Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Obtenga información sobre lo que son las canalizaciones declarativas (SDP) de Lakeflow Spark, los conceptos básicos (como canalizaciones, tablas de streaming y vistas materializadas) que lo definen, las relaciones entre esos conceptos y las ventajas de usarlos en los flujos de trabajo de procesamiento de datos.
Nota:
Las canalizaciones declarativas de Spark de Lakeflow requieren el plan Premium. Póngase en contacto con el equipo de la cuenta de Databricks para obtener más información.
¿Qué es SDP?
Lakeflow Spark Declarative Pipelines es un marco declarativo para desarrollar y ejecutar canalizaciones de datos por lotes y streaming en SQL y Python. Lakeflow SDP extiende y es interoperable con las Canalizaciones Declarativas de Apache Spark, mientras se ejecuta en el Databricks Runtime optimizado para el rendimiento, y la API de las Canalizaciones Declarativas de Spark de Lakeflow usa la misma API DataFrame que Apache Spark y Structured Streaming. Entre los casos de uso comunes para SDP se incluyen la ingesta de datos incrementales de orígenes como el almacenamiento en la nube (incluido Amazon S3, Azure ADLS Gen2 y Google Cloud Storage) y los buses de mensajes (como Apache Kafka, Amazon Kinesis, Google Pub/Sub, Azure EventHub y Apache Pulsar), transformaciones incrementales por lotes y streaming con operadores sin estado y procesamiento de flujos en tiempo real entre almacenes transaccionales, como buses de mensajes y bases de datos.
Para más información sobre el procesamiento de datos declarativo, consulte Procesamiento de datos procedimental frente al declarativo en Databricks.
¿Cuáles son las ventajas de SDP?
La naturaleza declarativa de SDP proporciona las siguientes ventajas en comparación con el desarrollo de procesos de datos con las API de Apache Spark y Spark Structured Streaming y su ejecución con Databricks Runtime mediante la orquestación manual a través de trabajos de Lakeflow.
- Orquestación automática: SDP organiza los pasos de procesamiento (denominados "flujos") automáticamente para garantizar el orden correcto de ejecución y el nivel máximo de paralelismo para obtener un rendimiento óptimo. Además, las canalizaciones reintentan de forma automática y eficaz los errores transitorios. El proceso de reintento comienza con la unidad más granular y rentable: la tarea de Spark. Si el reintento a nivel de tarea falla, SDP procede a reintentar el flujo y, finalmente, toda la tubería si es necesario.
- Procesamiento declarativo: SDP proporciona funciones declarativas que pueden reducir cientos o incluso miles de líneas de código manual de Spark y Structured Streaming a solo unas pocas líneas. La API AUTO CDC de SDP simplifica el procesamiento de eventos de Captura de Datos Cambiados (CDC) con compatibilidad con SCD Tipo 1 y SCD Tipo 2. Elimina la necesidad de código manual para controlar eventos desordenados y no requiere una comprensión de la semántica de streaming o conceptos como marcas de agua.
- Procesamiento incremental: SDP proporciona un motor de procesamiento incremental para vistas materializadas. Para usarlo, escriba la lógica de transformación con semántica por lotes y el motor solo procesará nuevos datos y cambios en los orígenes de datos siempre que sea posible. El procesamiento incremental reduce el reprocesamiento ineficaz cuando se producen nuevos datos o cambios en los orígenes y elimina la necesidad de código manual para controlar el procesamiento incremental.
Conceptos clave
En el diagrama siguiente se muestran los conceptos más importantes de las canalizaciones declarativas de Spark de Lakeflow.
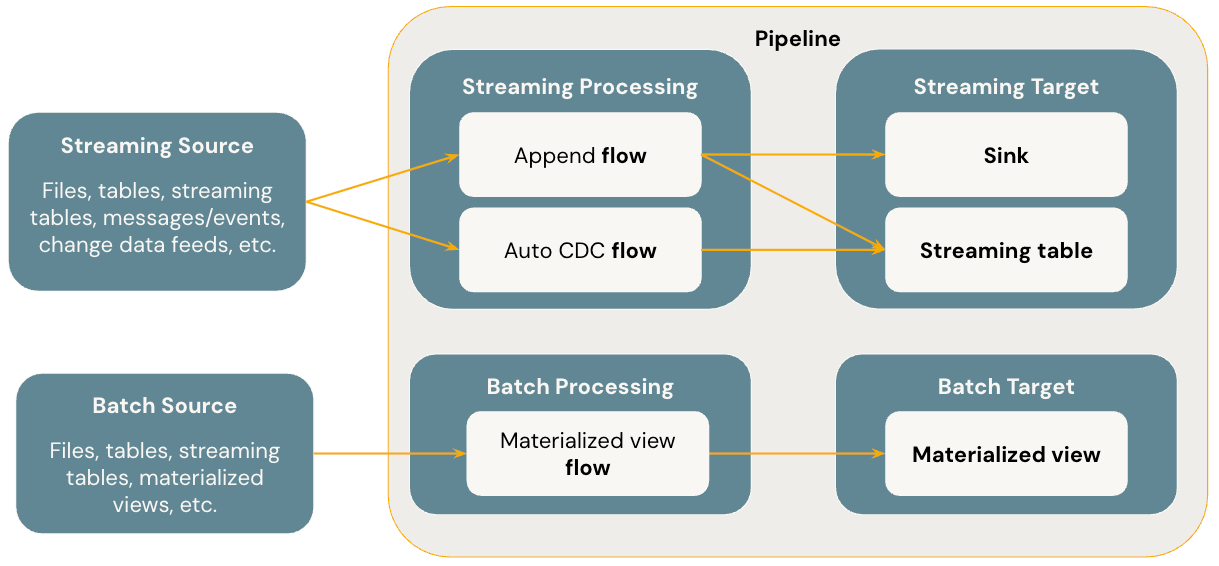
Flows
Un flujo es el concepto de procesamiento de datos fundamentales en SDP que admite la semántica de streaming y por lotes. Un flujo lee los datos de un origen, aplica la lógica de procesamiento definida por el usuario y escribe el resultado en un destino. SDP comparte el mismo tipo de flujo de streaming (Append, Update, Complete) que Spark Structured Streaming. (Actualmente, solo se expone el flujo append ). Para obtener más información, consulte modos de salida en Structured Streaming.
Las canalizaciones declarativas de Spark de Lakeflow también proporcionan tipos de flujo adicionales:
- AUTO CDC es un flujo de streaming único en SDP de Lakeflow que controla eventos CDC desordenados y admite scD tipo 1 y scD tipo 2. CDC automático no está disponible en las canalizaciones declarativas de Apache Spark.
- La vista materializada es un flujo por lotes en SDP que solo procesa nuevos datos y cambios en las tablas de origen siempre que sea posible.
Para obtener más información, consulte:
Tablas de streaming
Una tabla de streaming es una forma de tabla administrada de Unity Catalog que también es un destino de streaming para Lakeflow SDP. Una tabla de streaming puede tener uno o varios flujos de streaming (Append, AUTO CDC) escritos en ella. AUTO CDC es un flujo de streaming único que solo está disponible para las tablas de streaming en Databricks. Puede definir flujos de streaming explícitamente e independientemente de su tabla de streaming de destino. También puede definir flujos de streaming implícitamente como parte de una definición de tabla de streaming.
Para obtener más información, consulte:
Vistas materializadas
Una vista materializada también es una forma de tabla administrada en Unity Catalog y funciona como un destino de procesamiento por lotes. Una vista materializada puede tener uno o varios flujos de vista materializados escritos en ella. Las vistas materializadas difieren de las tablas de streaming en que siempre se definen los flujos implícitamente como parte de la definición de vista materializada.
Para obtener más información, consulte:
Sinks
Un receptor es un destino de streaming para una canalización y admite tablas delta, temas de Apache Kafka, temas de Azure EventHubs y orígenes de datos personalizados de Python. Un sumidero puede tener uno o varios flujos de streaming (Añadir) escritos en él.
Para obtener más información, consulte:
Tuberías
Una pipeline es la unidad de desarrollo y ejecución en las canalizaciones declarativas de Lakeflow Spark. Una canalización puede contener uno o varios flujos, tablas de streaming, vistas materializadas y receptores. Utiliza SDP definiendo flujos, tablas de streaming, vistas materializadas y destinos en el código fuente de la canalización, y luego ejecuta la canalización. Mientras se ejecuta la canalización, analiza las dependencias de los flujos definidos, las tablas de streaming, las vistas materializadas y los receptores, y organiza automáticamente su orden de ejecución y paralelización.
Para obtener más información, consulte:
Pipelines SQL de Databricks
Las tablas de streaming y las vistas materializadas son dos funcionalidades fundamentales en Databricks SQL. Puede usar SQL estándar para crear y actualizar tablas de streaming y vistas materializadas en Databricks SQL. Las tablas de streaming y las vistas materializadas de Databricks SQL se ejecutan en la misma infraestructura de Azure Databricks y tienen la misma semántica de procesamiento que en las canalizaciones declarativas de Spark de Lakeflow. Cuando se usan tablas de streaming y vistas materializadas en Databricks SQL, los flujos se definen implícitamente como parte de las tablas de streaming y la definición de vistas materializadas.
Para obtener más información, consulte: