Supervisión de la calidad y seguridad de las aplicaciones de flujo de avisos implementadas
La supervisión de modelos que se implementan en producción es una parte esencial del ciclo de vida de la aplicación de inteligencia artificial generativa. Los cambios en los datos y en el comportamiento de los consumidores pueden influir en su aplicación a lo largo del tiempo, dando lugar a sistemas obsoletos que afectan negativamente a los resultados empresariales y exponen a las organizaciones a riesgos de cumplimiento, económicos y de reputación.
La supervisión de modelo de Azure AI para aplicaciones de inteligencia artificial generativa facilita la supervisión de la seguridad y la calidad de las aplicaciones en producción con una cadencia que garantice que está aportando el máximo valor empresarial.
Entre las funcionalidades e integraciones para supervisar una implementación de flujo de avisos se incluyen las siguientes:
- Recopilar datos de producción mediante el recopilador de datos de modelos.
- Aplicar métricas de evaluación de inteligencia artificial responsable, como la fundamentación, la coherencia, la fluidez, la relevancia y la similitud, que son interoperables con las métricas de evaluación del flujo de avisos.
- Alertas preconfiguradas y valores predeterminados para ejecutar la supervisión de forma periódica.
- Consumir el resultado y configurar el comportamiento avanzado en Inteligencia artificial de Inteligencia artificial de Azure Studio.
Configurar la supervisión del flujo de avisos
Siga estos pasos para configurar la supervisión de la implementación del flujo de avisos:
Confirme que el flujo se ejecute correctamente y que las entradas y salidas necesarias estén configuradas para las métricas que desea evaluar. Los parámetros mínimos necesarios para recopilar solo entradas y salidas proporcionan dos métricas: coherencia y fluidez. Debe configurar su flujo de acuerdo con los requisitos de configuración de flujos y métricas.
Implemente el flujo. De manera predeterminada, la recopilación de datos de inferencia y la información de la aplicación se habilitan automáticamente. Son necesarias para la creación del monitor.
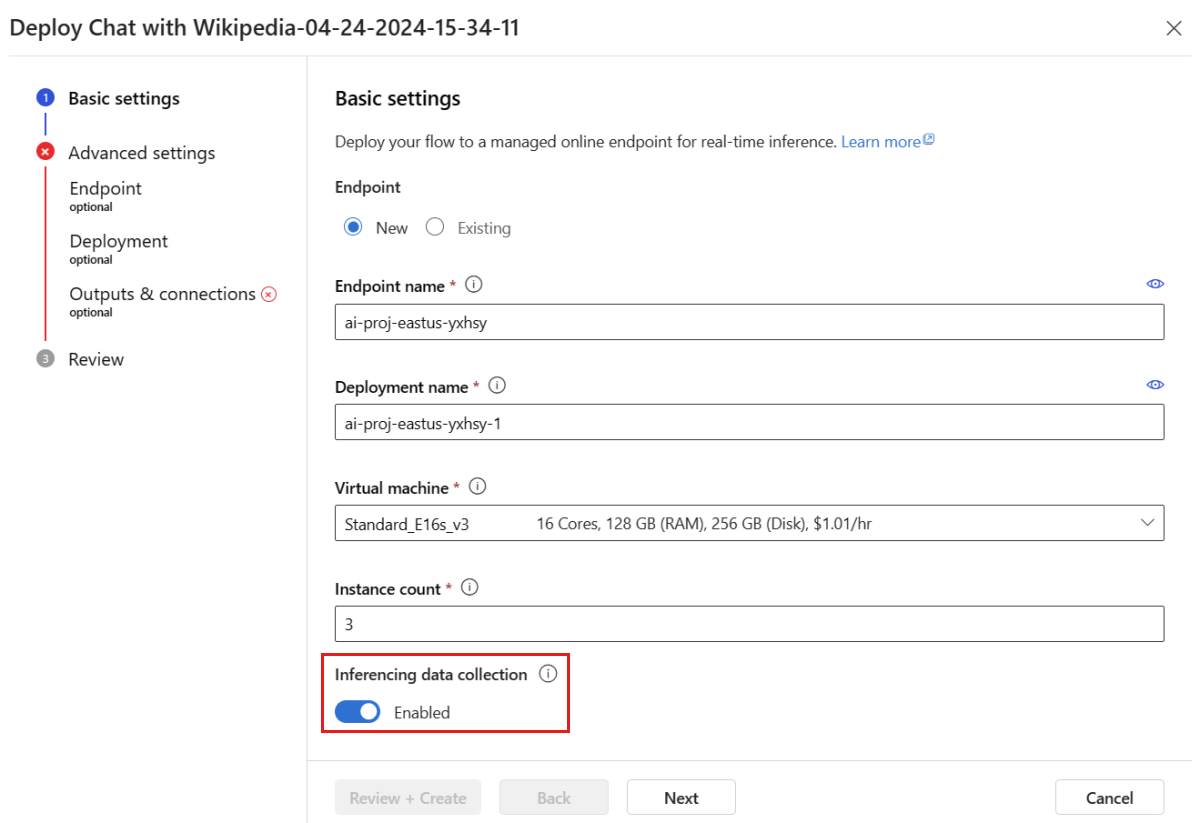
De manera predeterminada, todas las salidas de la implementación se recopilan mediante el recopilador de datos de modelos de Azure AI. Como paso opcional, puede especificar la configuración avanzada para confirmar que las columnas deseadas (por ejemplo, el contexto de la verdad fundamental) se incluyen en la respuesta del punto de conexión.
El flujo implementado debe configurarse de la siguiente manera:
Entradas y salidas de flujos: tiene que asignar un nombre adecuado a las salidas del flujo y recordar estos nombres de columna al crear el monitor. En este artículo, se usa la siguiente configuración:
- Entradas (obligatorias): "prompt"
- Salidas (obligatorias): "completion"
- Salidas (opcionales): "contexto" o "verdad fundamental"
Recopilación de datos: el botón de alternancia de recopilación de datos de referencia debe habilitarse usando el recopilador de datos del modelo
Salidas: en el asistente para la implementación del flujo de avisos, confirme que se han seleccionado las salidas necesarias (como finalización, contexto y ground_truth) que cumplen los requisitos de configuración de sus métricas.
Pruebe la implementación en la pestaña Prueba de la implementación.

Nota:
La supervisión requiere que el punto de conexión se use al menos 10 veces para recopilar datos suficientes para proporcionar información. Si quiere probar antes, envíe manualmente aproximadamente 50 filas en la pestaña "prueba" antes de ejecutar el monitor.
Para crear el monitor, habilite desde la página de detalles de implementación o la pestaña Supervisión.

Asegúrese de que las columnas se asignen desde el flujo tal como se define en los requisitos anteriores.

Vea el monitor en la pestaña Monitor.
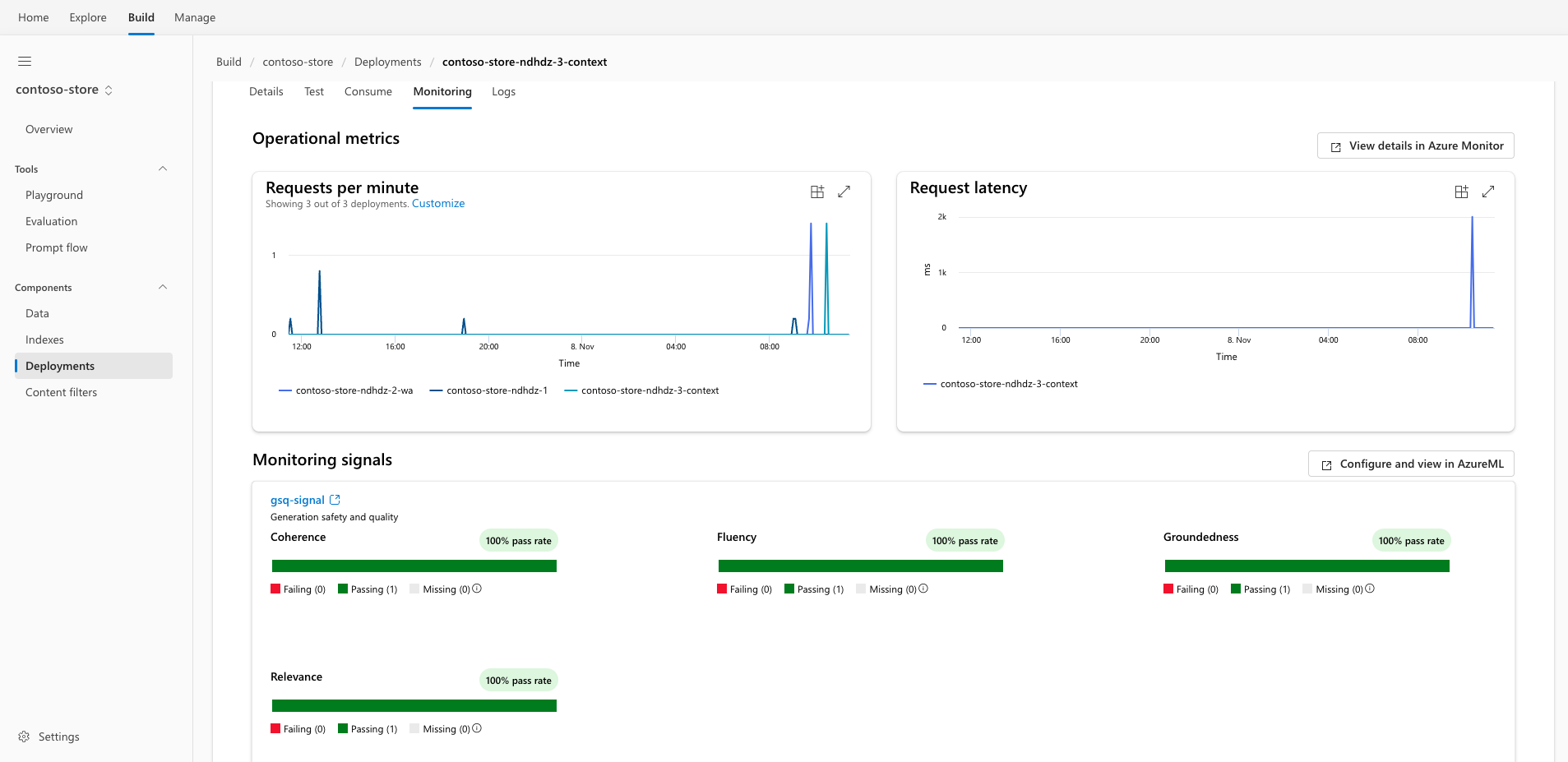






De manera predeterminada, se muestran métricas operativas como solicitudes por minuto y latencia de solicitud. La señal de seguridad y supervisión de calidad predeterminada se configura con una frecuencia de muestreo del 10 % y se ejecuta en la conexión predeterminada de Azure Open AI del área de trabajo.
El monitor se crea con la configuración predeterminada:
- Frecuencia de muestreo de 10 %
- 4/5 (umbrales/periodicidad)
- Periodicidad semanal el lunes por la mañana
- Las alertas se entregan a la bandeja de entrada de la persona que desencadenó el monitor.
Para ver más detalles sobre las métricas de supervisión, puede seguir el vínculo para ir a la supervisión en Estudio de Azure Machine Learning, que es un estudio independiente que permite más personalizaciones.
Métricas de evaluación
Las métricas se generan mediante los siguientes modelos de lenguaje GPT de última generación configurados con instrucciones de evaluación específicas (plantillas de solicitud) que actúan como modelos de evaluador para tareas de secuencia en secuencia. Esta técnica presenta resultados empíricos sólidos y una alta correlación con el juicio humano en comparación con las métricas de evaluación de la IA generativa estándar. Para más información sobre la evaluación del flujo de avisos, consulte Envío de pruebas masivas y evaluación de un flujo y Métricas de evaluación y supervisión para la inteligencia artificial generativa.
Estos modelos GPT se admiten, y se configurarán como su recurso de Azure OpenAI:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Se admiten las siguientes métricas para supervisión:
| Métrica | Descripción |
|---|---|
| Base | Mide lo bien que se alinean las respuestas generadas por el modelo con la información de los datos de origen (contexto definido por el usuario). |
| Relevancia | Evalúa la medida en que las respuestas generadas del modelo son pertinentes y directamente relacionadas con las preguntas formuladas. |
| Coherencia | Mide hasta qué punto las respuestas generadas por el modelo son lógicamente coherentes y están conectadas. |
| Fluidez | Mide la competencia gramatical de la respuesta predicha por una inteligencia artificial generativa. |
| Similitud | Mide la similitud entre una frase de datos de origen (verdad fundamental) y la respuesta generada por un modelo de inteligencia artificial. |
Requisitos de configuración de flujo y métricas
Al crear el flujo, debe asegurarse de que se asignen los nombres de columna. Los siguientes nombres de columnas de datos de entrada son necesarios para medir la seguridad y la calidad de la generación:
| Nombre de columna de entrada | Definición | Obligatorio |
|---|---|---|
| Texto de solicitud | La solicitud original especificada (también conocida como "entradas" o "pregunta") | Obligatorio |
| API de finalización | La finalización de la llamada API que se devuelve (también conocida como "salidas" o "respuesta") | Obligatorio |
| Texto de contexto | Los datos de contexto que se envían a la llamada API, junto con la solicitud original. Por ejemplo, si espera obtener resultados de búsqueda solo de determinados orígenes de información o sitios web certificados, puede definirlo en los pasos de evaluación. | Opcionales |
| Texto de verdad fundamental | Texto definido por el usuario como el "verdad fundamental" | Opcional |
Los parámetros que se configuran en el recurso de datos determinan qué métricas puede generar, según esta tabla:
| Métrica | Prompt | Completion | Context | Cierto |
|---|---|---|---|---|
| Coherencia | Obligatorio | Obligatorio | - | - |
| Fluidez | Obligatorio | Obligatorio | - | - |
| Base | Obligatorio | Obligatorio | Obligatorio | - |
| Relevancia | Obligatorio | Obligatorio | Obligatorio | - |
| Similitud | Obligatorio | Obligatorio | - | Obligatorio |
Para más información, consulte los requisitos de métricas de respuesta a preguntas.
Pasos siguientes
- Más información sobre lo que puede hacer en Inteligencia artificial de Azure Studio
- Obtenga respuestas a las preguntas más frecuentes en el artículo preguntas más frecuentes sobre Azure AI.