Use Azure Synapse Link para que Dataverse exporte sus datos de Microsoft Dataverse a Azure Synapse Analytics en formato Delta Lake. Luego explore sus datos y acelere el tiempo para obtener información. Este artículo proporciona la siguiente información y le muestra cómo realizar las siguientes tareas:
Explica Delta Lake y Parquet y por qué debería exportar datos en este formato.
Exporte sus datos de Dataverse a su espacio de trabajo Azure Synapse Analytics en formato Delta Lake con el Azure Synapse Link.
Supervise su Azure Synapse Link y la conversión de datos.
Ver sus datos desde Azure Data Lake Storage Gen2.
Vea sus datos desde Synapse Workspace.
Importante
Si va a actualizar de CSV a Delta Lake con vistas personalizadas existentes, le recomendamos que actualice el script para reemplazar todas las tablas particionadas por non_partitioned. Para ello, busque instancias de _partitioned y reemplácelas con una cadena vacía.
Para la configuración de Dataverse, solo agregar está habilitado de forma predeterminada para exportar datos CSV en el modo appendonly. Pero la tabla del delta lake tendrá una estructura de actualización en el lugar porque la conversión del delta lake viene con un proceso de fusión periódico.
No se incurre en costos con la creación de grupos de Spark. Solo se incurre en cargos una vez que se ejecuta un trabajo de Spark en el grupo de Spark de destino y se crea una instancia de Spark a pedido. Estos costos están relacionados con el uso de Azure Synapse workspace Spark y se facturan mensualmente. El coste de realizar computación con Spark depende principalmente del intervalo de tiempo para la actualización incremental y los volúmenes de datos. Más información: Precios de Azure Synapse Analytics
Es importante tener en cuenta estos costes adicionales cuando decida usar esta característica, ya que no son opcionales y deben pagarse para continuar usando esta característica.
El fin de la vida útil anunciada (EOLA) para Azure Synapse Runtime para Apache Spark 3.3 se ha anunciado el 12 de julio de 2024. De acuerdo con la directiva de tiempo de ejecución de Synapse para el ciclo de vida de Apache Spark, Azure Synapse Runtime para Apache Spark 3.3 se retirará y deshabilitará a partir del 31 de marzo de 2025. Después de la fecha EOL, los tiempos de ejecución retirados no están disponibles para los nuevos grupos de Spark y los flujos de trabajo existentes no se pueden ejecutar. Los metadatos permanecerán temporalmente en el espacio de trabajo de Synapse. Más información: Tiempo de ejecución de Azure Synapse para Apache Spark 3.3 (EOSA). Para tener su Synapse Link para Dataverse con la exportación al formato de Delta Lake, actualice a Spark 3.4, realice una actualización local para sus perfiles existentes. Más información: Actualización local a Apache Spark 3.4 con Delta Lake 2.4
A partir del 25 de diciembre de 2024, solo se admitirá la versión 3.4 de Spark Pool al crear inicialmente el vínculo.
Nota
El estado del Azure Synapse Link en Power Apps (make.powerapps.com) refleja el estado de conversión de Delta Lake:
Count muestra el número total de registros de la tabla del Delta Lake.
Last synchronized on la fecha y hora representa la marca de tiempo de la última conversión exitosa.
Sync status se muestra como activo una vez que se completa la sincronización de datos y la conversión del Delta Lake, lo que indica que los datos están listos para su consumo.
¿Qué es Delta Lake?
Delta Lake es un proyecto de código abierto que permite construir una arquitectura de lago sobre lagos de datos. Delta Lake proporciona transacciones ACID (atomicidad, consistencia, aislamiento y durabilidad), manejo escalable de metadatos y unifica el procesamiento de datos por lotes y transmisión por encima de los lagos de datos existentes. Azure Synapse Analytics es compatible con Linux Foundation Delta Lake. La versión actual de Delta Lake incluida con Azure Synapse tiene soporte de lenguaje para Scala, PySpark y .NET. Más información: ¿Qué es Delta Lake?. También puede obtener más información en el vídeo Introducción a las tablas delta.
Apache Parquet es el formato de referencia para Delta Lake, lo que le permite aprovechar los esquemas de compresión y codificación eficientes que son nativos del formato. El formato de archivo Parquet utiliza compresión por columnas. Es eficiente y ahorra espacio de almacenamiento. Las consultas que obtienen valores de columna específicos no necesitan leer los datos de fila completos, lo que mejora el rendimiento. Por lo tanto, el grupo de SQL sin servidor necesita menos tiempo y menos solicitudes de almacenamiento para leer los datos.
¿Por qué usar Delta Lake?
Escalabilidad: Delta Lake se basa en la licencia Apache de código abierto, que está diseñada para cumplir con los estándares de la industria para manejar cargas de trabajo de procesamiento de datos a gran escala.
Fiabilidad: Delta Lake proporciona transacciones ACID, lo que garantiza la consistencia y fiabilidad de los datos incluso ante fallas o acceso simultáneo.
Rendimiento: Delta Lake aprovecha el formato de almacenamiento en columnas de Parquet, proporcionando mejores técnicas de compresión y codificación, lo que puede conducir a un mejor rendimiento de las consultas en comparación con los archivos CSV de consulta.
Rentable: el formato de archivo Delta Lake es una tecnología de almacenamiento de datos altamente comprimidos que ofrece importantes ahorros potenciales de almacenamiento para las empresas. Este formato está diseñado específicamente para optimizar el procesamiento de datos y reducir potencialmente la cantidad total de datos procesados o el tiempo de ejecución requerido para la informática bajo demanda.
Cumplimiento de la protección de datos: Delta Lake con el Azure Synapse Link proporciona herramientas y funciones que incluyen la eliminación temporal y la eliminación permanente para cumplir con diversas regulaciones de privacidad de datos , incluido el Reglamento general de protección de datos (RGPD).
¿Cómo funciona Delta Lake con Azure Synapse Link Dataverse?
Al configurar un Azure Synapse Link para Dataverse, puede habilitar la característica exportar a Delta Lake y conectarse con un área de trabajo de Synapse y un grupo de Spark. Azure Synapse Link exporta las tablas Dataverse seleccionadas en formato CSV a intervalos de tiempo designados y las procesa a través de un trabajo de Spark de conversión de Delta Lake. Al finalizar este proceso de conversión, los datos CSV se limpian para guardarlos en el almacenamiento. Además, una serie de trabajos de mantenimiento están programados para ejecutarse diariamente, realizando automáticamente procesos de compactación y limpieza para fusionar y limpiar archivos de datos para optimizar aún más el almacenamiento y mejorar el rendimiento de las consultas.
Requisitos previos
Dataverse: debe tener el rol de seguridad de administrador del sistema Dataverse. Además, las tablas que desee exportar mediante Azure Synapse Link deben tener habilitada la propiedad Control de cambios. Más información: Opciones avanzadas
Azure Data Lake Storage Gen2: debe tener una cuenta de Azure Data Lake Storage Gen2 y el acceso a los roles Propietario y Colaborador de datos de Storage Blob. Su cuenta de almacenamiento debe habilitar Espacio de nombres jerárquico y Acceso a la red pública para la configuración inicial y la sincronización delta. Se requiere Permitir el acceso a la clave de la cuenta de almacenamiento solo para la configuración inicial.
Área de trabajo de Synapse: debe tener un área de trabajo de Synapse y el rol Propietario en el control de acceso (IAM) y el acceso al rol Administrador de Synapse dentro de Synapse Studio. El área de trabajo de Synapse debe estar en la misma región que su cuenta de Azure Data Lake Storage Gen2. La cuenta de almacenamiento debe agregarse como un servicio vinculado dentro de Synapse Studio. Para crear un área de trabajo de Synapse, vaya a Crear un área de trabajo de Synapse.
Esta configuración se puede considerar un paso de arranque para casos de uso medio.
Tamaño del nodo: pequeño (4 núcleos virtuales/32 GB)
Escalado automático: Habilitado
Número de nodos: 5 a 10
Pausa automática: Habilitada
Número de minutos inactivo: 5
Apache Spark: 3.4
Asignar ejecutores dinámicamente: habilitado
Número predeterminado de ejecutores: 1 a 9
Importante
Use el grupo de Spark exclusivamente para la operación de conversión de Delta Lake con Synapse Link para Dataverse. Para obtener una fiabilidad y un rendimiento óptimos, evite ejecutar otros trabajos de Spark con el mismo grupo de Spark.
Conecte Dataverse al espacio de trabajo de Synapse y exporte datos en formato Delta Lake
Inicie sesión en Power Apps y seleccione el entorno que desee.
En el panel de navegación izquierdo, seleccione Azure Synapse Link. Si el elemento no se encuentra en el panel lateral, seleccione …Más y, a continuación, el elemento que desee.
En la barra de comandos, seleccione Nuevo enlace
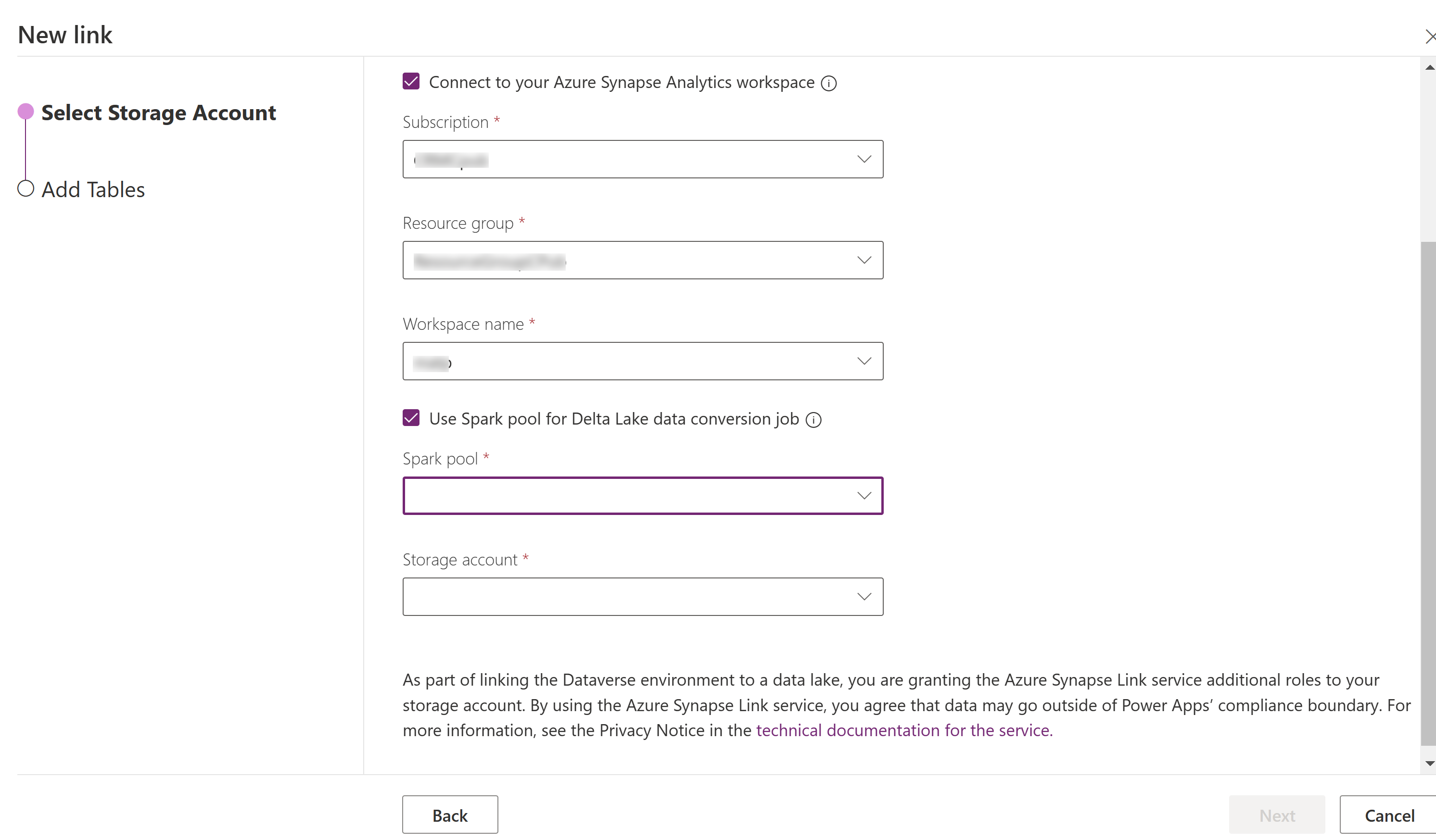
Seleccione Conectarse a su espacio de trabajo Azure Synapse Analytics y luego seleccione Suscripción, Grupo de recursos y Nombre del espacio de trabajo.
Seleccione Usar grupo de Spark para procesar y luego seleccione el grupo de Spark creado previamente y Cuenta de almacenamiento.
Seleccione Siguiente.
Agregue las tablas que desea exportar y luego seleccione Avanzado.
De forma opcional, seleccione Mostrar configuración avanzada e Ingrese el intervalo de tiempo, en minutos, para la frecuencia con la que se deben capturar las actualizaciones incrementales.
Seleccione Guardar.
Supervise su Azure Synapse Link y la conversión de datos
Seleccione el Azure Synapse Link deseado y elija Ir a espacio de trabajo Azure Synapse Analytics en la barra de comandos.
Seleccione el Azure Synapse Link deseado y elija Ir a espacio de trabajo Azure Synapse Analytics en la barra de comandos.
Expanda las Bases de datos Lake en el panel izquierdo, seleccione dataverse-environmentNameorganizationUniqueName y expanda Tablas. Todas las Tablas de Parquet se enumeran y están disponibles para su análisis con la convención de nomenclatura DataverseTableName.(Non_partitioned Table).
Nota
No utilice tablas con la convención de nomenclatura _partitioned. Cuando elige Delta parquet como formato, las tablas con la convención de nomenclatura _partition se utilizan como tablas provisionales y se eliminan una vez que el sistema las utiliza.
Ver sus datos desde Azure Data Lake Storage Gen2
Seleccione el Azure Synapse Link deseado y elija Ir a Azure data lake en la barra de comandos.
Seleccione los Contenedores en Almacenamiento de datos.
Seleccione *dataverse- *environmentName-organizationUniqueName. Todos los archivos de Parquet se almacenan en la carpeta deltalake.
Actualización local a Apache Spark 3.4 con Delta Lake 2.4
Requisitos previos
Debe tener un Azure Synapse Link existente para el perfil de Dataverse Delta Lake que se ejecute con una versión 3.3 de Synapse Spark.
Debe crear un nuevo grupo de Synapse Spark con Spark versión 3.4, utilizando la misma configuración de hardware de nodos o una superior dentro del mismo espacio de trabajo de Synapse. Para obtener información sobre cómo crear un grupo de Spark, vaya a Crear nuevo grupo de Apache Spark. Este grupo de Spark debe crearse independientemente del grupo 3.3 actual.
Actualización local a Spark 3.4:
Inicie sesión en Power Apps y seleccione su entorno preferido.
En el panel de navegación izquierdo, seleccione Azure Synapse Link. Si el elemento no está en el panel de navegación izquierdo, seleccione …Más y, a continuación, el elemento que desee.
Abra el perfil de Azure Synapse Link, y luego seleccione Actualizar a Apache Spark 3.4 con Delta Lake 2.4.
Seleccione el grupo de Spark disponible de la lista y seleccione Actualizar.
Nota
La actualización del grupo de Spark sucede solo cuando se desencadena un nuevo trabajo de Spark de conversión de Delta Lake. Asegúrese de tener al menos un cambio de datos después de seleccionar Actualizar.