Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los modelos semánticos en una capacidad Premium con el punto de conexión XMLA habilitado para operaciones de lectura y escritura permiten implementaciones más avanzadas de actualización, administración de particiones y metadatos mediante herramientas, scripting y compatibilidad con API. Además, las operaciones de actualización mediante el punto de conexión XMLA no se limitan a 48 actualizaciones al día, y no se impone el límite de tiempo de actualización programado.
Particiones
Las particiones de tabla de modelo semántico no son visibles y no se pueden administrar mediante Power BI Desktop o el servicio Power BI. En el caso de los modelos de un área de trabajo asignada a una capacidad Premium, las particiones se pueden administrar a través del punto de conexión XMLA mediante herramientas como SQL Server Management Studio (SSMS), Tabular Editor de código abierto, con scripts con Tabular Model Scripting Language (TMSL) y mediante programación con el Modelo de objetos tabulares (TOM).
La primera vez que publica un modelo en el servicio, Power BI, cada tabla del modelo nuevo tiene una partición. En el caso de las tablas que no tienen una directiva de actualización incremental, esa partición única contiene todas las filas de datos de esa tabla, salvo que se hayan aplicado filtros. En el caso de las tablas con una directiva de actualización incremental, esa partición inicial solo existe porque Power BI todavía no ha aplicado la directiva. La partición inicial de Power BI Desktop se configura al definir el filtro de intervalo de fecha y hora de la tabla según los parámetros RangeStart y RangeEnd, y cualquier otro filtro aplicado en el Editor de Power Query. Esta partición inicial solo contiene las filas de datos que cumplen los criterios del filtro.
Al realizar la primera operación de actualizació, las tablas que no tienen una directiva de actualización incremental actualizan todas las filas contenidas en la partición única predeterminada de esa tabla. En el caso de las tablas que tienen una directiva de actualización incremental, se crean automáticamente particiones históricas y de actualización y las filas se cargan en ellas según la fecha y hora de cada fila. Si la directiva de actualización incremental incluye la obtención de datos en tiempo real, Power BI también agregará una partición DirectQuery a la tabla.
Esta primera operación de actualización puede tardar bastante tiempo en virtud de la cantidad de datos que se deben cargar desde el origen de datos. La complejidad del modelo también puede ser un factor importante, porque las operaciones de actualización deben realizar operaciones de procesamiento y recálculo adicionales. Esta operación se puede arrancar. Para más información, consulte Prevención de tiempos de espera en la actualización completa inicial.
Las particiones se crean y nombran por granularidad de período: años, trimestres, meses y días. Las particiones más recientes, las particiones de actualización, contienen filas en el período de actualización que se especifica en la directiva. Las particiones históricas contienen filas por período completo hasta el período de actualización. Si se habilita la actualización en tiempo real, una partición de DirectQuery recogerá los cambios de datos que se produjeron después de la fecha de finalización del período de actualización. La granularidad de las particiones históricas y de actualización depende de los períodos de actualización e históricos (almacén) que elige al definir la directiva.
Por ejemplo, si hoy es 2 de febrero de 2021 y nuestra tabla FactInternetSales en el origen de datos contiene filas hasta esta fecha, si nuestra directiva especifica que se incluyan cambios en tiempo real, actualice las filas del último período de actualización de un día y almacene las filas del último período histórico de tres años. A continuación, con la primera operación de actualización, se crea una partición de DirectQuery para los cambios futuros, se crea una nueva partición de importación para las filas con fecha de hoy y se crea una partición histórica para ayer, un período de día completo, el 1 de febrero de 2021. Se crea una partición histórica para el período del mes completo anterior (enero de 2021), se crea una partición histórica para el período del año completo anterior (2020) y se crean particiones históricas para los períodos de los años completos 2019 y 2018. No se crean particiones para trimestres completos porque todavía no ha finalizado el primer trimestre completo de 2021.
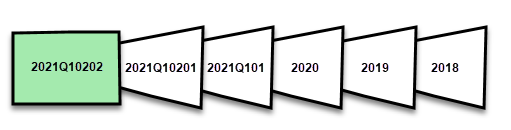
Con cada operación de actualización, solo se actualizan las particiones del período de actualización, y el filtro de fecha de la partición de DirectQuery se actualiza para incluir solo los cambios que se producen después del período de actualización actual. Se crea una nueva partición de actualización para las nuevas filas con una nueva fecha y hora dentro del período de actualización actualizado, y se actualizan las filas existentes con una fecha y hora que ya está dentro de las particiones existentes en el período de actualización. Las filas con fecha y hora anteriores al período de actualización ya no se actualizan.
A medida que se cierran períodos completos, se combinan las particiones. Por ejemplo, si en la directiva se especifica un período de actualización de un día y un período de almacenamiento histórico de tres años, el primer día del mes, todas las particiones de día del mes anterior se combinan en una partición de mes. El primer día de un trimestre nuevo, las tres particiones del mes anterior se combinan en una partición de trimestre. El primer día de un año nuevo, las cuatro particiones del trimestre anterior se combinan en una partición de año.
Un modelo siempre conserva las particiones durante todo el período de almacenamiento histórico más las particiones de período completo hasta el período de actualización actual. En el ejemplo, se conservan tres años completos de datos históricos en particiones para 2018, 2019, 2020, y también particiones para el período de meses 2021Q101, el período de días 2021Q10201 y la partición del período de actualización del día actual. Dado que en el ejemplo se conservan los datos históricos durante tres años, la partición de 2018 se conserva hasta la primera actualización, el 1 de enero de 2022.
Con la actualización incremental de y los datos en tiempo real de Power BI, el servicio controla automáticamente la administración de particiones en función de la directiva. Aunque el servicio puede controlar toda la administración de particiones de forma automática, el uso de herramientas mediante el punto de conexión XMLA permite actualizar selectivamente las particiones de manera individual, secuencial o en paralelo.
Actualización de la administración con SQL Server Management Studio
Se puede usar SQL Server Management Studio (SSMS) para ver y administrar las particiones creadas por la aplicación de directivas de actualización incremental. Al usar SSMS puede, por ejemplo, actualizar una partición histórica específica que no se encuentra en el período de actualización incremental para realizar una actualización con fecha en el pasado sin tener que actualizar todos los datos históricos. También se puede usar SSMS en el arranque a fin de cargar datos históricos para modelos grandes mediante la incorporación o actualización incremental de particiones históricas en lotes.
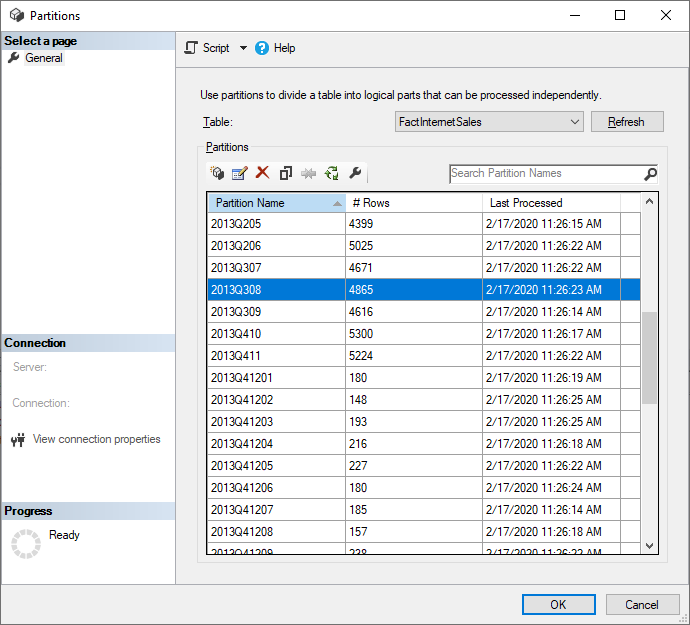
Reemplazo del comportamiento de actualización incremental
Con SSMS, también tiene más control sobre cómo invocar las actualizaciones mediante lenguaje de scripting de modelos tabulares (TMSL) y el modelo de objetos tabulares (TOM). Por ejemplo, en SSMS, en el Explorador de objetos, haga clic con el botón derecho en una tabla y, luego, seleccione la opción de menú Procesar tabla y haga clic en el botón Script para generar un comando de actualización de TMSL.
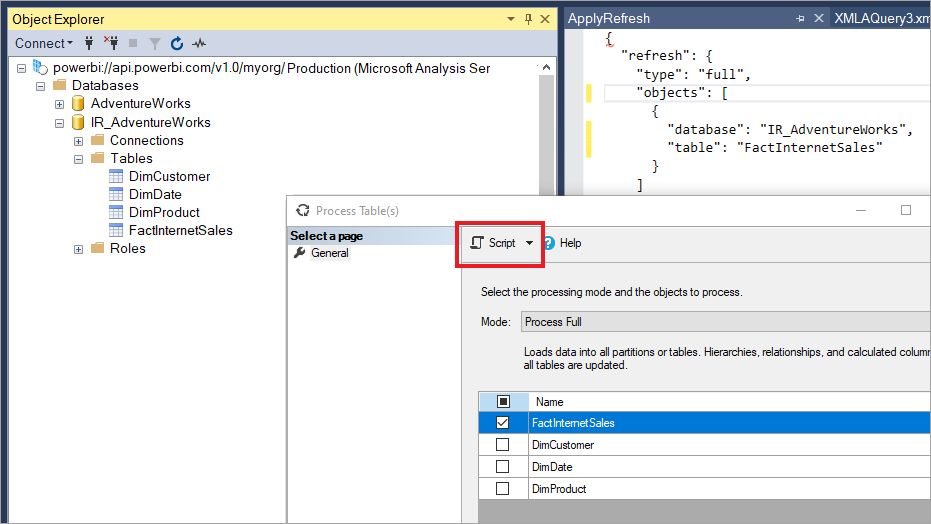
Estos parámetros se pueden usar con el comando de actualización de TMSL para invalidar el comportamiento predeterminado de la actualización incremental:
applyRefreshPolicy. Si una tabla tiene definida una directiva de actualización incremental,
applyRefreshPolicydeterminará si la directiva se aplica o no. Si no se aplica la directiva, una operación de proceso completa deja las definiciones de partición sin cambios y todas las particiones de la tabla se actualizan por completo. El valor predeterminado es true.effectiveDate. Si se va a aplicar una directiva de actualización incremental, se debe conocer la fecha actual para determinar los intervalos de ventana acumulados de los períodos históricos y de actualización incremental. El parámetro
effectiveDatepermite invalidar la fecha actual. Este parámetro es útil para pruebas, demostraciones y escenarios empresariales en los que los datos se actualizan incrementalmente hasta una fecha anterior o posterior, por ejemplo, presupuestos futuros. El valor predeterminado es la fecha actual.
{
"refresh": {
"type": "full",
"applyRefreshPolicy": true,
"effectiveDate": "12/31/2013",
"objects": [
{
"database": "IR_AdventureWorks",
"table": "FactInternetSales"
}
]
}
}
Para obtener más información sobre cómo invalidar el comportamiento predeterminado de la actualización incremental con TMSL, vea comando Refresh.
Garantía de un rendimiento óptimo
Con cada operación de actualización, el servicio Power BI puede enviar consultas de inicialización al origen de datos para cada partición de actualización incremental. Para mejorar el rendimiento de la actualización incremental, se puede reducir el número de consultas de inicialización, garantizando la siguiente configuración:
- La tabla para la que configura la actualización incremental debe obtener datos de un único origen de datos. Si la tabla obtiene datos de más de un origen de datos, el número de consultas que envía el servicio para cada operación de actualización se multiplica por el número de orígenes de datos, lo que puede reducir el rendimiento de la actualización. Asegúrese de que la consulta de la tabla de actualización incremental se realiza para un único origen de datos.
- Para las soluciones con actualización incremental de particiones de importación y datos en tiempo real con Direct Query, todas las particiones deben consultar datos de un único origen de datos.
- Si los requisitos de seguridad lo permiten, establezca la opción de nivel de privacidad del origen de datos en Organizativo o Público. De forma predeterminada, el nivel de privacidad es Privado; sin embargo, este nivel puede impedir que los datos se intercambien con otros orígenes en la nube. Para establecer el nivel de privacidad, seleccione el menú Más opciones y, luego, elija Configuración>Credenciales de origen de datos>Editar credenciales>Nivel de privacidad para este origen de datos. Si se establece el nivel de privacidad en el modelo de Power BI Desktop antes de publicarlo en el servicio, no se transfiere al servicio cuando se publique. Todavía debe establecerlo en la configuración del modelo semántico en el servicio. Para obtener más información, vea Niveles de privacidad.
- Si se usa una puerta de enlace de datos local, asegúrese de que usa la versión 3000.77.3 o una posterior.
Prevención de tiempos de espera en la actualización completa inicial
Después de publicarlo en el servicio Power BI, la operación de actualización completa inicial del modelo crea particiones para la tabla de actualización incremental y carga y procesa los datos históricos de todo el período definido en la directiva de actualización incremental. En el caso de algunos modelos que cargan y procesan grandes cantidades de datos, la cantidad de tiempo que tarda la operación de actualización inicial puede superar el límite de tiempo de actualización que impone el servicio o un límite de tiempo de consulta que impone el origen de datos.
El arranque de la operación de actualización inicial permite al servicio crear objetos de partición para la tabla de actualización incremental, pero no cargar ni procesar datos históricos en ninguna de las particiones. Después, se usa SSMS para procesar las particiones de manera selectiva. En función de la cantidad de datos que se carguen para cada partición, puede procesar cada partición de manera secuencial o en lotes pequeños, a fin de reducir la posibilidad de que una o varias de esas particiones causen un tiempo de espera. Los métodos siguientes funcionan para cualquier origen de datos.
Aplicar directiva de actualización
La herramienta Tabular Editor 2 de código abierto proporciona una manera sencilla de arrancar una operación de actualización inicial. Después de publicar en el servicio un modelo con una directiva de actualización incremental definida para él desde Power BI Desktop, conéctese al modelo mediante el punto de conexión XMLA en modo de lectura y escritura. Ejecute Aplicar directiva de actualización en la tabla de actualización incremental. Con solo la directiva aplicada, se crean particiones, pero no se cargan datos en ellas. Después, conéctese a SSMS para actualizar las particiones de forma secuencial o en lotes para cargar y procesar los datos. Para más información, consulte Actualización incremental en la documentación del Editor tabular.
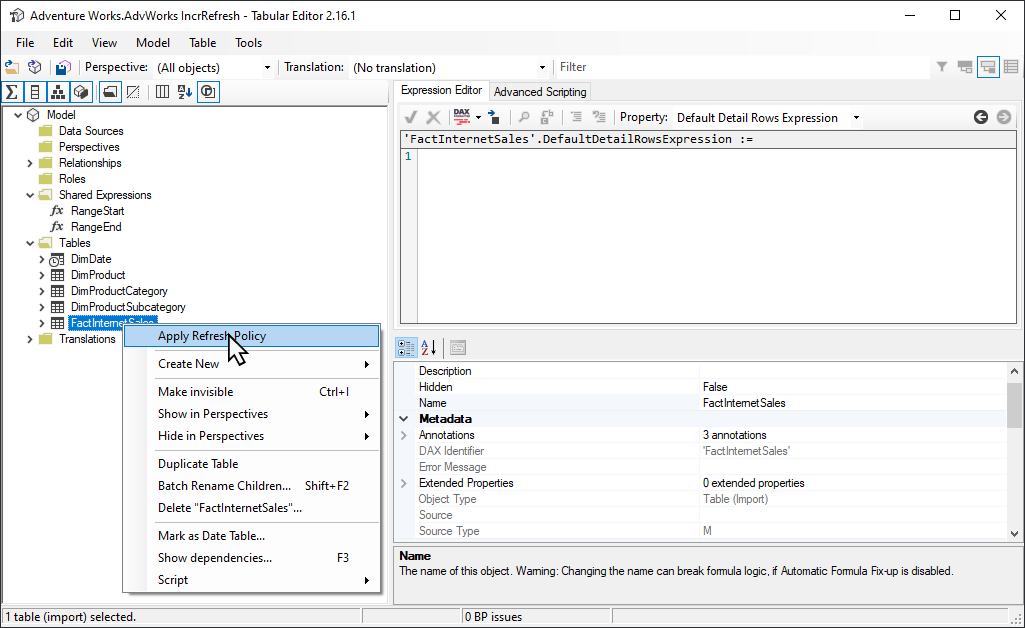
Filtro de Power Query para particiones vacías
Antes de publicar el modelo en el servicio, en el Editor de Power Query, agregue otro filtro a la columna ProductKey que filtre cualquier valor distinto de 0 o que filtre todos los datos de la tabla FactInternetSales.
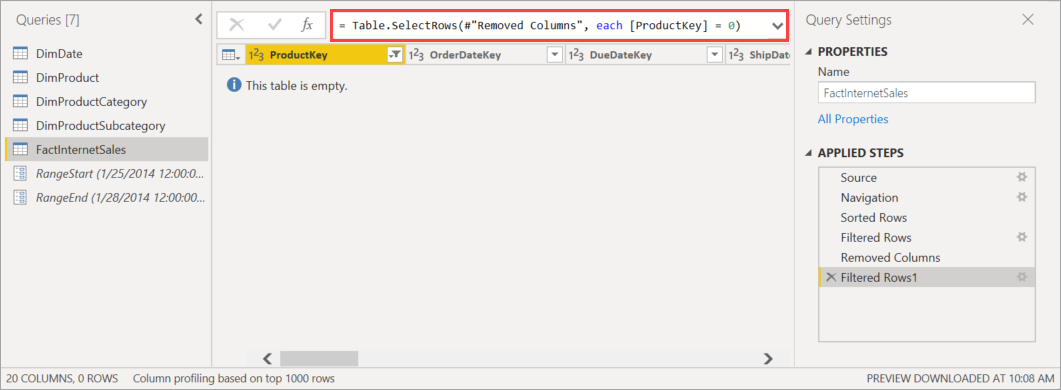
Después de seleccionar Cerrar y aplicar en el Editor de Power Query, definir la directiva de actualización incremental y guardar el modelo, este se publica en el servicio. Desde el servicio, se ejecuta la operación de actualización inicial en el modelo. Las particiones de la tabla FactInternetSales se crean con arreglo a la directiva, pero no se cargan ni procesan datos, porque todos se han filtrado.
Una vez que se completa la operación de actualización inicial, de nuevo en el Editor de Power Query, se quita el otro filtro de la columna ProductKey. Después de seleccionar Cerrar y aplicar en el Editor de Power Query, y de guardar el modelo, no se vuelve a publicar. Si el modelo se vuelve a publicar, se sobrescribe la configuración de la directiva de actualización incremental y se fuerza una actualización completa del modelo cuando se realiza una operación de actualización posterior desde el servicio. En su lugar, realice una implementación solo de metadatos mediante el kit de herramientas de administración del ciclo de vida de la aplicación (ALM), que quita el filtro de la columna ProductKey del modelo. Después, se puede usar SSMS para procesar las particiones de manera selectiva. Cuando todas las particiones se hayan procesado completamente (lo que debe incluir un recálculo del proceso en todas las particiones), desde SSMS, las operaciones de actualización subsiguientes en el modelo desde el servicio solo actualizan las particiones de actualización incremental.
Sugerencia
Asegúrese de consultar vídeos, blogs y muchos otros recursos más proporcionados por la comunidad de expertos en BI de Power BI.
Para más información sobre el procesamiento de tablas y particiones de SSMS, consulte Procesamiento de bases de datos, tablas o particiones (Analysis Services). Para más información sobre el procesamiento de modelos, tablas y particiones mediante TMSL, consulte Comando de actualización (TMSL).
Personalización de consultas para detectar cambios de datos
Se puede usar TMSL o TOM para invalidar el comportamiento de los cambios de datos detectados. Este método se puede usar no solo para evitar que se conserve la columna de última actualización en la caché en memoria, sino que puede permitir escenarios en los que los procesos de extracción, transformación y carga (ETL) preparan una tabla de configuración o instrucción con el fin de marcar solo las particiones que se deben actualizar. Este método puede crear un proceso de actualización incremental más eficaz donde solo se actualicen los períodos necesarios, con independencia del tiempo transcurrido desde las actualizaciones de datos.
La expresión pollingExpression está diseñada para ser una expresión M ligera o el nombre de otra consulta M. Debe devolver un valor escalar y se ejecutará para cada partición. Si el valor devuelto es diferente al de la última vez que se produjo una actualización incremental, la partición se marca para su procesamiento completo.
En el ejemplo siguiente se abarcan los 120 meses del período histórico para los cambios con fecha en el pasado. Especificar 120 meses en lugar de 10 años significa que la compresión de datos puede no ser tan eficiente, pero evita tener que actualizar todo un año histórico, lo que sería más caro cuando un mes sería suficiente para un cambio retroactivo.
"refreshPolicy": {
"policyType": "basic",
"rollingWindowGranularity": "month",
"rollingWindowPeriods": 120,
"incrementalGranularity": "month",
"incrementalPeriods": 120,
"pollingExpression": "<M expression or name of custom polling query>",
"sourceExpression": [
"let ..."
]
}
Sugerencia
Asegúrese de consultar vídeos, blogs y muchos otros recursos más proporcionados por la comunidad de expertos en BI de Power BI.
Implementación de solo metadatos
Al publicar una versión nueva de un archivo .pbix desde Power BI Desktop en un área de trabajo, si ya existe un modelo con el mismo nombre, se le pedirá que reemplace el modelo existente.
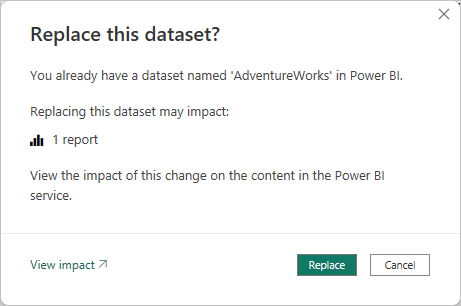
En algunos casos, es posible que no quiera reemplazar el modelo, especialmente con la actualización incremental. El modelo de Power BI Desktop podría ser mucho menor que el del servicio Power BI. Si el modelo del servicio Power BI tiene aplicada una directiva de actualización incremental, puede que tenga varios años de datos históricos que se perderán si el modelo se reemplaza. La actualización de todos los datos históricos podría tardar horas y provocar un tiempo de inactividad del sistema para los usuarios.
En su lugar, es mejor realizar una implementación solo de metadatos, lo que permite la implementación de nuevos objetos sin perder los datos históricos. Por ejemplo, si agregó algunas medidas, puede implementar solo las medidas nuevas sin necesidad de actualizar los datos, lo que ahorra tiempo.
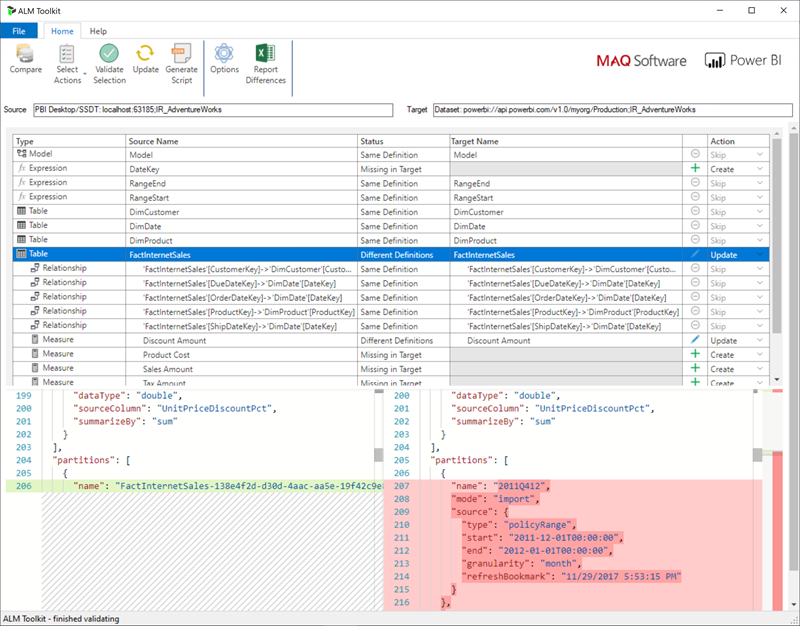
En el caso de las áreas de trabajo asignadas a una capacidad Premium configurada para lectura y escritura de puntos de conexión XMLA, las herramientas compatibles permiten la implementación de solo metadatos. Por ejemplo, ALM Toolkit es una herramienta de comparación de esquemas para los modelos de Power BI y se puede usar para realizar la implementación solo de metadatos.
Descargue e instale la versión más reciente de ALM Toolkit desde el repositorio de Git de Analysis Services. La guía paso a paso sobre el uso del kit de herramientas de ALM no está incluida en la documentación de Microsoft. Los vínculos de la documentación del kit de herramientas de ALM y la información sobre compatibilidad están disponibles en la cinta de opciones de la Ayuda. Para realizar una implementación de solo metadatos, compare y seleccione la instancia de Power BI Desktop en ejecución como origen y el modelo existente en el servicio Power BI como destino. Tenga en cuenta las diferencias que se muestran y omita la actualización de la tabla con particiones de actualización incremental, o use el cuadro de diálogo Opciones para conservar las particiones para las actualizaciones de la tabla. Valide la selección para garantizar la integridad del modelo de destino y, a continuación, actualice.
Adición de una directiva de actualización incremental y datos en tiempo real mediante programación
También puede usar TMSL y TOM para agregar una directiva de actualización incremental a un modelo existente a través del punto de conexión XMLA.
Nota:
Para evitar problemas de compatibilidad, asegúrese de usar la versión más reciente de las bibliotecas cliente de Analysis Services. Por ejemplo, para trabajar con directivas híbridas, la versión debe ser la 19.27.1.8 o superior.
El proceso incluye los siguientes pasos:
Asegúrese de que el modelo de destino tiene el nivel de compatibilidad mínimo necesario. En SSMS, haga clic con el botón derecho en [nombre del modelo]>Propiedades>Nivel de compatibilidad. Para aumentar el nivel de compatibilidad, use un script TMSL createOrReplace o compruebe el siguiente código de ejemplo de TOM para obtener un ejemplo.
a. Import policy - 1550 b. Hybrid policy - 1565Agregue los parámetros
RangeStartyRangeEnda las expresiones de modelo. Si es necesario, agregue también una función para convertir valores de fecha y hora en claves de fecha.Defina un objeto
RefreshPolicycon el archivado que quiere (ventana gradual) y los períodos de actualización incremental, así como una expresión de origen que filtre la tabla de destino en función de los parámetrosRangeStartyRangeEnd. Establezca el modo de directiva de actualización en Importar o Híbrido en función de los requisitos de datos en tiempo real. Híbrido hace que Power BI agregue una partición de DirectQuery a la tabla para capturar los cambios más recientes del origen de datos que se produjeron después de la hora de la última actualización.Agregue la directiva de actualización a la tabla y realice una actualización completa para las particiones de Power BI de la tabla según sus requisitos.
En el ejemplo de código siguiente se muestra cómo realizar los pasos anteriores mediante TOM. Si quiere usar este ejemplo tal y como está, debe tener una copia para la base de datos AdventureWorksDW e importar la tabla FactInternetSales en un modelo. En el ejemplo de código se supone que los parámetros RangeStart y RangeEnd y la función DateKey no existen en el modelo. Solo tiene que importar la tabla FactInternetSales y publicar el modelo en un área de trabajo de Power BI Premium. Después, actualice workspaceUrl para que el código de ejemplo pueda conectarse al modelo. Actualice otras líneas de código según sea necesario.
using System;
using TOM = Microsoft.AnalysisServices.Tabular;
namespace Hybrid_Tables
{
class Program
{
static string workspaceUrl = "<Enter your Workspace URL here>";
static string databaseName = "AdventureWorks";
static string tableName = "FactInternetSales";
static void Main(string[] args)
{
using (var server = new TOM.Server())
{
// Connect to the dataset.
server.Connect(workspaceUrl);
TOM.Database database = server.Databases.FindByName(databaseName);
if (database == null)
{
throw new ApplicationException("Database cannot be found!");
}
if(database.CompatibilityLevel < 1565)
{
database.CompatibilityLevel = 1565;
database.Update();
}
TOM.Model model = database.Model;
// Add RangeStart, RangeEnd, and DateKey function.
model.Expressions.Add(new TOM.NamedExpression {
Name = "RangeStart",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 30, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "RangeEnd",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 31, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "DateKey",
Kind = TOM.ExpressionKind.M,
Expression =
"let\n" +
" Source = (x as datetime) => Date.Year(x)*10000 + Date.Month(x)*100 + Date.Day(x)\n" +
"in\n" +
" Source"
});
// Apply a RefreshPolicy with Real-Time to the target table.
TOM.Table salesTable = model.Tables[tableName];
TOM.RefreshPolicy hybridPolicy = new TOM.BasicRefreshPolicy
{
Mode = TOM.RefreshPolicyMode.Hybrid,
IncrementalPeriodsOffset = -1,
RollingWindowPeriods = 1,
RollingWindowGranularity = TOM.RefreshGranularityType.Year,
IncrementalPeriods = 1,
IncrementalGranularity = TOM.RefreshGranularityType.Day,
SourceExpression =
"let\n" +
" Source = Sql.Database(\"demopm.database.windows.net\", \"AdventureWorksDW\"),\n" +
" dbo_FactInternetSales = Source{[Schema=\"dbo\",Item=\"FactInternetSales\"]}[Data],\n" +
" #\"Filtered Rows\" = Table.SelectRows(dbo_FactInternetSales, each [OrderDateKey] >= DateKey(RangeStart) and [OrderDateKey] < DateKey(RangeEnd))\n" +
"in\n" +
" #\"Filtered Rows\""
};
salesTable.RefreshPolicy = hybridPolicy;
model.RequestRefresh(TOM.RefreshType.Full);
model.SaveChanges();
}
Console.WriteLine("{0}{1}", Environment.NewLine, "Press [Enter] to exit...");
Console.ReadLine();
}
}
}