the security context of the report user. That way, the report user will only see the data they're permitted to access. This approach can simplify the report design, providing performance is acceptable.
For improved performance, you can create an import model that connects to Dataverse instead. In this case, you can add row-level security (RLS) to the model, if necessary.
Note
It might be challenging to replicate some Dataverse role-based security as Power BI RLS, especially when Dataverse enforces complex permissions. Further, it might require ongoing management to keep Power BI permissions in sync with Dataverse permissions.
For more information about Power BI RLS, see Row-level security (RLS) guidance in Power BI Desktop.
Setup complexity
Using the Dataverse connector in Power BI—whether for import or DirectQuery models—is straightforward and doesn't require any special software or elevated Dataverse permissions. That's an advantage for organizations or departments that are getting started.
The Azure Synapse Link option requires system administrator access to Dataverse and certain Azure permissions. These Azure permissions are required to set up the storage account and a Synapse workspace.
Recommended practices
This section describes design patterns (and anti-patterns) you should consider when creating a Power BI model that connects to Dataverse. Only a few of these patterns are unique to Dataverse, but they tend to be common challenges for Dataverse makers when they go about building Power BI reports.
Focus on a specific use case
Rather than trying to solve everything, focus on the specific use case.
This recommendation is probably the most common and easily the most challenging anti-pattern to avoid. Attempting to build a single model that achieves all self-service reporting needs is challenging. The reality is that successful models are built to answer questions around a central set of facts over a single core topic. While that might initially seem to limit the model, it's actually empowering because you can tune and optimize the model for answering questions within that topic.
To help ensure that you have a clear understanding of the model's purpose, ask yourself the following questions.
- What topic area will this model support?
- Who is the audience of the reports?
- What questions are the reports trying to answer?
- What is the minimum viable semantic model?
Resist combining multiple topic areas into a single model just because the report user has questions across multiple topic areas that they want addressed by a single report. By breaking that report out into multiple reports, each with a focus on a different topic (or fact table), you can produce much more efficient, scalable, and manageable models.
Design a star schema
Dataverse developers and administrators who are comfortable with the Dataverse schema might be tempted to reproduce the same schema in Power BI. This approach is an anti-pattern, and it's probably the toughest to overcome because it just feels right to maintain consistency.
Dataverse, as a relational model, is well suited for its purpose. However, it's not designed as an analytic model that's optimized for analytical reports. The most prevalent pattern for modeling analytics data is a star schema design. Star schema is a mature modeling approach widely adopted by relational data warehouses. It requires modelers to classify their model tables as either dimension or fact. Reports can filter or group by using dimension table columns and summarize fact table columns.
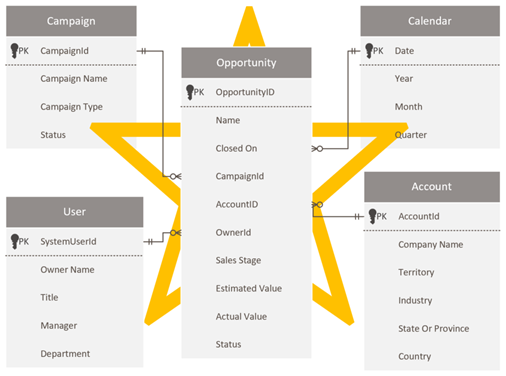
For more information, see Understand star schema and the importance for Power BI.
Optimize Power Query queries
The Power Query mashup engine strives to achieve query folding whenever possible for reasons of efficiency. A query that achieves folding delegates query processing to the source system.
The source system, in this case Dataverse, then only needs to deliver filtered or summarized results to Power BI. A folded query is often significantly faster and more efficient than a query that doesn't fold.
For more information on how you can achieve query folding, see Power Query query folding.
Note
Optimizing Power Query is a broad topic. To achieve a better understanding of what Power Query is doing at authoring and at model refresh time in Power BI Desktop, see Query diagnostics.
Minimize the number of query columns
By default, when you use Power Query to load a Dataverse table, it retrieves all rows and all columns. When you query a system user table, for example, it could contain more than 1,000 columns. The columns in the metadata include relationships to other entities and lookups to option labels, so the total number of columns grows with the complexity of the Dataverse table.
Attempting to retrieve data from all columns is an anti-pattern. It often results in extended data refresh operations, and it will cause the query to fail when the time needed to return the data exceeds 10 minutes.
We recommend that you only retrieve columns that are required by reports. It's often a good idea to reevaluate and refactor queries when report development is complete, allowing you to identify and remove unused columns. For more information, see Data reduction techniques for import modeling (Remove unnecessary columns).
Additionally, ensure that you introduce the Power Query Remove columns step early so that it folds back to the source. That way, Power Query can avoid the unnecessary work of extracting source data only to discard it later (in an unfolded step).
When you have a table that contains many columns, it might be impractical to use the Power Query interactive query builder. In this case, you can start by creating a blank query. You can then use the Advanced Editor to paste in a minimal query that creates a starting point.
Consider the following query that retrieves data from just two columns of the account table.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Write native queries
When you have specific transformation requirements, you might achieve better performance by using a native query written in Dataverse SQL, which is a subset of Transact-SQL. You can write a native query to:
- Reduce the number of rows (by using a
WHEREclause). - Aggregate data (by using the
GROUP BYandHAVINGclauses). - Join tables in a specific way (by using the
JOINorAPPLYsyntax). - Use supported SQL functions.
For more information, see:
Execute native queries with the EnableFolding option
Power Query executes a native query by using the Value.NativeQuery function.
When using this function, it's important to add the EnableFolding=true option to ensure queries are folded back to the Dataverse service. A native query won't fold unless this option is added. Enabling this option can result in significant performance improvements—up to 97 percent faster in some cases.
Consider the following query that uses a native query to source selected columns from the account table. The native query will fold because the EnableFolding=true option is set.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
You can expect to achieve the greatest performance improvements when retrieving a subset of data from a large data volume.
Tip
Performance improvement can also depend on how Power BI queries the source database. For example, a measure that uses the COUNTDISTINCT DAX function showed almost no improvement with or without the folding hint. When the measure formula was rewritten to use the SUMX DAX function, the query folded resulting in a 97 percent improvement over the same query without the hint.
For more information, see Value.NativeQuery. (The EnableFolding option isn't documented because it's specific to only certain data sources.)
Speed up the evaluation stage
If you're using the Dataverse connector (formerly known as the Common Data Service), you can add the CreateNavigationProperties=false option to speed up the evaluation stage of a data import.
The evaluation stage of a data import iterates through the metadata of its source to determine all possible table relationships. That metadata can be extensive, especially for Dataverse. By adding this option to the query, you're letting Power Query know that you don't intend to use those relationships. The option allows Power BI Desktop to skip that stage of the refresh and move on to retrieving the data.
Note
Don't use this option when the query depends on any expanded relationship columns.
Consider an example that retrieves data from the account table. It contains three columns related to territory: territory, territoryid, and territoryidname.
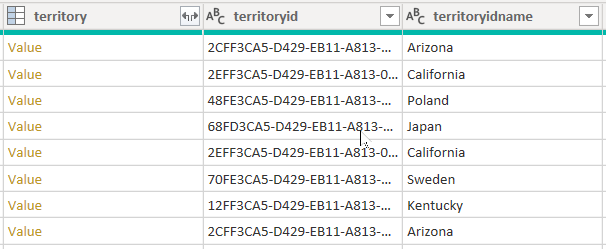
When you set the CreateNavigationProperties=false option, the territoryid and territoryidname columns will remain, but the territory column, which is a relationship column (it shows Value links), will be excluded. It's important to understand that Power Query relationship columns are a different concept to model relationships, which propagate filters between model tables.
Consider the following query that uses the CreateNavigationProperties=false option (in the Source step) to speed up the evaluation stage of a data import.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
When using this option, you're likely to experience significant performance improvement when a Dataverse table has many relationships to other tables. For example, because the SystemUser table is related to every other table in the database, refresh performance of this table would benefit by setting the CreateNavigationProperties=false option.
Note
This option can improve the performance of data refresh of import tables or dual storage mode tables, including the process of applying Power Query Editor window changes. It doesn't improve the performance of interactive cross-filtering of DirectQuery storage mode tables.
Resolve blank choice labels
If you discover that Dataverse choice labels are blank in Power BI, it could be because the labels haven't been published to the Tabular Data Stream (TDS) endpoint.
In this case, open the Dataverse Maker Portal, navigate to the Solutions area, and then select Publish all customizations. The publication process will update the TDS endpoint with the latest metadata, making the option labels available to Power BI.
Larger semantic models with Azure Synapse Link
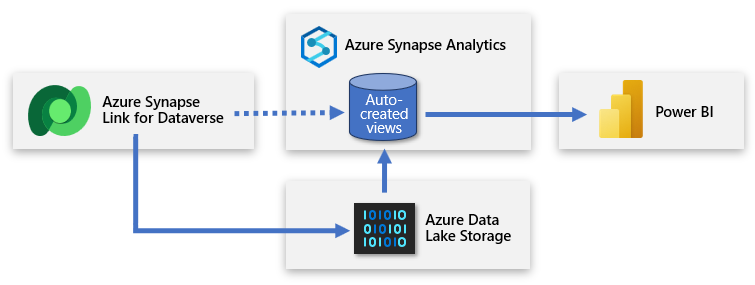
Dataverse includes the ability to synchronize tables to Azure Data Lake Storage (ADLS) and then connect to that data through an Azure Synapse workspace. With minimal effort, you can set up Azure Synapse Link to populate Dataverse data into Azure Synapse and enable data teams to discover deeper insights.
Azure Synapse Link enables a continuous replication of the data and metadata from Dataverse into the data lake. It also provides a built-in serverless SQL pool as a convenient data source for Power BI queries.
The strengths of this approach are significant. Customers gain the ability to run analytics, business intelligence, and machine learning workloads across Dataverse data by using various advanced services. Advanced services include Apache Spark, Power BI, Azure Data Factory, Azure Databricks, and Azure Machine Learning.
Create an Azure Synapse Link for Dataverse
To create an Azure Synapse Link for Dataverse, you'll need the following prerequisites in place.
- System administrator access to the Dataverse environment.
- For the Azure Data Lake Storage:
- You must have a storage account to use with ADLS Gen2.
- You must be assigned Storage Blob Data Owner and Storage Blob Data Contributor access to the storage account. For more information, see Role-based access control (Azure RBAC).
- The storage account must enable hierarchical namespace.
- It's recommended that the storage account use read-access geo-redundant storage (RA-GRS).
- For the Synapse workspace:
- You must have access to a Synapse workspace and be assigned Synapse Administrator access. For more information, see Built-in Synapse RBAC roles and scopes.
- The workspace must be in the same region as the ADLS Gen2 storage account.
The setup involves signing in to Power Apps and connecting Dataverse to the Azure Synapse workspace. A wizard-like experience allows you to create a new link by selecting the storage account and the tables to export. Azure Synapse Link then copies data to the ADLS Gen2 storage and automatically creates views in the built-in Azure Synapse serverless SQL pool. You can then connect to those views to create a Power BI model.
Tip
For complete documentation on creating, managing, and monitoring Azure Synapse Link see Create an Azure Synapse Link for Dataverse with your Azure Synapse Workspace.
Create a second serverless SQL database
You can create a second serverless SQL database and use it to add custom report views. That way, you can present a simplified set of data to the Power BI creator that allows them to create a model based on useful and relevant data. The new serverless SQL database becomes the creator's primary source connection and a friendly representation of the data sourced from the data lake.

This approach delivers data to Power BI that's focused, enriched, and filtered.
You can create a serverless SQL database in the Azure Synapse workspace by using Azure Synapse Studio. Select Serverless as the SQL database type and enter a database name. Power Query can connect to this database by connecting to the workspace SQL endpoint.
Create custom views
You can create custom views that wrap serverless SQL pool queries. These views will serve as straightforward, clean sources of data that Power BI connects to. The views should:
- Include the labels associated with choice fields.
- Reduce complexity by including only the columns required for data modeling.
- Filter out unnecessary rows, such as inactive records.
Consider the following view that retrieves campaign data.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Notice that the view includes only four columns, each aliased with a friendly name. There's also a WHERE clause to return only necessary rows, in this case active campaigns. Also, the view queries the campaign table that's joined to the OptionsetMetadata and StatusMetadata tables, which retrieve choice labels.
Tip
For more information on how to retrieve metadata, see Access choice labels directly from Azure Synapse Link for Dataverse.
Query appropriate tables
Azure Synapse Link for Dataverse ensures that data is continually synchronized with the data in the data lake. For high-usage activity, simultaneous writes and reads can create locks that cause queries to fail. To ensure reliability when retrieving data, two versions of the table data are synchronized in Azure Synapse.
- Near real-time data: Provides a copy of data synchronized from Dataverse via Azure Synapse Link in an efficient manner by detecting what data has changed since it was initially extracted or last synchronized.
- Snapshot data: Provides a read-only copy of near real-time data that's updated at regular intervals (in this case every hour). Snapshot data table names have _partitioned appended to their name.
If you anticipate that a high volume of read and write operations will be executed simultaneously, retrieve data from the snapshot tables to avoid query failures.
For more information, see Access near real-time data and read-only snapshot data.
Connect to Synapse Analytics
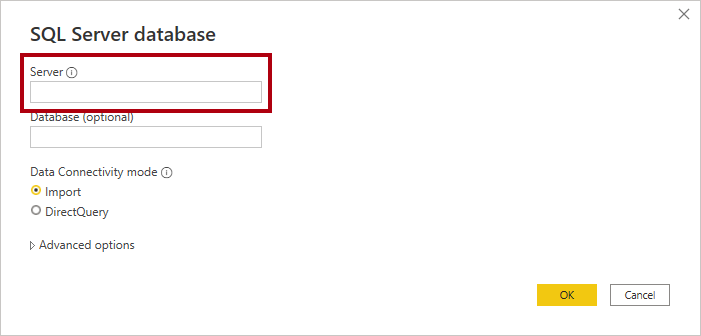
To query an Azure Synapse serverless SQL pool, you'll need its workspace SQL endpoint. You can retrieve the endpoint from Synapse Studio by opening the serverless SQL pool properties.
In Power BI Desktop, you can connect to Azure Synapse by using the Azure Synapse Analytics SQL connector. When prompted for the server, enter the workspace SQL endpoint.
Considerations for DirectQuery
There are many use cases when using DirectQuery storage mode can solve your requirements. However, using DirectQuery can negatively affect Power BI report performance. A report that uses a DirectQuery connection to Dataverse won't be as fast as a report that uses an import model. Generally, you should import data to Power BI whenever possible.
We recommend that you consider the topics in this section when working with DirectQuery.
For more information about determining when to work with DirectQuery storage mode, see Choose a Power BI model framework.
Use dual storage mode dimension tables
A dual storage mode table is set to use both import and DirectQuery storage modes. At query time, Power BI determines the most efficient mode to use. Whenever possible, Power BI attempts to satisfy queries by using imported data because it's faster.
You should consider setting dimension tables to dual storage mode, when appropriate. That way, slicer visuals and filter card lists—which are often based on dimension table columns—will render more quickly because they'll be queried from imported data.
Important
When a dimension table needs to inherit the Dataverse security model, it isn't appropriate to use dual storage mode.
Fact tables, which typically store large volumes of data, should remain as DirectQuery storage mode tables. They'll be filtered by the related dual storage mode dimension tables, which can be joined to the fact table to achieve efficient filtering and grouping.
Consider the following data model design. Three dimension tables, Owner, Account, and Campaign have a striped upper border, which means they're set to dual storage mode.
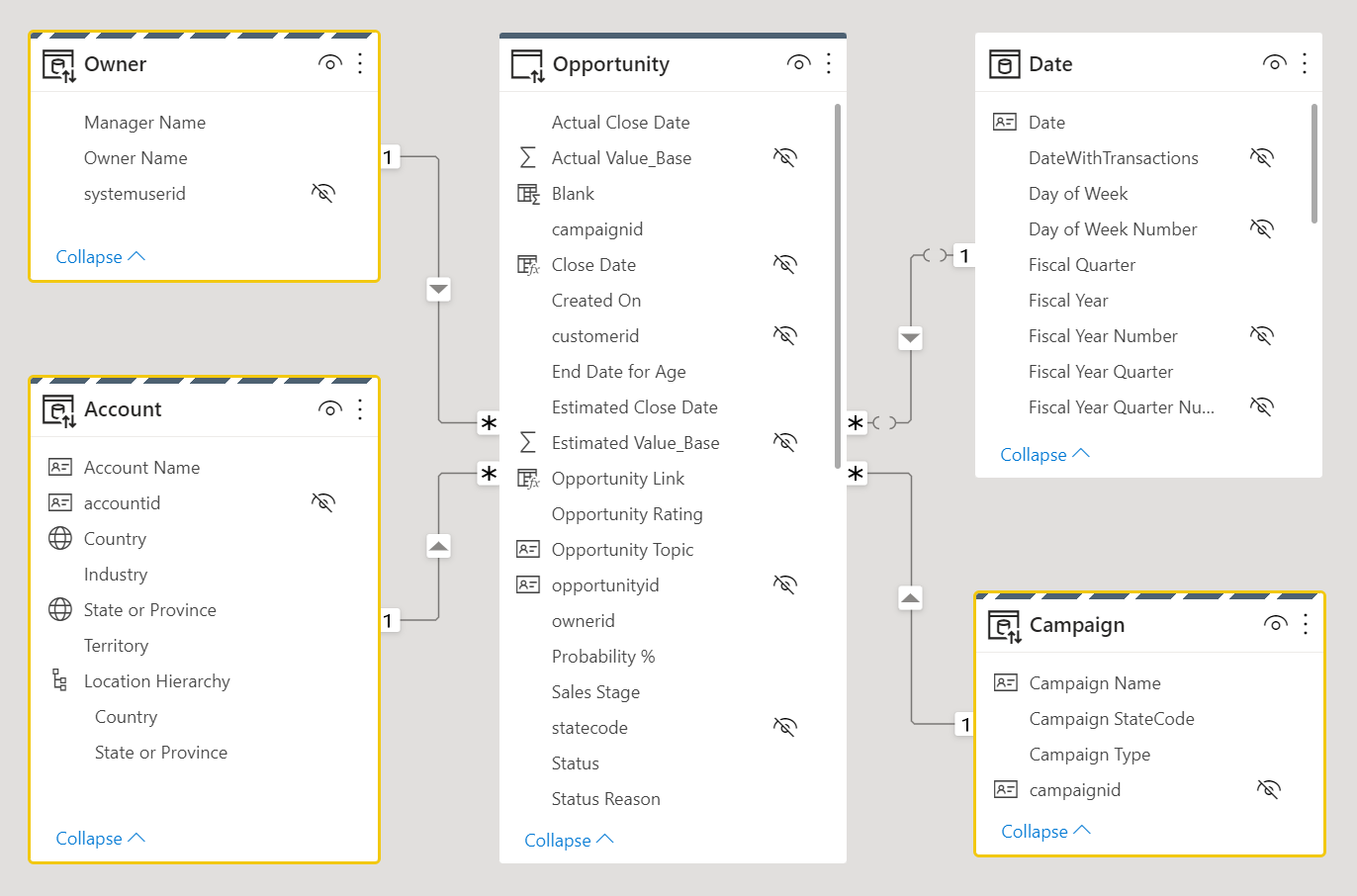
For more information on table storage modes including dual storage, see Manage storage mode in Power BI Desktop.
Enable single-sign on
When you publish a DirectQuery model to the Power BI service, you can use the semantic model settings to enable single sign-on (SSO) by using Microsoft Entra ID OAuth2 for your report users. You should enable this option when Dataverse queries must execute in the security context of the report user.
When the SSO option is enabled, Power BI sends the report user's authenticated Microsoft Entra credentials in the queries to Dataverse. This option enables Power BI to honor the security settings that are set up in the data source.
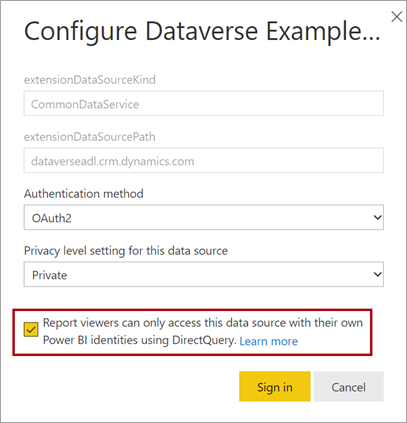
For more information, see Single sign-on (SSO) for DirectQuery sources.
Replicate "My" filters in Power Query
When using Microsoft Dynamics 365 Customer Engagement (CE) and model-driven Power Apps built on Dataverse, you can create views that show only records where a username field, like Owner, equals the current user. For example, you might create views named "My open opportunities", "My active cases", and others.
Consider an example of how the Dynamics 365 My Active Accounts view includes a filter where Owner equals current user.
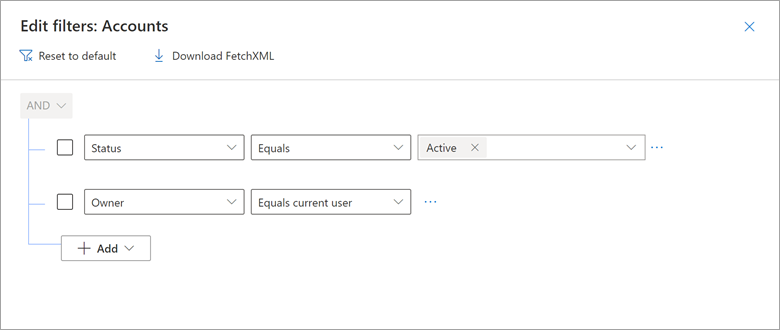
You can reproduce this result in Power Query by using a native query that embeds the CURRENT_USER token.
Consider the following example that shows a native query that returns the accounts for the current user. In the WHERE clause, notice that the ownerid column is filtered by the CURRENT_USER token.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
When you publish the model to the Power BI service, you must enable single sign-on (SSO) so that Power BI will send the report user's authenticated Microsoft Entra credentials to Dataverse.
Create supplementary import models
You can create a DirectQuery model that enforces Dataverse permissions knowing that performance will be slow. You can then supplement this model with import models that target specific subjects or audiences that could enforce RLS permissions.
For example, an import model could provide access to all Dataverse data but not enforce any permissions. This model would be suited to executives who already have access to all Dataverse data.
As another example, when Dataverse enforces role-based permissions by sales region, you could create one import model and replicate those permissions using RLS. Alternatively, you could create a model for each sales region. You could then grant read permission to those models (semantic models) to the salespeople of each region. To facilitate the creation of these regional models, you can use parameters and report templates. For more information, see Create and use report templates in Power BI Desktop.
Related content
For more information related to this article, check out the following resources.