Introducción a las utilidades de Spark para Microsoft
Las utilidades de Spark para Microsoft (MSSparkUtils) son un paquete integrado que le ayuda a realizar las tareas más comunes con mayor facilidad. Puede usar MSSparkUtils para trabajar con sistemas de archivos, obtener variables de entorno, encadenar cuadernos entre sí y trabajar con secretos. MSSparkUtils está disponible en los cuadernos de PySpark (Python), Scala, .NET Spark (C#) y R (Preview), así como en canalizaciones de Synapse.
Requisitos previos
Configuración del acceso a Azure Data Lake Storage Gen2
Los cuadernos de Synapse usan el paso a través de Microsoft Entra para acceder a las cuentas de ADLS Gen2. Debe ser un colaborador de datos de Blob Storage para acceder a la cuenta (o carpeta) de ADLS Gen2.
Las canalizaciones de Synapse usan la identidad de servicio administrada (MSI) del área de trabajo para acceder a las cuentas de almacenamiento. Para usar MSSparkUtils en las actividades de canalización, la identidad del área de trabajo debe ser un colaborador de datos de Blob Storage para acceder a la cuenta (o carpeta) de ADLS Gen2.
Siga los pasos a continuación para asegurarse de que Microsoft Entra ID y la MSI del área de trabajo tienen acceso a la cuenta de ADLS Gen2:
Abra Azure Portal y la cuenta de almacenamiento a la que quiere acceder. Puede desplazarse al contenedor específico al que quiere obtener acceso.
Seleccione Control de acceso (IAM) en el panel izquierdo.
Seleccione Agregar>Agregar asignación de roles para abrir la página Agregar asignación de roles.
Asigne el siguiente rol. Para asignar roles, consulte Asignación de roles de Azure mediante Azure Portal.
Configuración Valor Role Colaborador de datos de blobs de almacenamiento Asignar acceso a USER y MANAGEDIDENTITY Miembros su cuenta de Microsoft Entra y la identidad del área de trabajo Nota:
El nombre de la identidad administrada también es el nombre del área de trabajo.

Seleccione Guardar.
Puede acceder a los datos en ADLS Gen2 con Synapse Spark mediante la siguiente dirección URL:
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Configuración del acceso a Azure Blob Storage
Synapse usa la firma de acceso compartido (SAS) para acceder a Azure Blob Storage. Para evitar la exposición de las claves de SAS en el código, se recomienda crear un nuevo servicio vinculado en el área de trabajo de Synapse para la cuenta de Azure Blob Storage a la que quiere acceder.
Siga los pasos a continuación para agregar un nuevo servicio vinculado para una cuenta de Azure Blob Storage:
- Abra Azure Synapse Studio.
- Seleccione Administrar en el panel izquierdo y, a continuación, seleccione Servicios vinculados en Conexiones externas.
- Busque Azure Blob Storage en el panel Nuevo servicio vinculado de la derecha.
- Seleccione Continuar.
- Seleccione la cuenta de Azure Blob Storage a la que quiere acceder y configure el nombre del servicio vinculado. Sugiera el uso de una clave de cuenta como método de autenticación.
- Seleccione Prueba de conexión para validar la configuración.
- Seleccione Crear primero y haga clic en Publicar todo para guardar los cambios.
Puede acceder a los datos en Azure Blob Storage con Synapse Spark a través de la siguiente dirección URL:
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
Este es un ejemplo de código:
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Configuración de acceso a Azure Key Vault
Puede agregar una instancia de Azure Key Vault como servicio vinculado para administrar sus credenciales en Synapse. Siga estos pasos para agregar una instancia de Azure Key Vault como servicio vinculado de Synapse:
Abra Azure Synapse Studio.
Seleccione Administrar en el panel izquierdo y, a continuación, seleccione Servicios vinculados en Conexiones externas.
Busque Azure Key Vault en el panel Nuevo servicio vinculado de la derecha.
Seleccione la cuenta de Azure Key Vault a la que quiere acceder y configure el nombre del servicio vinculado.
Seleccione Prueba de conexión para validar la configuración.
Seleccione Crear primero y haga clic en Publicar todo para guardar el cambio.
Los cuadernos de Synapse usan el paso a través de Microsoft Entra para acceder a Azure Key Vault. Las canalizaciones de Synapse usan la identidad del área de trabajo (MSI) para acceder a Azure Key Vault. Para asegurarse de que el código funciona en el cuaderno y en la canalización de Synapse, se recomienda conceder el permiso de acceso al secreto tanto a la cuenta de Microsoft Entra como a la identidad del área de trabajo.
Siga los pasos a continuación para conceder acceso al secreto a la identidad del área de trabajo:
- Abra Azure Portal y la instancia de Azure Key Vault a la que quiere acceder.
- Seleccione Directivas de acceso en el panel izquierdo.
- Seleccione Agregar directiva de acceso.
- Elija Administración de claves, secretos y certificados como plantilla de configuración.
- Seleccione la cuenta de Microsoft Entra y la identidad del área de trabajo (igual que el nombre del área de trabajo) en la opción Seleccionar entidad de seguridad, o asegúrese de que ya estén asignadas.
- Elija Seleccionar y Agregar.
- Seleccione el botón Guardar para confirmar los cambios.
Utilidades del sistema de archivos
mssparkutils.fs ofrece utilidades para trabajar con varios sistemas de archivos, como Azure Data Lake Storage Gen2 (ADLS Gen2) y Azure Blob Storage. Asegúrese de configurar el acceso a Azure Data Lake Storage Gen2 y Azure Blob Storage adecuadamente.
Ejecute los siguientes comandos para obtener información general sobre los métodos disponibles:
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
El resultado es:
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
Enumerar archivos
Enumerar el contenido de un directorio.
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
Vea las propiedades del archivo.
Devuelve las propiedades del archivo, incluido el nombre, la ruta de acceso, el tamaño, la hora de modificación del archivo y si es un directorio y un archivo.
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
Creación de un directorio
Crea el directorio especificado si no existe, y también crea los directorios principales necesarios.
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
Copiar archivo
Copia un archivo o un directorio. Admite la copia entre sistemas de archivos.
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
Copiar archivos de un modo más eficaz
Este método proporciona una manera más rápida de copiar o mover archivos, especialmente grandes volúmenes de datos.
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
Nota:
El método solo admite en Azure Synapse Runtime para Apache Spark 3.3 y Azure Synapse Runtime para Apache Spark 3.4.
Vista previa del contenido del archivo
Devuelve hasta los primeros "maxBytes" bytes del archivo especificado como una cadena codificada en UTF-8.
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
Mover archivo
Mueve un archivo o un directorio. Permite el movimiento entre sistemas de archivos.
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
Escritura de archivos
Escribe la cadena especificada en un archivo, codificada en formato UTF-8.
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
Adición de contenido a un archivo
Anexa la cadena especificada a un archivo, codificada en formato UTF-8.
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
Nota:
mssparkutils.fs.append()ymssparkutils.fs.put()no admiten la escritura simultánea en el mismo archivo debido a la falta de garantías de atomicidad.- Al usar la
mssparkutils.fs.appendAPI en unforbucle para escribir en el mismo archivo, se recomienda agregar unasleepinstrucción alrededor de 0,5s~1s entre las escrituras periódicas. Esto se debe a que la operación internaflushde lamssparkutils.fs.appendAPI es asincrónica, por lo que un breve retraso ayuda a garantizar la integridad de los datos.
Eliminación de un archivo o directorio
Elimina un archivo o directorio.
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Utilidades de cuaderno
No compatible.
Puede usar las utilidades de cuaderno MSSparkUtils para ejecutar un cuaderno o salir de uno con un valor. Ejecute el siguiente comando para obtener información general sobre los métodos disponibles:
mssparkutils.notebook.help()
Obtenga los resultados:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Nota:
Las utilidades de cuaderno no son aplicables a las definiciones de trabajo de Apache Spark (SJD).
Referencia a un cuaderno
Hace referencia un cuaderno y devuelve su valor de salida. Puede ejecutar llamadas de función anidadas en un cuaderno de manera interactiva o en una canalización. El cuaderno al que se hace referencia se ejecutará en el grupo de Spark del cuaderno que llamó a esta función.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Por ejemplo:
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
Una vez finalizada la ejecución, verá un vínculo de instantánea denominado "View notebook run: Notebook Name" que se muestra en la salida de la celda, puede hacer clic en el vínculo para ver la instantánea de esta ejecución específica.

Referencia que ejecuta varios cuadernos en paralelo
El método mssparkutils.notebook.runMultiple() permite ejecutar varios cuadernos en paralelo o con una estructura topológica predefinida. La API utiliza un mecanismo de implementación de varios subprocesos dentro de una sesión de Spark, lo que significa que los recursos de proceso se comparten mediante las ejecuciones del cuaderno de referencia.
Con mssparkutils.notebook.runMultiple(), puede:
Ejecute varios cuadernos simultáneamente, sin esperar a que finalice cada uno.
Especifique las dependencias y el orden de ejecución de los cuadernos mediante un formato JSON simple.
Optimice el uso de recursos de proceso de Spark y reduzca el costo de los proyectos de Synapse.
Vea las instantáneas de cada registro de ejecución de cuadernos en la salida y depure o supervise las tareas del cuaderno de forma cómoda.
Obtenga el valor de salida de cada actividad ejecutiva y úselos en tareas descendentes.
También puede intentar ejecutar mssparkutils.notebook.help("runMultiple") para buscar el ejemplo y el uso detallado.
Este es un ejemplo sencillo de ejecutar una lista de cuadernos en paralelo mediante este método:
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
El resultado de la ejecución del cuaderno raíz es el siguiente:

A continuación se muestra un ejemplo de ejecución de cuadernos con estructura topológica mediante mssparkutils.notebook.runMultiple(). Use este método para organizar fácilmente cuadernos a través de una experiencia de código.
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
Nota:
- El método solo admite en Azure Synapse Runtime para Apache Spark 3.3 y Azure Synapse Runtime para Apache Spark 3.4.
- El grado de paralelismo de la ejecución de varios cuadernos está restringido al recurso de proceso total disponible de una sesión de Spark.
Salida de un cuaderno
Sale de un cuaderno con un valor. Puede ejecutar llamadas de función anidadas en un cuaderno de manera interactiva o en una canalización.
Cuando llamas a una función exit() desde un cuaderno de forma interactiva, Azure Synapse generará una excepción, omitirá la ejecución de celdas de subsecuencia y mantendrá activa la sesión de Spark.
Cuando se orqueste un cuaderno que llama a una función
exit()en una canalización de Synapse, Azure Synapse devolverá un valor de salida, completará la ejecución de la canalización y detendrá la sesión de Spark.Cuando se llame a una función
exit()en un cuaderno al que se hace referencia, Azure Synapse detendrá el resto de las ejecuciones en el cuaderno al que se hace referencia y seguirá ejecutando las siguientes celdas del cuaderno que llamó a la funciónrun(). Por ejemplo: Notebook1 tiene tres celdas y llama a una funciónexit()en la segunda celda. Notebook2 tiene cinco celdas y llama arun(notebook1)en la tercera celda. Al ejecutar Notebook2, Notebook1 se detendrá en la segunda celda al alcanzar la funciónexit(). Notebook2 continuará con la ejecución de su cuarta y quinta celda.
mssparkutils.notebook.exit("value string")
Por ejemplo:
El cuaderno Sample1 se encuentra en la carpeta folder/ con las dos celdas siguientes:
- La celda 1 define un parámetro input con un valor predeterminado establecido en 10.
- La celda 2 sale del cuaderno con el valor de input como valor de salida.
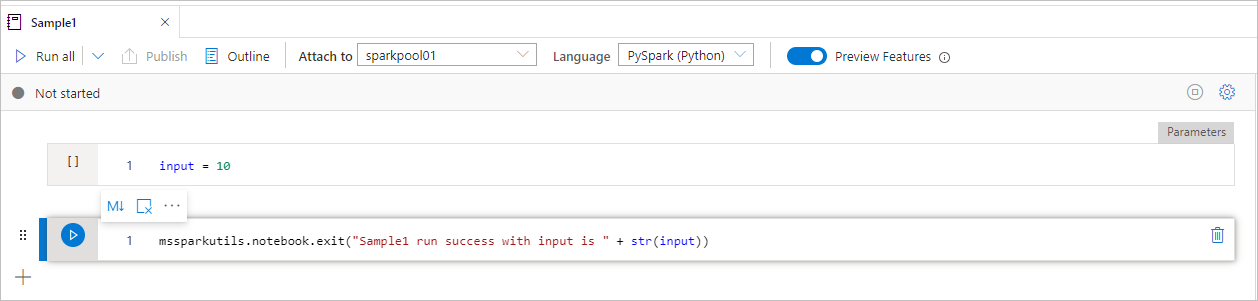
Puede ejecutar Sample1 en otro cuaderno con los valores predeterminados:
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
El resultado es:
Sample1 run success with input is 10
Puede ejecutar Sample1 en otro cuaderno y establecer el valor de input en 20:
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
El resultado es:
Sample1 run success with input is 20
Puede usar las utilidades de cuaderno MSSparkUtils para ejecutar un cuaderno o salir de uno con un valor. Ejecute el siguiente comando para obtener información general sobre los métodos disponibles:
mssparkutils.notebook.help()
Obtenga los resultados:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Referencia a un cuaderno
Hace referencia un cuaderno y devuelve su valor de salida. Puede ejecutar llamadas de función anidadas en un cuaderno de manera interactiva o en una canalización. El cuaderno al que se hace referencia se ejecutará en el grupo de Spark del cuaderno que llamó a esta función.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Por ejemplo:
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
Una vez finalizada la ejecución, verá un vínculo de instantánea denominado "View notebook run: Notebook Name" que se muestra en la salida de la celda, puede hacer clic en el vínculo para ver la instantánea de esta ejecución específica.
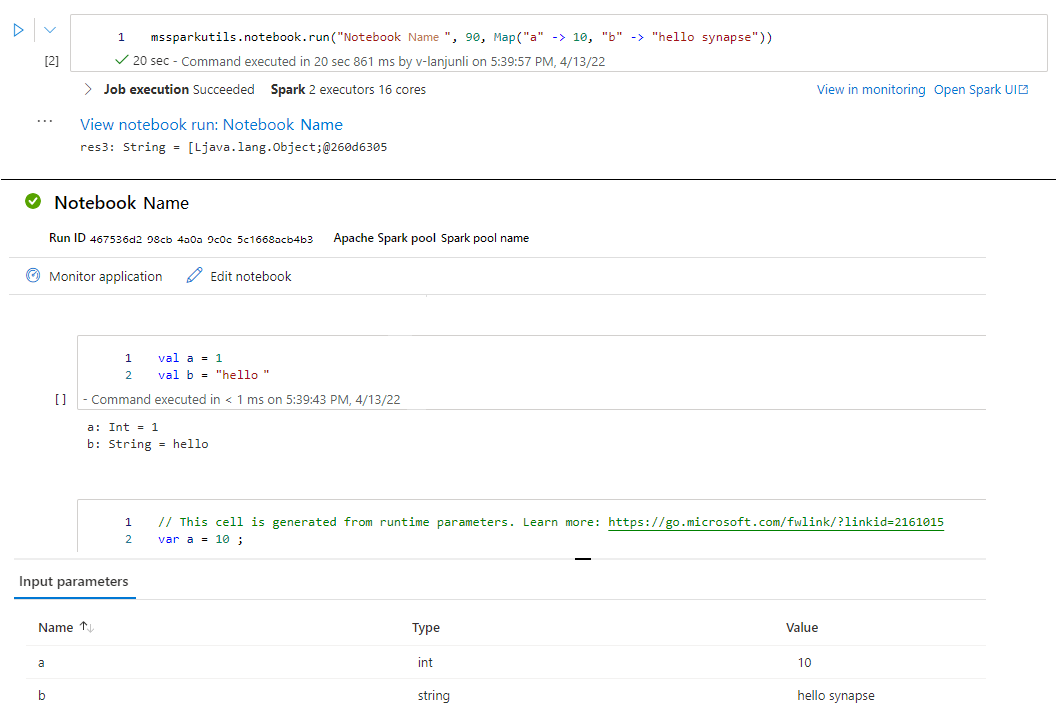
Salida de un cuaderno
Sale de un cuaderno con un valor. Puede ejecutar llamadas de función anidadas en un cuaderno de manera interactiva o en una canalización.
Cuando se llame a una función
exit()en un cuaderno de manera interactiva, Azure Synapse producirá una excepción, omitirá la ejecución de las celdas siguientes y mantendrá activa la sesión de Spark.Cuando se orqueste un cuaderno que llama a una función
exit()en una canalización de Synapse, Azure Synapse devolverá un valor de salida, completará la ejecución de la canalización y detendrá la sesión de Spark.Cuando se llame a una función
exit()en un cuaderno al que se hace referencia, Azure Synapse detendrá el resto de las ejecuciones en el cuaderno al que se hace referencia y seguirá ejecutando las siguientes celdas del cuaderno que llamó a la funciónrun(). Por ejemplo: Notebook1 tiene tres celdas y llama a una funciónexit()en la segunda celda. Notebook2 tiene cinco celdas y llama arun(notebook1)en la tercera celda. Al ejecutar Notebook2, Notebook1 se detendrá en la segunda celda al alcanzar la funciónexit(). Notebook2 continuará con la ejecución de su cuarta y quinta celda.
mssparkutils.notebook.exit("value string")
Por ejemplo:
El cuaderno Sample1 se encuentra en la carpeta mssparkutils/folder/ con las dos celdas siguientes:
- La celda 1 define un parámetro input con un valor predeterminado establecido en 10.
- La celda 2 sale del cuaderno con el valor de input como valor de salida.
Puede ejecutar Sample1 en otro cuaderno con los valores predeterminados:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
El resultado es:
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
Puede ejecutar Sample1 en otro cuaderno y establecer el valor de input en 20:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
El resultado es:
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
Puede usar las utilidades de cuaderno MSSparkUtils para ejecutar un cuaderno o salir de uno con un valor. Ejecute el siguiente comando para obtener información general sobre los métodos disponibles:
mssparkutils.notebook.help()
Obtenga los resultados:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Referencia a un cuaderno
Hace referencia un cuaderno y devuelve su valor de salida. Puede ejecutar llamadas de función anidadas en un cuaderno de manera interactiva o en una canalización. El cuaderno al que se hace referencia se ejecutará en el grupo de Spark del cuaderno que llamó a esta función.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Por ejemplo:
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
Una vez finalizada la ejecución, verá un vínculo de instantánea denominado "View notebook run: Notebook Name" que se muestra en la salida de la celda, puede hacer clic en el vínculo para ver la instantánea de esta ejecución específica.
Salida de un cuaderno
Sale de un cuaderno con un valor. Puede ejecutar llamadas de función anidadas en un cuaderno de manera interactiva o en una canalización.
Cuando se llame a una función
exit()en un cuaderno de manera interactiva, Azure Synapse producirá una excepción, omitirá la ejecución de las celdas siguientes y mantendrá activa la sesión de Spark.Cuando se orqueste un cuaderno que llama a una función
exit()en una canalización de Synapse, Azure Synapse devolverá un valor de salida, completará la ejecución de la canalización y detendrá la sesión de Spark.Cuando se llame a una función
exit()en un cuaderno al que se hace referencia, Azure Synapse detendrá el resto de las ejecuciones en el cuaderno al que se hace referencia y seguirá ejecutando las siguientes celdas del cuaderno que llamó a la funciónrun(). Por ejemplo: Notebook1 tiene tres celdas y llama a una funciónexit()en la segunda celda. Notebook2 tiene cinco celdas y llama arun(notebook1)en la tercera celda. Al ejecutar Notebook2, Notebook1 se detendrá en la segunda celda al alcanzar la funciónexit(). Notebook2 continuará con la ejecución de su cuarta y quinta celda.
mssparkutils.notebook.exit("value string")
Por ejemplo:
El cuaderno Sample1 se encuentra en la carpeta folder/ con las dos celdas siguientes:
- La celda 1 define un parámetro input con un valor predeterminado establecido en 10.
- La celda 2 sale del cuaderno con el valor de input como valor de salida.
Puede ejecutar Sample1 en otro cuaderno con los valores predeterminados:
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
El resultado es:
Sample1 run success with input is 10
Puede ejecutar Sample1 en otro cuaderno y establecer el valor de input en 20:
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
El resultado es:
Sample1 run success with input is 20
Utilidades de credenciales
Puede usar las utilidades de credenciales de MSSparkUtils para obtener los tokens de acceso de los servicios vinculados y administrar los secretos en Azure Key Vault.
Ejecute el siguiente comando para obtener información general sobre los métodos disponibles:
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
Resultado obtenido:
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Nota:
Actualmente, no se admite getSecretWithLS(linkedService, secret) en C#.
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Obtener el token
Devuelve el token de Microsoft Entra para una audiencia determinada, nombre (opcional). En la tabla siguiente se enumeran todos los tipos de público disponibles:
| Tipo de público | Literal de cadena que se va a usar en la llamada API |
|---|---|
| Azure Storage | Storage |
| Azure Key Vault | Vault |
| Administración de Azure | AzureManagement |
| Azure SQL Data Warehouse (dedicado y sin servidor) | DW |
| Azure Synapse | Synapse |
| Azure Data Lake Store | DataLakeStore |
| Azure Data Factory | ADF |
| Explorador de datos de Azure | AzureDataExplorer |
| Azure Database for MySQL | AzureOSSDB |
| Azure Database for MariaDB | AzureOSSDB |
| Azure Database for PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
Validación de token
Devuelve true si el token no ha expirado.
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
Obtención de la cadena de conexión o las credenciales para el servicio vinculado
Devuelve la cadena de conexión o las credenciales para el servicio vinculado.
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
Obtención del secreto mediante la identidad del área de trabajo
Devuelve el secreto de Azure Key Vault para un nombre de instancia de Azure Key Vault, un nombre de secreto y un nombre de servicio vinculado concretos mediante la identidad del área de trabajo. Asegúrese de configurar el acceso a Azure Key Vault adecuadamente.
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
Obtención del secreto con las credenciales de usuario
Devuelve el secreto de Azure Key Vault para un nombre de instancia de Azure Key Vault, un nombre de secreto y un nombre de servicio vinculado concretos mediante las credenciales del usuario.
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
Asignación de secreto mediante la identidad del área de trabajo
Asigna el secreto de Azure Key Vault a un nombre de instancia de Azure Key Vault, un nombre de secreto y un nombre de servicio vinculado concretos mediante la identidad del área de trabajo. Debe configurar el acceso a Azure Key Vault adecuadamente.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Asignación de secreto mediante la identidad del área de trabajo
Asigna el secreto de Azure Key Vault a un nombre de instancia de Azure Key Vault, un nombre de secreto y un nombre de servicio vinculado concretos mediante la identidad del área de trabajo. Debe configurar el acceso a Azure Key Vault adecuadamente.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
Asignación de secreto mediante la identidad del área de trabajo
Asigna el secreto de Azure Key Vault a un nombre de instancia de Azure Key Vault, un nombre de secreto y un nombre de servicio vinculado concretos mediante la identidad del área de trabajo. Debe configurar el acceso a Azure Key Vault adecuadamente.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Asignación del secreto con las credenciales de usuario
Asigna el secreto de Azure Key Vault a un nombre de instancia de Azure Key Vault, un nombre de secreto y un nombre de servicio vinculado concretos mediante las credenciales del usuario.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Asignación del secreto con las credenciales de usuario
Asigna el secreto de Azure Key Vault a un nombre de instancia de Azure Key Vault, un nombre de secreto y un nombre de servicio vinculado concretos mediante las credenciales del usuario.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Asignación del secreto con las credenciales de usuario
Asigna el secreto de Azure Key Vault a un nombre de instancia de Azure Key Vault, un nombre de secreto y un nombre de servicio vinculado concretos mediante las credenciales del usuario.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
Utilidades de entorno
Ejecute los siguientes comandos para obtener información general sobre los métodos disponibles:
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
Resultado obtenido:
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
Obtención del nombre de usuario
Devuelve el nombre del usuario actual.
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
Obtención del id. de usuario
Devuelve el id. de usuario actual.
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
Obtención del id. de trabajo
Devuelve el id. de trabajo.
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
Obtención del nombre del área de trabajo
Devuelve el nombre del área de trabajo.
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
Obtención del nombre del grupo
Devuelve el nombre del grupo de Spark.
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
Obtención del id. del clúster
Devuelve el id. de clúster actual.
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
Contexto en entorno de ejecución
Las utilidades del entorno de ejecución de Mssparkutils exponen tres propiedades para el entorno de ejecución; puede usar el contexto del entorno de ejecución de mssparkutils para obtener las propiedades enumeradas a continuación:
- Notebookname: el nombre del cuaderno actual, siempre devolverá el valor para el modo interactivo y el modo de canalización.
- Pipelinejobid: el identificador de ejecución de canalización, devolverá el valor en el modo de canalización y devolverá una cadena vacía en el modo interactivo.
- Activityrunid: el identificador de ejecución de la actividad del cuaderno, devolverá el valor en el modo de canalización y devolverá una cadena vacía en el modo interactivo.
Actualmente, el contexto del entorno de ejecución admite Python y Scala.
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
Administración de sesiones
Detención de una sesión interactiva
En lugar de hacer clic manualmente en el botón Detener, a veces es más conveniente detener una sesión interactiva mediante una llamada a una API en el código. En estos casos, se proporciona una API mssparkutils.session.stop() para facilitar la detención de la sesión interactiva mediante código. Está disponible para Scala y Python.
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
La API mssparkutils.session.stop() detendrá la sesión interactiva actual de forma asincrónica en segundo plano, detiene la sesión de Spark y libera los recursos ocupados por la sesión para que estén disponibles para otras sesiones del mismo grupo.
Nota
No se recomienda llamar a las API integradas del lenguaje como sys.exit en Scala o sys.exit() en Python en el código, ya que estas API simplemente terminan el proceso del intérprete, lo que deja la sesión de Spark activa y los recursos no se liberan.
Dependencias de paquetes
Si desea desarrollar cuadernos o trabajos localmente y necesita hacer referencia a los paquetes pertinentes para sugerencias de compilación o IDE, puede usar los siguientes paquetes.