Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se describe el uso de la actividad de copia de Azure Data Factory y Azure Synapse Analytics para copiar datos con Azure Databricks Delta Lake como origen o destino. Se basa en el artículo Actividad de copia, en el que se ofrece información general sobre la actividad de copia.
Funcionalidades admitidas
Este conector de Azure Databricks Delta Lake es compatible con las funcionalidades siguientes:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/receptor) | ① ② |
| Flujo de datos de asignación (origen/receptor) | ① |
| Actividad de búsqueda | ① ② |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
En general, el servicio admite Data Lake con las siguientes funcionalidades para satisfacer sus diversas necesidades.
- La actividad de copia admite el conector de Azure Databricks Delta Lake para copiar datos desde cualquier almacén de datos de origen compatible a la tabla de Azure Databricks Delta Lake, y desde la tabla de Delta Lake a cualquier almacén de datos receptor compatible. Aprovecha el clúster de Databricks para realizar el movimiento de datos. Consulte los detalles en la sección Requisitos previos.
- El flujo de datos de asignación admite el formato Delta genérico en Azure Storage como origen y receptor para leer y escribir archivos delta para las operaciones de ETL sin código y se ejecuta en una instancia administrada de Azure Integration Runtime.
- Las actividades de Databricks admiten la orquestación de la carga de trabajo de ETL centrada en código, o de aprendizaje automático basada en Delta Lake.
Requisitos previos
Para usar este conector de Azure Databricks Delta Lake, debe configurar un clúster en Azure Databricks.
- Para copiar datos en Delta Lake, la actividad de copia invoca un clúster de Azure Databricks para leer los datos de una instancia de Azure Storage, que es el origen inicial, o un área de almacenamiento provisional en la que el servicio escribe primero los datos de origen a través de la copia almacenada provisionalmente integrada. Obtenga más información sobre Delta Lake como receptor.
- Del mismo modo, para copiar datos desde Delta Lake, la actividad de copia invoca un clúster de Azure Databricks para escribir los datos en una instancia de Azure Storage, que es el receptor original, o un área de almacenamiento provisional desde la que el servicio sigue escribiendo los datos en un receptor final a través de la copia almacenada provisionalmente integrada. Obtenga más información sobre Delta Lake como origen.
El clúster de Databricks debe tener acceso a una cuenta de blob de Azure o Azure Data Lake Storage Gen2, al sistema de archivos o contenedor de almacenamiento usado como origen, receptor o almacenamiento provisional y al sistema de archivos o contenedor en el que quiere escribir las tablas de Delta Lake.
Para usar Azure Data Lake Storage Gen2, puede configurar una entidad de servicio en el clúster de Databricks como parte de la configuración de Apache Spark. Siga los pasos que se indican en Acceso directo con la entidad de servicio.
Para usar Azure Blob Storage, puede configurar una clave de acceso de cuenta de almacenamiento o token de SAS en el clúster de Databricks como parte de la configuración de Apache Spark. Siga los pasos descritos en Acceso a Azure Blob Storage mediante la API de RDD.
Durante la ejecución de la actividad de copia, si el clúster que configuró se ha finalizado, el servicio lo inicia automáticamente. Si crea una canalización mediante la interfaz de usuario de creación, en el caso de las operaciones como la vista previa de los datos, deberá tener un clúster activo, ya que el servicio no iniciará el clúster automáticamente.
Especificación de la configuración de clúster
En el menú desplegable Modo del clúster, seleccione Estándar.
En la lista desplegable Versión de Databricks Runtime, seleccione una versión de Databricks Runtime.
Active la Optimización automática al agregar las siguientes propiedades a la configuración de Spark:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueConfigure el clúster en función de sus necesidades de escalado e integración.
Para obtener detalles sobre la configuración del clúster, consulte Configuración de los clústeres.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado a Azure Databricks Delta Lake mediante la interfaz de usuario
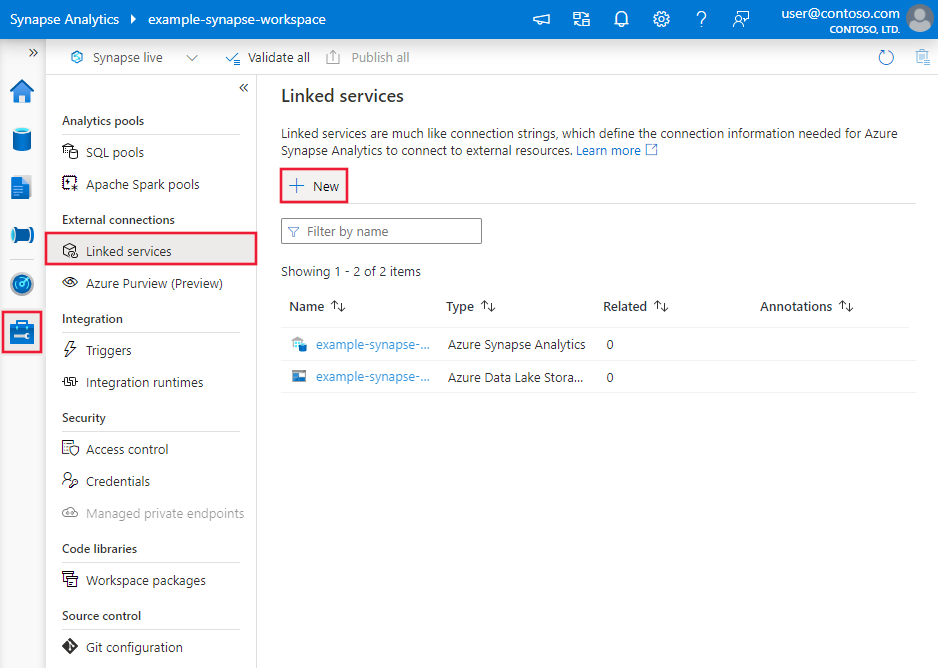
Siga estos pasos para crear un servicio vinculado a Azure Databricks Delta Lake en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque delta y seleccione el conector Azure Databricks Delta Lake.

Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
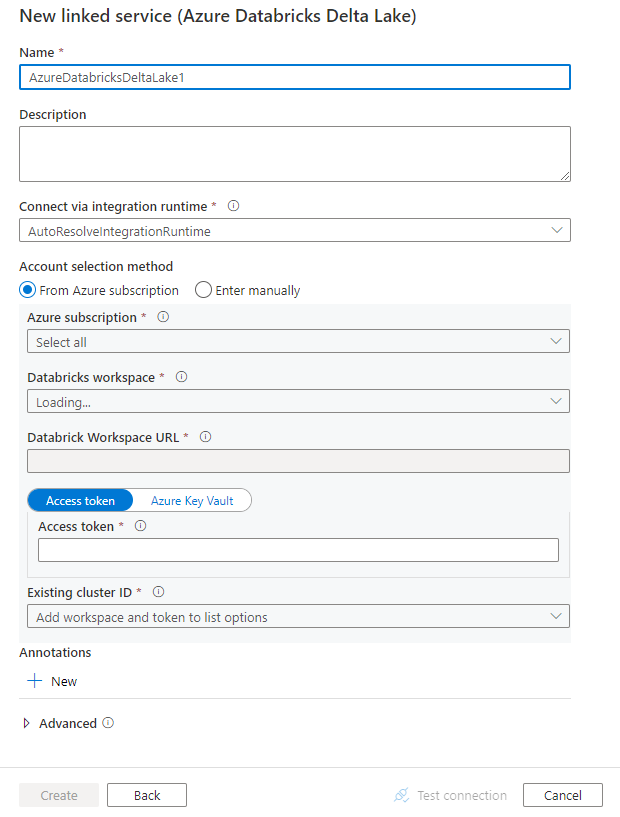

Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que definen entidades específicas de un conector Azure Databricks Delta Lake.
Propiedades del servicio vinculado
Este conector de Azure Databricks Delta Lake admite los siguientes tipos de autenticación. Consulte las secciones correspondientes para más información.
- Access token
- Autenticación de identidad administrada asignada por el sistema
- Autenticación de identidad administrada asignada por el usuario
Access token
Las siguientes propiedades son compatibles con el servicio vinculado de Azure Databricks Delta Lake:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | Propiedad type, que debe establecerse en AzureDatabricksDeltaLake. | Sí |
| dominio | Especifique la dirección URL del área de trabajo de Azure Databricks; por ejemplo, https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Especifique el id. de clúster de un clúster existente. Debe tratarse de un clúster interactivo que ya se haya creado. Encontrará el identificador del clúster interactivo en el área de trabajo de Databricks -> Clústeres -> Nombre del clúster interactivo -> Configuración -> Etiquetas. Obtenga más información. |
|
| accessToken | El token de acceso es necesario para que el servicio se autentique en Azure Databricks. El token de acceso debe generarse a partir del área de trabajo de Databricks. Aquí encontrará más pasos detallados para encontrar el token de acceso. | |
| connectVia | El entorno de ejecución de integración que se utiliza para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos se encuentra en una red privada). Si no se especifica, se usará Azure Integration Runtime. | No |
Ejemplo:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Autenticación de identidad administrada asignada por el sistema
Para obtener más información sobre las identidades administradas asignadas por el sistema para los recursos de Azure, consulte Identidad administrada asignada por el sistema para recursos de Azure.
Para usar la autenticación de identidad administrada asignada por el sistema, siga estos pasos a fin de conceder los permisos:
Recupere la información de la identidad administrada mediante la copia del valor de Id. del objeto de identidad administrada que se ha generado junto con la factoría de datos o el área de trabajo de Synapse.
Conceda a la identidad administrada los permisos correctos en Azure Databricks. En general, debe conceder al menos el rol Colaborador a la identidad administrada asignada por el sistema en Control de acceso (IAM) de Azure Databricks.
Las siguientes propiedades son compatibles con el servicio vinculado de Azure Databricks Delta Lake:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | Propiedad type, que debe establecerse en AzureDatabricksDeltaLake. | Sí |
| dominio | Especifique la dirección URL del área de trabajo de Azure Databricks; por ejemplo, https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Sí |
| clusterId | Especifique el id. de clúster de un clúster existente. Debe tratarse de un clúster interactivo que ya se haya creado. Encontrará el identificador del clúster interactivo en el área de trabajo de Databricks -> Clústeres -> Nombre del clúster interactivo -> Configuración -> Etiquetas. Obtenga más información. |
Sí |
| workspaceResourceId | Especifique el identificador del recurso del área de trabajo de Azure Databricks. | Sí |
| connectVia | El entorno de ejecución de integración que se utiliza para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos se encuentra en una red privada). Si no se especifica, se usará Azure Integration Runtime. | No |
Ejemplo:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación de identidad administrada asignada por el usuario
Para obtener más información sobre las identidades administradas asignadas por el usuario para los recursos de Azure, consulte Identidades administradas asignadas por el usuario.
Para usar la autenticación de identidad administrada asignada por el usuario, siga estos pasos:
Cree una o varias identidades administradas asignadas por el usuario y conceda permiso en la instancia de Azure Databricks. En general, debe conceder al menos el rol Colaborador a la identidad administrada asignada por el usuario en Control de acceso (IAM) de Azure Databricks.
Asigne una o varias identidades administradas asignadas por el usuario a la factoría de datos o al área de trabajo de Synapse y cree credenciales para cada una de estas entidades.
Las siguientes propiedades son compatibles con el servicio vinculado de Azure Databricks Delta Lake:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | Propiedad type, que debe establecerse en AzureDatabricksDeltaLake. | Sí |
| dominio | Especifique la dirección URL del área de trabajo de Azure Databricks; por ejemplo, https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Sí |
| clusterId | Especifique el id. de clúster de un clúster existente. Debe tratarse de un clúster interactivo que ya se haya creado. Encontrará el identificador del clúster interactivo en el área de trabajo de Databricks -> Clústeres -> Nombre del clúster interactivo -> Configuración -> Etiquetas. Obtenga más información. |
Sí |
| credentials | Especifique la identidad administrada asignada por el usuario como objeto de credencial. | Sí |
| workspaceResourceId | Especifique el identificador del recurso del área de trabajo de Azure Databricks. | Sí |
| connectVia | El entorno de ejecución de integración que se utiliza para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos se encuentra en una red privada). Si no se especifica, se usará Azure Integration Runtime. | No |
Ejemplo:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos.
Las siguientes propiedades son compatibles con el conjunto de datos de Azure Databricks Delta Lake.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | Propiedad type del conjunto de datos, que debe establecerse en AzureDatabricksDeltaLakeDataset. | Sí |
| database | Nombre de la base de datos. | No para el origen, sí para el receptor |
| table | Nombre de la tabla de Delta. | No para el origen, sí para el receptor |
Ejemplo:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que admite el receptor y el origen de Azure Databricks Delta Lake.
Delta Lake como origen
Para copiar datos de Azure Databricks Delta Lake, se admiten las siguientes propiedades en la sección de origen de la actividad de copia.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | Propiedad type del origen de la actividad de copia, que debe establecerse en: AzureDatabricksDeltaLakeSource. | Sí |
| Query | Especifique la consulta SQL para leer los datos. Para el control de viaje en el tiempo, use el siguiente patrón: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
No |
| exportSettings | Configuración avanzada utilizada para recuperar datos de la tabla de Delta. | No |
En exportSettings: |
||
| type | Propiedad type del comando de exportación, establecida en AzureDatabricksDeltaLakeExportCommand. | Yes |
| dateFormat | Da formato de cadena con formato de fecha a un elemento de tipo date. Los formatos de fecha personalizados siguen los formatos del patrón de datetime. Si no se especifica, el valor predeterminado es yyyy-MM-dd. |
No |
| timestampFormat | Da formato de cadena con formato de marca de tiempo a un elemento de tipo timestamp. Los formatos de fecha personalizados siguen los formatos del patrón de datetime. Si no se especifica, el valor predeterminado es yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
No |
Copia directa desde Delta Lake
Si el almacén de datos y el formulario del receptor cumplen los criterios descritos en esta sección, puede usar la actividad de copia para copiar directamente de la tabla de Azure Databricks Delta al receptor. El servicio comprueba la configuración y genera un error en la ejecución de la actividad de copia si no se cumplen los siguientes criterios:
El servicio vinculado del receptor es Azure Blob Storage o Azure Data Lake Storage Gen2. Las credenciales de la cuenta deben estar configuradas previamente en la configuración de clúster de Azure Databricks. Obtenga más información sobre los Requisitos previos.
El formato de datos de receptor es Parquet, texto delimitado o JSON con estas configuraciones, y apunta a una carpeta en lugar de un archivo.
- Para el formato Parquet, el códec de compresión es none, snappy, o gzip.
- Para el formato de texto delimitado:
-
rowDelimiteres cualquier carácter individual. -
compressionpuede ser none, bzip2 o gzip. - No se admite
encodingNamecon el valor UTF-7.
-
- En el caso del formato Avro, el códec de compresión es none, deflate o snappy.
En el origen de la actividad Copy,
additionalColumnsno se especifica.Si se copian datos en texto delimitado, en el receptor de la actividad de copia,
fileExtensiondebe ser ".csv".La conversión de tipos no está habilitada en la asignación de la actividad de copia.
Ejemplo:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Copia almacenada provisionalmente desde Delta Lake
Cuando el formato o el almacén de datos del receptor no coincide con los criterios de copia directa, como se menciona en la última sección, habilite la copia preconfigurada integrada con una instancia intermedia de Azure Storage. La característica de copia almacenada provisionalmente también proporciona un mejor rendimiento. El servicio exporta los datos de Azure Databricks Delta Lake al almacenamiento provisional, copia los datos en el receptor y, por último, limpia los datos temporales del almacenamiento provisional. Consulte Copia almacenada provisionalmente para obtener más información sobre cómo copiar datos mediante el almacenamiento provisional.
Para usar esta característica, cree un servicio vinculado de Azure Blob Storage o Azure Data Lake Storage Gen2 que haga referencia a la cuenta de almacenamiento como almacenamiento provisional temporal. Luego especifique las propiedades enableStaging y stagingSettings en la actividad de copia.
Nota
Las credenciales de la cuenta de almacenamiento provisional deben estar configuradas previamente en la configuración de clúster de Azure Databricks. Obtenga más información sobre los Requisitos previos.
Ejemplo:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta Lake como receptor
Para copiar datos a Azure Databricks Delta Lake, se admiten las siguientes propiedades en la sección de receptor de la actividad de copia.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | Propiedad type del receptor de la actividad de copia, establecida en AzureDatabricksDeltaLakeSink. | Sí |
| preCopyScript | Especifica una consulta SQL para que la ejecute la actividad de copia antes de escribir datos en la tabla de Databricks Delta en cada ejecución. Ejemplo: VACUUM eventsTable DRY RUN Puede usar esta propiedad para limpiar los datos cargados previamente, o agregar una instrucción TRUNCATE TABLE o VACUUM. |
No |
| importSettings | Configuración avanzada usada para escribir datos en la tabla de Delta. | No |
En importSettings: |
||
| type | Propiedad type del comando de importación, establecida en AzureDatabricksDeltaLakeImportCommand. | Yes |
| dateFormat | Da formato de tipo date con formato de fecha a una cadena. Los formatos de fecha personalizados siguen los formatos del patrón de datetime. Si no se especifica, el valor predeterminado es yyyy-MM-dd. |
No |
| timestampFormat | Da formato de tipo timestamp con formato de marca de tiempo a una cadena. Los formatos de fecha personalizados siguen los formatos del patrón de datetime. Si no se especifica, el valor predeterminado es yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
No |
Copia directa a Delta Lake
Si el almacén de datos y el formulario de origen cumplen los criterios descritos en esta sección, puede usar la actividad de copia para copiar directamente desde el origen a Azure Databricks Delta Lake. El servicio comprueba la configuración y genera un error en la ejecución de la actividad de copia si no se cumplen los siguientes criterios:
El servicio vinculado de origen es Azure Blob Storage o Azure Data Lake Storage Gen2. Las credenciales de la cuenta deben estar configuradas previamente en la configuración de clúster de Azure Databricks. Obtenga más información sobre los Requisitos previos.
El formato de datos de origen es Parquet, texto delimitado o JSON con estas configuraciones, y apunta a una carpeta en lugar de un archivo.
- Para el formato Parquet, el códec de compresión es none, snappy, o gzip.
- Para el formato de texto delimitado:
-
rowDelimiteres el valor predeterminado, o cualquier carácter individual. -
compressionpuede ser none, bzip2 o gzip. - No se admite
encodingNamecon el valor UTF-7.
-
- En el caso del formato Avro, el códec de compresión es none, deflate o snappy.
En el origen de la actividad de copia:
-
wildcardFileNamesolo contiene caracteres*comodín, pero ningún?y no se especifica el valor dewildcardFolderName. -
prefix,modifiedDateTimeStart,modifiedDateTimeEndyenablePartitionDiscoveryno se especifican. -
additionalColumnsno se especifica.
-
La conversión de tipos no está habilitada en la asignación de la actividad de copia.
Ejemplo:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReaderQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Copia almacenada provisionalmente a Delta Lake
Cuando el formato o el almacén de datos del origen no coincide con los criterios de copia directa, como se menciona en la última sección, habilite la copia preconfigurada integrada con una instancia intermedia de Azure Storage. La característica de copia almacenada provisionalmente también proporciona un mejor rendimiento. El servicio convierte automáticamente los datos para satisfacer los requisitos de formato en el almacenamiento provisional y, luego, los carga en Delta Lake desde allí. Por último, limpia los datos temporales del almacenamiento. Consulte Copia almacenada provisionalmente para obtener más información sobre cómo copiar datos con el almacenamiento provisional.
Para usar esta característica, cree un servicio vinculado de Azure Blob Storage o Azure Data Lake Storage Gen2 que haga referencia a la cuenta de almacenamiento como almacenamiento provisional temporal. Luego especifique las propiedades enableStaging y stagingSettings en la actividad de copia.
Nota
Las credenciales de la cuenta de almacenamiento provisional deben estar configuradas previamente en la configuración de clúster de Azure Databricks. Obtenga más información sobre los Requisitos previos.
Ejemplo:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Supervisión
Se proporciona la misma experiencia de supervisión de la actividad de copia que para otros conectores. Además, dado que la carga de datos con Delta Lake como origen o destino se está ejecutando en el clúster de Azure Databricks, puede ver los registros de clúster detallados y supervisar el rendimiento.
Propiedades de la actividad de búsqueda
Para más información sobre las propiedades, consulte Actividad de búsqueda.
La actividad Búsqueda puede devolver hasta 1000 filas; si el conjunto de resultados contiene más registros, se devolverán las primeras 1000 filas.
Contenido relacionado
Consulte los formatos y almacenes de datos compatibles para ver una lista de los almacenes de datos que la actividad de copia admite como orígenes y receptores.