Actividad Flujo de datos de Azure Data Factory y Azure Synapse Analytics
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
Utilice la actividad de Data Flow para transformar y trasladar datos a través de flujos de datos de asignación. Si no está familiarizado con los flujos de datos, consulte esta introducción a los flujos de datos de asignación.
Creación de una actividad de flujo de datos con la interfaz de usuario
Para usar una actividad de flujo de datos en una canalización, complete los pasos siguientes:
Busque Flujo de datos en el panel Actividades de canalización y arrastre una actividad de flujo de datos al lienzo de canalización.
Seleccione la nueva actividad de flujo de datos en el lienzo si aún no está seleccionada y seleccione la pestaña Configuración para editar los detalles.
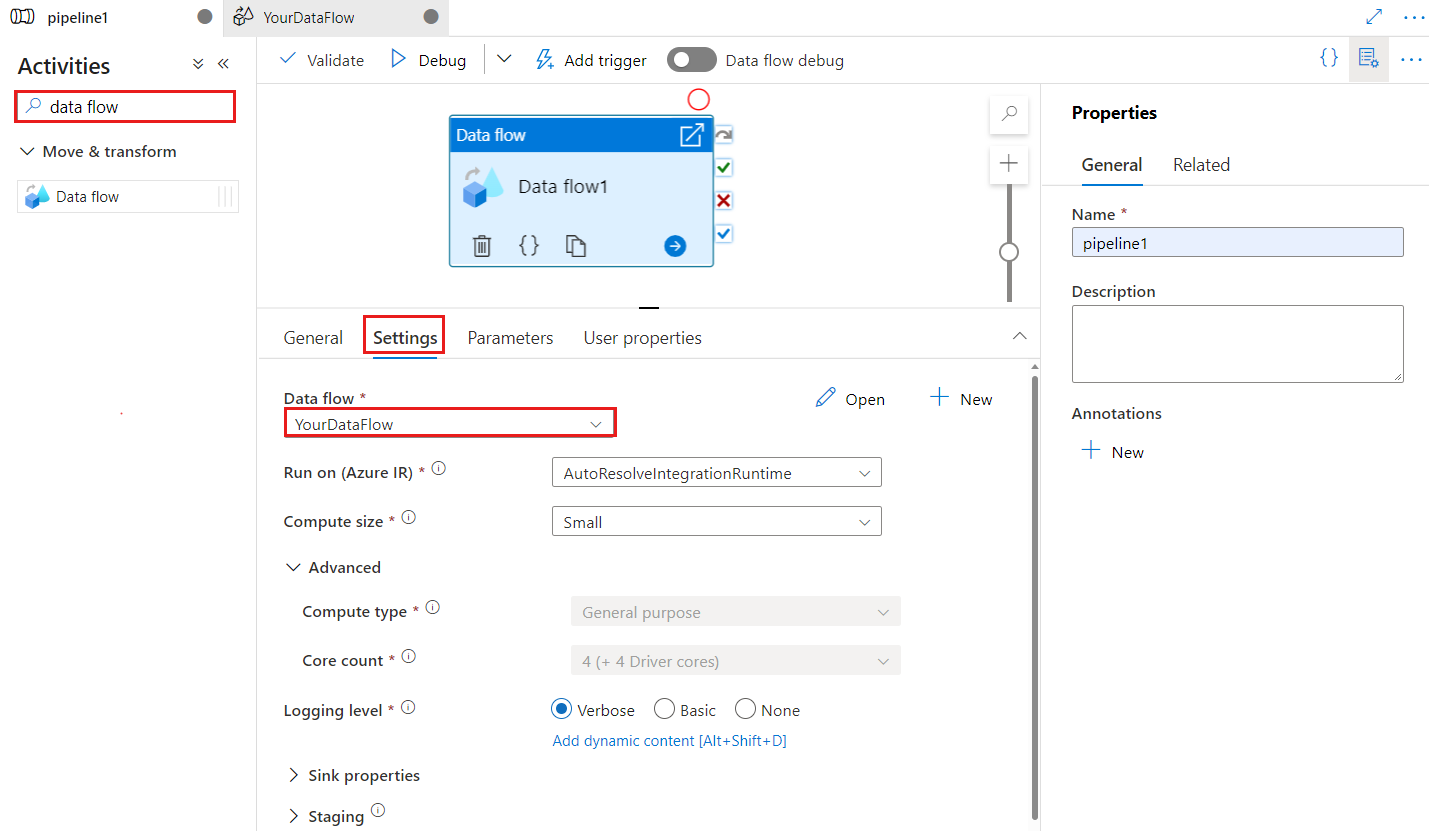
La clave de punto de control se usa para establecer el punto de control cuando la función de captura de datos modificados esté usando el flujo de datos. Esta puede sobrescribirse. Las actividades del flujo de datos usan un valor GUID como clave de punto de control, en lugar de una combinación de los nombres de la canalización y la actividad, para que esta pueda hacer un seguimiento del estado de la captura de datos modificados del cliente a pesar de cualquier acción de cambio de nombre. Toda la actividad de flujo de datos ya existente usa la clave del patrón anterior para mantener la compatibilidad con versiones anteriores. A continuación se muestra la opción "clave de punto de control" después de publicar una nueva actividad de flujo de datos que se ha obtenido a partir de un recurso de flujo de datos para el cual se ha habilitado la función de captura de datos modificados.
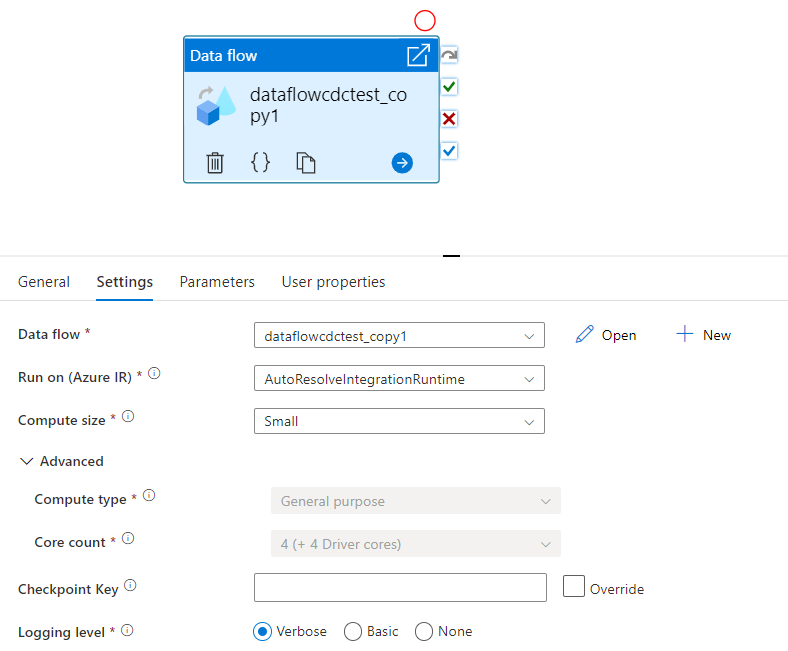
Seleccione un flujo de datos existente o cree uno nuevo con el botón Nuevo. Seleccione otras opciones según sea necesario para completar la configuración.
Sintaxis
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Propiedades de tipo
| Propiedad | Descripción | Valores permitidos | Obligatorio |
|---|---|---|---|
| dataflow | Referencia al flujo de datos que se está ejecutando. | DataFlowReference | Sí |
| integrationRuntime | Entorno de proceso en el que se ejecuta el flujo de datos. Si no se especifica, se usa la resolución automática del entorno de ejecución de integración de Azure. | IntegrationRuntimeReference | No |
| compute.coreCount | Número de núcleos utilizados en el clúster de Spark. Solo se puede especificar si se usa la resolución automática del entorno de ejecución de integración de Azure | 8, 16, 32, 48, 80, 144, 272 | No |
| compute.computeType | Tipo de proceso utilizado en el clúster de Spark. Solo se puede especificar si se usa la resolución automática del entorno de ejecución de integración de Azure | "General" | No |
| staging.linkedService | Si utiliza un origen o un receptor de Azure Synapse Analytics, especifique la cuenta de almacenamiento que se utilizará como almacenamiento provisional de PolyBase. Si Azure Storage está configurado con el punto de conexión de servicio de red virtual, tiene que utilizar la autenticación de identidad administrada con la opción para permitir el servicio de Microsoft de confianza habilitada en la cuenta de almacenamiento; consulte Efectos del uso de puntos de conexión de servicio de la red virtual con Azure Storage. Obtenga también información sobre las configuraciones necesarias para Azure Blob y Azure Data Lake Storage Gen2 respectivamente. |
LinkedServiceReference | Solo si el flujo de datos lee o escribe en una instancia de Azure Synapse Analytics. |
| staging.folderPath | Si usa un origen o un receptor de Azure Synapse Analytics, es la ruta de la carpeta de la cuenta de almacenamiento de blobs que se utiliza como almacenamiento provisional de PolyBase. | String | Solo si el flujo de datos lee o escribe en una instancia de Azure Synapse Analytics. |
| traceLevel | Establecimiento del nivel de registro de la ejecución de actividades de flujo de datos | Fino, Grueso, Ninguno | No |
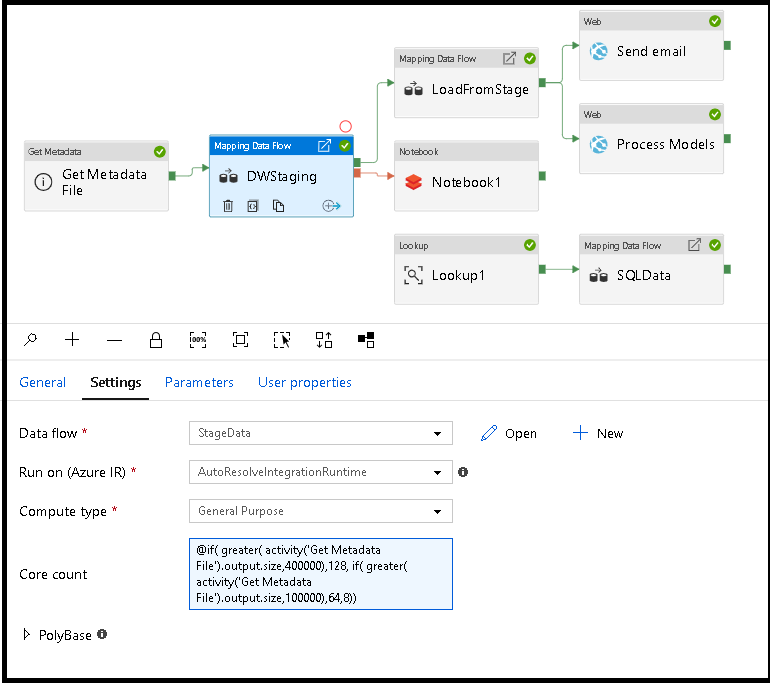
Ajuste dinámico del tamaño del proceso de flujo de datos en tiempo de ejecución
Las propiedades Recuento de núcleos y Tipo de proceso se pueden configurar dinámicamente para ajustarse al tamaño de los datos de origen entrantes en tiempo de ejecución. Use actividades de canalización como Búsqueda u Obtener metadatos para averiguar el tamaño de los datos del conjunto de datos de origen. Tras ello, use Agregar contenido dinámico en las propiedades de la actividad del flujo de datos. Puede elegir entre procesos de tamaño pequeño, mediano o grande. Opcionalmente, elija "Personalizado" y configure manualmente los tipos de proceso y el número de núcleos.
Este es un breve tutorial en formato de vídeo en el que se explica esta técnica
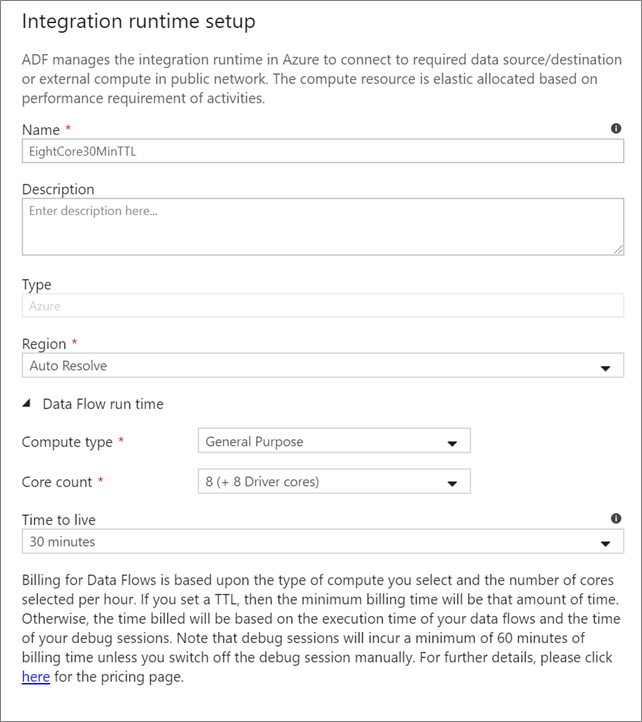
Entorno de ejecución de integración de Data Flow
Seleccione el entorno de ejecución de integración que desee usar con la ejecución de la actividad de Data Flow. De manera predeterminada, el servicio usa la resolución automática del entorno de ejecución de integración de Azure con cuatro núcleos de trabajo. Este IR tiene un tipo de proceso de uso general y se ejecuta en la misma región que la instancia de servicio. En el caso de las canalizaciones operativas, se recomienda encarecidamente crear sus propias instancias de Azure Integration Runtime que definan regiones específicas, el tipo de proceso, los recuentos de núcleos y el TTL para la ejecución de actividades del flujo de datos.
Un tipo de proceso mínimo de uso general con una configuración de 8+8 (16 núcleos virtuales en total) y de 10 minutos de TTL es la recomendación mínima para la mayoría de las cargas de trabajo de producción. Al establecer un valor de TTL pequeño, Azure IR puede mantener un clúster semiactivo que no empleará los minutos de tiempo de inicio que un clúster en frío necesita. Para más información, consulte Azure Integration Runtime.
Importante
La selección del entorno de ejecución de integración en la actividad de Data Flow solo se aplica a las ejecuciones activadas de su canalización. La canalización con flujos de datos se depurará en el clúster que se haya especificado en la sesión de depuración.
PolyBase
Si utiliza Azure Synapse Analytics como origen o receptor, debe elegir una ubicación de almacenamiento provisional para la carga por lotes de PolyBase. PolyBase utiliza la carga por lotes en lugar de cargar los datos fila a fila. PolyBase reduce considerablemente el tiempo de carga en Azure Synapse Analytics.
Clave de punto de control
Si se usa la opción de captura de cambios para orígenes de flujo de datos, ADF mantiene y administra el punto de control automáticamente. La clave de punto de control predeterminada es un hash de los nombres del flujo de datos y la canalización. Si usa un patrón dinámico para las tablas o carpetas de origen, puede invalidar este hash y establecer aquí su propio valor de clave de punto de control.
Nivel de registro
Si no es necesario que cada ejecución de canalización de las actividades de flujo de datos anote completamente todos los registros de telemetría detallados, tiene la opción de establecer el nivel de registro en "Básico" o "Ninguno". Al ejecutar los flujos de datos en modo "detallado" (valor predeterminado), está solicitando al servicio que registre la actividad por completo en cada nivel de partición individual durante la transformación de los datos. Esta puede ser una operación costosa; por tanto, habilitar solo el modo detallado al solucionar problemas puede mejorar el flujo de datos y el rendimiento de la canalización en general. El modo "Básico" solo registra las duraciones de las transformaciones, mientras que "Ninguno" solo proporciona un resumen de las duraciones.

Propiedades del receptor
La característica de agrupación de los flujos de datos permite establecer el orden de ejecución de los receptores y agruparlos con el mismo número de grupo. Para facilitar la administración de los grupos, puede pedir al servicio que ejecute los receptores, en el mismo grupo, en paralelo. También puede establecer que el grupo de receptores continúe incluso después de que uno de los receptores encuentre un error.
El comportamiento predeterminado de los receptores de flujo de datos es ejecutar cada receptor de forma secuencial, en serie, y producir un error en el flujo de datos cuando se encuentra un error en el receptor. Además, todos los receptores se establecen de forma predeterminada en el mismo grupo, a menos que vaya a las propiedades del flujo de datos y establezca otras prioridades para los receptores.

Solo la primera fila
Esta opción solo está disponible para los flujos de datos que tienen los receptores de caché habilitados para la "salida a la actividad". La salida del flujo de datos que se inserta directamente en la canalización está limitada a 2 MB. Establecer "solo la primera fila" le ayuda a limitar la salida de datos del flujo de datos al insertar la salida de la actividad de flujo de datos directamente en la canalización.
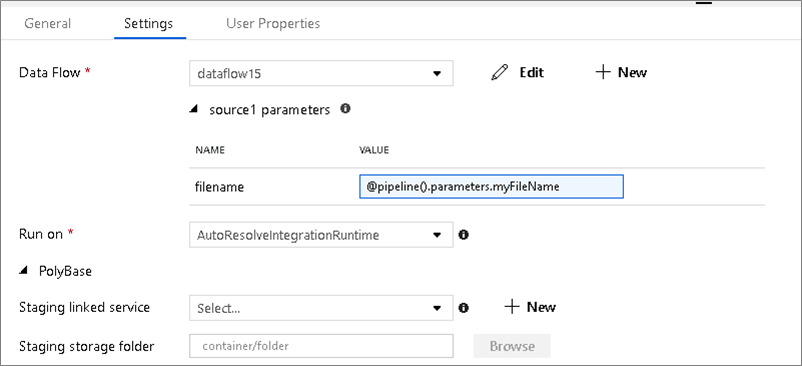
Flujos de datos con parámetros
Conjuntos de datos con parámetros
Si el flujo de datos utiliza conjuntos de datos con parámetros, establezca los valores de los parámetros en la pestaña Configuración.
Flujos de datos con parámetros
Si el flujo de datos tiene parámetros, establezca los valores dinámicos de los parámetros de flujo de datos en la pestaña Parámetros. Puede usar el lenguaje de expresiones de canalización o el lenguaje de expresiones de flujo de datos para asignar valores de parámetros dinámicos o literales. Para más información, consulte Parámetros de Data Flow.
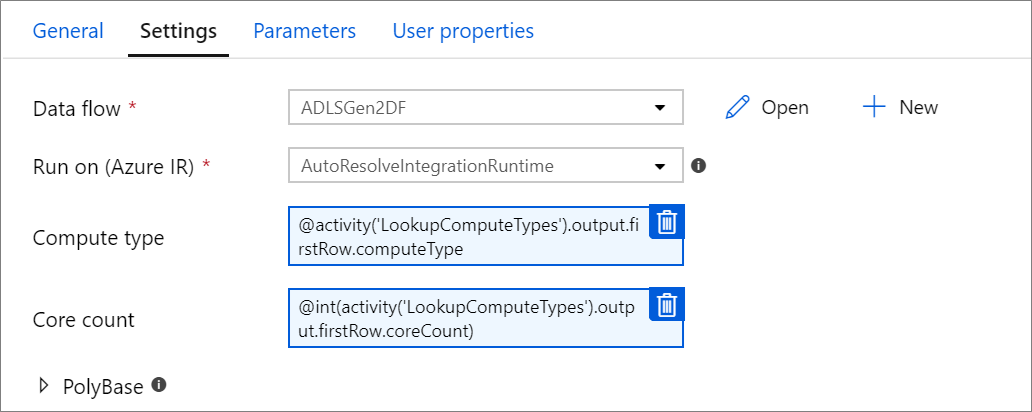
Propiedades de proceso con parámetros.
Puede parametrizar el número de núcleos o el tipo de proceso si usa la resolución automática del entorno de ejecución de integración de Azure y especifica valores para compute.coreCount y compute.computeType.
Depuración de la canalización de actividades de Data Flow
Para ejecutar una canalización de depuración con una actividad de Data Flow, debe activar el modo de depuración del flujo de datos a través del control deslizante Data Flow Debug (Depuración de flujo de datos) en la barra superior. El modo de depuración permite ejecutar el flujo de datos en un clúster de Spark activo. Para más información, consulte Modo de depuración.

La canalización de depuración se ejecuta en el clúster de depuración activo, no en el entorno de ejecución de integración especificado en la configuración de la actividad de Data Flow. Puede elegir el entorno de proceso de depuración al iniciar el modo de depuración.
Supervisión de la actividad de Data Flow
La supervisión de la actividad de Data Flow se realiza de forma especial, ya que permite ver información sobre las particiones, el tiempo de cada fase y el linaje de datos. Abra el panel supervisión utilizando el icono con forma de gafas que encontrará en Acciones. Para más información, consulte Supervisión de flujos de datos.
Uso de los resultados de actividad de Data Flow en una actividad posterior
La actividad de flujo de datos genera métricas con respecto al número de filas escritas en cada receptor y las filas leídas de cada origen. Estos resultados se devuelven en la sección output del resultado de ejecución de la actividad. Las métricas devueltas están en el formato del siguiente código JSON.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Por ejemplo, para obtener el número de filas escritas en un receptor denominado "sink1" en una actividad denominada "dataflowActivity", use @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Para obtener el número de filas leídas de un origen denominado "source1" que se usó en ese receptor, use @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Nota
Si un receptor tiene cero filas escritas, no se mostrará en las métricas. Se puede comprobar la existencia con la función contains. Por ejemplo, contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') comprueba si se escribieron filas en sink1.
Contenido relacionado
Vea actividades de flujo de control admitidas:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de