En este artículo se describe una arquitectura que usa Azure Machine Learning para predecir la delincuencia y las probabilidades predeterminadas de los solicitantes de préstamos. Las predicciones del modelo se basan en el comportamiento fiscal del solicitante. El modelo usa un enorme conjunto de puntos de datos para clasificar a los solicitantes y proporcionar una puntuación de elegibilidad para cada solicitante.
Apache®, Spark y el logotipo de la llama son marcas registradas o marcas comerciales de Apache Software Foundation en los Estados Unidos y otros países. El uso de estas marcas no implica la aprobación de Apache Software Foundation.
Architecture

Descargue un archivo Visio de esta arquitectura.
Flujo de datos
El siguiente flujo de trabajo corresponde al diagrama anterior:
Almacenamiento: los datos se almacenan en una base de datos como un grupo de Azure Synapse Analytics si están estructurados. Las bases de datos SQL anteriores se pueden integrar en el sistema. Los datos semiestructurados y no estructurados se pueden cargar en un lago de datos.
Ingesta y preprocesamiento: las canalizaciones de procesamiento de Azure Synapse Analytics y el procesamiento de ETL pueden conectarse a los datos almacenados en Azure o a orígenes de terceros a través de conectores integrados. Azure Synapse Analytics admite varias metodologías de análisis que usan SQL, Spark, Azure Data Explorer y Power BI. También puede usar la orquestación de Azure Data Factory existente para las canalizaciones de datos.
Procesamiento: Azure Machine Learning se usa para desarrollar y administrar los modelos de Machine Learning.
Procesamiento inicial: durante esta fase, los datos sin procesar se procesan para crear un conjunto de datos mantenido que entrenará un modelo de aprendizaje automático. Entre las operaciones típicas se incluyen el formato de tipo de datos, la imputación de los valores que faltan, la ingeniería de características, la selección de características y la reducción de dimensionalidad.
Entrenamiento: durante la fase de entrenamiento, Azure Machine Learning usa el conjunto de datos procesado para entrenar el modelo de riesgo de crédito y seleccionar el mejor modelo.
Entrenamiento de modelos: puede usar una variedad de modelos de Machine Learning, incluidos los modelos de Machine Learning clásicos y los de aprendizaje profundo. Puede usar el ajuste de hiperparámetros para optimizar el rendimiento del modelo.
Evaluación del modelo: Azure Machine Learning evalúa el rendimiento de cada modelo entrenado para que pueda seleccionar el mejor para la implementación.
Registro de modelos: debe registrar el modelo que funciona mejor en Azure Machine Learning. Este paso hace que el modelo esté disponible para la implementación.
c. La IA responsable es un enfoque para desarrollar, evaluar e implementar sistemas de IA de manera segura, confiable y ética. Dado que este modelo deduce una decisión de aprobación o denegación para una solicitud de préstamo, debe implementar los principios de inteligencia artificial responsable.
Las métricas de equidad evalúan el efecto del comportamiento incorrecto y permiten estrategias de mitigación. Los atributos y características confidenciales se identifican en el conjunto de datos y en cohortes (subconjuntos) de los datos. Para obtener más información, consulte Rendimiento y equidad del modelo.
La interpretación es una medida de lo bien que puede comprender el comportamiento de un modelo de Machine Learning. Este componente de IA responsable genera descripciones comprensibles de las predicciones del modelo. Para obtener más información, vea Interpretación del modelo.
Implementación de aprendizaje automático en tiempo real: debe usar la inferencia de modelos en tiempo real cuando la solicitud se debe revisar inmediatamente para su aprobación.
- Punto de conexión en línea de Azure Machine Learning administrado. Para la puntuación en tiempo real, debe elegir un destino de proceso adecuado.
- Las solicitudes en línea para préstamos usan la puntuación en tiempo real en función de la entrada del formulario o la solicitud de préstamo del solicitante.
- La decisión y la entrada usada para la puntuación del modelo se almacenan en el almacenamiento persistente y se pueden recuperar para futuras referencias.
Implementación de aprendizaje automático por lotes: para el procesamiento de préstamos sin conexión, el modelo está programado para desencadenarse a intervalos regulares.
- Punto de conexión por lotes administrado. La inferencia por lotes está programada y se crea el conjunto de datos de resultados. Las decisiones se basan en la confiabilidad del solicitante.
- El conjunto de resultados de puntuación del procesamiento por lotes se conserva en la base de datos o en el almacenamiento de datos de Azure Synapse Analytics.
Interfaz a los datos sobre la actividad del solicitante: los detalles proporcionados por el solicitante, el perfil de crédito interno y la decisión del modelo se almacenan provisionalmente y almacenan en los servicios de datos adecuados. Estos detalles se usan en el motor de decisión para la puntuación futura, por lo que se documentan.
- Almacenamiento: todos los detalles del procesamiento de crédito se conservan en el almacenamiento persistente.
- Interfaz de usuario: la decisión de aprobación o denegación se presenta al solicitante.
Informes: la información en tiempo real sobre el número de solicitudes procesadas y la aprobación o denegación de resultados se presenta continuamente a los administradores y el liderazgo. Entre los ejemplos de informes se incluyen informes casi en tiempo real de importes aprobados, la cartera de préstamos creada y el rendimiento del modelo.
Componentes
- Azure Blob Storage proporciona almacenamiento de objetos escalable para datos no estructurados. Está optimizado para almacenar archivos como archivos binarios, registros de actividad y archivos que no cumplen un formato específico.
- Azure Data Lake Storage es la base de almacenamiento para crear lagos de datos rentables en Azure. Proporciona Blob Storage con una estructura jerárquica de carpetas y un rendimiento, administración y seguridad mejorados. Suministra varios petabytes de información, al mismo tiempo que mantiene un rendimiento de cientos de gigabits.
- Azure Synapse Analytics es un servicio de análisis que reúne lo mejor de las tecnologías de SQL y Spark y una experiencia de usuario unificada para Azure Synapse Data Explorer y canalizaciones. Integración profunda con Power BI, Azure Cosmos DB y Azure Machine Learning. El servicio admite modelos de recursos dedicados y sin servidor y la capacidad de cambiar entre esos modelos.
- Azure SQL Database es una base de datos relacional siempre actualizada y totalmente administrada creada para la nube.
- Azure Machine Learning es un servicio en la nube que permite administrar los ciclos de vida de los proyectos de aprendizaje automático. Proporciona un entorno integrado para la exploración de datos, la compilación y administración de modelos y la implementación, y admite enfoques de Code First y con poco código o sin código para el aprendizaje automático.
- Power BI es una herramienta de visualización que proporciona una integración sencilla con los recursos de Azure.
- Azure App Service le permite compilar y hospedar aplicaciones web, back-ends móviles y API de RESTful sin necesidad de administrar la infraestructura. Entre los lenguajes admitidos se incluyen .NET, .NET Core, Java, Ruby, Node.js, PHP y Python.
Alternativas
Puede usar Azure Databricks para desarrollar, implementar y administrar modelos de Machine Learning y cargas de trabajo de análisis. El servicio proporciona un entorno unificado para el desarrollo de modelos.
Detalles del escenario
Las organizaciones del sector financiero necesitan predecir el riesgo de crédito de individuos o empresas que solicitan crédito. Este modelo evalúa la delincuencia y las probabilidades predeterminadas de los solicitantes de préstamo.
La predicción del riesgo de crédito implica un análisis profundo del comportamiento de la población y la clasificación de la base de clientes en segmentos basados en la responsabilidad fiscal. Otras variables incluyen factores de mercado y condiciones económicas, que tienen una influencia significativa en los resultados.
Desafíos. Los datos de entrada incluyen decenas de millones de perfiles de cliente y datos sobre el comportamiento del crédito del cliente y los hábitos de gasto basados en miles de millones de registros de sistemas dispares, como los sistemas internos de actividad del cliente. Los datos de terceros sobre las condiciones económicas y el análisis del mercado del país o región pueden proceder de instantáneas mensuales o trimestrales que requieren la carga y mantenimiento de cientos de GB de archivos. Se necesita información de la agencia de crédito sobre las filas del solicitante o semiestructuradas de los datos de los clientes y las combinaciones cruzadas entre estos conjuntos de datos y las comprobaciones de calidad para validar la integridad de los datos.
Los datos normalmente constan de tablas de columnas anchas de información de clientes de agencias de crédito junto con el análisis de mercado. La actividad del cliente consta de registros con diseño dinámico que podría no estar estructurado. Los datos también están disponibles en texto de forma libre de las notas del servicio de atención al cliente y los formularios de interacción del solicitante.
El procesamiento de estos grandes volúmenes de datos y la garantía de que los resultados son actuales requiere un procesamiento simplificado. Necesita un proceso de almacenamiento y recuperación de baja latencia. La infraestructura de datos debe ser capaz de escalar para admitir orígenes de datos dispares y proporcionar la capacidad de administrar y proteger el perímetro de datos. La plataforma de aprendizaje automático debe admitir el análisis complejo de los muchos modelos entrenados, probados y validados en muchos segmentos de población.
Confidencialidad y privacidad de los datos. El procesamiento de datos de este modelo implica datos personales y detalles demográficos. Debe evitar la generación de perfiles de poblaciones. La visibilidad directa de todos los datos personales debe estar restringida. Algunos ejemplos de datos personales son los números de cuenta, los detalles de la tarjeta de crédito, los números del seguro social, los nombres, las direcciones y los códigos postales.
Las tarjetas de crédito y los números de cuenta bancaria siempre deben ofuscarse. Es necesario enmascarar y cifrar determinados elementos de datos, lo que no proporciona acceso a la información subyacente, pero está disponible para su análisis.
Los datos deben cifrarse en reposo, en tránsito y durante el procesamiento a través de enclaves seguros. El acceso a los elementos de datos se registra en una solución de supervisión. El sistema de producción debe configurarse con canalizaciones de CI/CD adecuadas con aprobaciones que desencadenan implementaciones y procesos del modelo. La auditoría de los registros y el flujo de trabajo deben proporcionar las interacciones con los datos de las necesidades de cumplimiento.
Procesamiento. Este modelo requiere una gran potencia computacional para el análisis, la contextualización y el entrenamiento y la implementación del modelo. La puntuación del modelo se valida con muestras aleatorias para asegurarse de que las decisiones de crédito no incluyan ningún sesgo de raza, género, étnico o ubicación geográfica. El modelo de decisión debe documentarse y archivarse para futuras referencias. Se almacenan todos los factores implicados en los resultados de la decisión.
El procesamiento de datos requiere un uso elevado de CPU. Incluye el procesamiento de SQL de datos estructurados en formato DB y JSON, el procesamiento de Spark de las tramas de datos o el análisis de macrodatos en terabytes de información en varios formatos de documento. Los trabajos de ELT/ETL de datos se programan o desencadenan a intervalos regulares o en tiempo real, en función del valor de los datos más recientes.
Marco de cumplimiento normativo. Debe documentarse cada detalle del procesamiento de préstamos, incluidas la solicitud enviada, las características usadas en la puntuación del modelo y el conjunto de resultados del modelo. La información de entrenamiento del modelo, los datos usados para el entrenamiento y los resultados del entrenamiento deben registrarse para futura referencia y futuras solicitudes de auditoría y cumplimiento.
Puntuación por lotes frente a puntuación en tiempo real. Algunas tareas son proactivas y se pueden procesar como trabajos por lotes, como transferencias de saldo aprobadas previamente. Algunas solicitudes, como los aumentos de la línea de crédito en línea, requieren aprobación en tiempo real.
El acceso en tiempo real al estado de las solicitudes de préstamos en línea debe estar disponible para el solicitante. La institución financiera emisora de préstamos supervisa continuamente el rendimiento del modelo de crédito y necesita información sobre métricas como el estado de aprobación del préstamo, el número de préstamos aprobados, los importes en dólares emitidos y la calidad de los nuevos orígenes de préstamos.
Inteligencia artificial responsable
El panel de inteligencia artificial responsable proporciona una única interfaz para varias herramientas que pueden ayudarle a implementar inteligencia artificial responsable. El estándar de inteligencia artificial responsable se basa en seis principios:
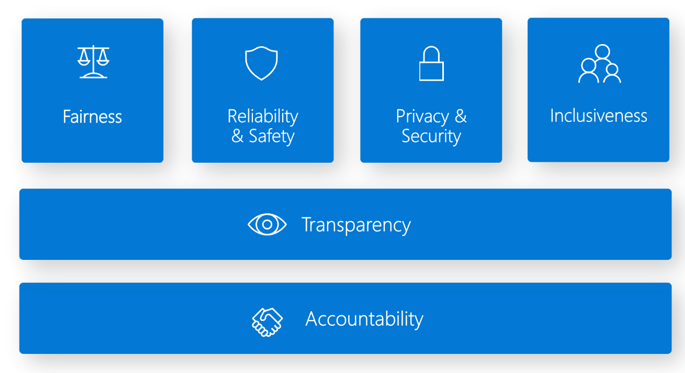
Equidad e inclusión en Azure Machine Learning. Este componente del panel de inteligencia artificial responsable le ayuda a evaluar comportamientos injustos al evitar daños en la asignación y de la calidad del servicio. Puede usarlo para evaluar la equidad entre grupos confidenciales definidos en términos de género, edad, etnia y otras características. Durante la valoración, la equidad se cuantifica a través de las métricas de disparidad. Debe implementar los algoritmos de mitigación en el paquete de código abierto Fairlearn, que usan restricciones de paridad.
Confiabilidad y seguridad en Azure Machine Learning. El componente de análisis de errores de Inteligencia artificial responsable puede ayudarle a:
- Adquirir un profundo conocimiento de cómo se distribuye el error en un modelo.
- Identificar las cohortes de los datos con una tasa de error mayor que la prueba comparativa general.
Transparencia en Azure Machine Learning. Una parte fundamental de la transparencia es comprender cómo afectan las características al modelo de Machine Learning.
- La interpretación del modelo le ayuda a comprender qué influye en el comportamiento del modelo. Genera descripciones comprensibles del usuario de las predicciones del modelo. Esta comprensión ayuda a garantizar que puede confiar en el modelo y le ayuda a depurarlo y mejorarlo. InterpretML puede ayudarle a comprender la estructura de los modelos de caja de cristal o la relación entre las características de los modelos de red neuronal profunda de caja negra.
- El componente de hipótesis contrafactual puede ayudarle a comprender y depurar un modelo de Machine Learning en términos de su reacción ante los cambios y problemas de características.
Privacidad y seguridad en Azure Machine Learning. Los administradores de Machine Learning deben crear una configuración segura para desarrollar y administrar la implementación de modelos. Las características de seguridad y gobernanza pueden ayudarle a cumplir las directivas de seguridad de su organización. Otras herramientas pueden ayudarle a evaluar y proteger los modelos.
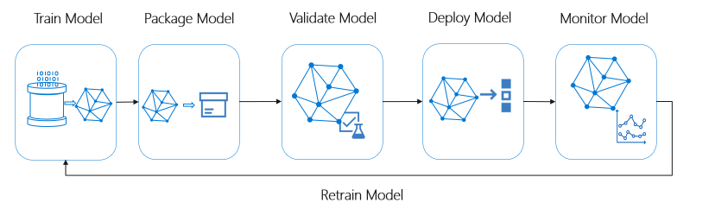
Responsabilidad en Azure Machine Learning. Las operaciones de Machine Learning (MLOps) se basan en los principios y procedimientos de DevOps que aumentan la eficacia de los flujos de trabajo de IA. Azure Machine Learning puede ayudarle a implementar funcionalidades de MLOps:
- Registro, empaquetado e implementación de modelos
- Obtención de notificaciones y alertas para los cambios en los modelos
- Captura de los datos de gobernanza del ciclo de vida de un extremo a otro
- Supervisión de aplicaciones para problemas operativos
En este diagrama se muestran las funcionalidades de MLOps de Azure Machine Learning:
Posibles casos de uso
Puede aplicar esta solución a los escenarios siguientes:
- Finanzas: obtenga análisis financiero de clientes o análisis de ventas cruzadas de clientes para campañas de marketing dirigidas.
- Atención sanitaria: use la información del paciente como entrada para sugerir ofertas de tratamiento.
- Hospitalidad: cree un perfil de cliente para sugerir ofertas para hoteles, vuelos, paquetes de cruceros y pertenencias.
Consideraciones
Estas consideraciones implementan los pilares del Azure Well-Architected Framework, que es un conjunto de principios rectores que puede utilizar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Seguridad
La seguridad proporciona garantías contra ataques deliberados y el abuso de datos y sistemas valiosos. Para más información, consulte Introducción al pilar de seguridad.
Las soluciones de Azure proporcionan defensa en profundidad y un enfoque de Confianza cero.
Considere la posibilidad de implementar las siguientes características de seguridad en esta arquitectura:
- Implementación de servicios de Azure dedicados en las redes virtuales
- Funcionalidades de seguridad de Azure SQL Database
- Protección de las credenciales en Data Factory mediante Key Vault
- Seguridad de empresa y gobernanza para Azure Machine Learning
- Base de referencia de seguridad de Azure para un área de trabajo de Synapse Analytics
Optimización de costos
La optimización de costos trata de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para más información, vea Información general del pilar de optimización de costos.
Para estimar el costo de implementación de esta solución, use la Calculadora de precios de Azure.
Tenga en cuenta también estos recursos:
- Planeamiento y administración de costos de Azure Synapse Analytics
- Planeamiento y administración de los costos de Azure Machine Learning
Excelencia operativa
La excelencia operativa abarca los procesos de las operaciones que implementan una aplicación y la mantienen en ejecución en producción. Para más información, consulte Introducción al pilar de excelencia operativa.
Las soluciones de Machine Learning deben ser escalables y estandarizadas para facilitar la administración y el mantenimiento. Asegúrese de que la solución admite la inferencia continua con ciclos de reentrenamiento y reimplementaciones automatizadas de modelos.
Para más información, consulte Acelerador de soluciones Azure MLOps (v2).
Eficiencia del rendimiento
La eficiencia del rendimiento es la capacidad de la carga de trabajo para escalar con el fin de satisfacer de manera eficiente las demandas que los usuarios hayan ejercido sobre ella. Para obtener más información, vea Resumen del pilar de eficiencia del rendimiento.
- Para más información sobre cómo diseñar soluciones escalables, consulte Lista de comprobación de eficiencia del rendimiento.
- Para obtener información sobre los sectores regulados, consulte Escalado de iniciativas de inteligencia artificial y Machine Learning en sectores regulados.
- Administre el entorno de Azure Synapse Analytics con grupos de SQL, Spark o SQL sin servidor.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Charitha Basani | Arquitecto sénior de soluciones en la nube
Otro colaborador:
- Mick Alberts | Escritor técnico
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
- Base de referencia de seguridad de Azure Machine Learning
- Azure Synapse Analytics
- Implementación de modelos de aprendizaje automático en Azure
- Definición de inteligencia artificial responsable