Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Tip
Power BI Dataflow Gen1 is now in a legacy state and won't receive new feature investment. For Premium customers with Fabric access, Dataflow Gen2 is the recommended path, offering improvements in performance, scale, reliability, functionality, and built-in AI. Pro/PPU customers can continue to use Gen1 as Gen2 guidance for these scenarios is evolving. See Upgrade from Dataflow Gen1 to Dataflow Gen2 for upgrade guidance.
Power BI dataflows are an enterprise-focused data prep solution that enables an ecosystem of data that's ready for consumption, reuse, and integration. This article presents some common scenarios, links to articles, and other information to help you understand and use dataflows to their full potential.
Get access to Premium features of dataflows
Power BI dataflows in Premium capacities provide many key features that help achieve greater scale and performance for your dataflows, such as:
- Advanced compute, which accelerates ETL performance and provides DirectQuery capabilities.
- Incremental refresh, which lets you load data that's changed from a source.
- Linked entities, which you can use to reference other dataflows.
- Computed entities, which you can use to build composable building blocks of dataflows that contain more business logic.
For these reasons, we recommend that you use dataflows in a Premium capacity whenever possible. Dataflows used in a Power BI Pro license can be used for simple, small-scale use cases.
Solution
Getting access to these Premium features of dataflows is possible in two ways:
- Designate a Premium capacity to a given workspace and bring your own Pro license to author dataflows here.
- Bring your own Premium per user (PPU) license, which requires other members of the workspace to also possess a PPU license.
You can't consume PPU dataflows (or any other content) outside the PPU environment (such as in Premium or other SKUs or licenses).
For Premium capacities, your consumers of dataflows in Power BI Desktop don't need explicit licenses to consume and publish to Power BI. But to publish to a workspace or share a resulting semantic model, you need at least a Pro license.
For PPU, everyone who creates or consumes PPU content must have a PPU license. This requirement varies from the rest of Power BI in that you need to explicitly license everyone with PPU. You can't mix Free, Pro, or even Premium capacities with PPU content unless you migrate the workspace to a Premium capacity.
Choosing a model typically depends on your organization's size and goals, but the following guidelines apply.
| Team type | Premium per capacity | Premium per user |
|---|---|---|
| >5,000 users | ✔ | |
| <5,000 users | ✔ |
For small teams, PPU can bridge the gap between Free, Pro, and Premium per capacity. If you have larger needs, using a Premium capacity with users who have Pro licenses is the best approach.
Create user dataflows with security applied
Imagine that you need to create dataflows for consumption but have security requirements:
In this scenario, you likely have two types of workspaces:
Back-end workspaces where you develop dataflows and build out the business logic.
User workspaces where you want to expose some dataflows or tables to a particular group of users for consumption:
- The user workspace contains linked tables that point to the dataflows in the back-end workspace.
- Users have viewer access to the consumer workspace and no access to the back-end workspace.
- When a user uses Power BI Desktop to access a dataflow in the user workspace, they can see the dataflow. But because the dataflow appears empty in the Navigator, the linked tables don't show.
Understand linked tables
Linked tables are simply a pointer to the original dataflow tables, and they inherit the permission of the source. If Power BI allowed the linked table to use the destination permission, any user might circumvent the source permission by creating a linked table in the destination that points to the source.
Solution: Use computed tables
If you have access to Power BI Premium, you can create a computed table in the destination that refers to the linked table, which has a copy of the data from the linked table. You can remove columns through projections and remove rows through filters. The user with permission on the destination workspace can access data through this table.
Lineage for privileged individuals also shows the referenced workspace and allows users to link back to fully understand the parent dataflow. For those users who aren't privileged, privacy is still respected. Only the name of the workspace is shown.
The following diagram illustrates this setup. On the left is the architectural pattern. On the right is an example that shows sales data split and secured by region.
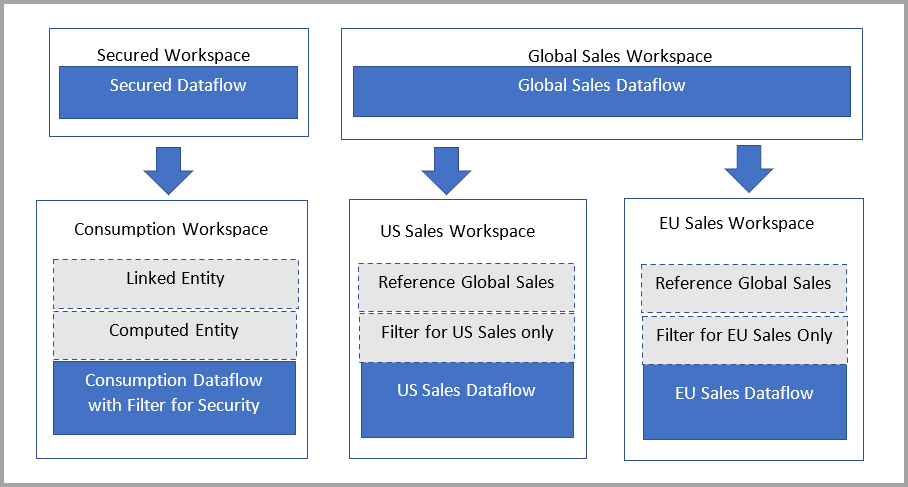
Reduce refresh times for dataflows
Imagine you have a large dataflow, but you want to build semantic models off of that dataflow and decrease the time required to refresh it. Typically, refreshes take a long time to complete from the data source to dataflows to the semantic model. Lengthy refreshes are difficult to manage or maintain.
Solution: Use tables with Enable Load explicitly configured for referenced tables and don't disable load
Power BI supports simple orchestration for dataflows, as defined in understanding and optimizing dataflows refresh. Taking advantage of orchestration requires explicitly having any downstream dataflows configured to Enable Load.
Disabling load typically is appropriate only when the overhead of loading more queries cancels the benefit of the entity with which you're developing.
While disabling load means Power BI doesn't evaluate that given query, when used as ingredients, that is, referenced in other dataflows, it also means that Power BI doesn't treat it as an existing table where we can provide a pointer to and perform folding and query optimizations. In this sense, performing transformations such as a join or merge is merely a join or merge of two data source queries. Such operations can have a negative effect on performance, because Power BI must fully reload already computed logic again and then apply any more logic.
To simplify the query processing of your dataflow and ensure any engine optimizations are taking place, enable load and ensure that the compute engine in Power BI Premium dataflows is set at the default setting, which is Optimized.
Enabling load also enables you to keep the complete view of lineage, because Power BI considers a non-enabled load dataflow as a new item. If lineage is important to you, don't disable load for entities or dataflows connected to other dataflows.
Reduce refresh times for semantic models
Imagine you have a dataflow that's large, but you want to build semantic models off of it and decrease the orchestration. Refreshes take a long time to complete from the data source to dataflows to semantic models, which adds increased latency.
Solution: Use DirectQuery dataflows
DirectQuery can be used whenever a workspace's enhanced compute engine (ECE) setting is configured explicitly to On. This setting is helpful when you have data that doesn't need to be loaded directly into a Power BI model. If you're configuring the ECE to be On for the first time, the changes that allow DirectQuery will occur during the next refresh. You need to refresh it when you enable it to have changes take place immediately. Refreshes on the initial dataflow load can be slower because Power BI writes data to both storage and a managed SQL engine.
To summarize, by using DirectQuery with dataflows enables the following enhancements to your Power BI and dataflows processes:
- Avoid separate refresh schedules: DirectQuery connects directly to a dataflow, which removes the need to create an imported semantic model. As such, by using DirectQuery with your dataflows means you no longer need separate refresh schedules for the dataflow and the semantic model to ensure your data is synchronized.
- Filtering data: DirectQuery is useful for working on a filtered view of data inside a dataflow. If you want to filter data, and in this way work with a smaller subset of the data in your dataflow, you can use DirectQuery (and the ECE) to filter dataflow data and work with the filtered subset you need.
Generally, by using DirectQuery trades up-to-date data in your semantic model with slower report performance compared to import mode. Consider this approach only when:
- Your use case requires low latency data coming from your dataflow.
- The dataflow data is large.
- An import would be too time consuming.
- You're willing to trade cached performance for up-to-date data.
Solution: Use the dataflows connector to enable query folding and incremental refresh for import
The unified Dataflows connector can significantly reduce evaluation time for steps performed over computed entities, such as performing joins, distinct, filters, and group by operations. There are two specific benefits:
- Downstream users connecting to the Dataflows connector in Power BI Desktop can take advantage of better performance in authoring scenarios because the new connector supports query folding.
- Semantic model refresh operations can also fold to the enhanced compute engine, which means even incremental refresh from a semantic model can fold to a dataflow. This capability improves refresh performance and potentially decreases latency between refresh cycles.
To enable this feature for any Premium dataflow, make sure the compute engine is explicitly set to On. Then use the Dataflows connector in Power BI Desktop. You must use the August 2021 version of Power BI Desktop or later to take advantage of this feature.
To use this feature for existing solutions, you must be on a Premium or Premium Per User subscription. You might also need to make some changes to your dataflow as described in Using the enhanced compute engine. You must update any existing Power Query queries to use the new connector by replacing PowerBI.Dataflows in the Source section with PowerPlatform.Dataflows.
Complex dataflow authoring in Power Query
Imagine you have a dataflow that's millions of rows of data, but you want to build complex business logic and transformations with it. You want to follow best practices for working with large dataflows. You also need the dataflow previews to perform quickly. But, you have dozens of columns and millions of rows of data.
Solution: Use Schema view
You can use Schema view, which is designed to optimize your flow when you work on schema-level operations by putting your query's column information front and center. Schema view provides contextual interactions to shape your data structure. Schema view also provides lower latency operations because it only requires the column metadata to be computed and not the complete data results.
Work with bigger data sources
Imagine you run a query on the source system, but you don't want to provide direct access to the system or democratize access. You plan to put it in a dataflow.
Solution 1: Use a view for the query or optimize the query
By using an optimized data source and query is your best option. Often, the data source operates best with queries intended for it. Power Query advances query-folding capabilities to delegate these workloads. Power BI also provides step-folding indicators in Power Query Online. Read more about types of indicators in the step-folding indicators documentation.
Solution 2: Use Native Query
You can also use the Value.NativeQuery() M function. You set EnableFolding=true in the third parameter. Native Query is documented on this website for the Postgres connector. It also works for the SQL Server connector.
Solution 3: Break the dataflow into ingestion and consumption dataflows to take advantage of the ECE and Linked Entities
By breaking a dataflow into separate ingestion and consumption dataflows, you can take advantage of the ECE and Linked Entities. You can learn more about this pattern and others in the best practices documentation.
Ensure customers use dataflows whenever possible
Imagine you have many dataflows that serve common purposes, such as conformed dimensions like customers, data tables, products, and geographies. Dataflows are already available in the ribbon for Power BI. Ideally, you want customers to primarily use the dataflows you created.
Solution: Use endorsement to certify and promote dataflows
To learn more about how endorsement works, see Endorsement: Promoting and certifying Power BI content.
Programmability and automation in Power BI dataflows
Imagine you have business requirements to automate imports, exports, or refreshes, and more orchestration and actions outside of Power BI. You have a few options to enable doing so, as described in the following table.
| Type | Mechanism |
|---|---|
| Use the Power Automate templates. | No-code |
| Use automation scripts in PowerShell. | Automation scripts |
| Build your own business logic by using the APIs. | Rest API |
For more information about refresh, see Understanding and optimizing dataflows refresh.
Ensure you protect data assets downstream
You can use sensitivity labels to apply a data classification and any rules you configured on downstream items that connect to your dataflows. To learn more about sensitivity labels, see sensitivity labels in Power BI. To review inheritance, see Sensitivity label downstream inheritance in Power BI.
Multi-geo support
Many customers today have a need to meet data sovereignty and residency requirements. You can complete a manual configuration to your dataflows workspace to be multi-geo.
Dataflows support multi-geo when they use the bring-your-own-storage-account feature. This feature is described in Configuring dataflow storage to use Azure Data Lake Gen 2. The workspace must be empty prior to attach for this capability. With this specific configuration, you can store dataflow data in specific geo regions of your choice.
Ensure you protect data assets behind a virtual network
Many customers today have a need to secure your data assets behind a private endpoint. To do so, use virtual networks and a gateway to stay compliant. The following table describes the current virtual network support and explains how to use dataflows to stay compliant and protect your data assets.
| Scenario | Status |
|---|---|
| Read virtual network data sources through an on-premises gateway. | Supported through an on-premises gateway |
| Write data to a sensitivity label account behind a virtual network by using an on-premises gateway. | Not yet supported |
Related content
The following articles provide more information about dataflows and Power BI: