Migre cientos de terabytes de datos a Azure Cosmos DB
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Cosmos DB puede almacenar terabytes de datos. Puede realizar una migración de datos a gran escala para trasladar la carga de trabajo de producción a Azure Cosmos DB. En este artículo se describen los desafíos relacionados con la transferencia de datos a gran escala a Azure Cosmos DB y se presenta la herramienta que ayuda con los desafíos y migra datos a Azure Cosmos DB. En este caso práctico, el cliente usó la API para NoSQL de Azure Cosmos DB.
Antes de migrar toda la carga de trabajo a Azure Cosmos DB, puede migrar un subconjunto de datos para validar algunos de los aspectos, como la elección de la clave de partición, el rendimiento de las consultas y el modelado de datos. Después de validar la prueba de concepto, puede trasladar toda la carga de trabajo a Azure Cosmos DB.
En la actualidad, las estrategias de migración de Azure Cosmos DB difieren en función de la elección de la API y el tamaño de los datos. Para migrar conjuntos de datos más pequeños (para validar el modelado de datos, el rendimiento de las consultas, la elección de la clave de partición, etc.), puede usar el conector de Azure Cosmos DB de Azure Data Factory. Si está familiarizado con Spark, también puede usar el conector de Spark a Azure Cosmos DB para migrar los datos.
Las herramientas existentes para migrar datos a Azure Cosmos DB tienen algunas limitaciones que se hacen especialmente evidentes en escalas grandes:
Capacidades de escalabilidad horizontal limitadas: Con el fin de migrar terabytes de datos a Azure Cosmos DB lo más rápido posible y consumir de forma eficaz todo el rendimiento aprovisionado, los clientes de migración deben tener la capacidad de escalar horizontalmente de manera indefinida.
Falta de seguimiento de progreso y de comprobación: Es importante realizar un seguimiento del progreso de migración y realizar una comprobación al migrar grandes conjuntos de datos. De lo contrario, cualquier error que se produzca durante la migración la detendrá, y tendrá que iniciar el proceso desde cero. No sería productivo reiniciar todo el proceso de migración cuando ya se haya completado el 99 % del mismo.
Falta de cola de mensajes fallidos: En conjuntos de datos grandes, en algunos casos podría haber problemas con partes de los datos de origen. Además, puede haber problemas transitorios con el cliente o la red. Ninguno de estos casos debe hacer que se produzca un error en toda la migración. Aunque la mayoría de las herramientas de migración tienen capacidades de reintento sólidas que protegen contra problemas intermitentes, no siempre es suficiente. Por ejemplo, si menos del 0,01 % de los documentos de datos de origen tienen un tamaño superior a 2 MB, se producirá un error en la escritura del documento en Azure Cosmos DB. Idealmente, es útil que la herramienta de migración conserve estos documentos "con errores" en otra cola de mensajes fallidos, que se puede procesar después de la migración.
Muchas de estas limitaciones se han corregido para herramientas como Azure Data Factory o los servicios de migración de datos de Azure.
Los desafíos descritos en la sección anterior se pueden resolver con una herramienta personalizada que se puede escalar horizontalmente en varias instancias y que es resistente a los errores transitorios. Además, la herramienta personalizada puede pausar y reanudar la migración en varios puntos de comprobación. Azure Cosmos DB ya proporciona la biblioteca BulkExecutor, que incorpora algunas de estas características. Por ejemplo, la biblioteca BulkExecutor ya tiene la funcionalidad para controlar los errores transitorios y puede escalar horizontalmente los subprocesos en un único nodo para consumir aproximadamente 500.000 RU por nodo. La biblioteca BulkExecutor también divide el conjunto de archivos de origen en microlotes que se operan de forma independiente como una forma de puntos de comprobación.
La herramienta personalizada usa la biblioteca BulkExecutor y admite la escalabilidad horizontal en varios clientes y el seguimiento de los errores durante el proceso de ingesta. Para usar esta herramienta, los datos de origen se deben dividir en archivos distintos en Azure Data Lake Storage (ADLS) para que los distintos trabajadores de migración puedan recoger los archivos e ingerirlos en Azure Cosmos DB. La herramienta personalizada hace uso de una colección independiente, que almacena los metadatos sobre el progreso de migración de cada archivo de origen individual en ADLS y realiza un seguimiento de los errores asociados a ellos.
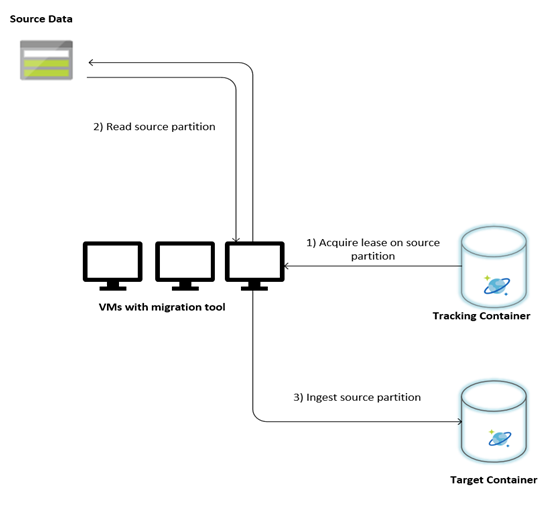
En la imagen siguiente se describe el proceso de migración mediante esta herramienta personalizada. La herramienta se ejecuta en un conjunto de máquinas virtuales y cada una de ellas consulta la colección de seguimiento en Azure Cosmos DB para adquirir una concesión en una de las particiones de datos de origen. Una vez hecho esto, la herramienta lee la partición de datos de origen y se ingiere en Azure Cosmos DB mediante la biblioteca BulkExecutor. A continuación, la colección de seguimiento se actualiza para registrar el progreso de la ingesta de datos y los errores encontrados. Una vez procesada una partición de datos, la herramienta intenta consultar la siguiente partición de origen disponible. Continúa procesando la siguiente partición de origen hasta que se migren todos los datos. El código fuente de la herramienta está disponible en el repositorio de ingesta en bloque de Azure Cosmos DB.
La colección de seguimiento contiene documentos como se muestra en el ejemplo siguiente. Verá que existe uno de estos documentos para cada partición de los datos de origen. Cada documento contiene los metadatos de la partición de datos de origen, como su ubicación, el estado de la migración y los errores (si existen):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Antes de que se inicie la migración de datos, existen algunos requisitos previos que deben tenerse en cuenta:
Es posible que el tamaño de los datos de origen no se asigne exactamente al tamaño de los datos en Azure Cosmos DB. Se pueden insertar algunos documentos de ejemplo del origen para comprobar el tamaño de los datos en Azure Cosmos DB. Dependiendo del tamaño del documento de ejemplo, se puede calcular el tamaño total de los datos en Azure Cosmos DB posterior a la migración.
Por ejemplo, si cada documento después de la migración en Azure Cosmos DB es aproximadamente de 1 KB y si hay alrededor de 60 mil millones de documentos en el conjunto de datos de origen, significaría que el tamaño estimado en Azure Cosmos DB sería cercano a 60 TB.
Aunque Azure Cosmos DB escala horizontalmente el almacenamiento de forma automática, no es aconsejable empezar con el menor tamaño de contenedor. Los contenedores más pequeños tienen una disponibilidad de rendimiento menor, lo que significa que la migración tardará mucho más tiempo en completarse. En su lugar, es útil crear los contenedores con el tamaño final de los datos (tal y como se ha estimado en el paso anterior) y asegurarse de que la carga de trabajo de migración está consumiendo por completo el rendimiento aprovisionado.
En el paso anterior, dado que el tamaño de los datos se estimó en torno a 60 TB, se requiere un contenedor de al menos 2400 RU para acomodar todo el conjunto de datos.
Suponiendo que la carga de trabajo de migración puede consumir todo el rendimiento aprovisionado, dicho rendimiento proporcionaría una estimación de la velocidad de migración. Siguiendo con el ejemplo anterior, se necesitan 5 RU para escribir un documento de 1 KB en la cuenta de la API para NoSQL de Azure Cosmos DB. 2,4 millones de RU permitirían una transferencia de 480.000 documentos por segundo (o 480 MB/s). Esto significa que la migración completa de 60 TB tardará 125.000 segundos o aproximadamente 34 horas.
En caso de que quiera que la migración se complete en un día, debe aumentar el rendimiento aprovisionado a 5 millones de RU.
Dado que la migración debe completarse tan pronto como sea posible, es aconsejable minimizar el tiempo y las RU empleadas en la creación de índices para cada uno de los documentos ingeridos. Azure Cosmos DB indexa automáticamente todas las propiedades, por lo que merece la pena minimizar la indexación a algunos términos seleccionados o desactivarla completamente durante el transcurso de la migración. Puede desactivar la directiva de indexación del contenedor cambiando indexingMode a none, como se muestra a continuación:
{
"indexingMode": "none"
}
Una vez completada la migración, puede actualizar la indexación.
Una vez completados los requisitos previos, puede migrar los datos con los pasos siguientes:
En primer lugar, importe los datos desde Azure Blob Storage. Para aumentar la velocidad de la migración, es útil paralelizar en particiones de origen distintas. Antes de iniciar la migración, el conjunto de datos de origen se debe dividir en archivos con un tamaño aproximado de 200 MB.
La biblioteca Bulk Executor se puede escalar verticalmente para que consuma 500 000 RU en una sola máquina virtual de cliente. Dado que el rendimiento disponible es de 5 millones de RU, se deben aprovisionar 10 VM Ubuntu 16.04 (Standard_D32_v3) en la misma región donde se encuentra la base de datos de Azure Cosmos DB. Debe preparar estas VM con la herramienta de migración y su archivo de configuración.
Ejecute el paso de la cola en una de las máquinas virtuales de cliente. En este paso se crea la colección de seguimiento, que examina el contenedor de ADLS y crea un documento de seguimiento de progreso para cada uno de los archivos de partición del conjunto de datos de origen.
A continuación, ejecute el paso de importación en todas las VM de cliente. Cada uno de los clientes puede tomar posesión en una partición de origen e ingerir sus datos en Azure Cosmos DB. Una vez que se completa y su estado se actualiza en la colección de seguimiento, los clientes pueden consultar la siguiente partición de origen disponible en la colección de seguimiento.
Este proceso continúa hasta que se ingiere todo el conjunto de particiones de origen. Una vez procesadas todas las particiones de origen, la herramienta debe volver a ejecutarse en el modo de corrección de errores en la misma colección de seguimiento. Este paso es necesario para identificar las particiones de origen que se deben volver a procesar debido a errores.
Algunos de estos errores pueden deberse a documentos incorrectos en los datos de origen. Deben identificarse y corregirse. Después, debe volver a ejecutar el paso de importación en las particiones con errores para volver a ingerirlas.
Una vez completada la migración, puede validar que el número de documentos en Azure Cosmos DB sea el mismo que en la base de datos de origen. En este ejemplo, el tamaño total de Azure Cosmos DB ha resultado ser de 65 terabytes. Después de la migración, la indexación se puede activar de manera selectiva y las RU pueden reducirse al nivel requerido por las operaciones de la carga de trabajo.
- Puede aprender más si prueba las aplicaciones de ejemplo que usan la biblioteca BulkExecutor en .NET y Java.
- La biblioteca BulkExecutor está integrada en el conector de Spark de Azure Cosmos DB; para más información, vea el artículo sobre el conector de Spark de Azure Cosmos DB.
- Para obtener más ayuda con las migraciones a gran escala, póngase en contacto con el equipo de producto de Azure Cosmos DB abriendo una incidencia de soporte técnico en el tipo de problema "Asesoramiento general" y en el subtipo "Grandes migraciones (TB+)".
- ¿Intenta planear la capacidad de una migración a Azure Cosmos DB? Para ello, puede usar información sobre el clúster de bases de datos existente.
- Si lo único que sabe es el número de núcleos virtuales y servidores del clúster de bases de datos existente, lea sobre el cálculo de unidades de solicitud mediante núcleos o CPU virtuales.
- Si conoce las tasas de solicitudes típicas de la carga de trabajo de la base de datos actual, obtenga información sobre el cálculo de unidades de solicitud mediante la herramienta de planeamiento de capacidad de Azure Cosmos DB.