Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Aprenda a conectar un clúster de Apache Spark en Azure HDInsight con una instancia de Azure SQL Database. A continuación, lea, escriba y transmita datos en la base de datos SQL. Las instrucciones descritas en este artículo usan un cuaderno de Jupyter Notebook para ejecutar los fragmentos de código de Scala. Sin embargo, puede crear una aplicación independiente en Scala o Python y realizar las mismas tareas.
Requisitos previos
Clúster de Spark en Azure HDInsight. Siga las instrucciones de Creación de un clúster de Apache Spark en HDInsight.
Azure SQL Database. Siga las instrucciones de Creación de una base de datos en Azure SQL Database. Asegúrese de crear una base de datos con los datos y el esquema del ejemplo AdventureWorksLT. Además, asegúrese de crear una regla de firewall a nivel de servidor para permitir que la dirección IP del cliente acceda a la base de datos SQL. Las instrucciones para agregar la regla de firewall están disponibles en el mismo artículo. Una vez que haya creado la base de datos en SQL Database, asegúrese de tener los siguientes valores a mano. Los necesitará para conectarse a la base de datos desde un clúster de Spark.
- Nombre de servidor.
- nombre de base de datos.
- Nombre de usuario y contraseña del administrador de Azure SQL Database.
SQL Server Management Studio (SSMS). Siga las instrucciones de Azure SQL Database: uso de SQL Server Management Studio para conectarse a los datos y realizar consultas en ellos.
Creación de un cuaderno de Jupyter Notebook
Comience con la creación de un cuaderno de Jupyter Notebook asociado al clúster de Spark. Utilice ese cuaderno para ejecutar los fragmentos de código que se utilizan en este artículo.
- En Azure Portal, abra el clúster.
- Seleccione Jupyter Notebook debajo de Paneles de clúster en el lado derecho. Si no ve paneles de clúster, seleccione Introducción del menú izquierdo. Cuando se le pida, escriba las credenciales del clúster.
Nota:
También puede acceder al cuaderno de Jupyter Notebook en el clúster Spark si abre la siguiente dirección URL en el explorador. Reemplace CLUSTERNAME por el nombre del clúster:
https://CLUSTERNAME.azurehdinsight.net/jupyter
- En el cuaderno de Jupyter Notebook, en la esquina superior derecha, haga clic en Nuevo y, a continuación, en Spark para crear un cuaderno de Scala. Los cuadernos de Jupyter Notebook en el clúster de HDInsight Spark también proporcionan el kernel PySpark para aplicaciones Python2 y el kernel PySpark3 para aplicaciones Python3. En este artículo, vamos a crear un cuaderno de Scala.

Para más información sobre los kernels, consulte Uso de kernels de Jupyter Notebook con clústeres de Apache Spark en HDInsight.
Nota
En este artículo, utilizamos un kernel de Spark (Scala) porque de momento solo se admite el streaming de los datos de Spark a SQL Database en Scala y Java. Aunque es posible leer y escribir en SQL mediante Python, por coherencia, en este artículo usamos Scala para las tres operaciones.
Se abre un nuevo cuaderno con el nombre predeterminado Sin título. Haga clic en el nombre del cuaderno y escriba un nombre de su elección.
Ahora puede empezar a crear la aplicación.
Lectura de datos desde la instancia de Azure SQL Database
En esta sección, va a leer los datos de una tabla (por ejemplo, SalesLT.Address) que existe en la base de datos AdventureWorks.
En un nuevo cuaderno de Jupyter Notebook, en una celda de código, pegue el siguiente fragmento de código y reemplace los valores del marcador de posición por los valores de su instancia de base de datos.
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Presione MAYÚS + ENTRAR para ejecutar la celda de código.
Use el fragmento de código siguiente para crear una dirección URL de JDBC que pueda pasar a las API de tramas de datos de Spark. El código crea un objeto
Propertiesque contenga los parámetros. Pegue el fragmento de código en una celda de código y presione MAYÚS + ENTRAR para ejecutarlo.import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")Use el siguiente fragmento de código para crear una trama de datos con los datos de una tabla en la base de datos. En este fragmento de código, utilizamos la tabla
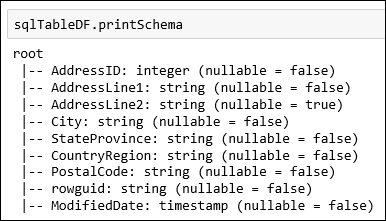
SalesLT.Addressque está disponible como parte de la base de datos AdventureWorksLT. Pegue el fragmento de código en una celda de código y presione MAYÚS + ENTRAR para ejecutarlo.val sqlTableDF = spark.read.jdbc(jdbc_url, "SalesLT.Address", connectionProperties)Ahora puede realizar operaciones en la trama de datos, como obtener el esquema de datos:
sqlTableDF.printSchemaDebe ver una salida similar a la que se muestra en la imagen siguiente:
También puede realizar operaciones como recuperar las 10 primeras filas.
sqlTableDF.show(10)O bien, recuperar columnas específicas del conjunto de datos.
sqlTableDF.select("AddressLine1", "City").show(10)
Escritura de datos en la instancia de Azure SQL Database
En esta sección, utilizamos un archivo CSV de ejemplo disponible en el clúster para crear una tabla en la base de datos y rellenarla con datos. El archivo CSV de ejemplo (HVAC.csv) está disponible en todos los clústeres de HDInsight en HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv.
En un nuevo cuaderno de Jupyter Notebook, en una celda de código, pegue el siguiente fragmento de código y reemplace los valores del marcador de posición por los valores de su instancia de base de datos.
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Presione MAYÚS + ENTRAR para ejecutar la celda de código.
El fragmento de código siguiente crea una dirección URL de JDBC que puede pasar a las API de tramas de datos de Spark. El código crea un objeto
Propertiesque contenga los parámetros. Pegue el fragmento de código en una celda de código y presione MAYÚS + ENTRAR para ejecutarlo.import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")Use el fragmento de código siguiente para extraer el esquema de los datos de HVAC.csv y utilizar el esquema para cargar los datos del archivo CSV en una trama de datos,
readDf. Pegue el fragmento de código en una celda de código y presione MAYÚS + ENTRAR para ejecutarlo.val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readDf = spark.read.format("csv").schema(userSchema).load("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Use la trama de datos
readDfpara crear una tabla temporal,temphvactable. Después, utilice la tabla temporal para crear una tabla de hive,hvactable_hive.readDf.createOrReplaceTempView("temphvactable") spark.sql("create table hvactable_hive as select * from temphvactable")Por último, utilice la tabla de hive para crear una tabla en la base de datos. El siguiente fragmento de código crea
hvactableen la instancia de Azure SQL Database.spark.table("hvactable_hive").write.jdbc(jdbc_url, "hvactable", connectionProperties)Conéctese a la instancia de Azure SQL Database con SSMS y compruebe que ve una
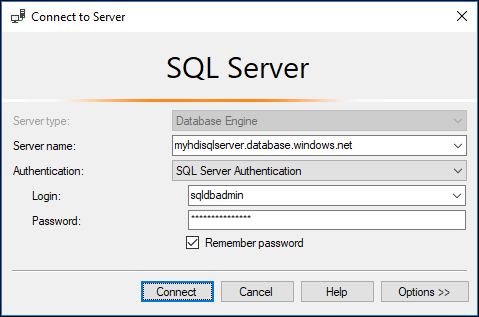
dbo.hvactableallí.a. Inicie SSMS y conéctese a la instancia de Azure SQL Database proporcionando los detalles de conexión, tal como se muestra en la captura de pantalla siguiente.
b. En el Explorador de objetos, expanda la base de datos y el nodo de tabla para ver la tabla dbo.hvactable creada.
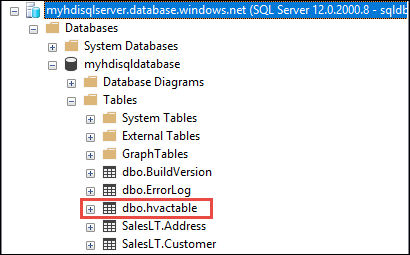
Ejecute una consulta en SSMS para ver las columnas de la tabla.
SELECT * from hvactable
Transmisión de datos en Azure SQL Database
En esta sección, vamos a transmitir los datos a la tabla hvactable que creó en la sección anterior.
Como primer paso, asegúrese de que no hay ningún registro en
hvactable. Con SSMS, ejecute la siguiente consulta en la tabla.TRUNCATE TABLE [dbo].[hvactable]Cree un nuevo cuaderno de Jupyter Notebook en el clúster de HDInsight Spark. En una celda de código, pegue el siguiente fragmento de código y presione MAYÚS + ENTRAR:
import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.streaming._ import java.sql.{Connection,DriverManager,ResultSet}Vamos a transmitir los datos desde HVAC.csv a
hvactable. El archivo HVAC.csv está disponible en el clúster en/HdiSamples/HdiSamples/SensorSampleData/HVAC/. En el fragmento de código siguiente, obtenemos primero el esquema de los datos que se van a transmitir. Después, creamos una trama de datos de streaming con ese esquema. Pegue el fragmento de código en una celda de código y presione MAYÚS + ENTRAR para ejecutarlo.val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readStreamDf = spark.readStream.schema(userSchema).csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/") readStreamDf.printSchemaLa salida muestra el esquema de HVAC.csv.
hvactabletiene también el mismo esquema. La salida muestra las columnas de la tabla.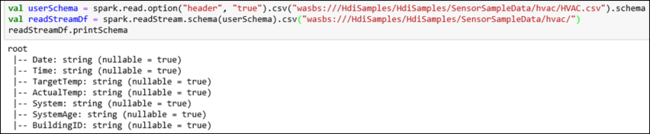
Por último, utilice el siguiente fragmento de código para leer los datos del archivo HVAC.csv y transmitirlos a la tabla
hvactableen la base de datos. Pegue el fragmento de código en una celda de código, reemplace los valores del marcador de posición por los valores de la base de datos y, después, presione MAYÚS + ENTRAR para ejecutarlo.val WriteToSQLQuery = readStreamDf.writeStream.foreach(new ForeachWriter[Row] { var connection:java.sql.Connection = _ var statement:java.sql.Statement = _ val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>" val driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver" val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" def open(partitionId: Long, version: Long):Boolean = { Class.forName(driver) connection = DriverManager.getConnection(jdbc_url, jdbcUsername, jdbcPassword) statement = connection.createStatement true } def process(value: Row): Unit = { val Date = value(0) val Time = value(1) val TargetTemp = value(2) val ActualTemp = value(3) val System = value(4) val SystemAge = value(5) val BuildingID = value(6) val valueStr = "'" + Date + "'," + "'" + Time + "'," + "'" + TargetTemp + "'," + "'" + ActualTemp + "'," + "'" + System + "'," + "'" + SystemAge + "'," + "'" + BuildingID + "'" statement.execute("INSERT INTO " + "dbo.hvactable" + " VALUES (" + valueStr + ")") } def close(errorOrNull: Throwable): Unit = { connection.close } }) var streamingQuery = WriteToSQLQuery.start()Para comprobar que los datos se estén transmitiendo a la tabla
hvactable, ejecute la siguiente consulta en SQL Server Management Studio (SSMS). Cada vez que se ejecuta la consulta, muestra el aumento del número de filas en la tabla.SELECT COUNT(*) FROM hvactable