Formato delta en Azure Data Factory
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
En este artículo se señala cómo copiar datos con un lago delta, como origen o destino, almacenado en Azure Data Lake Store Gen2 o Azure Blob Storage con el formato delta. Este conector está disponible como conjunto de datos en línea en los flujos de datos de asignación como origen y receptor.
Propiedades de Asignación de instancias de Data Flow
Este conector está disponible como conjunto de datos en línea en los flujos de datos de asignación como origen y receptor.
Propiedades de origen
En la tabla siguiente se enumeran las propiedades que admite un origen delta. Puede editar estas propiedades en la pestaña Source options (Opciones del origen).
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Formato | El formato debe ser delta. |
sí | delta |
format |
| Sistema de archivos | Sistema de archivos o contenedor del lago delta | sí | String | fileSystem |
| Ruta de acceso a la carpeta | Directorio del lago delta | sí | String | folderPath |
| Tipo de compresión | Tipo de compresión de la tabla delta | no | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Nivel de compresión | Elija si la compresión debe completarse tan pronto como sea posible, incluso si el archivo resultante debe comprimirse de forma óptima. | obligatorio si se especifica compressedType |
Optimal o Fastest |
compressionLevel |
| Viaje en el tiempo | Elija si se debe consultar una instantánea anterior de una tabla delta | no | Consulta por marca de tiempo: marca de tiempo Consulta por versión: Entero |
timestampAsOf versionAsOf |
| No permitir que se encuentren archivos | Si es true, no se devuelve un error si no se encuentra ningún archivo | no | true o false |
ignoreNoFilesFound |
Importar esquema
Delta solo está disponible como conjunto de datos insertado y, de forma predeterminada, no tiene un esquema asociado. Para obtener los metadatos de columna, haga clic en el botón Importar esquema en la pestaña Proyección. Esto le permite hacer referencia a los nombres de columna y los tipos de datos especificados por el corpus. Para importar el esquema, una sesión de depuración de flujo de datos debe estar activa y debe tener un archivo de definición de entidad CDM existente al que apuntar.
Ejemplo de script de origen delta
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Propiedades del receptor
En la tabla siguiente se enumeran las propiedades que admite un receptor delta. Puede editar estas propiedades en la pestaña Configuración.
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Formato | El formato debe ser delta. |
sí | delta |
format |
| Sistema de archivos | Sistema de archivos o contenedor del lago delta | sí | String | fileSystem |
| Ruta de acceso a la carpeta | Directorio del lago delta | sí | String | folderPath |
| Tipo de compresión | Tipo de compresión de la tabla delta | no | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Nivel de compresión | Elija si la compresión debe completarse tan pronto como sea posible, incluso si el archivo resultante debe comprimirse de forma óptima. | obligatorio si se especifica compressedType |
Optimal o Fastest |
compressionLevel |
| Vacío | Elimina los archivos anteriores a la duración especificada que ya no es relevante para la versión de la tabla actual. Cuando se especifica un valor de 0 o menos, no se realiza la operación de vaciado. | sí | Entero | vacuum |
| Acción Table | Indica a ADF qué hacer con la tabla delta de destino en el receptor. Puede dejarla tal cual y anexar nuevas filas, sobrescribir la definición de tabla y los datos existentes con nuevos metadatos y datos o mantener la estructura de tabla existente, pero truncar primero todas las filas y, a continuación, insertar las filas nuevas. | no | Ninguno, Truncar, Sobrescribir | deltaTruncate, sobrescribir |
| Método de actualización | Al seleccionar solo "Permitir inserción" o al escribir en una nueva tabla delta, el destino recibe todas las filas entrantes independientemente de las directivas de fila establecidas. Si los datos contienen filas de otras directivas de fila, deben excluirse mediante una transformación de filtro anterior. Cuando se seleccionan todos los métodos Update, se realiza una combinación, donde las filas se insertan, eliminan o actualizan según las directivas de fila establecidas mediante una transformación de Alteración de fila anterior. |
sí | true o false |
insertable deletable upsertable updateable |
| Escritura optimizada | Logre un mayor rendimiento de la operación de escritura mediante la optimización del orden aleatorio interno en los ejecutores de Spark. Como resultado, es posible que observe menos particiones y archivos de un tamaño mayor. | no | true o false |
optimizedWrite: true |
| Compactación automática | Una vez completada la operación de escritura, Spark ejecutará automáticamente el comando OPTIMIZE para volver a organizar los datos, lo que dará lugar a más particiones si es necesario, para mejorar el rendimiento de la lectura en el futuro. |
no | true o false |
autoCompact: true |
Ejemplo de script de receptor delta
El script de flujo de datos asociado es:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Receptor delta con eliminación de particiones
Con esta opción en el método Update anterior (es decir, update/upsert/delete), puede limitar el número de particiones que se inspeccionan. Solo las particiones que satisfagan esta condición se capturan desde el almacén de destino. Puede especificar un conjunto fijo de valores que puede tomar una columna de partición.
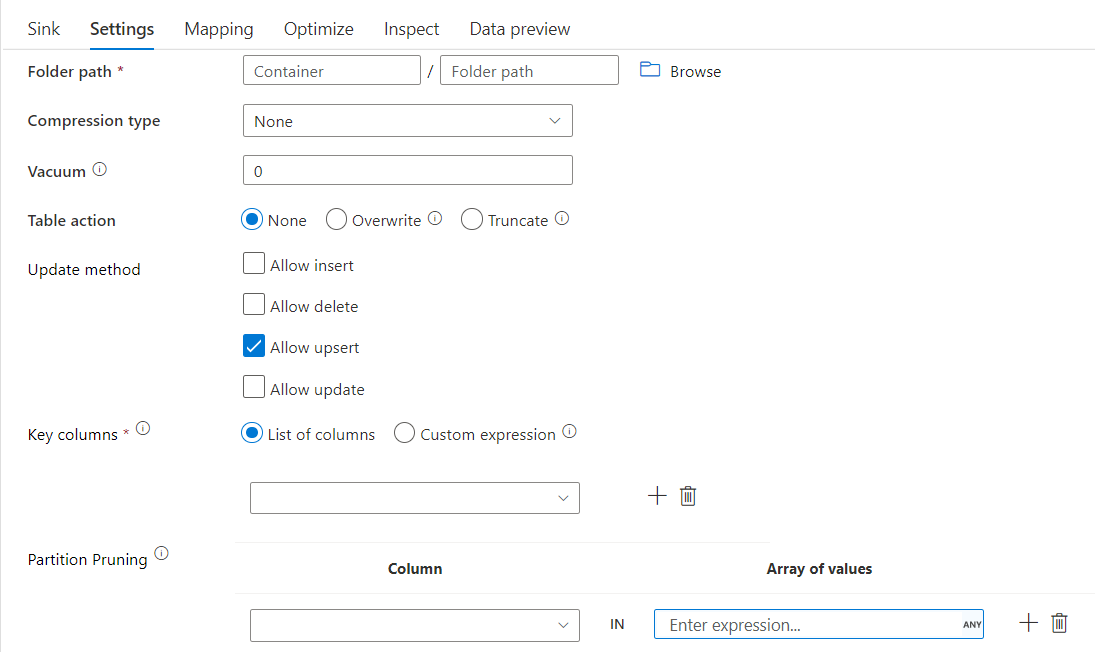
Ejemplo de script de receptor delta con eliminación de particiones
A continuación se proporciona un script de ejemplo.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta solo leerá 2 particiones en las que part_col == 5 y 8 del almacén delta de destino en lugar de todas las particiones. part_col es una columna por la que se particionan los datos delta de destino. No es necesario que esté presente en los datos de origen.
Opciones de optimización del receptor delta
En la pestaña Configuración, encontrará tres opciones más para optimizar la transformación del receptor delta.
Cuando la opción Combinar esquema está habilitada, permite la evolución del esquema, es decir, cualquier columna que esté presente en el flujo entrante actual pero no en la tabla Delta de destino se agregará automáticamente a su esquema. Esta opción se admite en todos los métodos de actualización.
Cuando la opción Compactación automática está activada, después de una escritura individual, la transformación comprueba si los archivos se pueden compactar más, y ejecuta un trabajo rápido OPTIMIZE (con tamaños de archivo de 128 MB en lugar de 1 GB) para compactar más los archivos de las particiones que tienen el mayor número de archivos pequeños. La compactación automática ayuda a fusionar un gran número de archivos pequeños en un número menor de archivos grandes. La compactación automática solo se inicia cuando hay al menos 50 archivos. Una vez realizada una operación de compactación, se crea una nueva versión de la tabla y se escribe un nuevo archivo que contiene los datos de varios archivos anteriores en un formato comprimido compacto.
Cuando la opción Optimizar escritura está habilitada, la transformación del receptor intenta escribir archivos de 128 MB para cada partición de tabla con el fin de optimizar dinámicamente los tamaños de partición en función de los datos reales. Este es un tamaño aproximado y puede variar en función de las características del conjunto de datos. Las escrituras optimizadas mejoran la eficacia general de las escrituras y las posteriores lecturas. Organiza las particiones de forma que mejora el rendimiento de las lecturas posteriores.
Sugerencia
El proceso de escritura optimizado ralentizará el trabajo de ETL general porque el receptor emitirá el comando Spark Delta Lake Optimize después de procesar los datos. Se recomienda usar la escritura optimizada con moderación. Por ejemplo, si tiene una canalización de datos por hora, ejecute un flujo de datos con escritura optimizada diaria.
Restricciones conocidas
Al escribir en un receptor delta, existe una limitación conocida en la que el número de filas escritas no se mostrará en el resultado de la supervisión.
Contenido relacionado
- Cree una transformación de origen en flujo de datos de asignación.
- Cree una transformación de receptor en el flujo de datos de asignación.
- Cree una transformación Alter row para marcar filas como insert, update, upsert o delete.