Nota
Este artículo se basa en una biblioteca de código abierto hospedada en GitHub en: https://github.com/mspnp/spark-monitoring.
La biblioteca original admite Azure Databricks Runtimes 10.x (Spark 3.2.x) y versiones anteriores.
Databricks ha contribuido a una versión actualizada para admitir Azure Databricks Runtimes 11.0 (Spark 3.3.x) y versiones posteriores en la rama de l4jv2 en: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Tenga en cuenta que la versión 11.0 no es compatible con la versión anterior debido a los diferentes sistemas de registro usados en los runtimes de Databricks. Asegúrese de usar la compilación correcta para Databricks Runtime. La biblioteca y el repositorio de GitHub están en modo de mantenimiento. No hay planes para versiones adicionales y el soporte técnico es la mejor opción. Para cualquier pregunta adicional sobre la biblioteca o la hoja de ruta para supervisar y registrar los entornos de Azure Databricks, póngase en contacto con azure-spark-monitoring-help@databricks.com.
En esta solución se demuestran los patrones y métricas de observabilidad para mejorar el rendimiento de procesamiento de un sistema de macrodatos que usa Azure Databricks.
Architecture

Descargue un archivo Visio de esta arquitectura.
Flujo de trabajo
Esta solución implica los pasos siguientes:
El servidor envía un archivo GZIP grande agrupado por el cliente a la carpeta de origen en Azure Data Lake Storage.
A continuación, Data Lake Storage envía un archivo de cliente extraído correctamente a Azure Event Grid, que convierte los datos de archivo del cliente en varios mensajes.
Azure Event Grid envía los mensajes al servicio Azure Queue Storage, que los almacena en una cola.
Azure Queue Storage envía la cola a la plataforma de análisis de datos de Azure Databricks para su procesamiento.
Azure Databricks desempaqueta y procesa los datos en cola en un archivo procesado que devuelve a Data Lake Storage:
Si el archivo procesado es válido, entrará en la carpeta Landing.
De lo contrario, el archivo se queda en el árbol de carpetas Bad. Inicialmente, el archivo entra en la subcarpeta Retry y Data Lake Storage vuelve a intentar el procesamiento de archivos de cliente (paso 2). Si, después de un par de reintentos, Azure Databricks sigue devolviendo archivos procesados que no son válidos, el archivo procesado se envía a la subcarpeta Failure.
A medida que Azure Databricks desempaqueta y procesa los datos del paso anterior, también envía métricas y registros de aplicaciones a Azure Monitor para su almacenamiento.
Un área de trabajo de Azure Log Analytics aplica consultas de Kusto en las métricas y registros de aplicaciones de Azure Monitor para solucionar problemas y realizar diagnósticos profundos.
Componentes
- Azure Data Lake Storage es un conjunto de funcionalidades dedicado al análisis de macrodatos.
- Azure Event Grid permite a los desarrolladores crear fácilmente aplicaciones con arquitecturas basadas en eventos.
- Azure Queue Storage es un servicio para almacenar grandes cantidades de mensajes, Permite acceder a mensajes desde cualquier lugar del mundo mediante llamadas autenticadas con HTTP o HTTPS. Puede usar colas para crear un trabajo pendiente del trabajo que se va a procesar de forma asincrónica.
- Azure Databricks es una plataforma de análisis de datos optimizada para la plataforma en la nube de Azure. Uno de los dos entornos que ofrece Azure Databricks para desarrollar aplicaciones con un uso intensivo de datos es el área de trabajo de Azure Databricks, un motor de análisis unificado basado en Apache Spark para el procesamiento de datos a gran escala.
- Azure Monitor recopila y analiza la telemetría de la aplicación, como las métricas de rendimiento y los registros de actividad.
- Azure Log Analytics es una herramienta que se usa para editar y ejecutar consultas con datos.
Detalles del escenario
El equipo de desarrollo puede usar métricas y patrones de observabilidad para detectar cuellos de botella y mejorar el rendimiento de un sistema de macrodatos. El equipo tiene que realizar pruebas de carga de una secuencia de métricas de alto volumen en una aplicación a gran escala.
En este escenario se ofrecen instrucciones para el ajuste del rendimiento. Dado que este escenario presenta un desafío de rendimiento para el registro por cliente, se usa Azure Databricks, que puede supervisar estos elementos de forma sólida:
- Métricas personalizadas de la aplicación
- Eventos de consulta de streaming
- Mensajes del registro de aplicaciones
Azure Databricks puede enviar estos datos de supervisión a distintos servicios de registro, como Azure Log Analytics.
En este escenario se describe la ingesta de un gran conjunto de datos agrupados por cliente y almacenados en un archivo de almacenamiento GZIP. Los registros detallados no están disponibles en Azure Databricks fuera de la interfaz de usuario de Apache Spark™ en tiempo real, por lo que el equipo necesita una forma de almacenar todos los datos para cada cliente y, a continuación, establecer puntos de referencia y compararlos. Con un escenario de datos de gran tamaño, es importante encontrar la combinación óptima de grupo de ejecutores y tamaño de máquina virtual (VM) para lograr el tiempo de procesamiento más rápido posible. En este escenario empresarial, la aplicación general se basa en la velocidad de ingesta y los requisitos de consulta a fin de que el rendimiento del sistema no se vea degradado inesperadamente cuando aumente el volumen de trabajo. El escenario debe garantizar que el sistema cumple los Acuerdos de Nivel de Servicio (SLA) establecidos con los clientes.
Posibles casos de uso
Estos son algunos de los escenarios que pueden beneficiarse de esta solución:
- Seguimiento de estado del sistema.
- Mantenimiento del rendimiento.
- Supervisión del uso diario del sistema.
- Detección de tendencias que podrían provocar problemas en el futuro si no se corrigen.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Tenga en cuenta estos aspectos al considerar esta arquitectura:
Azure Databricks puede asignar automáticamente los recursos informáticos necesarios para un trabajo grande, lo que evita los problemas que presentan otras soluciones. Por ejemplo, con el escalado automático optimizado para Databricks en Apache Spark, un aprovisionamiento excesivo puede generar un uso de los recursos inferior al óptimo. O bien, es posible que no conozca el número de ejecutores necesarios para un trabajo.
Un mensaje de la cola de Azure Queue Storage puede tener un tamaño máximo de 64 KB. Una cola puede contener millones de mensajes, hasta el límite de capacidad total de una cuenta de almacenamiento.
Optimización de costos
La optimización de costos trata de buscar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para más información, vea Información general del pilar de optimización de costos.
Use la calculadora de precios de Azure para estimar el costo de la implementación de esta solución.
Implementación de este escenario
Nota
Los pasos de implementación que se describen aquí solo se aplican a Azure Databricks, Azure Monitor y Azure Log Analytics. En este artículo no se describe la implementación del resto de componentes.
Para obtener todos los registros y la información del proceso, configure Azure Log Analytics y la biblioteca de supervisión de Azure Databricks. La biblioteca de supervisión transmite los eventos de nivel de Apache Spark y las métricas de Spark Structured Streaming de los trabajos a Azure Monitor. No es necesario realizar ningún cambio en el código de aplicación para estos eventos y métricas.
Los pasos para configurar el ajuste del rendimiento de un sistema de macrodatos son los siguientes:
En Azure Portal, cree un área de trabajo de Azure Databricks. Copie y guarde el identificador de suscripción de Azure (un identificador único global (GUID)), el nombre del grupo de recursos, el nombre del área de trabajo de Databricks y la dirección URL del portal de dicha área para usarlos más tarde.
En un explorador web, vaya a la dirección URL del área de trabajo de Databricks y genere un token de acceso personal de Databricks. Copie y guarde la cadena de token que aparece (que comienza con
dapiy un valor hexadecimal de 32 caracteres) para usarla más tarde.Clone el repositorio de GitHub mspnp/spark-monitoring en el equipo local. Este repositorio tiene el código fuente de los siguientes componentes:
- La plantilla de Azure Resource Manager (plantilla de ARM) para crear un área de trabajo de Azure Log Analytics, que también instala consultas precompiladas para recopilar métricas de Spark
- Bibliotecas de supervisión de Azure Databricks
- La aplicación de ejemplo para enviar métricas y registros de aplicaciones de Azure Databricks a Azure Monitor
Use el comando de la CLI de Azure para implementar una plantilla de ARM y cree un área de trabajo de Azure Log Analytics con consultas de métricas de Spark predefinidas. En la salida del comando, copie y guarde el nombre generado para la nueva área de trabajo de Log Analytics (con el formato spark-monitoring-<cadena-aleatoria>).
En Azure Portal, copie y guarde la clave y el identificador del área de trabajo de Log Analytics para usarlos más tarde.
Instale la edición Community de IntelliJ IDEA, un entorno de desarrollo integrado (IDE) que tiene compatibilidad integrada con el Kit de desarrollo de Java (JDK) y Apache Maven. Agregue el complemento de Scala.
Con IntelliJ IDEA, compile las bibliotecas de supervisión de Azure Databricks. Para realizar el paso de compilación real, seleccione Ver>Ventanas de herramientas>Maven para mostrar la ventana de herramientas de Maven y, a continuación, seleccione Ejecutar objetivo de Maven>mvn package.
Mediante una herramienta de instalación de paquetes de Python, instale la CLI de Azure Databricks y configure la autenticación con el token de acceso personal de Databricks que copió antes.
Configure el área de trabajo de Azure Databricks modificando el script init de Databricks con los valores de Databricks y Log Analytics que copió antes. Después use la CLI de Azure Databricks para copiar el script init y las bibliotecas de supervisión de Azure Databricks en el área de trabajo de Databricks.
En el portal del área de trabajo de Databricks, cree y configure un clúster de Azure Databricks.
En IntelliJ IDEA, compile la aplicación de ejemplo con Maven. Después, en el portal del área de trabajo de Databricks, ejecute la aplicación de ejemplo para generar registros y métricas de muestra para Azure Monitor.
Mientras el trabajo de ejemplo se ejecuta en Azure Databricks, vaya a Azure Portal para ver y consultar los tipos de eventos (registros y métricas de la aplicación) en la interfaz de Log Analytics:
- Seleccione Tablas>Registros personalizados para ver el esquema de tabla de eventos de escucha de Spark (SparkListenerEvent_CL), eventos de registro de Spark (SparkLoggingEvent_CL) y métricas de Spark (SparkMetric_CL).
- Seleccione Explorador de consultas>Consultas guardadas>Métricas de Spark para ver y ejecutar las consultas que se agregaron al crear el área de trabajo de Log Analytics.
Obtenga más información sobre cómo ver y ejecutar consultas predefinidas y personalizadas en la sección siguiente.
Consultar los registros y las métricas en Azure Log Analytics
Acceso a consultas predefinidas
A continuación se enumeran los nombres de consultas predefinidas para recuperar métricas de Spark.
- % de tiempo de CPU por ejecutor
- % de tiempo de deserialización por ejecutor
- % de tiempo de JVM por ejecutor
- % de tiempo de deserialización por ejecutor
- Bytes de disco volcados
- Seguimientos de errores (registros incorrectos o archivos no válidos)
- Bytes del sistema de archivos leídos por ejecutor
- Bytes del sistema de archivos escritos por ejecutor
- Errores de trabajo por trabajo
- Latencia de trabajo por trabajo (duración del lote)
- Rendimiento del trabajo
- Ejecución de ejecutores
- Bytes de contenido aleatorio leídos
- Bytes de contenido aleatorio leídos por ejecutor
- Bytes de contenido aleatorio leídos en disco por ejecutor
- Memoria directa de cliente de contenido aleatorio
- Memoria de cliente de contenido aleatorio por ejecutor
- Bytes de disco de contenido aleatorio volcados por ejecutor
- Memoria de montón de contenido aleatorio por ejecutor
- Bytes de memoria de contenido aleatorio volcados por ejecutor
- Latencia de fase por fase (duración de la fase)
- Rendimiento de la fase por fase
- Errores de streaming por flujo
- Latencia de streaming por flujo
- Filas de entrada/s de rendimiento de streaming
- Filas procesadas/s de rendimiento de streaming
- Suma de ejecución de tareas por host
- Tiempo de deserialización de tareas
- Errores de tarea por fase
- Tiempo de proceso del ejecutor de tareas (tiempo de asimetría de datos)
- Bytes de entrada de tarea leídos
- Latencia de tarea por fase (duración de las tareas)
- Tiempo de serialización del resultado de la tarea
- Latencia de retraso del Programador de tareas
- Bytes de tareas aleatorias leídos
- Bytes de tareas aleatorias escritos
- Tiempo de lectura de tareas aleatorias
- Tiempo de escritura de tareas aleatorias
- Rendimiento de tareas (suma de tareas por fase)
- Tareas por ejecutor (suma de tareas por ejecutor)
- Tareas por fase
Creación de consultas personalizadas
También puede escribir sus propias consultas en lenguaje de consulta de Kusto (KQL). Solo tiene que seleccionar el panel superior central, que es editable, y personalizar la consulta para que se ajuste a sus necesidades.
Las dos consultas siguientes extraen datos de los eventos de registro de Spark:
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
Y estos dos ejemplos son consultas del registro de métricas de Spark:
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
Terminología de consulta
En la tabla siguiente se explican algunos términos que se usan al crear una consulta de registros de aplicación y métricas.
| Término | ID | Comentarios |
|---|---|---|
| Cluster_init | Identificador de aplicación | |
| Cola | Ejecutar identificador | Un identificador de ejecución abarca varios lotes. |
| Batch | Identificador de lote | Un lote abarca dos trabajos. |
| Trabajo | Id. del trabajo | Un trabajo abarca dos fases. |
| Fase | Identificador de fase | Una fase tiene entre 100 y 200 identificadores de tarea, en función de la tarea (lectura, orden aleatorio o escritura). |
| Tareas | Identificador de tarea | Una tarea se asigna a un ejecutor. Se asigna una tarea para realizar una acción partitionBy para una partición. Para unos 200 clientes, debería haber 200 tareas. |
En las secciones siguientes se incluyen las métricas típicas que se usan en este escenario para supervisar el rendimiento del sistema, el estado de ejecución de los trabajos de Spark y el uso de recursos del sistema.
Rendimiento del sistema
| Nombre | Medición | Unidades |
|---|---|---|
| Rendimiento del flujo | Promedio de velocidad de entrada en relación con el promedio de velocidad de procesamiento por minuto | Filas por minuto |
| Duración del trabajo | Promedio de duración del trabajo de Spark finalizado por minuto | Duraciones por minuto |
| Recuento de trabajos | Número promedio de trabajos de Spark finalizados por minuto | Número de trabajos por minuto |
| Duración de la fase | Duración media de las fases completadas por minuto | Duraciones por minuto |
| Recuento de fases | Número promedio de fases completadas por minuto | Número de fases por minuto |
| Duración de la tarea | Duración media de las tareas terminadas por minuto | Duraciones por minuto |
| Recuento de tareas | Número promedio de tareas finalizadas por minuto | Número de tareas por minuto |
Estado de ejecución del trabajo de Spark
| Nombre | Medición | Unidades |
|---|---|---|
| Recuento de grupos de programador | Número de recuentos diferenciados de grupos de programador por minuto (número de colas en funcionamiento) | Número de grupos de programador |
| Número de ejecutores en ejecución | Número de ejecutores en ejecución por minuto | Número de ejecutores en ejecución |
| Seguimiento de errores | Todos los registros de errores con el nivel Error y el identificador de fases/tareas correspondientes (se muestra en thread_name_s) |
Uso de recursos del sistema
| Nombre | Medición | Unidades |
|---|---|---|
| Uso de CPU promedio por ejecutor/general | Porcentaje de CPU usado por ejecutor por minuto | % por minuto |
| Promedio de memoria directa usada (MB) por host | Promedio de memoria directa usada por ejecutor por minuto | MB por minuto |
| Memoria volcada por host | Promedio de memoria volcada por ejecutor | MB por minuto |
| Supervisar el impacto de la asimetría de datos en la duración | Intervalo de medida y diferencia del percentil 70-90 y el 90-100 en la duración de las tareas | Diferencia neta entre 100 %, 90 % y 70 %; diferencia porcentual entre 100 %, 90 % y 70 %. |
Decida cómo relacionar la entrada del cliente, que se combinó en un archivo de almacenamiento GZIP, con un archivo de salida de Azure Databricks determinado, ya que Azure Databricks controla la operación por lotes completa como una unidad. Aquí se aplica la granularidad al seguimiento. También puede usar métricas personalizadas para realizar el seguimiento de un archivo de salida respecto al archivo de entrada original.
Para obtener definiciones más detalladas de cada métrica, consulte Visualizaciones en los paneles en este sitio web o consulte la sección Métricas en la documentación de Apache Spark.
Valoración de opciones de ajuste del rendimiento
Definición de base de referencia
Usted y su equipo de desarrollo deben establecer una base de referencia para poder comparar los futuros estados de la aplicación.
Mida el rendimiento de la aplicación cuantitativamente. En este escenario, la métrica clave es la latencia de trabajo, que es habitual en la mayor parte del preprocesamiento y la ingesta de datos. Intente acelerar el tiempo de procesamiento de datos y céntrese en medir la latencia, como en el siguiente gráfico:
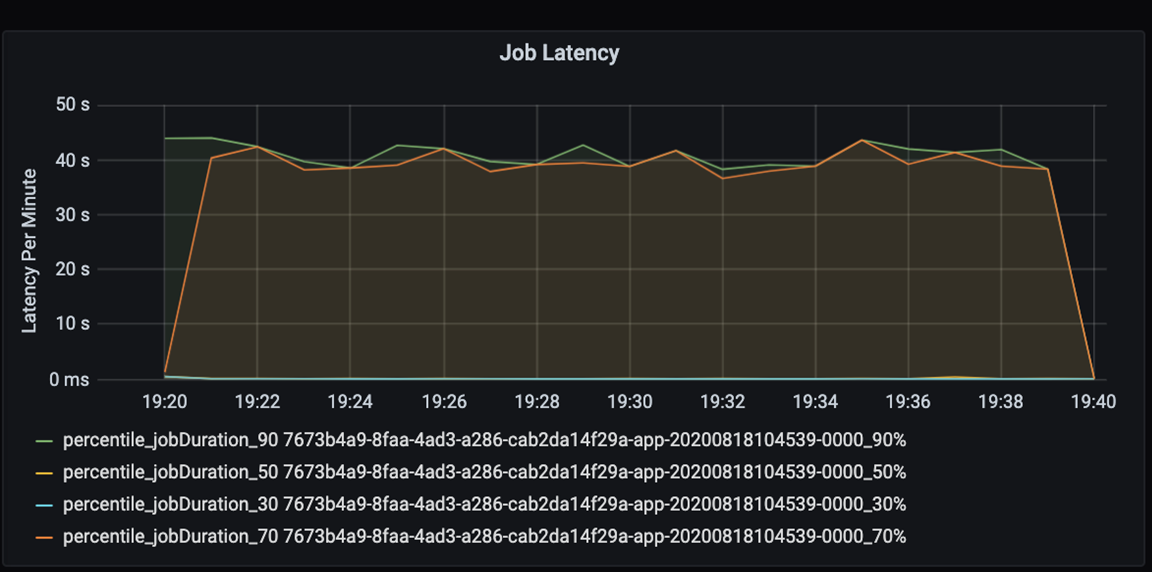
Mida la latencia de ejecución de un trabajo: una vista aproximada del rendimiento general del trabajo, y la duración de la ejecución del trabajo desde el inicio hasta la finalización (tiempo de microlote). En el gráfico anterior, en la marca 19:30, se tardan unos 40 segundos de duración en procesar el trabajo.
Si analiza esos 40 segundos, verá los datos siguientes por fases:
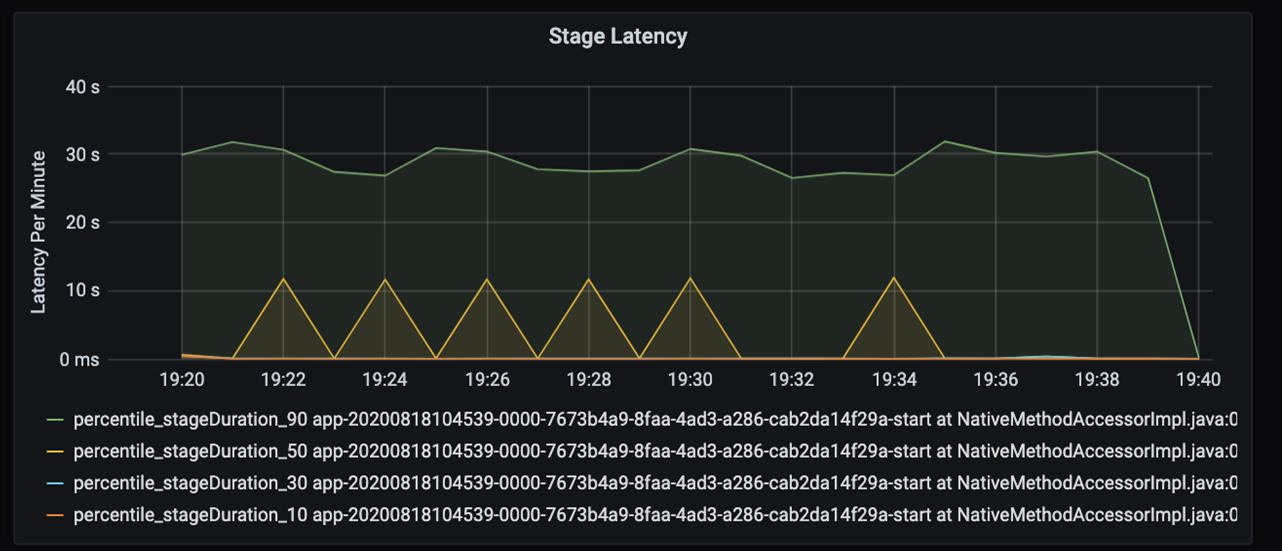
En la marca 19:30, hay dos fases: una fase naranja de 10 segundos y una fase verde a los 30 segundos. Supervise si existe un pico en alguna fase, ya que un pico indica un retraso en una fase.
Investigue cuándo una determinada fase se ejecuta lentamente. En el escenario de creación de particiones, suele haber al menos dos fases: una fase para leer un archivo y otra para ordenar aleatoriamente, particionar y escribir el archivo. Si tiene una alta latencia de fase principalmente en la fase de escritura, podría tener un problema de cuello de botella en la creación de particiones.
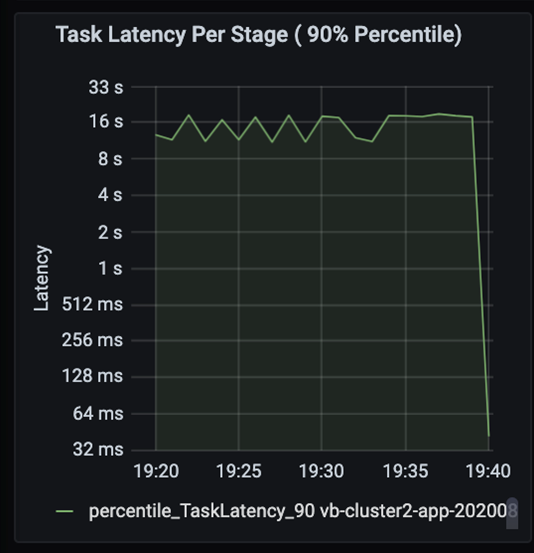
Observe las tareas a medida que las fases de un trabajo se ejecuten secuencialmente, donde las fases anteriores bloquean a las posteriores. Dentro de una fase, si una tarea ejecuta una partición de orden aleatorio más lentamente que otras tareas, todas las tareas del clúster deben esperar a que finalice la tarea más lenta para que se complete la fase. Así pues, las tareas son una forma de supervisar la asimetría de datos y los posibles cuellos de botella. En el gráfico anterior, puede ver que todas las tareas están distribuidas uniformemente.
Ahora supervise el tiempo de procesamiento. Dado que tiene un escenario de streaming, examine el rendimiento de streaming.
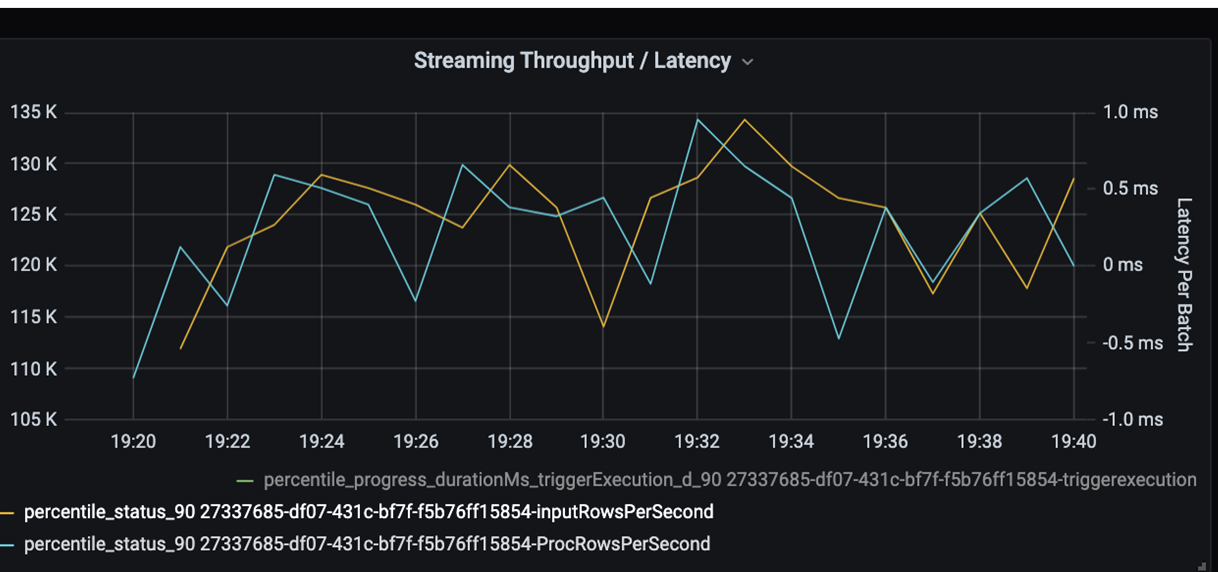
En el gráfico de latencia por lote/rendimiento de streaming anterior, la línea naranja representa la velocidad de entrada (filas de entrada por segundo). La línea azul representa la velocidad de procesamiento (filas procesadas por segundo). En algunos puntos, la velocidad de procesamiento no alcanza la velocidad de entrada. El problema potencial es que los archivos de entrada pueden apilarse en la cola.
Dado que la velocidad de procesamiento es inferior a la de entrada en el gráfico, intente mejorar la velocidad de procesamiento para que pueda cubrir la velocidad de entrada por completo. Una posible razón podría ser el desequilibrio de los datos del cliente en cada clave de partición, que generaría un cuello de botella. Para el siguiente paso y posible solución, aproveche la escalabilidad de Azure Databricks.
Investigación de particiones
En primer lugar, identifique mejor el número correcto de ejecutores de escalado que necesita con Azure Databricks. Aplique la regla general de asignación de cada partición con una CPU dedicada en los ejecutores en ejecución. Por ejemplo, si tiene 200 claves de partición, el número de CPU multiplicado por el número de ejecutores debe ser igual a 200. (Por ejemplo, ocho CPU combinadas con 25 ejecutores serían una buena correlación). Con 200 claves de partición, cada ejecutor solo puede trabajar en una tarea, lo que reduce la posibilidad de un cuello de botella.
Dado que este escenario contiene algunas particiones, investigue la alta varianza en la duración de las tareas. Compruebe si hay picos en la duración de las tareas. Una tarea controla una partición. Si una tarea requiere más tiempo, la partición puede ser demasiado grande y provocar un cuello de botella.
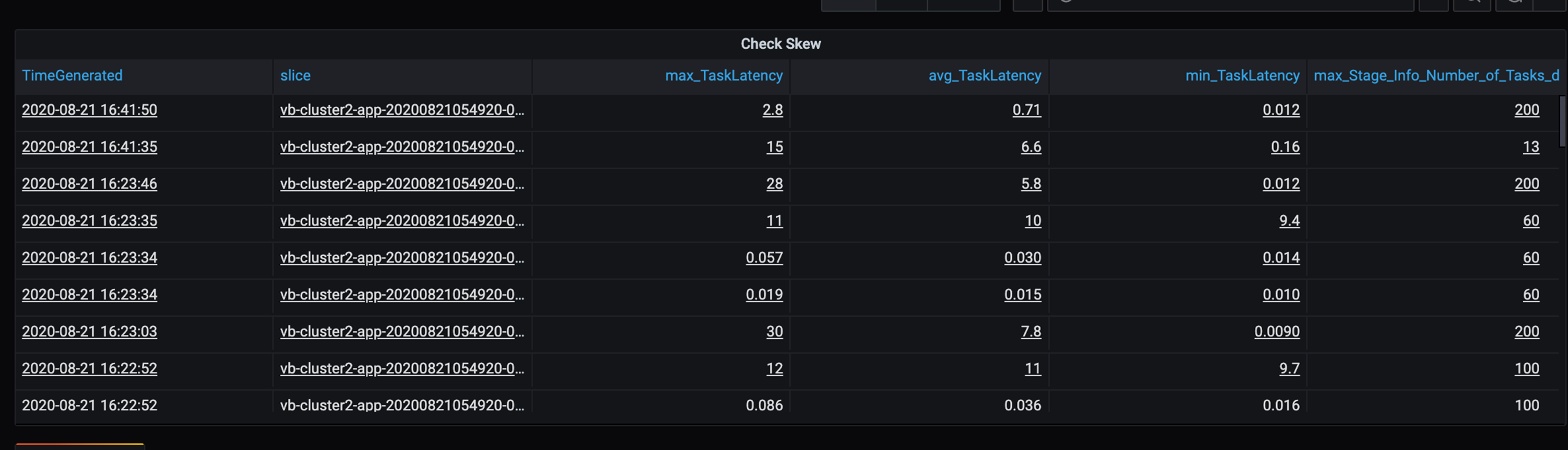
Seguimiento de errores
Agregue un panel para el seguimiento de errores para que pueda detectar errores en datos específicos del cliente. Durante el preprocesamiento de datos, en algunas ocasiones, los archivos están dañados y los registros de un archivo no coinciden con el esquema de datos. En el siguiente panel se detectan muchos archivos incorrectos y registros no válidos.
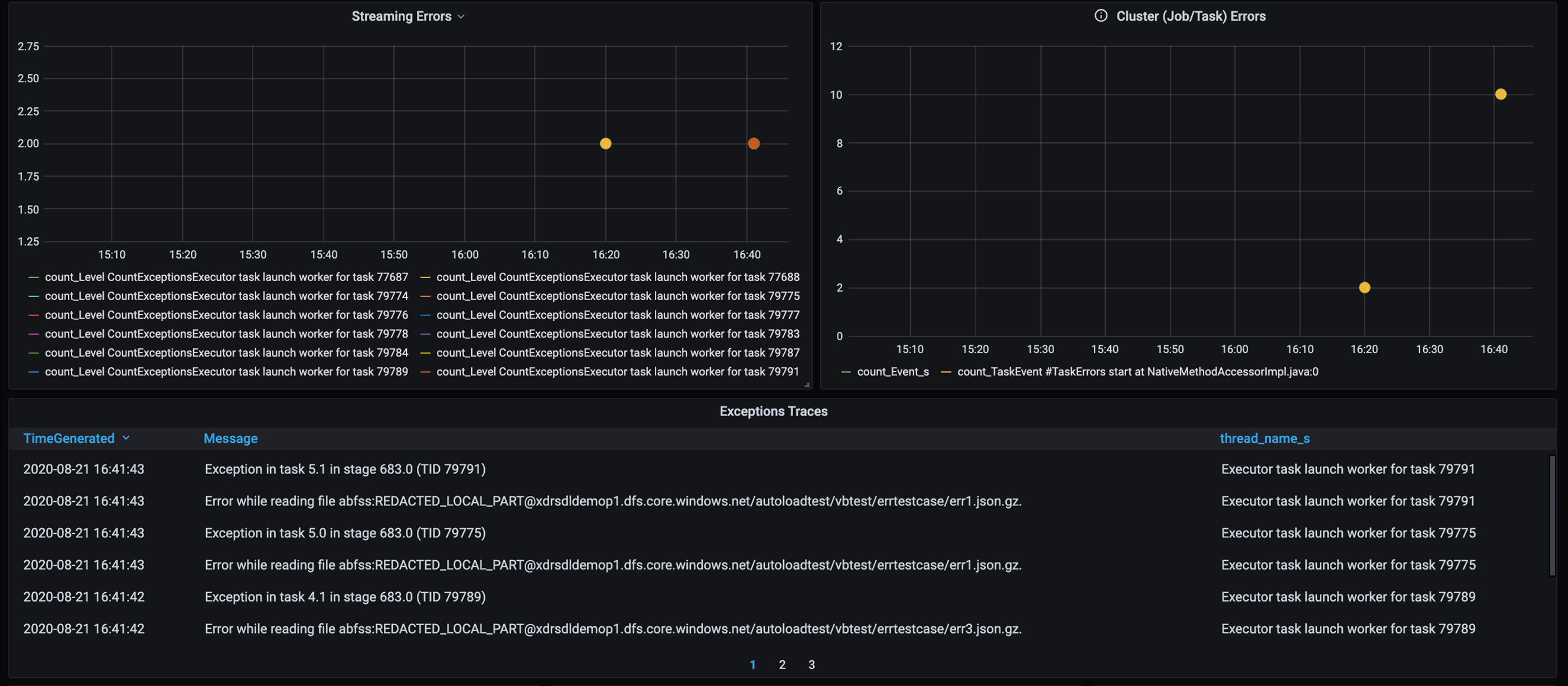
En este panel se muestra el número de errores, los mensajes de error y el identificador de tarea para la depuración. Desde el mensaje, puede realizar fácilmente el seguimiento del error hasta el archivo de error. Al realizar la lectura, se detectan varios archivos con errores. Revise la escala de tiempo superior e investigue los puntos específicos del gráfico (16:20 y 16:40).
Otros cuellos de botella
Para obtener más ejemplos e instrucciones, consulte Solución de cuellos de botella de rendimiento en Azure Databricks.
Resumen de la valoración del ajuste del rendimiento
En este escenario, estas métricas permitieron las observaciones siguientes:
- En el gráfico de latencia de fase, las fases de escritura ocupan la mayor parte del tiempo de procesamiento.
- En el gráfico de latencia de tarea, la latencia de tarea es estable.
- En el gráfico de rendimiento de streaming, la velocidad de salida es inferior a la de entrada en algunos puntos.
- En la tabla de duración de la tarea, hay una varianza de la tarea debido al desequilibrio de los datos del cliente.
- Para obtener un rendimiento optimizado en la fase de creación de particiones, el número de ejecutores de escalado debe coincidir con el número de particiones.
- Hay errores de seguimiento, como archivos incorrectos y registros no válidos.
Para diagnosticar estos problemas, ha usado las siguientes métricas:
- Latencia del trabajo
- Latencia de la fase
- Latencia de la tarea
- Rendimiento de streaming
- Duración de la tarea (máx., promedio, mín.) por fase
- Seguimiento de errores (recuento, mensaje, identificador de tarea)
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- David McGhee | Administrador principal del programa
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
- Lea el Tutorial de Log Analytics.
- Supervisión de Azure Databricks en un área de trabajo de Azure Log Analytics
- Implementación de Azure Log Analytics con métricas de Spark
- Patrones de observación