Use Azure Data Factory para migrar datos de un clúster de Hadoop local a Azure Storage
SE APLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
Azure Data Factory proporciona un mecanismo eficaz, sólido y rentable para migrar datos a escala desde una versión local de HDFS a Azure Blob Storage o Azure Data Lake Storage Gen2.
Data Factory ofrece dos enfoques básicos para la migración de datos desde una versión local de HDFS a Azure. Seleccione el enfoque en función de su escenario.
- Modo DistCp de Data Factory (recomendado): en Data Factory, puede usar DistCp (copia distribuida) para copiar archivos tal cual a Azure Blob Storage (incluida la copia almacenada provisionalmente) o a Azure Data Lake Store Gen2. Use Data Factory integrado con DistCp para aprovechar el clúster eficaz existente para lograr el mejor rendimiento de copia. También obtendrá las ventajas de la programación flexible y una experiencia de supervisión unificada de Data Factory. En función de la configuración de Data Factory, la actividad de copia crea automáticamente un comando DistCp, envía los datos a un clúster de Hadoop y supervisa el estado de la copia. Se recomienda el modo DistCp de Data Factory para la migración de datos desde un clúster de Hadoop local a Azure.
- Modo del entorno de ejecución de integración nativo de Data Factory: DistCp no es una opción en todos los escenarios. Por ejemplo, en un entorno de Azure Virtual Networks, la herramienta DistCp no admite el emparejamiento privado de Azure ExpressRoute con un punto de conexión de red virtual de Azure Storage. Además, en algunos casos, no deseará usar el clúster de Hadoop existente como motor de migración de datos con el fin de evitar las cargas pesadas en el clúster, que afectan al rendimiento de los trabajos de extracción, transformación y carga de datos existentes. En su lugar, puede usar la funcionalidad nativa del entorno de ejecución de integración de Data Factory como motor para copiar los datos de la versión local de HDFS a Azure.
En este artículo se proporciona la siguiente información sobre los dos enfoques:
- Rendimiento
- Resistencia de copia
- Seguridad de las redes
- Arquitectura de soluciones de alto nivel
- Procedimientos recomendados para la implementación
Rendimiento
En el modo Distcp de Data Factory, el rendimiento es el mismo que si se usa la herramienta DistCp de forma independiente. El modo DistCp de Data Factory maximiza la capacidad del clúster de Hadoop existente. Puede usar DistCp para la copia de grandes volúmenes entre clústeres o dentro del mismo clúster.
DistCp utiliza MapReduce para llevar a cabo la distribución, el control y la recuperación de errores, y la generación de informes. Expande una lista de archivos y directorios en la entrada para la asignación de tareas. Cada tarea copia una partición de archivo que se especifica en la lista de origen. Puede usar Data Factory integrado con DistCp para compilar canalizaciones que usen completamente el ancho de banda de red, las operaciones de IOPS de almacenamiento y el ancho de banda para maximizar el rendimiento del movimiento de datos en su entorno.
El modo del entorno de ejecución de integración de Data Factory nativo también permite el paralelismo en diferentes niveles. Puede usar el paralelismo para utilizar por completo el ancho de banda de red, las IOPS de almacenamiento y el ancho de banda para maximizar el rendimiento del movimiento de datos:
- Una sola actividad de copia puede aprovechar los recursos de proceso escalables. Con un entorno de ejecución de integración autohospedado, puede escalar verticalmente el equipo o escalar horizontalmente a varias máquinas (hasta cuatro nodos). Una única actividad de copia particiona su conjunto de archivos en todos los nodos.
- Una única actividad de copia lee y escribe en el almacén de datos mediante varios subprocesos.
- El flujo de control de Data Factory puede iniciar varias actividades de copia en paralelo. Por ejemplo, puede usar For Each loop (Bucle For Each).
Para más información, consulte la guía sobre el rendimiento de la actividad de copia.
Resistencia
En el modo DistCp de Data Factory, puede usar diferentes parámetros de la línea de comandos de DistCp (por ejemplo,-i, omitir errores; o -update, escribir datos cuando el tamaño del archivo de origen no es el mismo que el de destino) para distintos niveles de resistencia.
En el modo de entorno de ejecución de integración nativo de Data Factory, en una ejecución de actividad de copia única, Data Factory tiene un mecanismo de reintento integrado. Puede controlar ciertos errores transitorios en los almacenes de datos o en la red subyacente.
Al realizar copias binarias de la versión local de HDFS a Blob Storage y de la versión local de HDFS a Data Lake Store Gen2, Data Factory incluye automáticamente puntos de control en mayor medida. Si se ha producido un error en la ejecución de la actividad de copia o se ha agotado el tiempo de espera, en un reintento posterior (asegúrese de que el número de reintentos sea mayor que 1), la copia se reanuda desde el último punto de error en lugar de comenzar desde el principio.
Seguridad de red
De forma predeterminada, Data Factory transfiere datos desde la versión local de HDFS a Blob Storage o Azure Data Lake Storage Gen2 mediante una conexión cifrada y el protocolo HTTPS. HTTPS proporciona cifrado de datos en tránsito y evita la interceptación y ataques de tipo "Man in the middle".
Como alternativa, si no quiere que los datos se transfieran por la red pública de Internet, la transferencia de datos con un vínculo de emparejamiento privado por medio de ExpressRoute ofrece más seguridad.
Arquitectura de la solución
En esta imagen se muestra cómo migrar datos por la red pública de Internet:
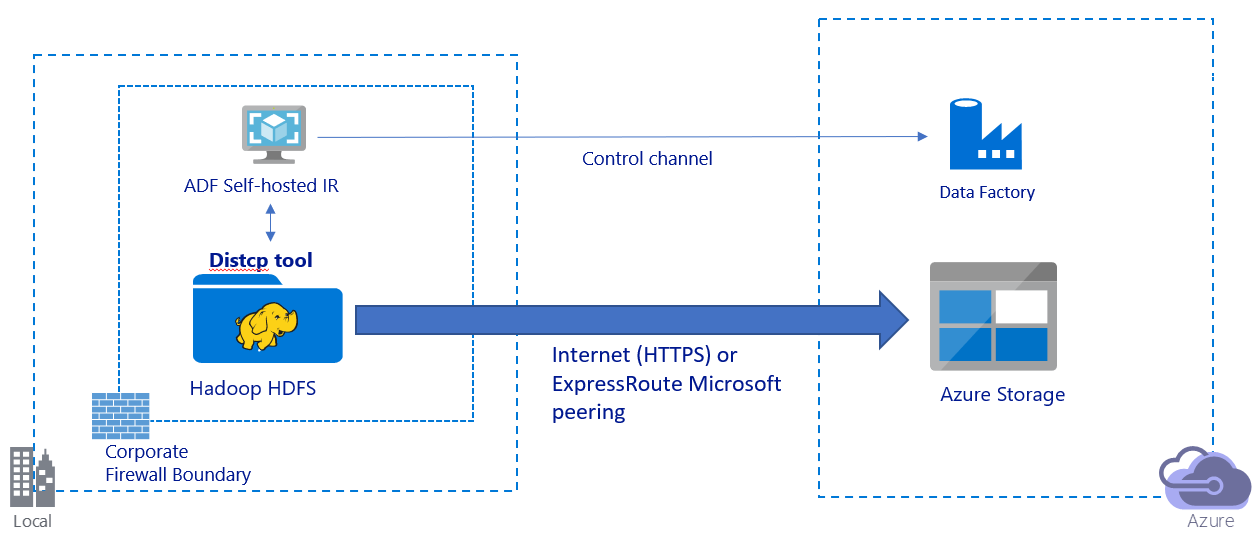
- En esta arquitectura, los datos se transfieren de forma segura mediante HTTPS por la red pública de Internet.
- En un entorno de red pública se recomienda usar el modo DistCp de Data Factory. Puede aprovechar las ventajas de un clúster existente eficaz para lograr el mejor rendimiento de copia. También obtendrá las ventajas de la programación flexible y la experiencia de supervisión unificada de Data Factory.
- Para esta arquitectura, debe instalar el entorno de ejecución de integración autohospedado de Data Factory en una máquina Windows con un firewall corporativo para enviar el comando DistCp al clúster de Hadoop y supervisar el estado de la copia. Como esta máquina no será el motor que moverá datos (solo se usa con fines de control), su capacidad no afecta al rendimiento del movimiento de datos.
- Se admiten los parámetros existentes del comando DistCp.
En esta imagen se muestra cómo migrar datos con un vínculo privado:
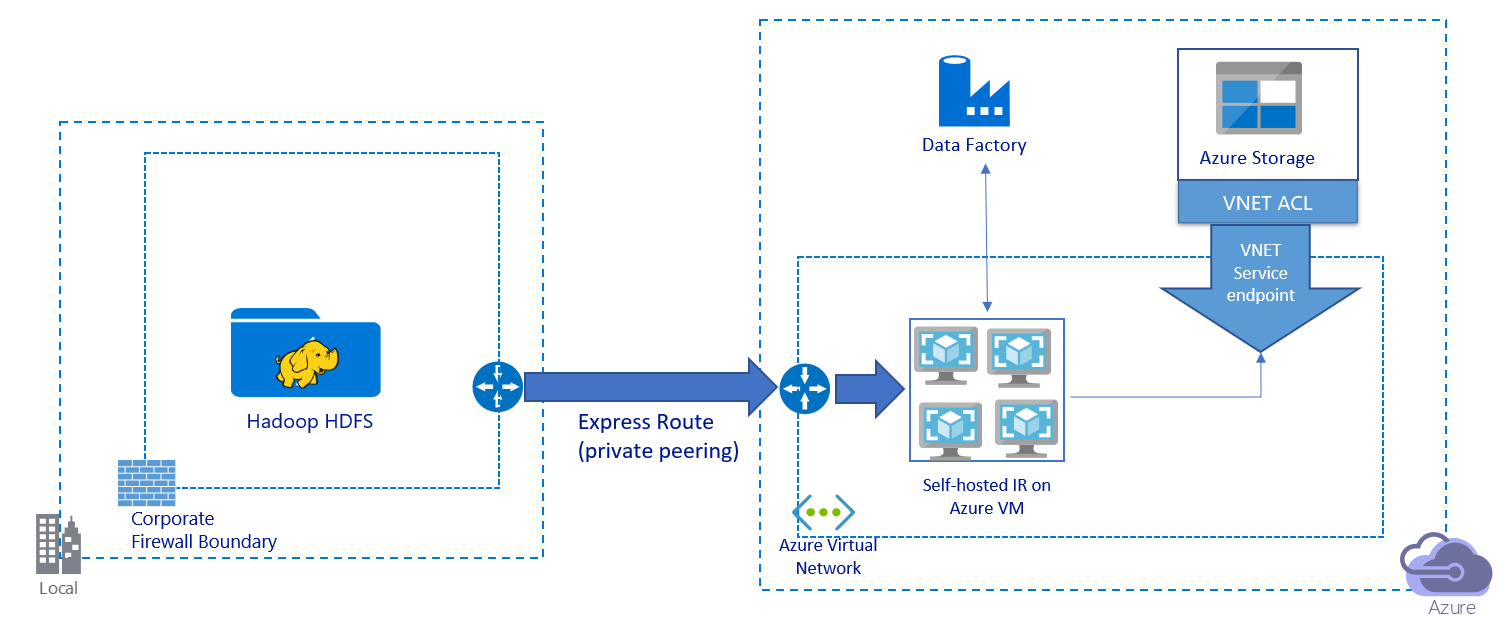
- En esta arquitectura, los datos se migran con un vínculo de emparejamiento privado mediante Azure ExpressRoute. Los datos nunca atraviesan la red pública de Internet.
- La herramienta DistCp no admite el emparejamiento privado de ExpressRoute con un punto de conexión de red virtual de Azure Storage. Se recomienda usar la funcionalidad nativa de Data Factory mediante el entorno de ejecución de integración para migrar los datos.
- Para esta arquitectura, debe instalar el entorno de ejecución de integración autohospedado de Data Factory en una máquina virtual Windows dentro de la red virtual de Azure. Puede escalar verticalmente una máquina virtual o escalar horizontalmente a varias máquinas virtuales manualmente para utilizar la totalidad del ancho de banda e IOPS de almacenamiento de la red.
- La configuración recomendada con la que empezar en cada máquina virtual de Azure (con el entorno de ejecución de integración autohospedado de Data Factory) es Standard_D32s_v3 con 32 vCPU y 128 GB de memoria. Puede supervisar el uso de la CPU y de la memoria de la máquina virtual durante la migración de datos para ver si necesita escalar verticalmente la máquina virtual para mejorar el rendimiento o reducirla verticalmente para reducir costos.
- También, para escalar horizontalmente, puede asociar hasta cuatro nodos de máquina virtual a un solo entorno de ejecución de integración autohospedado. Un único trabajo de copia que se ejecute en un entorno de ejecución de integración autohospedado realizará particiones automáticamente en el conjunto de archivos y usará todos los nodos de máquina virtual para copiar los archivos en paralelo. Para lograr una alta disponibilidad, se recomienda empezar con dos nodos de máquina virtual para evitar que se genere un escenario de un único punto de error durante la migración de datos.
- Al usar esta arquitectura, tiene disponibles tanto la migración de datos de la instantánea inicial como la migración de datos diferencial.
Procedimientos recomendados para la implementación
Se recomienda seguir estos procedimientos recomendados al implementar la migración de datos.
Autenticación y administración de identidades
- Para autenticarse en HDFS, se pueden usar Windows (Kerberos) o Anónima.
- Se admiten varios tipos de autenticación para conectarse a Azure Blob Storage. Se recomienda encarecidamente usar identidades administradas para recursos de Azure. Creadas a partir de una identidad de Data Factory administrada automáticamente en Microsoft Entra ID, las identidades administradas permiten configurar canalizaciones sin tener que proporcionar credenciales en la definición del servicio vinculado. Como alternativa, puede autenticarse en Blob Storage mediante una entidad de servicio, una firma de acceso compartido o una clave de la cuenta de almacenamiento.
- También se admiten varios tipos de autenticación para conectarse a Data Lake Storage Gen2. Se recomienda encarecidamente el uso de identidades administradas para los recursos de Azure, aunque también se puede usar una entidad de servicio o una clave de la cuenta de almacenamiento.
- Si no va a usar identidades administradas para los recursos de Azure, es muy recomendable almacenar las credenciales en Azure Key Vault para facilitar la administración y la rotación de las claves de forma centralizada sin modificar los servicios vinculados de Data Factory. También se trata de un procedimiento recomendado de CI/CD.
Migración de datos de instantánea inicial
En el modo DistCp de Data Factory, puede crear una actividad de copia para enviar el comando DistCp y usar distintos parámetros para controlar el comportamiento inicial de la migración de datos.
En el modo del entorno de ejecución de integración de Data Factory se recomienda la partición de datos, especialmente para la migración de más de 10 TB de datos. Para realizar la partición de los datos, use los nombres de carpeta de HDFS. Después, cada trabajo de copia de Data Factory puede copiar una partición de carpeta a la vez. Puede ejecutar varios trabajos de copia de Data Factory simultáneamente para mejorar el rendimiento.
Si se produce un error en alguno de los trabajos de copia debido a una incidencia transitoria de la red o del almacén de datos, puede volver a ejecutar el trabajo de copia con errores para volver a cargar esa partición específica de HDFS. Esto no afectará a otros trabajos de copia que carguen otras particiones.
Migración de datos diferencial
En el modo DistCp de Data Factory, puede usar el parámetro de la línea de comandos de DistCp -update, escribir datos cuando el tamaño del archivo de origen no sea el mismo que el de destino, para la migración de datos diferencial.
En el modo de integración nativo de Data Factory, la manera más eficaz de identificar los archivos nuevos o modificados de HDFS es mediante una convención de nomenclatura con particiones de tiempo. Cuando se han realizado particiones de tiempo en los datos de HDFS con la información del segmento de tiempo en el nombre de archivo o carpeta (por ejemplo, /aaaa/mm/dd/archivo. csv), la canalización puede identificar fácilmente qué archivos y carpetas copiar de forma incremental.
Como alternativa, si los datos de HDFS no tienen particiones de tiempo, Data Factory puede identificar los archivos nuevos o modificados por el valor de LastModifiedDate. Data Factory examina todos los archivos de HDFS y copia solo los archivos nuevos y actualizados que tengan una marca de tiempo de última modificación mayor que el valor establecido.
Si tiene un gran número de archivos en HDFS, el análisis de archivos inicial podría tardar mucho tiempo, independientemente de la cantidad de archivos que cumplan la condición de filtro. En este escenario, se recomienda dividir primero los datos con la misma partición que usó para la migración de la instantánea inicial. Después, el análisis de archivos puede realizarse en paralelo.
Precio estimado
Considere la siguiente canalización de migración de datos de HDFS a Azure Blob Storage:
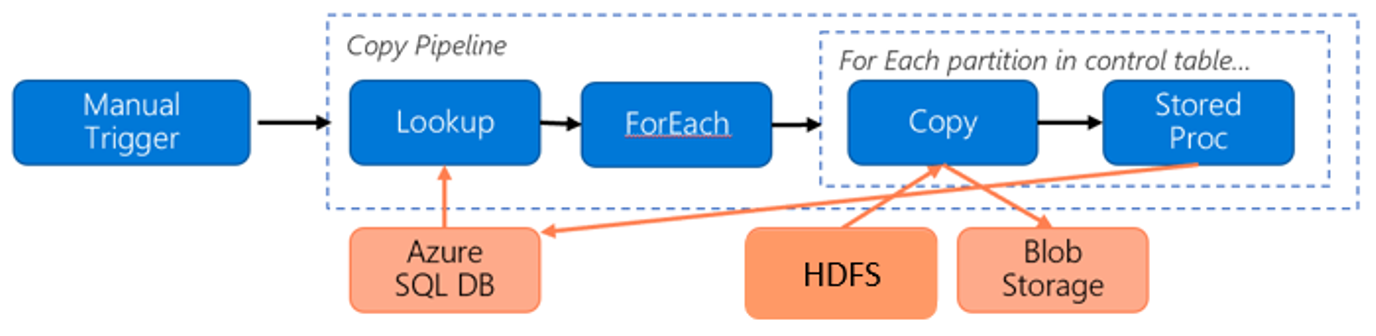
Considerando la información siguiente:
- Volumen total de datos de 1 PB.
- Los datos se migran mediante el modo del entorno de ejecución de integración de Data Factory.
- 1 PB se divide en particiones de 1000 y cada copia mueve una partición.
- Cada actividad de copia se configura con un entorno de ejecución de integración autohospedado asociado a cuatro máquinas y logra un rendimiento de 500 MBps.
- La simultaneidad de ForEach se establece en 4 y el rendimiento agregado es de 2 Gbps.
- En total, se tardan 146 horas en completar la migración.
Este es el precio estimado en función de las suposiciones anteriores:
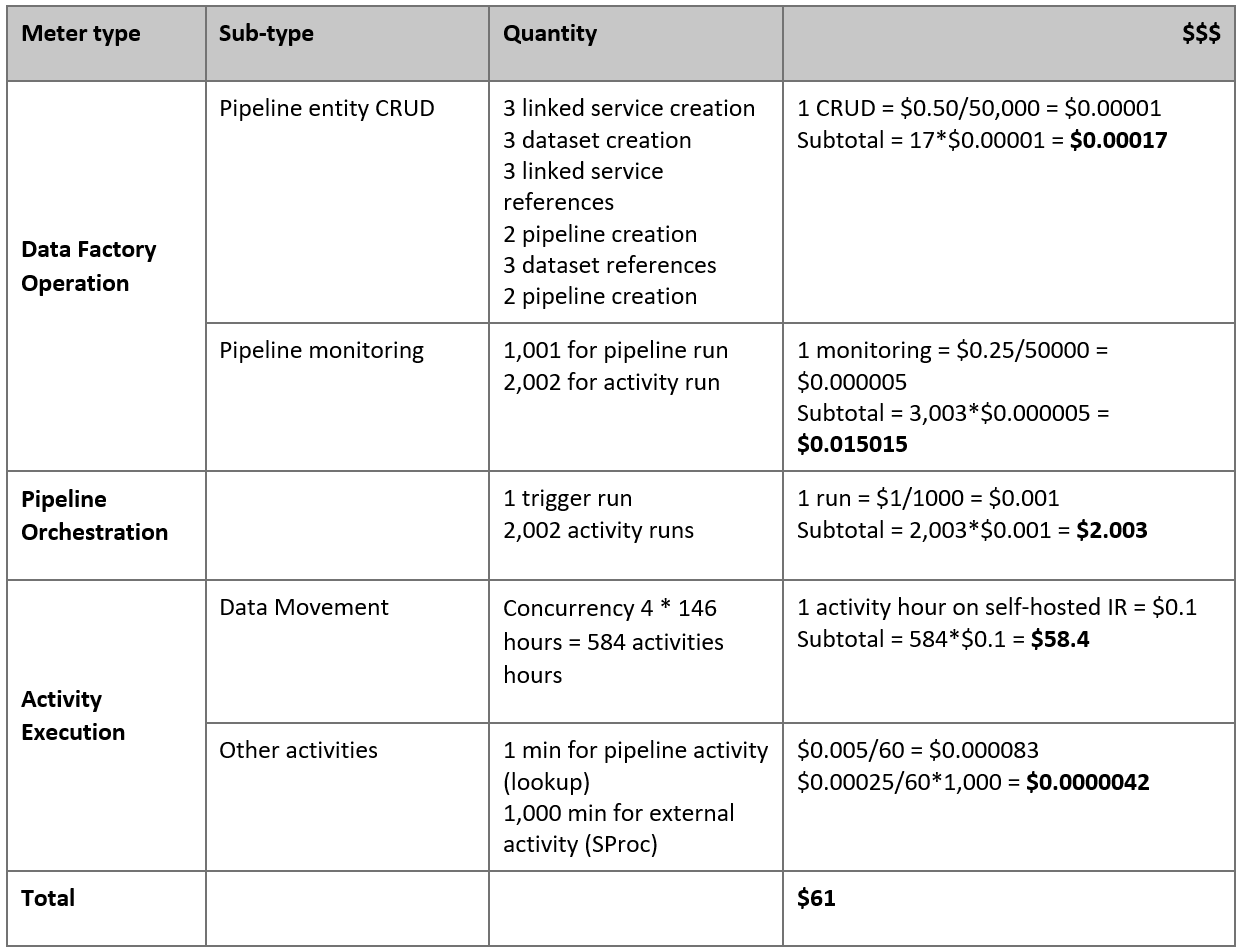
Nota:
Este es un ejemplo de precios hipotético. Los precios reales dependen del rendimiento real de su entorno. No se incluye el precio de la máquina virtual Windows de Azure (con entorno de ejecución de integración autohospedado instalado).
Referencias adicionales
- Conector de HDFS
- Conector de Azure Blob Storage
- Conector de Azure Data Lake Storage Gen2
- Guía de optimización y rendimiento de la actividad de copia
- Creación y configuración de un entorno de ejecución de integración autohospedado
- Alta disponibilidad y escalabilidad de un entorno de ejecución de integración autohospedado
- Consideraciones sobre la seguridad del movimiento de datos
- Almacenamiento de credenciales en Azure Key Vault
- Copia incremental de un archivo por el nombre de archivo con particiones de tiempo
- Copia incremental de archivos nuevos y modificados según LastModifiedDate
- Página de precios de Data Factory
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de