Copia de datos desde un servidor HDFS con Azure Data Factory o Synapse Analytics
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se describe cómo copiar datos desde el servidor del sistema de archivos distribuido de Hadoop (HDFS). Para obtener más información, lea los artículos de introducción para Azure Data Factory y Synapse Analytics.
Funcionalidades admitidas
El conector HDFS es compatible con las siguientes funcionalidades:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/-) | 7,7 |
| Actividad de búsqueda | 7,7 |
| Actividad de eliminación | 7,7 |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
En concreto, el conector HDFS admite las siguientes funcionalidades:
- Copiar los archivos mediante la autenticación de Windows (Kerberos) o anónima.
- Copiar los archivos mediante el protocolo webhdfs o la compatibilidad con DistCp integrada.
- La copia de archivos tal cual, o bien el análisis o generación de archivos con los códecs de compresión y los formatos de archivo compatibles.
Requisitos previos
Si el almacén de datos se encuentra en una red local, una red virtual de Azure o una nube privada virtual de Amazon, debe configurar un entorno de ejecución de integración autohospedado para conectarse a él.
Si el almacén de datos es un servicio de datos en la nube administrado, puede usar Azure Integration Runtime. Si el acceso está restringido a las direcciones IP que están aprobadas en las reglas de firewall, puede agregar direcciones IP de Azure Integration Runtime a la lista de permitidos.
También puede usar la característica del entorno de ejecución de integración de red virtual administrada de Azure Data Factory para acceder a la red local sin instalar ni configurar un entorno de ejecución de integración autohospedado.
Consulte Estrategias de acceso a datos para más información sobre los mecanismos de seguridad de red y las opciones que admite Data Factory.
Nota
Asegúrese de que el entorno de ejecución de integración puede acceder a todos los [servidor de nodo de nombres]:[puerto de nodo de nombres] y [servidores de nodos de datos]:[puerto de nodo de datos] del clúster de Hadoop. El [puerto de nodo de nombres] predeterminado es 50070 y el [puerto de nodo de datos] es 50075.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado a HDFS mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado a HDFS en la interfaz de usuario de Azure Portal.
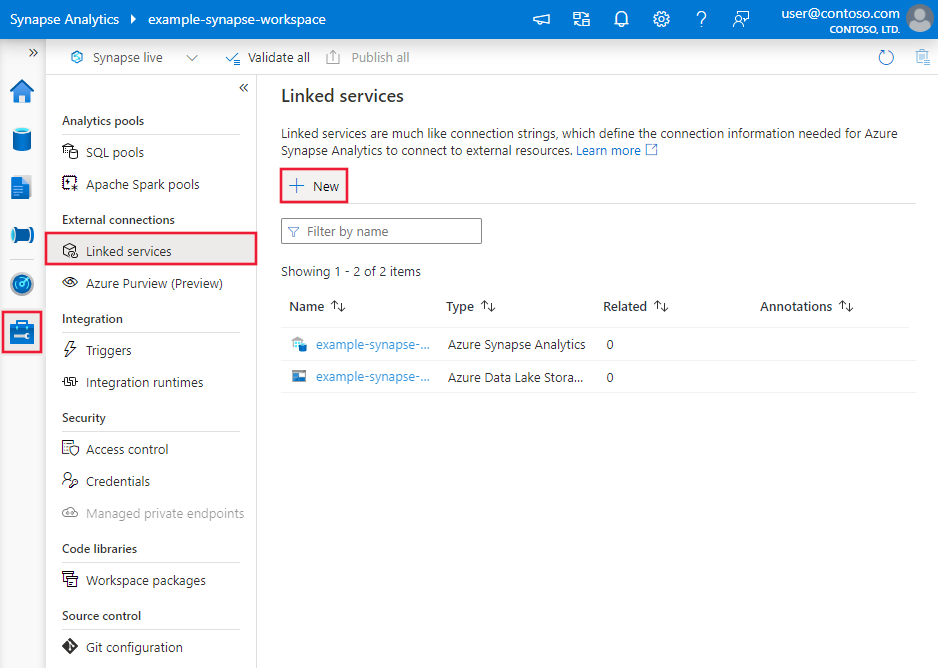
Vaya a la pestaña "Administrar" de su área de trabajo de Azure Data Factory o Synapse y seleccione "Servicios vinculados"; a continuación, haga clic en "Nuevo":
Busque HDFS y seleccione su conector.
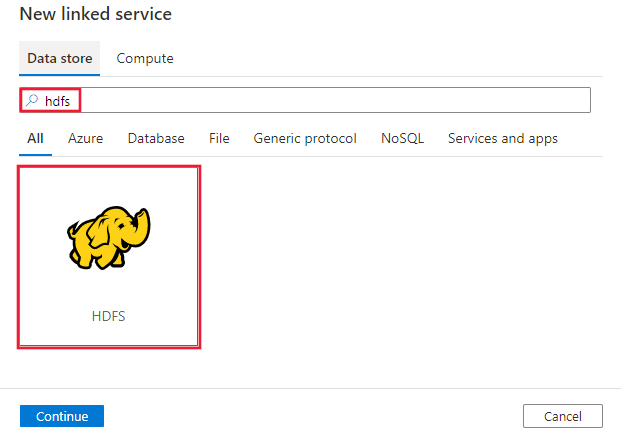
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
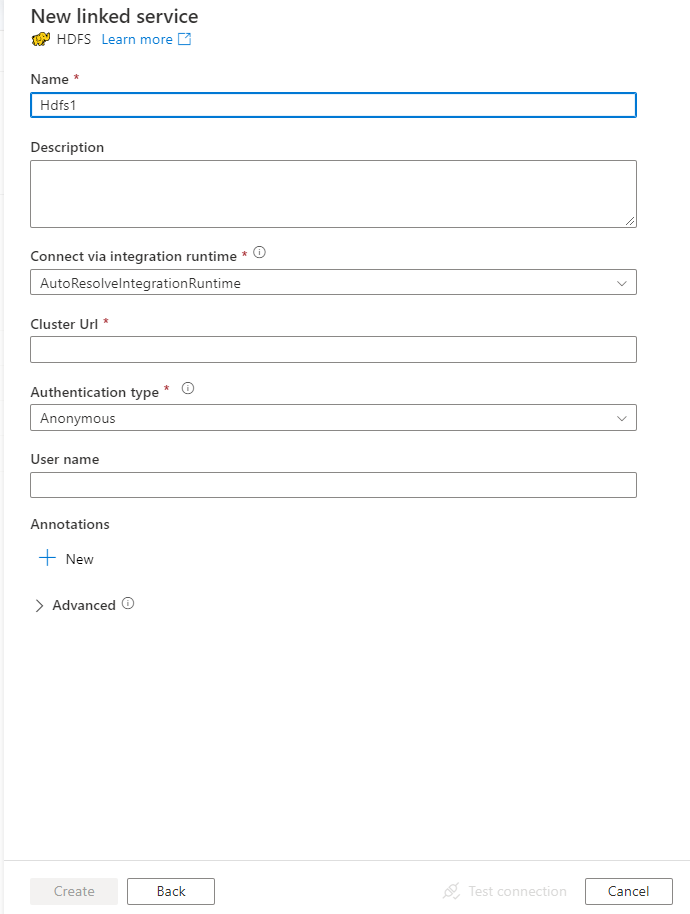

Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades de Data Factory específicas de HDFS.
Propiedades del servicio vinculado
Las siguientes propiedades son compatibles con el servicio vinculado de HDFS:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en Hdfs. | Sí |
| url | Dirección URL a HDFS | Sí |
| authenticationType | Los valores permitidos son Anónima o Windows. Para configurar el entorno local, consulte la sección Uso de la autenticación Kerberos para el conector HDFS. |
Sí |
| userName | Nombre de usuario para la autenticación de Windows. Para la autenticación Kerberos, especifique <username>@<domain>.com. | Sí (para la autenticación de Windows) |
| password | Contraseña para la autenticación de Windows. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | Sí (para la autenticación de Windows) |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Para más información, consulte la sección Requisitos previos. Si no se especifica el entorno de ejecución de integración, el servicio usa la instancia predeterminada de Azure Integration Runtime. | No |
Ejemplo: Uso de autenticación anónima
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo: Uso de autenticación de Windows
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
Para ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte Conjuntos de datos.
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
- Formato Avro
- Formato binario
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Las propiedades siguientes se admiten para HDFS en la configuración location del conjunto de datos basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de location del conjunto de datos se debe establecer en HdfsLocation. |
Sí |
| folderPath | Ruta de acceso a la carpeta. Si quiere usar un carácter comodín para filtrar la carpeta, omita este valor y especifique la ruta de acceso en la configuración del origen de actividad. | No |
| fileName | Nombre de archivo en la propiedad folderPath especificada. Si quiere usar un carácter comodín para filtrar archivos, omita este valor y especifique el nombre de archivo en la configuración del origen de actividad. | No |
Ejemplo:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propiedades de la actividad de copia
Para ver una lista completa de las secciones y propiedades que están disponibles para definir actividades, consulte Canalizaciones y actividades. En esta sección se proporciona una lista de las propiedades que el origen HDFS admite.
HDFS como origen
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
- Formato Avro
- Formato binario
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Las propiedades siguientes se admiten para HDFS en la configuración storeSettings del origen de copia basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de storeSettings se debe establecer en HdfsReadSettings. |
Sí |
| Búsqueda de los archivos que se van a copiar | ||
| OPCIÓN 1: ruta de acceso estática |
Copia de la ruta de acceso de archivo o carpeta especificada en el conjunto de datos. Si quiere copiar todos los archivos de una carpeta, especifique también wildcardFileName como *. |
|
| OPCIÓN 2: carácter comodín - wildcardFolderPath |
Ruta de acceso de carpeta con caracteres comodín para filtrar las carpetas de origen. Los caracteres comodín permitidos son: * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter). Use ^ como escape si el nombre real de la carpeta contiene un carácter comodín o este carácter de escape. Para ver más ejemplos, consulte Ejemplos de filtros de carpetas y archivos. |
No |
| OPCIÓN 2: carácter comodín - wildcardFileName |
Nombre de archivo con caracteres comodín en la propiedad folderPath o wildcardFolderPath especificada para filtrar los archivos de origen. Los caracteres comodín permitidos son: * (equivale a cero o más caracteres) y ? (equivale a cero o un único carácter); use ^ como carácter de escape si el nombre de archivo real tiene un carácter comodín o este carácter de escape dentro. Para ver más ejemplos, consulte Ejemplos de filtros de carpetas y archivos. |
Sí |
| OPCIÓN 3: una lista de archivos - fileListPath |
Indica que se copie un conjunto de archivos especificado. Apunte a un archivo de texto que incluya una lista de archivos que quiera copiar (un archivo por línea, con la ruta de acceso relativa a la ruta de acceso configurada en el conjunto de datos). Al usar esta opción, no especifique un nombre de archivo en el conjunto de datos. Para ver más ejemplos, consulte Ejemplos de lista de archivos. |
No |
| Configuración adicional | ||
| recursive | Indica si los datos se leen de forma recursiva de las subcarpetas o solo de la carpeta especificada. Cuando recursive se establece en true y el receptor es un almacén basado en archivos, no se copia ni crea ninguna carpeta o subcarpeta vacías en el receptor. Los valores permitidos son: True (valor predeterminado) y False. Esta propiedad no se aplica al configurar fileListPath. |
No |
| deleteFilesAfterCompletion | Indica si los archivos binarios se eliminarán del almacén de origen después de moverse correctamente al almacén de destino. Cada archivo se elimina individualmente, de modo que cuando se produzca un error en la actividad de copia, algunos archivos ya se habrán copiado al destino y se habrán eliminado del origen, mientras que otros seguirán aún en el almacén de origen. Esta propiedad solo es válida en el escenario de copia de archivos binarios. El valor predeterminado es false. |
No |
| modifiedDatetimeStart | Los archivos se filtran en función del atributo Last Modified. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart, y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato 2018-12-01T05:00:00Z. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene un valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene el valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea inferior al valor de fecha y hora.Esta propiedad no se aplica al configurar fileListPath. |
No |
| modifiedDatetimeEnd | Igual que el anterior. | |
| enablePartitionDiscovery | En el caso de archivos con particiones, especifique si quiere analizar las particiones de la ruta de acceso del archivo y agregarlas como columnas de origen adicionales. Los valores permitidos son false (valor predeterminado) y true. |
No |
| partitionRootPath | Cuando esté habilitada la detección de particiones, especifique la ruta de acceso raíz absoluta para poder leer las carpetas con particiones como columnas de datos. Si no se especifica, de forma predeterminada, - Cuando se usa la ruta de acceso de archivo en un conjunto de datos o una lista de archivos del origen, la ruta de acceso raíz de la partición es la ruta de acceso configurada en el conjunto de datos. - Cuando se usa el filtro de carpeta con caracteres comodín, la ruta de acceso raíz de la partición es la subruta antes del primer carácter comodín. Por ejemplo, supongamos que configura la ruta de acceso en el conjunto de datos como "root/folder/year=2020/month=08/day=27": - Si especifica la ruta de acceso raíz de la partición como "root/folder/year=2020", la actividad de copia generará dos columnas más, month y day, con el valor "08" y "27", respectivamente, además de las columnas de los archivos.- Si no se especifica la ruta de acceso raíz de la partición, no se generará ninguna columna adicional. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
| Configuración de DistCp | ||
| distcpSettings | Grupo de propiedades que se va a usar al utilizar HDFS DistCp. | No |
| resourceManagerEndpoint | Punto de conexión de YARN (Yet Another Resource Negotiator) | Sí, si se utiliza DistCp |
| tempScriptPath | Ruta de acceso de carpeta que se usa para almacenar el script del comando DistCp temporal. El archivo de script se genera y se eliminará después de que haya finalizado el trabajo de copia. | Sí, si se utiliza DistCp |
| distcpOptions | Opciones adicionales que se proporcionan al comando DistCp. | No |
Ejemplo:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Ejemplos de filtros de carpetas y archivos
En esta sección se describe el comportamiento resultante si se usa un filtro de carácter comodín con la ruta de acceso de carpeta y el nombre de archivo.
| folderPath | fileName | recursive | Resultado de estructura de carpeta de origen y filtro (se recuperan los archivos en negrita) |
|---|---|---|---|
Folder* |
(vacío, usar el valor predeterminado) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(vacío, usar el valor predeterminado) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Ejemplos de lista de archivos
En esta sección se describe el comportamiento resultante de usar una ruta de acceso de la lista de archivos en el origen de la actividad de copia. Se asume que tiene la siguiente estructura de carpetas de origen y quiere copiar los archivos que están en negrita:
| Estructura de origen de ejemplo | Contenido de FileListToCopy.txt | Configuración |
|---|---|---|
| root FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv Metadatos FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
El conjunto de datos: - Ruta de acceso de la carpeta: root/FolderAEn el origen de la actividad de copia: - Ruta de acceso de la lista de archivos: root/Metadata/FileListToCopy.txt La ruta de acceso de la lista de archivos apunta a un archivo de texto en el mismo almacén de datos que incluye una lista de archivos que se quiere copiar (un archivo por línea, con la ruta de acceso relativa a la ruta de acceso configurada en el conjunto de datos). |
Uso de DistCp para copiar datos desde HDFS
DistCp es una herramienta de línea de comandos nativa de Hadoop para realizar una copia distribuida en un clúster de Hadoop. Al ejecutar un comando en DistCp, dicho comando primero enumera todos los archivos que se van a copiar y luego crea varios trabajos de asignación en el clúster de Hadoop. Cada trabajo de asignación realiza una copia binaria desde el origen al receptor.
La actividad de copia admite el uso de DistCp para copiar archivos tal cual en Azure Blob Storage (incluida la copia almacenada provisionalmente) o en Azure Data Lake Store. En este caso, DistCp puede aprovechar la versatilidad del clúster en lugar de ejecutarse en el entorno de ejecución de integración autohospedado. El uso de DistCp proporciona el mejor rendimiento de la copia, sobre todo si el clúster es muy eficaz. En función de la configuración, la actividad de copia crea automáticamente un comando DistCp, lo envía a un clúster de Hadoop y supervisa el estado de la copia.
Requisitos previos
Para usar DistCp con el fin de copiar los archivos tal cual desde HDFS a Azure Blob (incluida la copia almacenada provisionalmente) o Azure Data Lake Store, asegúrese de que el clúster de Hadoop cumpla los siguientes requisitos:
Los servicios de MapReduce y YARN están habilitados.
La versión de YARN es la 2.5 o una posterior.
El servidor HDFS se integra con el almacén de datos de destino: Azure Blob Storage o Azure Data Lake Store (ADLS Gen1) :
- El sistema de archivos de Azure Blob se admite de forma nativa en Hadoop 2.7 o superior. Solo necesita especificar la ruta de acceso de JAR en la configuración del entorno de Hadoop.
- El sistema de archivos de Azure Data Lake Store se empaqueta a partir de Hadoop 3.0.0-alpha1. Si la versión del clúster de Hadoop es anterior a esa versión, debe importar manualmente los paquetes JAR relacionados con Azure Data Lake Store (azure-datalake-store.jar) en el clúster desde aquí y especificar la ruta de acceso del archivo JAR en la configuración del entorno de Hadoop.
Prepare una carpeta temporal en HDFS. Esta carpeta temporal se usa para almacenar un script de shell de DistCp, por lo que ocupa varios kilobytes de espacio.
Asegúrese de que la cuenta de usuario que se proporciona en el servicio vinculado de HDFS tiene permiso para:
- Enviar una aplicación en YARN.
- Crear una subcarpeta y archivos de lectura y escritura en la carpeta temporal.
Configurations
Para configuraciones y ejemplos relacionados con DistCp, vaya a la sección HDFS como origen.
Uso de la autenticación Kerberos para el conector HDFS
Existen dos opciones para configurar el entorno local para usar la autenticación Kerberos para el conector HDFS. Puede elegir la que mejor se adapte a su situación.
- Opción 1: Unir una máquina del entorno de ejecución de integración autohospedado en el dominio Kerberos
- Opción 2: Habilitar la confianza mutua entre el dominio de Windows y el dominio Kerberos
Para ambas opciones, asegúrese de activar webhdfs en el clúster de Hadoop:
Cree la entidad de seguridad HTTP y el archivo keytab de webhdfs.
Importante
La entidad de seguridad HTTP de Kerberos debe comenzar por "HTTP/ " según la especificación SPNEGO de HTTP de Kerberos. Puede obtener más información sobre esto aquí.
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>Opciones de configuración de HDFS: agregue las tres propiedades siguientes en el archivo
hdfs-site.xml.<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
Opción 1: Unir una máquina del entorno de ejecución de integración autohospedado en el dominio Kerberos
Requisitos
- La máquina del entorno de ejecución de integración autohospedado debe unirse al dominio Kerberos y no a ninguno de Windows.
Cómo se configura
En el servidor KDC:
Cree una entidad de seguridad y especifique la contraseña.
Importante
El nombre de usuario no debe contener el nombre de host.
Kadmin> addprinc <username>@<REALM.COM>
En la máquina del entorno de ejecución de integración autohospedado:
Ejecute la utilidad Ksetup para configurar el dominio y el servidor del Centro de distribución de claves (KDC) de Kerberos.
La máquina debe configurarse como miembro de un grupo de trabajo, porque un dominio Kerberos es diferente a un dominio de Windows. Para lograr esta configuración, establezca el dominio Kerberos y agregue un servidor KDC mediante la ejecución de los siguientes comandos. Reemplace REALM.COM por su propio nombre de dominio.
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>Después de ejecutar estos comandos, reinicie el equipo.
Compruebe la configuración con el comando
Ksetup. La salida debe ser como la siguiente:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
En la factoría de datos o el área de trabajo de Synapse:
- Configure el conector HDFS mediante la autenticación de Windows junto con el nombre y la contraseña de la entidad de seguridad de Kerberos para conectarse al origen de datos de HDFS. Para conocer los detalles de la configuración, consulte la sección Propiedades del servicio vinculado.
Opción 2: Habilitar la confianza mutua entre el dominio de Windows y el dominio Kerberos
Requisitos
- La máquina del entorno de ejecución de integración autohospedado debe unirse a un dominio de Windows.
- Necesita permiso para actualizar la configuración del controlador de dominio.
Cómo se configura
Nota
Reemplace REALM.COM y AD.COM en el siguiente tutorial por su nombre de dominio y controlador de dominio.
En el servidor KDC:
Edite la configuración de KDC en el archivo krb5.conf para permitir que KDC confíe en el dominio de Windows; para ello, remítase a la siguiente plantilla de configuración. La configuración se encuentra de forma predeterminada en /etc/krb5.conf.
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }Después de configurar el archivo, reinicie el servicio KDC.
Prepare una entidad de seguridad de nombre krbtgt/REALM.COM@AD.COM en el servidor KDC con el comando siguiente:
Kadmin> addprinc krbtgt/REALM.COM@AD.COMEn el archivo de configuración del servicio de HDFS hadoop.security.auth_to_local, agregue
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//.
En el controlador de dominio:
Ejecute los siguientes comandos
Ksetuppara agregar una entrada de dominio:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMEstablezca una confianza entre el dominio de Windows y el dominio Kerberos. [password] es la contraseña de la entidad de seguridad krbtgt/REALM.COM@AD.COM.
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Seleccione el algoritmo de cifrado que se usó en Kerberos.
a. Vaya a Administrador de servidores>Administración de directivas de grupo>Dominio>Objetos de directiva de grupo>Default or Active Domain Policy (Directiva de dominio predeterminada o activa) y haga clic en Editar.
b. En el panel Editor de administración de directivas de grupo, seleccione Configuración del equipo>Directivas>Configuración de Windows>Configuración de seguridad>Directivas locales>Opciones de seguridad y configure Seguridad de red: Configure los tipos de cifrado permitidos para Kerberos.
c. Seleccione el algoritmo de cifrado que quiere usar cuando se conecte al servidor KDC. Puede seleccionar todas las opciones.
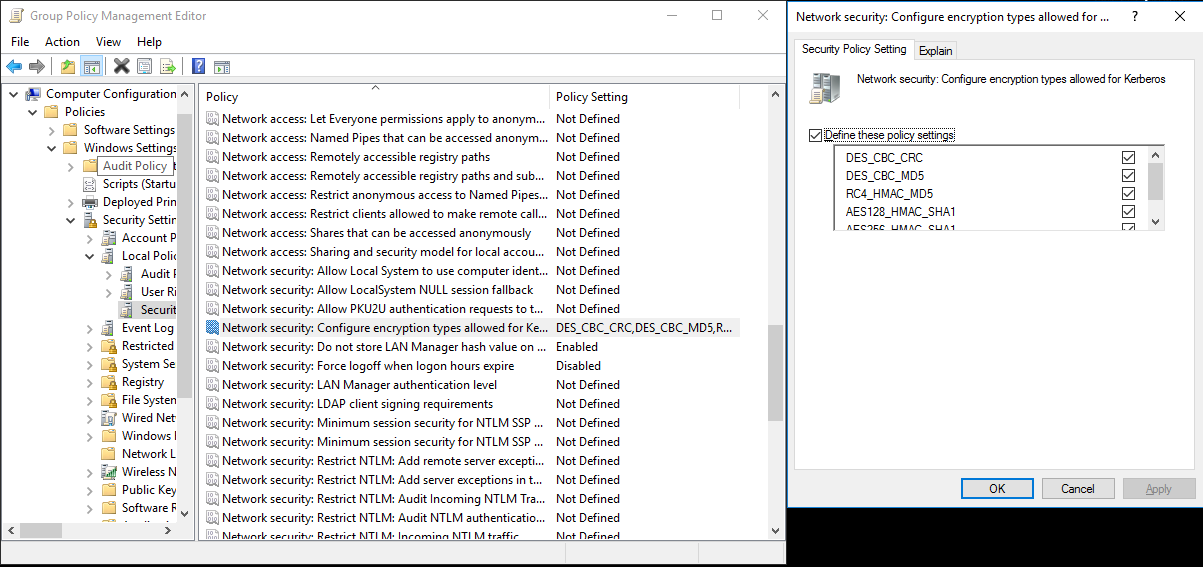
d. Use el comando
Ksetuppara especificar el algoritmo de cifrado que se usará en el dominio específico.C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Cree una asignación entre la cuenta de dominio y la entidad de seguridad de Kerberos para que pueda usar la entidad de seguridad de Kerberos en el dominio de Windows.
a. Seleccione Herramientas administrativas>Equipos y usuarios de Active Directory.
b. Configure las características avanzadas; para ello, seleccione Ver>Características avanzadas.
c. En el panel Características avanzadas, haga clic con el botón derecho en la cuenta con la que quiera crear las asignaciones y, en el panel Asignaciones de nombres, seleccione la pestaña Nombres Kerberos.
d. Agregue una entidad de seguridad del dominio Kerberos.
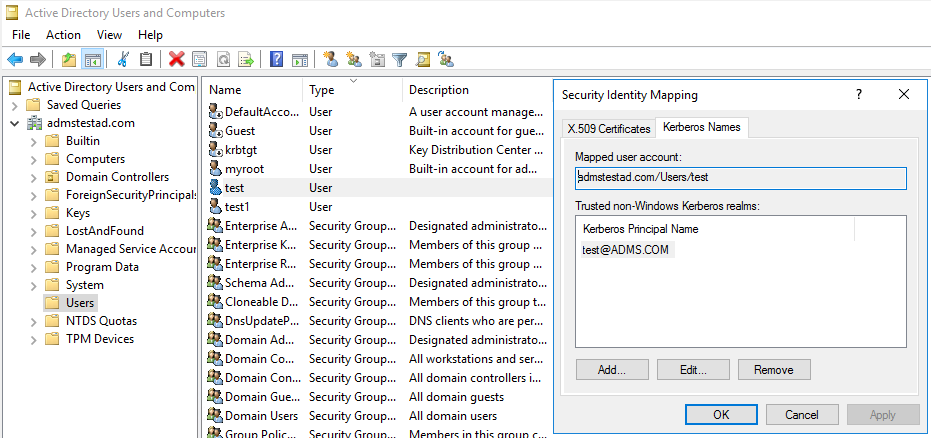
En la máquina del entorno de ejecución de integración autohospedado:
Ejecute los siguientes comandos
Ksetuppara agregar una entrada de dominio.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
En la factoría de datos o el área de trabajo de Synapse:
- Configure el conector de HDFS mediante la autenticación de Windows en combinación con la cuenta de dominio o la entidad de seguridad de Kerberos para conectarse al origen de datos de HDFS. Para conocer los detalles de la configuración, consulte la sección Propiedades del servicio vinculado.
Propiedades de la actividad de búsqueda
Para obtener más información sobre las propiedades de la actividad de búsqueda, consulte Actividad de búsqueda.
Propiedades de la actividad de eliminación
Para obtener más información sobre las propiedades de la actividad de eliminación, consulte Actividad de eliminación.
Modelos heredados
Nota
Estos modelos siguen siendo compatibles con versiones anteriores. Se recomienda usar el nuevo modelo descrito anteriormente, ya que la UI de creación ha cambiado para generar el nuevo modelo.
Modelo de conjunto de datos heredado
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en FileShare. | Sí |
| folderPath | Ruta de acceso a la carpeta. Se admite un filtro con caracteres comodín. Los caracteres comodín permitidos son * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter); use ^ como carácter de escape si el nombre de archivo real tiene un carácter comodín o este carácter de escape dentro. Ejemplos: rootfolder/subfolder/ver más en Ejemplos de filtros de carpetas y archivos. |
Sí |
| fileName | Filtro de nombre o de comodín para los archivos de la ruta "folderPath" especificada. Si no especifica ningún valor para esta propiedad, el conjunto de datos apunta a todos los archivos de la carpeta. Para filtrar, los caracteres comodín permitidos son * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter).- Ejemplo 1: "fileName": "*.csv"- Ejemplo 2: "fileName": "???20180427.txt"Use ^ como escape si el nombre real de la carpeta contiene un carácter comodín o este carácter de escape. |
No |
| modifiedDatetimeStart | Los archivos se filtran en función del atributo Last Modified. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart, y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato 2018-12-01T05:00:00Z. Tenga en cuenta que el rendimiento general del movimiento de datos se ve afectado si habilita esta configuración cuando desea aplicar un filtro de archivo a grandes cantidades de archivos. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene un valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene el valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea inferior al valor de fecha y hora. |
No |
| modifiedDatetimeEnd | Los archivos se filtran en función del atributo Last Modified. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart, y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato 2018-12-01T05:00:00Z. Tenga en cuenta que el rendimiento general del movimiento de datos se ve afectado si habilita esta configuración cuando desea aplicar un filtro de archivo a grandes cantidades de archivos. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene un valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene el valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea inferior al valor de fecha y hora. |
No |
| format | Si desea copiar los archivos tal cual entre los almacenes basados en archivos (copia binaria), omita la sección de formato en las definiciones de los conjuntos de datos de entrada y salida. Si quiere analizar archivos con un formato concreto, se admiten los siguientes tipos de formato de archivo: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Establezca la propiedad type de formato en uno de los siguientes valores. Para más información, consulte las secciones Formato de texto, Formato Json, Formato Avro, Formato ORC y Formato Parquet. |
No (solo para el escenario de copia binaria) |
| compression | Especifique el tipo y el nivel de compresión de los datos. Para más información, consulte el artículo sobre códecs de compresión y formatos de archivo compatibles. Estos son los tipos que se admiten: Gzip, Deflate, Bzip2 y ZipDeflate. Estos son los niveles que se admiten: Optimal y Fastest. |
No |
Sugerencia
Para copiar todos los archivos en una carpeta, especifique solo folderPath.
Para copiar un único archivo con un nombre determinado, especifique folderPath con el elemento de carpeta y fileName con el nombre de archivo.
Para copiar un subconjunto de archivos en una carpeta, especifique folderPath con el elemento de carpeta y fileName con el filtro de comodín.
Ejemplo:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Modelo de origen de actividad de copia heredada
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en: HdfsSource. | Sí |
| recursive | Indica si los datos se leen de forma recursiva de las subcarpetas o solo de la carpeta especificada. Cuando recursive se establece en true y el receptor es un almacén basado en archivos, no se copiará ni creará una subcarpeta o carpeta vacía en el receptor. Los valores permitidos son: True (valor predeterminado) y False. |
No |
| distcpSettings | Grupo de propiedades cuando se usa la herramienta DistCp de HDFS. | No |
| resourceManagerEndpoint | Punto de conexión de Resource Manager de YARN | Sí, si se utiliza DistCp |
| tempScriptPath | Ruta de acceso de carpeta que se usa para almacenar el script del comando DistCp temporal. El archivo de script se genera y se eliminará después de que haya finalizado el trabajo de copia. | Sí, si se utiliza DistCp |
| distcpOptions | Se proporcionan opciones adicionales para el comando DistCp. | No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo: Origen HDFS de la actividad de copia mediante DistCp
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
Contenido relacionado
Consulte la tabla de almacenes de datos compatibles para ver una lista de almacenes de datos que la actividad de copia admite como orígenes y receptores.