Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a: ✓ Todos los modelos personalizados | ✓ Todos los modelos precompilados
En Microsoft Syntex, el procesamiento de documentos comienza con modelos, herramientas eficaces que le ayudan a identificar, clasificar y extraer información de documentos almacenados en bibliotecas de documentos de SharePoint. Estos modelos son la base para convertir contenido no estructurado en datos estructurados y utilizables.
Cuando se aplica un modelo a una biblioteca de SharePoint, está vinculado a un tipo de contenido que define la estructura de la información que se extrae. Este tipo de contenido, que incluye columnas para almacenar datos extraídos, se guarda en la galería de tipos de contenido de SharePoint. Puede crear un nuevo tipo de contenido adaptado a sus necesidades o usar los existentes para reutilizar su esquema y mantener la coherencia en toda la organización.
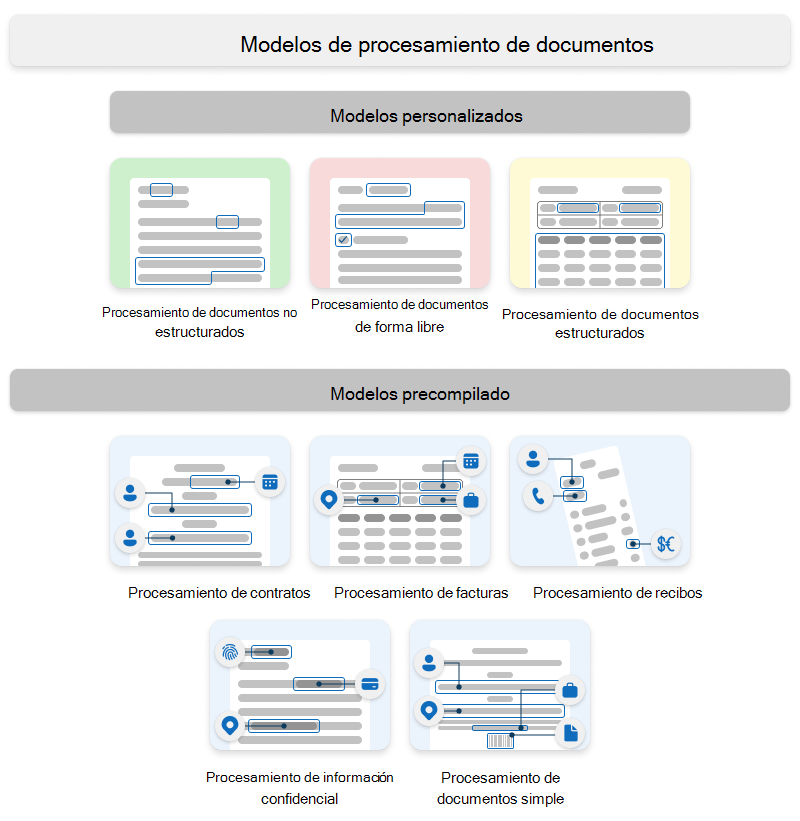
Microsoft Syntex usa modelos personalizados y modelos precompilados.
Los modelos se pueden crear de dos maneras en función de sus necesidades y de dónde quiera administrarlos. Los modelos empresariales se crean y administran en un centro de contenido, lo que los hace reutilizables en varios sitios de SharePoint. Por otro lado, los modelos locales se crean directamente dentro de una biblioteca de documentos de SharePoint en su sitio y tienen como ámbito esa biblioteca específica. Esto le proporciona flexibilidad para elegir el tipo de modelo adecuado en función de si necesita un control centralizado o una personalización localizada.
Modelos personalizados
El tipo de modelo personalizado que elija depende de los tipos de archivos con los que trabaje, la estructura y el formato de esos archivos y las ubicaciones de SharePoint en las que planea aplicar el modelo.
Los modelos personalizados incluyen:
- Procesamiento de documentos no estructurados
- Procesamiento de documentos de forma libre
- Procesamiento estructurado de documentos
Para ver las diferencias en paralelo en los modelos personalizados, consulte Comparación de modelos personalizados.
Procesamiento de documentos no estructurados
Use el modelo de procesamiento de documentos no estructurado al trabajar con documentos como letras o contratos que no siguen un diseño coherente, pero que contienen frases o patrones identificables. Este modelo clasifica automáticamente documentos y extrae información relevante basada en patrones de texto.
Por ejemplo, una carta de renovación de contrato puede variar en formato, pero incluir de forma coherente una frase como "Fecha de inicio del servicio de" seguida de una fecha. El modelo usa estos patrones para determinar el tipo de documento (clasificación) y los datos que se van a extraer (extractores).
- Mejor para: documentos no estructurados con patrones de texto reconocibles.
- Compatibilidad con archivos: gama más amplia de tipos de archivos.
- Compatibilidad con idiomas: más de 40 idiomas.
- Programa de instalación: use la opción Modelo de clase única .
Para obtener más información, vea Información general sobre el procesamiento de documentos no estructurados.
Procesamiento de documentos de forma libre
El modelo de procesamiento de documentos de forma libre es ideal para extraer información de documentos en los que los datos pueden aparecer en cualquier lugar, como cartas escaneadas, faxes o ARCHIVOS PDF. A diferencia de los modelos no estructurados, los modelos de forma libre no clasifican el tipo de documento; se centran únicamente en la extracción de datos.
Estos modelos se crean mediante Microsoft Power Apps AI Builder y son especialmente útiles al procesar grandes volúmenes de documentos entrantes de varios orígenes.
- Mejor para: archivos PDF o archivos de imagen en los que no se requiere la clasificación.
- Compatibilidad con archivos: formatos PDF e imagen.
- Compatibilidad con idiomas: más de 40 idiomas.
- Programa de instalación: use la opción Modelo de extracción de forma libre .
- Disponibilidad: varía según la región.
Para obtener más información, consulte Información general sobre el procesamiento de documentos estructurados y de forma libre.
Procesamiento estructurado de documentos
Elija el modelo de procesamiento estructurado de documentos para documentos con un diseño coherente, como formularios o facturas. Este modelo identifica los valores de campo y tabla en función de sus posiciones fijas en el documento.
Creados con Microsoft Power Apps AI Builder, los modelos estructurados aprenden de documentos de ejemplo y extraen datos de ubicaciones similares en archivos futuros. Por ejemplo, un formulario fiscal siempre podría colocar el número de seguro social en el mismo lugar.
- Mejor para: documentos estructurados o semiestructurados como formularios.
- Compatibilidad con archivos: Forms con diseños coherentes.
- Compatibilidad con idiomas: amplia gama de idiomas admitidos.
- Configuración: use la opción Modelo de extracción estructurada .
Para obtener más información, consulte Información general sobre el procesamiento de documentos estructurados y de forma libre.
Modelos creados previamente
Además de los modelos personalizados, Microsoft Syntex ofrece un conjunto de modelos precompilados que proporcionan funcionalidades integradas para extraer información estructurada de documentos empresariales comunes. Estos modelos están diseñados para ahorrar tiempo y esfuerzo al eliminar la necesidad de entrenamiento o configuración manuales.
Los modelos precompilados incluyen:
- Procesamiento del contrato
- Procesamiento de facturas
- Procesamiento de recibos
- Procesamiento de información confidencial
- Procesamiento simple de documentos
Procesamiento del contrato
El modelo de procesamiento de contratos está diseñado para analizar y extraer información clave de documentos de contrato. Funciona en varios formatos e identifica detalles importantes del contrato, como:
- Nombre de cliente o entidad
- Dirección de facturación
- Jurisdicción
- Fecha de caducidad
Este modelo es ideal para equipos legales, de adquisiciones o de operaciones que administran grandes volúmenes de contratos.
Para obtener más información, consulte Uso de un modelo precompilado para extraer información de contratos.
Procesamiento de facturas
El modelo de procesamiento de facturas extrae datos esenciales de las facturas de ventas, lo que ayuda a simplificar los flujos de trabajo de cuentas por pagar. Puede identificar información como:
- Nombre del cliente
- Dirección de facturación
- Fecha límite
- Importe vencido
Este modelo es especialmente útil para los equipos financieros que buscan automatizar la ingesta de facturas y reducir la entrada manual de datos.
Para obtener más información, consulte Uso de un modelo precompilado para extraer información de facturas.
Procesamiento de recibos
El modelo de procesamiento de recibos controla los recibos impresos y manuscritos, extracción de detalles clave de transacción como:
- Nombre del comerciante
- Número de teléfono del comerciante
- Fecha de transacción
- Impuestos y importe total
Este modelo es adecuado para los flujos de trabajo de informes de gastos y reembolsos.
Para obtener más información, consulte Uso de un modelo precompilado para extraer información de recibos.
Procesamiento de información confidencial
El modelo de procesamiento de información confidencial ayuda a identificar y extraer datos personales y confidenciales de documentos. Puede detectar información como:
- Números del Seguro Social
- Números de cuenta financiera
- Identificadores de licencia de conducir
- Otra información de identificación personal (PII)
Este modelo admite los esfuerzos de cumplimiento y protección de datos en toda la organización.
Para obtener más información, consulte Uso de un modelo precompilado para detectar información confidencial de documentos.
Procesamiento simple de documentos
El modelo de procesamiento de documentos sencillo ofrece una solución flexible y previamente entrenada para extraer información como:
- Pares clave-valor
- Marcas de selección (por ejemplo, casillas)
- Entidades con nombre
- Códigos de barras
- Detección de idioma
A diferencia de otros modelos precompilados con esquemas fijos, este modelo se adapta a una variedad más amplia de documentos estructurados y es una excelente alternativa cuando el etiquetado personalizado no es factible.
Para obtener más información, consulte Uso de un modelo precompilado para detectar información confidencial de documentos.