Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Los flujos de datos están disponibles tanto en canalizaciones de Azure Data Factory como en canalizaciones de Azure Synapse Analytics. Este artículo se aplica a los flujos de datos de mapeo. Si no está familiarizado con las transformaciones, consulte el artículo introductorio Transformación de datos mediante flujos de datos de asignación.
Sugerencia
Para obtener la transformación equivalente (Obtener datos) en Dataflow Gen2, consulte Una guía de Dataflow Gen2 para asignar usuarios de flujo de datos.
Una transformación de origen configura el origen de datos para el flujo de datos. Al diseñar flujos de datos, el primer paso será siempre configurar una transformación de origen. Para agregar un origen, seleccione el cuadro Agregar origen en el lienzo de Data Flow.
Cada flujo de datos requiere al menos una transformación de origen, pero puede agregar tantos orígenes como sea necesario para completar las transformaciones de datos. Puede combinar esos orígenes con una transformación de combinación, búsqueda o unión.
Cada transformación de origen se asocia exactamente con un conjunto de datos o servicio vinculado. El conjunto de datos define la forma y la ubicación de los datos que quiere escribir o leer. Si va a utilizar un conjunto de datos basado en archivos, puede usar caracteres comodín y listas de archivos en el origen para trabajar con más de un archivo a la vez.
Conjuntos de datos en línea
La primera decisión que se toma al crear una transformación de origen es si la información de origen se define dentro de un objeto de conjunto de datos o dentro de la transformación de origen. La mayoría de los formatos están disponibles solo en una opción o en la otra. Para obtener información sobre cómo usar un conector específico, consulte el documento adecuado del conector.
Cuando un formato se admita tanto en la opción en línea como en un objeto de conjunto de datos, existen ventajas para ambos. Los objetos de conjunto de datos son entidades reutilizables que se pueden utilizar en otros flujos de datos y actividades, como Copiar. Estas entidades reutilizables son especialmente útiles cuando se usa un esquema protegido. Los conjuntos de datos no se basan en Spark. En ocasiones, es posible que necesite reemplazar determinados valores o la proyección del esquema en la transformación de origen.
Se recomiendan los conjuntos de datos en línea cuando se usan esquemas flexibles, instancias de origen único u orígenes con parámetros. Si el origen contiene muchos parámetros, los conjuntos de datos en línea permiten no crear un objeto "ficticio". Los conjuntos de datos en línea se basan en Spark y sus propiedades son nativas para el flujo de datos.
Para usar un conjunto de datos en línea, seleccione el formato que desee en el selector Tipo de origen. En lugar de seleccionar un conjunto de datos de origen, seleccione el servicio vinculado al que desea conectarse.
Opciones del esquema
Dado que un conjunto de datos insertado se define dentro del flujo de datos, no hay un esquema definido asociado al conjunto de datos insertado. En la pestaña Proyección, puede importar el esquema de datos de origen y almacenar ese esquema como una proyección de origen. En esta pestaña, encontrará un botón "Opciones de esquema" que le permite definir el comportamiento del servicio de detección de esquemas de ADF.
- Usar esquema proyectado: esta opción es útil cuando tiene un gran número de archivos de origen que ADF examina como origen. El comportamiento predeterminado de ADF es detectar el esquema de cada archivo de origen. Pero si ya tiene una proyección predefinida almacenada en la transformación de origen, puede establecerla en true y ADF omite la detección automática de cada esquema. Con esta opción activada, la transformación de origen puede leer todos los archivos de forma mucho más rápida, aplicando el esquema predefinido a cada archivo.
- Permitir desfase de esquema: active el desfase de esquema para que el flujo de datos permita nuevas columnas que aún no están definidas en el esquema de origen.
- Validar esquema: al establecer esta opción, se producirá un error en el flujo de datos si alguna columna y tipo definido en la proyección no coincide con el esquema detectado de los datos de origen.
- Inferir tipos de columnas desviadas: cuando ADF identifica nuevas columnas desviadas, esas nuevas columnas se convierten al tipo de datos apropiado mediante la inferencia de tipos automática de ADF.
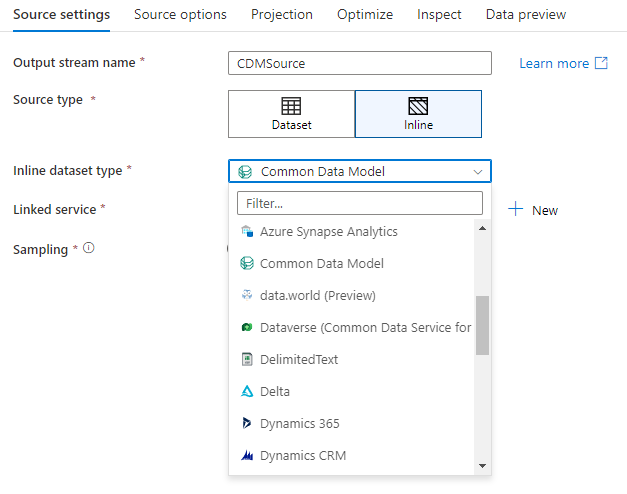
Base de datos del área de trabajo (solo áreas de trabajo de Synapse)
En los espacios de trabajo de Azure Synapse, existe una opción adicional en la transformación de origen del flujo de datos denominada Workspace DB. Esto le permite elegir directamente una base de datos de área de trabajo de cualquier tipo disponible como datos de origen sin necesidad de servicios vinculados ni conjuntos de datos adicionales. Las bases de datos creadas a través de las plantillas de base de datos Azure Synapse también son accesibles al seleccionar Base de datos del área de trabajo.
Tipos de orígenes admitidos
El flujo de datos de asignación sigue un enfoque de extracción, carga y transformación (ELT) y funciona con conjuntos de datos de un almacenamiento provisional que están todos en Azure. Actualmente, se pueden usar los siguientes conjuntos de datos en una transformación de origen.
La configuración específica de estos conectores se encuentra en la pestaña Source options (Opciones de origen). La información y algunos ejemplos de script de flujo de datos sobre esta configuración se encuentran en la documentación del conector.
Azure Data Factory y las canalizaciones de Synapse tienen acceso a más de 90 conectores nativos. Para incluir datos de esos otros orígenes en el flujo de datos, use la herramienta de actividad de copia para cargar esos datos en una de las áreas de almacenamiento provisional compatibles.
Configuración de origen
Una vez que haya agregado un origen, configúrelo mediante la pestaña Configuración de origen. Aquí puede elegir o crear el conjunto de datos al que apunta el origen. También puede seleccionar las opciones de esquema y muestreo para sus datos.
Los valores de desarrollo de los parámetros del conjunto de datos se pueden configurar en la configuración de depuración. (Requiere que esté activado el modo Depuración)
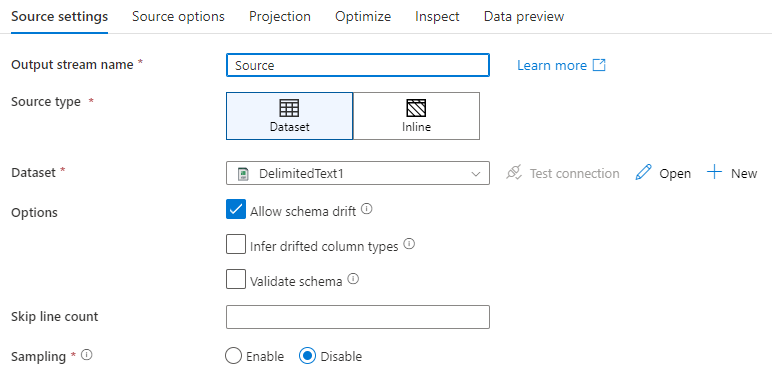
Nombre de la secuencia de salida: El nombre de la transformación de origen.
Tipo de origen: Elija si desea utilizar un conjunto de datos en línea o un objeto de conjunto de datos existente.
Probar conexión: pruebe si el servicio Spark del flujo de datos puede conectarse correctamente al servicio vinculado que se usa en el conjunto de datos de origen. El modo de depuración debe estar activado para habilitar esta característica.
Desfase de esquema: el desfase de esquema es la capacidad del servicio de administrar de forma nativa esquemas flexibles de los flujos de datos sin necesidad de definir explícitamente cambios en las columnas.
Active la casilla Permitir desfase de esquema si las columnas de origen cambian a menudo. Esta opción permite que todos los campos de origen entrantes fluyan hasta el receptor a través de las transformaciones.
Al seleccionar Inferir tipos de columnas desfasadas, se indica a Data Factory que detecte y defina los tipos de datos para cada nueva columna detectada. Con esta característica desactivada, todas las columnas desviadas son de tipo texto.
Validar esquema: si se selecciona Validar esquema, el flujo de datos no se puede ejecutar si los datos de origen entrantes no coinciden con el esquema definido del conjunto de datos.
Skip line count (Número de líneas para omitir): el campo Skip line count (Número de líneas para omitir) especifica el número de líneas que se van a omitir al principio del conjunto de datos.
Muestreo: Habilite Muestreo para limitar el número de filas de su origen. Use esta configuración al probar o muestrear datos de tu fuente con fines de depuración. Esto resulta muy útil cuando se ejecutan flujos de datos en modo de depuración desde una canalización.
Para validar si el origen está configurado correctamente, active el modo de depuración y capture una vista previa de los datos. Para más información, consulte Modo de depuración.
Nota:
Cuando el modo de depuración está activado, la configuración de límite de filas en la configuración de depuración sobrescribe la configuración de muestreo en el origen durante la vista previa de datos.
Opciones de origen
La pestaña Source options (Opciones de origen) contiene la configuración específica del conector y el formato elegidos. Para obtener más información y ejemplos, consulte la documentación del conector pertinente. Esto incluye detalles como el nivel de aislamiento de los orígenes de datos que lo admiten (como servidores SQL Server locales, bases de datos de Azure SQL e instancias administradas de Azure SQL) y otras configuraciones específicas del origen de datos.
Proyección
Al igual que los esquemas en los conjuntos de datos, la proyección de un origen define las columnas, los tipos y los formatos de datos de los datos de origen. Para la mayoría de los tipos de conjuntos de datos, como SQL y Parquet, la proyección en un origen se corrige para que refleje el esquema definido en un conjunto de datos, que variará en función del origen. Cuando los archivos de origen no están fuertemente tipados (por ejemplo, archivos .csv sin formato en lugar de archivos Parquet), puede definir los tipos de datos de cada campo en la transformación de origen. En la imagen siguiente se muestra una proyección de ejemplo:
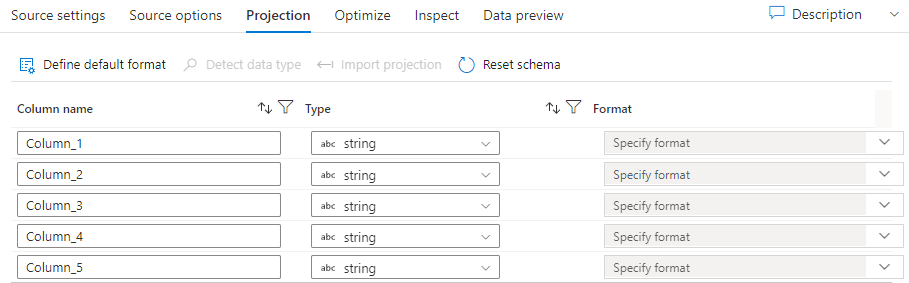
Si el archivo de texto no tiene ningún esquema definido, seleccione Detectar tipo de datos para que el servicio muestree e infiera los tipos de datos. Seleccione Definir formato predeterminado para detectar automáticamente los formatos de datos predeterminados.
Reset schema (Restablecer esquema) restablece la proyección a la definición del conjunto de datos de referencia.
Sobrescribir esquema permite modificar los tipos de datos proyectados en el origen, sobrescribiendo los tipos de datos definidos por el esquema. Como alternativa, puede modificar los tipos de datos de columna en una transformación de columna derivada posterior. Use una transformación de selección para modificar los nombres de columna.
Importar esquema
Seleccione Importar esquema de la pestaña Proyección para usar un clúster de depuración activo para crear una proyección de esquema. Está disponible en todos los tipos de origen. La importación del esquema aquí invalida la proyección definida en el conjunto de datos. El objeto del conjunto de datos no se cambiará.
La importación del esquema es útil en conjuntos de datos como Avro y Azure Cosmos DB que admiten estructuras de datos complejas que no requieren definiciones de esquema para existir en el conjunto de datos. Para los conjuntos de datos en línea, la importación del esquema es la única manera de hacer referencia a los metadatos de columna sin desfase de esquema.
Optimizar la transformación de la fuente
La pestaña Optimizar permite la edición de la información de partición en cada paso de la transformación. En la mayoría de los casos, Usar partición actual optimiza la estructura de partición ideal para una fuente.
Si está leyendo desde un origen de Azure SQL Database, la partición personalizada Origen probablemente sea la forma más rápida de leer los datos. El servicio lee consultas grandes realizando conexiones a la base de datos en paralelo. Esta partición de origen se puede realizar en una columna o mediante una consulta.
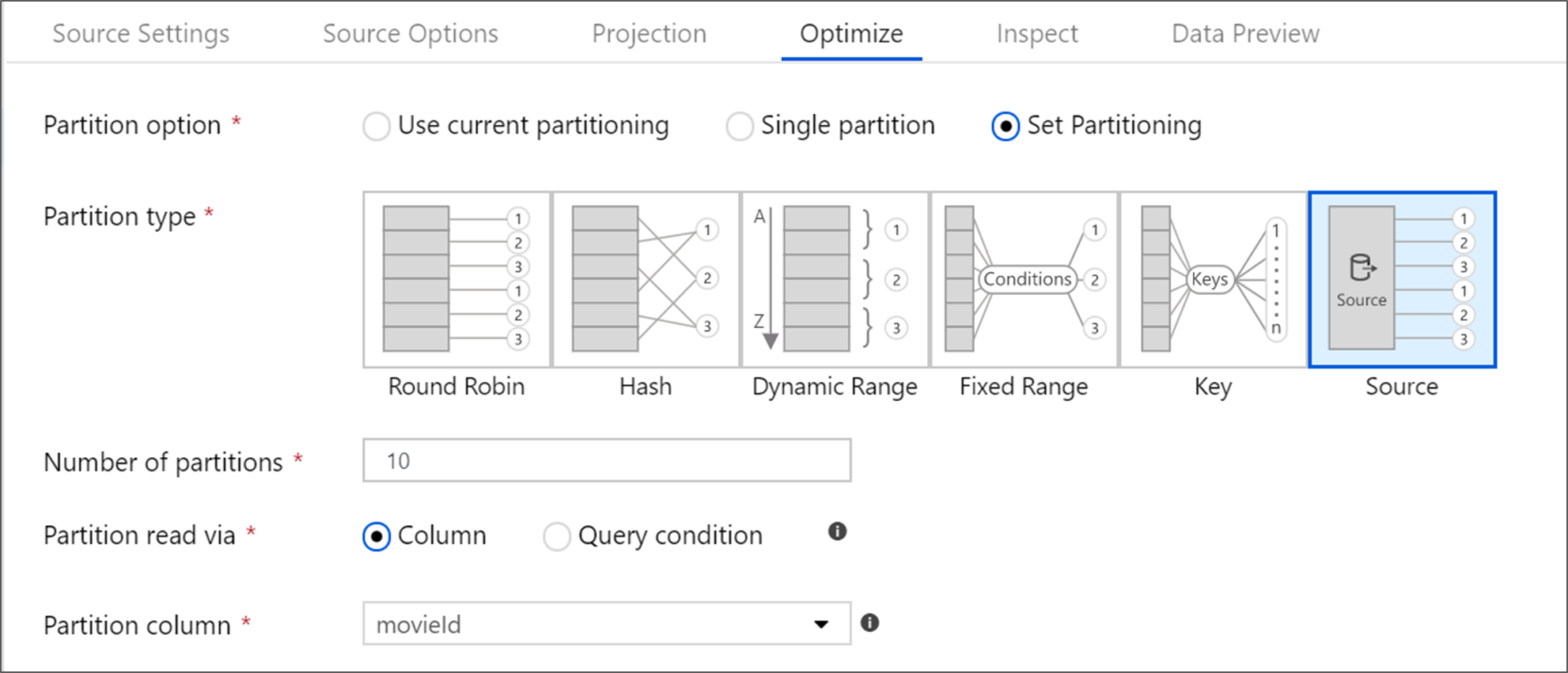
Para más información sobre la optimización en Mapping Data Flow, consulte la pestaña de optimización.
Contenido relacionado
Comience a compilar el flujo de datos con una transformación de columna derivada y una transformación de selección.