Copia y transformación de datos en Azure Blob Storage mediante Azure Data Factory o Azure Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se resume el uso de la actividad de copia en canalizaciones de Azure Data Factory y Azure Synapse para copiar datos con Azure Blob Storage como origen y destino. También se describe cómo usar la actividad de Data Flow para transformar datos en Azure Blob Storage. Para obtener más información, lea los artículos de introducción a Azure Data Factory y Azure Synapse Analytics.
Sugerencia
Para obtener información sobre un escenario de migración de un lago de datos o un almacenamiento de datos, vea el artículo Migración de datos desde el lago de datos o el almacenamiento de datos a Azure.
Funcionalidades admitidas
Este conector de Azure Blob Storage es compatible con las siguientes capacidades:
| Funcionalidades admitidas | IR | Puntos de conexión privados administrados de Synapse (versión preliminar) |
|---|---|---|
| Actividad de copia (origen/receptor) | ① ② | ✓ Exclusión de cuenta de almacenamiento V1 |
| Flujo de datos de asignación (origen/receptor) | ① | ✓ Exclusión de cuenta de almacenamiento V1 |
| Actividad de búsqueda | ① ② | ✓ Exclusión de cuenta de almacenamiento V1 |
| Actividad GetMetadata | ① ② | ✓ Exclusión de cuenta de almacenamiento V1 |
| Actividad de eliminación | ① ② | ✓ Exclusión de cuenta de almacenamiento V1 |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
En el caso de la actividad de copia, este conector de Blob Storage admite:
- Copia de blobs con cuentas de Azure Storage de uso general y almacenamiento de blobs en frío y en caliente como orígenes y destinos.
- Copia de blobs mediante el uso de una clave de cuenta, una firma de acceso compartido de servicio (SAS), una entidad de servicio o identidades administradas paras las autenticaciones de recurso de Azure.
- Copia de blobs desde blobs en bloques, blobs con anexos o blobs en páginas y copia de datos solo a blobs en bloques.
- Copia de blobs tal cual, o análisis o generación de los mismos con códecs de compresión y formatos de archivo compatibles.
- Conservación de los metadatos de archivo durante la copia.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado de Azure Blob Storage mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado de Azure Blob Storage en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar de su área de trabajo de Azure Data Factory o Synapse, y seleccione Servicios vinculados; a continuación, seleccione Nuevo:
Busque "blob" y seleccione el conector Azure Blob Storage.
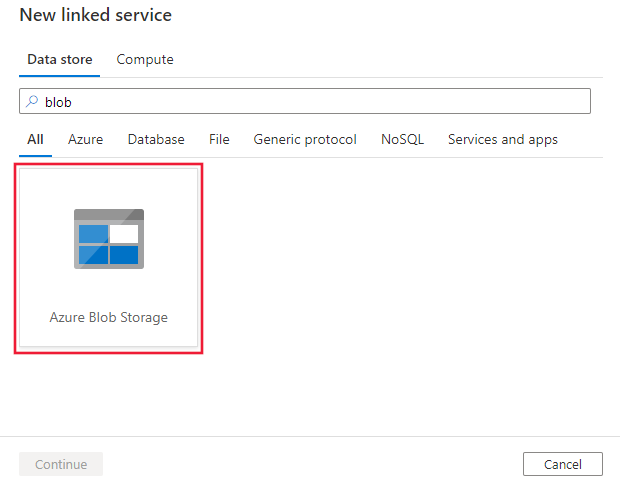
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
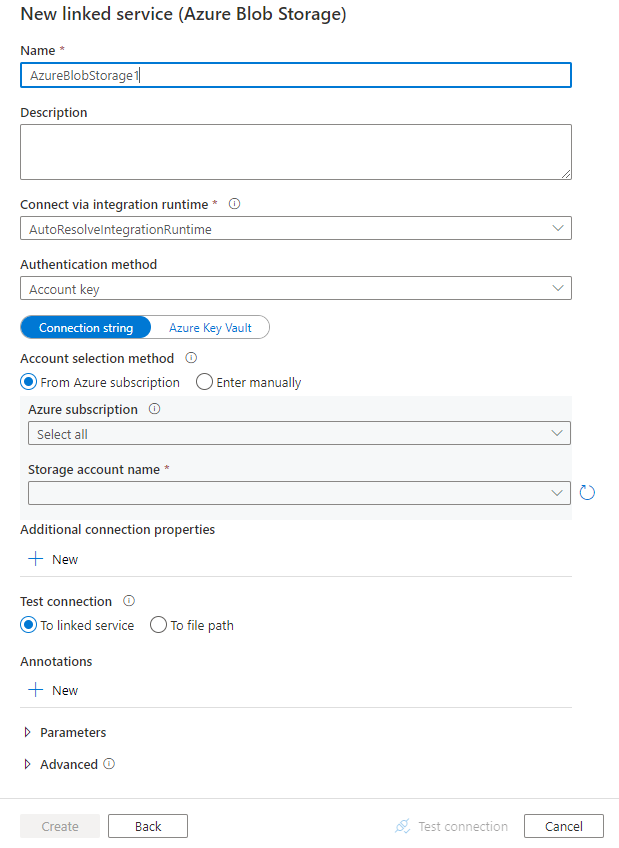
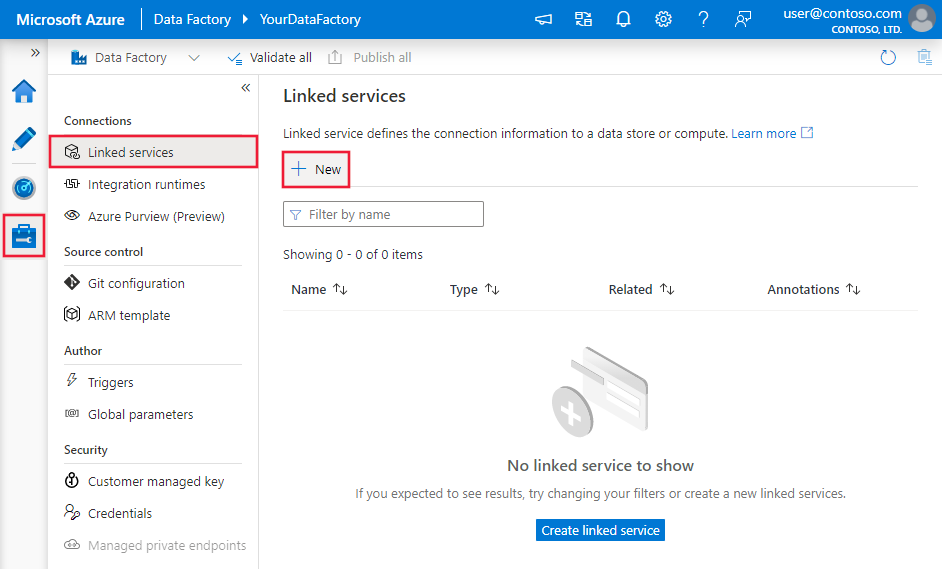
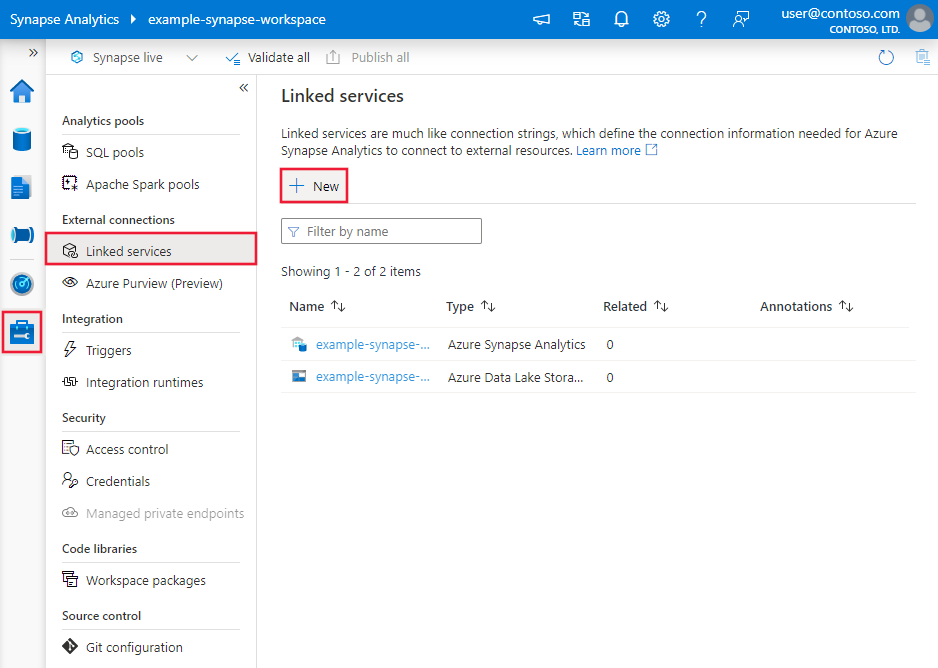
Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades de canalización de Data Factory y Synapse específicas de Blob Storage.
Propiedades del servicio vinculado
El conector de Blob Storage admite los siguientes tipos de autenticación. Consulte las secciones correspondientes para más información.
- Autenticación anónima
- Autenticación de clave de cuenta
- Autenticación con firma de acceso compartido
- Autenticación de entidad de servicio
- Autenticación de identidad administrada asignada por el sistema
- Autenticación de identidad administrada asignada por el usuario
Nota
- Si desea utilizar el entorno de ejecución de integración de Azure público para conectarse a su instancia de Blob Storage con la opción Permitir que los servicios de Microsoft de confianza accedan a esta cuenta de almacenamiento habilitada en el firewall de Azure Storage, debe usar la autenticación de identidad administrada. Para más información sobre la configuración de los firewalls de Azure Storage, consulte Configuración de redes virtuales y firewalls de Azure Storage.
- Cuando use PolyBase o la instrucción COPY para cargar datos en Azure Synapse Analytics, si la instancia de origen o almacenamiento provisional de Blob Storage está configurada con un punto de conexión de Azure Virtual Network, tendrá que usar la autenticación de identidad administrada como es necesario en Azure Synapse. Consulte la sección sobre autenticación de identidad administrada para conocer más requisitos previos de configuración.
Nota
Las actividades de Azure HDInsight y Azure Machine Learning solo admiten la autenticación que usa las claves de cuenta de Azure Blob Storage.
Autenticación anónima
Las siguientes propiedades se admiten para la autenticación de clave de cuenta de almacenamiento en canalizaciones de Azure Data Factory o Synapse:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureBlobStorage (recomendable) o AzureStorage (consulte las siguientes notas). |
Sí |
| containerUri | Especifique el URI del contenedor de blobs de Azure que ha habilitado el acceso de lectura anónimo utilizando este formato https://<AccountName>.blob.core.windows.net/<ContainerName> y Configuración del acceso de lectura público anónimo para contenedores y blobs |
Sí |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos está en una red privada). Si no se especifica esta propiedad, el servicio usa el valor predeterminado de Azure Integration Runtime. | No |
Ejemplo:
{
"name": "AzureBlobStorageAnonymous",
"properties": {
"annotations": [],
"type": "AzureBlobStorage",
"typeProperties": {
"containerUri": "https:// <accountname>.blob.core.windows.net/ <containername>",
"authenticationType": "Anonymous"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplos de la interfaz de usuario:
La experiencia de la interfaz de usuario es como se describe en la imagen siguiente. Esta muestra usa el conjunto de datos abiertos de Azure como origen. Si quiere obtener el conjunto de datos bing_covid-19_data.csv abierto, solo tiene que establecer Tipo de autenticación en Anónimo y el URI del contenedor en https://pandemicdatalake.blob.core.windows.net/public.
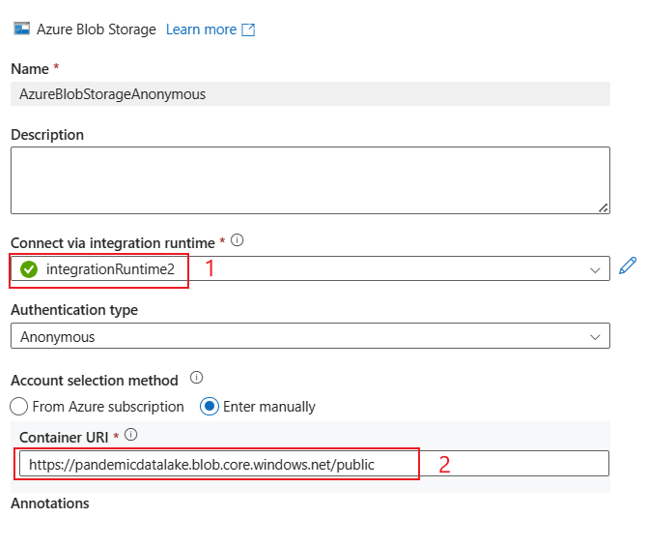
Autenticación de clave de cuenta
Las siguientes propiedades se admiten para la autenticación de clave de cuenta de almacenamiento en canalizaciones de Azure Data Factory o Synapse:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureBlobStorage (recomendable) o AzureStorage (consulte las siguientes notas). |
Sí |
| connectionString | Especifique la información necesaria para conectarse a Storage para la propiedad connectionString. También puede colocar la clave de cuenta en Azure Key Vault y extraer la configuración accountKey de la cadena de conexión. Para obtener más información, consulte los siguientes ejemplos y el artículo Almacenamiento de credenciales en Azure Key Vault. |
Sí |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos está en una red privada). Si no se especifica esta propiedad, el servicio usa el valor predeterminado de Azure Integration Runtime. | No |
Nota:
No se admite un punto de conexión de servicio secundario de Blob service secundario cuando se usa la autenticación de clave de cuenta. Puede usar otros tipos de autenticación.
Nota
Si está usando el tipo de servicio vinculado AzureStorage, todavía se admite tal cual. Pero se recomienda usar el nuevo tipo de servicio vinculado AzureBlobStorage en el futuro.
Ejemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo: Almacenamiento de la clave de cuenta en Azure Key Vault
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación con firma de acceso compartido
Una firma de acceso compartido ofrece acceso delegado a recursos en la cuenta de almacenamiento. Puede utilizar una firma de acceso compartido para conceder a un cliente permisos limitados a los objetos de su cuenta de almacenamiento durante un periodo de tiempo especificado.
No tiene que compartir las claves de acceso de su cuenta. La firma de acceso compartido es un URI que incluye en sus parámetros de consulta toda la información necesaria para el acceso autenticado a un recurso de almacenamiento. Para obtener acceso a los recursos de almacenamiento con la firma de acceso compartido, el cliente solo tiene que pasar la firma de acceso compartido al método o constructor adecuados.
Para obtener más información sobre las firmas de acceso compartido, consulte Uso de firmas de acceso compartido (SAS): Comprender el modelo de firma de acceso compartido.
Nota
- Ahora el servicio admite firmas de acceso compartido de servicio y firmas de acceso compartido de cuenta. Para obtener más información sobre las firmas de acceso compartido, consulte Otorgar acceso limitado a recursos de Azure Storage con firmas de acceso compartido.
- En la configuración posterior del conjunto de datos, la ruta de la carpeta es la ruta absoluta a partir del nivel del contenedor. Deberá configurar una alineada con la ruta de acceso del URI de SAS.
Para usar la autenticación con firma de acceso compartido, se admiten las propiedades siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureBlobStorage (recomendable) o AzureStorage (consulte la siguiente nota). |
Sí |
| sasUri | Especifique el URI de firma de acceso compartido a los recursos de Storage como blob o contenedor. Marque este campo como SecureString para almacenarlo de forma segura. También puede colocar el token de SAS en Azure Key Vault para usar la rotación automática y quitar la parte del token. Para obtener más información, consulte los siguientes ejemplos y el Almacenamiento de credenciales en Azure Key Vault. |
Sí |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos está en una red privada). Si no se especifica esta propiedad, el servicio usa el valor predeterminado de Azure Integration Runtime. | No |
Nota
Si está usando el tipo de servicio vinculado AzureStorage, todavía se admite tal cual. Pero se recomienda usar el nuevo tipo de servicio vinculado AzureBlobStorage en el futuro.
Ejemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo: Almacenamiento de la clave de cuenta en Azure Key Vault
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Cuando cree un URI de firma de acceso compartido, tenga en cuenta lo siguiente:
- Establezca los permisos de lectura y escritura adecuados en los objetos, en función de cómo se use el servicio vinculado (lectura, escritura, lectura y escritura).
- Establezca la hora de expiración adecuadamente. Asegúrese de que el acceso a los objetos de Storage no expirará durante el período activo de la canalización.
- El URI debe crearse en el nivel correcto del contenedor o blob, en función de lo que se necesite. Un URI de firma de acceso compartido a un blob permite a la canalización de factoría de datos o Synapse acceder a ese blob concreto. Un URI de firma de acceso compartido a un contenedor de Blob Storage permite a la canalización de factoría de datos o Synapse iterar por los blobs de ese contenedor. Para proporcionar acceso a más o menos objetos más adelante, o actualizar el URI de firma de acceso compartida, no olvide actualizar el servicio vinculado con el nuevo URI.
Autenticación de entidad de servicio
Para obtener información general sobre la autenticación con entidad de servicio de Azure Storage, consulte Autenticación del acceso a Azure Storage con Microsoft Entra ID.
Antes de usar la autenticación de entidad de servicio, siga estos pasos:
Registro de una aplicación en la Plataforma de identidad de Microsoft. Para aprender cómo, consulte Inicio rápido: Registrar una aplicación con la plataforma de identidad de Microsoft. Anote estos valores; los usará para definir el servicio vinculado:
- Identificador de aplicación
- Clave de la aplicación
- Id. de inquilino
Conceda a la entidad de servicio el permiso adecuado en Azure Blob Storage. Para obtener más información sobre los roles, consulte Uso de Azure Portal para asignar un rol de Azure para el acceso a datos de blobs y colas.
- Como origen, en Control de acceso (IAM) , conceda al menos el rol Lector de datos de Storage Blob.
- Como receptor, en el control de acceso (IAM) , conceda al menos el rol Colaborador de datos de Storage Blob.
Estas propiedades son compatibles con un servicio vinculado de Azure Blob Storage:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureBlobStorage. | Sí |
| serviceEndpoint | Especifique el punto de conexión de servicio de Azure Blob Storage con el patrón https://<accountName>.blob.core.windows.net/. |
Sí |
| accountKind | Especifique el tipo de la cuenta de almacenamiento. Los valores permitidos son: Storage (v1 de uso general), StorageV2 (v2 de uso general), BlobStorage o BlockBlobStorage. Cuando se usa el servicio vinculado de blob de Azure en el flujo de datos, la autenticación de identidad administrada o de entidad de servicio no se admite cuando el tipo de cuenta está definido como vacío o "almacenamiento". Especifique el tipo de cuenta adecuado, elija una autenticación diferente o actualice la cuenta de almacenamiento a uso general v2. |
No |
| servicePrincipalId | Especifique el id. de cliente de la aplicación. | Sí |
| servicePrincipalCredentialType | Tipo de credencial que se usará para la autenticación de entidades de servicio. Los valores válidos son ServicePrincipalKey y ServicePrincipalCert. | Sí |
| servicePrincipalCredential | Credencial de entidad de servicio. Al usar ServicePrincipalKey como tipo de credenciales, especifique la clave de la aplicación. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. Cuando use ServicePrincipalCert como credencial, haga referencia a un certificado en Azure Key Vault y asegúrese de que el tipo de contenido del certificado sea PKCS #12. |
Sí |
| tenant | Especifique la información del inquilino (nombre de dominio o identificador de inquilino) en el que reside la aplicación. Para recuperarlo, mantenga el mouse en la esquina superior derecha de Azure Portal. | Sí |
| azureCloudType | Para la autenticación de la entidad de servicio, especifique el tipo de entorno de nube de Azure en el que está registrada la aplicación de Microsoft Entra. Los valores permitidos son AzurePublic, AzureChina, AzureUsGovernment y AzureGermany. De forma predeterminada, se usa el entorno en la nube de la canalización de Data Factory o Synapse. |
No |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos está en una red privada). Si no se especifica esta propiedad, el servicio usa el valor predeterminado de Azure Integration Runtime. | No |
Nota:
- Si la cuenta de blob habilita la eliminación temporal, la autenticación de la entidad de servicio no se admite en Data Flow.
- Si tiene acceso al almacenamiento de blobs a través de un punto de conexión privado mediante el flujo de datos, tenga en cuenta cuando se usa la autenticación de entidad de servicio el flujo de datos se conecta al punto de conexión ADLS Gen2 en lugar de a un punto de conexión Blob. Asegúrese de crear el punto de conexión privado correspondiente en la factoría de datos o el área de trabajo de Synapse para habilitar el acceso.
Nota
Solo el servicio vinculado tipo "AzureBlobStorage" admite la autenticación con la entidad de servicio, mientras que el servicio vinculado tipo "AzureStorage" anterior no la admite.
Ejemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación de identidad administrada asignada por el sistema
Una factoría de datos o una canalización de Synapse se pueden asociar a una identidad administrada asignada por el sistema para recursos de Azure, que representa ese recurso para la autenticación en otros servicios de Azure. Puede usar directamente esta identidad administrada asignada por el sistema para la autenticación de Blob Storage, que es similar a como se usa una entidad de servicio propia. Permite que este recurso designado acceda y copie los datos con Blob Storage como origen y destino. Para obtener más información sobre las identidades administradas para los recursos de Azure, vea Identidades administradas para recursos de Azure.
Para obtener información general sobre la autenticación de Azure Storage, vea Autenticación del acceso a Azure Storage con Microsoft Entra ID. Para usar identidades administradas para la autenticación de recursos de Azure, siga estos pasos:
Recupere la información de identidad administrada asignada por el sistema; para ello, copie el valor del identificador de objeto de identidad administrada asignada por el sistema generado junto con la factoría o el área de trabajo de Synapse.
Conceda permiso a la identidad administrada en Azure Blob Storage. Para obtener más información sobre los roles, consulte Uso de Azure Portal para asignar un rol de Azure para el acceso a datos de blobs y colas.
- Como origen, en Control de acceso (IAM) , conceda al menos el rol Lector de datos de Storage Blob.
- Como receptor, en el control de acceso (IAM) , conceda al menos el rol Colaborador de datos de Storage Blob.
Estas propiedades son compatibles con un servicio vinculado de Azure Blob Storage:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureBlobStorage. | Sí |
| serviceEndpoint | Especifique el punto de conexión de servicio de Azure Blob Storage con el patrón https://<accountName>.blob.core.windows.net/. |
Sí |
| accountKind | Especifique el tipo de la cuenta de almacenamiento. Los valores permitidos son: Storage (v1 de uso general), StorageV2 (v2 de uso general), BlobStorage o BlockBlobStorage. Cuando se usa el servicio vinculado de blob de Azure en el flujo de datos, la autenticación de identidad administrada o de entidad de servicio no se admite cuando el tipo de cuenta está definido como vacío o "almacenamiento". Especifique el tipo de cuenta adecuado, elija una autenticación diferente o actualice la cuenta de almacenamiento a uso general v2. |
No |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos está en una red privada). Si no se especifica esta propiedad, el servicio usa el valor predeterminado de Azure Integration Runtime. | No |
Ejemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación de identidad administrada asignada por el usuario
Una factoría de datos se puede asignar con una o varias identidades administradas asignadas por el usuario. Puede usar esta identidad administrada asignada por el usuario para la autenticación de Blob Storage, lo que permite acceder y copiar datos desde o hacia Blob Storage. Para obtener más información sobre las identidades administradas para los recursos de Azure, vea Identidades administradas para recursos de Azure.
Para obtener información general sobre la autenticación de Azure Storage, vea Autenticación del acceso a Azure Storage con Microsoft Entra ID. Para usar la autenticación de identidad administrada asignada por el usuario, siga estos pasos:
Cree una o varias identidades administradas asignadas por el usuario y conceda permiso en Azure Blob Storage. Para obtener más información sobre los roles, consulte Uso de Azure Portal para asignar un rol de Azure para el acceso a datos de blobs y colas.
- Como origen, en Control de acceso (IAM) , conceda al menos el rol Lector de datos de Storage Blob.
- Como receptor, en el Control de acceso (IAM) , conceda al menos el rol Colaborador de datos de blobs de almacenamiento.
Asigne una o varias identidades administradas asignadas por el usuario a la factoría de datos y cree credenciales para cada identidad administrada asignada por el usuario.
Estas propiedades son compatibles con un servicio vinculado de Azure Blob Storage:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureBlobStorage. | Sí |
| serviceEndpoint | Especifique el punto de conexión de servicio de Azure Blob Storage con el patrón https://<accountName>.blob.core.windows.net/. |
Sí |
| accountKind | Especifique el tipo de la cuenta de almacenamiento. Los valores permitidos son: Storage (v1 de uso general), StorageV2 (v2 de uso general), BlobStorage o BlockBlobStorage. Cuando se usa el servicio vinculado de blob de Azure en el flujo de datos, la autenticación de identidad administrada o de entidad de servicio no se admite cuando el tipo de cuenta está definido como vacío o "almacenamiento". Especifique el tipo de cuenta adecuado, elija una autenticación diferente o actualice la cuenta de almacenamiento a uso general v2. |
No |
| credentials | Especifique la identidad administrada asignada por el usuario como objeto de credencial. | Sí |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos está en una red privada). Si no se especifica esta propiedad, el servicio usa el valor predeterminado de Azure Integration Runtime. | No |
Ejemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Importante
Si usa PolyBase o una instrucción COPY para cargar datos desde Blob Storage (como origen o como almacenamiento provisional) en Azure Synapse Analytics, cuando use la autenticación de identidad administrada para Blob Storage, asegúrese de seguir los pasos 1 a 3 de esta guía. En estos pasos se registrará el servidor con Microsoft Entra ID y se asignará el rol Colaborador de datos de Storage Blob en el servidor. Data Factory controla el resto. Si configura Blob Storage con un punto de conexión de Azure Virtual Network, también debe tener la opción Permitir que los servicios de Microsoft de confianza accedan a esta cuenta de almacenamiento activada en el menú de configuración Firewalls y redes virtuales de la cuenta de Azure Storage, como es necesario en Azure Synapse.
Nota:
- Si la cuenta de blob habilita la eliminación temporal, la autenticación de la identidad administrada asignada por el sistema o el usuario no se admite en Data Flow.
- Si accede al almacenamiento de blobs por medio de un punto de conexión privado mediante Data Flow, tenga en cuenta que cuando se usa la autenticación de identidad administrada asignada por el sistema o el usuario, Data Flow se conecta al punto de conexión de ADLS Gen2 en lugar de un punto de conexión de blob. Asegúrese de crear el punto de conexión privado correspondiente en ADF para habilitar el acceso.
Nota
Solo el servicio vinculado del tipo "AzureBlobStorage" admite la autenticación de identidad administrada asignada por el sistema o el usuario, pero el servicio vinculado del tipo "AzureStorage" anterior no las admite.
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos.
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
- Formato Avro
- Formato binario
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Las propiedades siguientes se admiten para Azure Blob Storage en la configuración location de un conjunto de datos basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de la ubicación del conjunto de datos se debe establecer en AzureBlobStorageLocation. | Sí |
| contenedor | Contenedor de blobs. | Sí |
| folderPath | Ruta de acceso a la carpeta bajo el contenedor especificado. Si quiere usar un carácter comodín para filtrar la carpeta, omita este valor y especifíquelo en la configuración del origen de actividad. | No |
| fileName | Nombre de archivo en el contenedor y ruta de carpeta indicados. Si quiere usar el carácter comodín para filtrar los archivos, omita este valor y especifíquelo en la configuración del origen de actividad. | No |
Ejemplo:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que admite el origen y receptor de Blob Storage.
Blob Storage como un tipo de origen
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
- Formato Avro
- Formato binario
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Las propiedades siguientes se admiten para Azure Blob Storage en la configuración storeSettings en un origen de copia basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de storeSettings se debe establecer en AzureBlobStorageReadSettings. |
Sí |
| Buscar los archivos que se van a copiar: | ||
| OPCIÓN 1: ruta de acceso estática |
Copia de la ruta de acceso de carpeta/archivo o de contenedor especificada en el conjunto de datos. Si quiere copiar todos los blobs de un contenedor o una carpeta, especifique también wildcardFileName como *. |
|
| OPCIÓN 2: prefijo de blob - prefix |
Prefijo para el nombre de blob en el contenedor dado configurado en un conjunto de datos para filtrar los blobs de origen. Se seleccionan los blobs cuyo nombre comienza con container_in_dataset/this_prefix. Usa el filtro del lado de servicio para Blob Storage, que proporciona un mejor rendimiento que un filtro de caracteres comodín.Cuando se usa el prefijo y se elige copiar a un receptor basado en archivos conservando la jerarquía, hay que tener en cuenta que se conserva la sub-ruta después de la última "/" del prefijo. Por ejemplo, si tiene el archivo container/folder/subfolder/file.txt de origen y configura el prefijo como folder/sub, la ruta del archivo que se conserva es subfolder/file.txt. |
No |
| OPCIÓN 3: carácter comodín - wildcardFolderPath |
Ruta de acceso de carpeta con caracteres comodín en el contenedor especificado configurado en un conjunto de datos para filtrar las carpetas de origen. Los caracteres comodín permitidos son: * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter). Use ^ como escape si el nombre de la carpeta contiene un carácter comodín o este carácter de escape. Ver más ejemplos en Ejemplos de filtros de carpetas y archivos. |
No |
| OPCIÓN 3: carácter comodín - wildcardFileName |
Nombre de archivo con caracteres comodín en el contenedor y la ruta de carpeta (o ruta de carpeta con carácter comodín) indicada para filtrar los archivos de origen. Los caracteres comodín permitidos son: * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter). Use ^ como escape si el nombre de archivo contiene un carácter comodín o este carácter de escape. Ver más ejemplos en Ejemplos de filtros de carpetas y archivos. |
Sí |
| OPCIÓN 4: una lista de archivos - fileListPath |
Indica que se copie un conjunto de archivos determinado. Apunte a un archivo de texto que incluya una lista de los archivos que quiere copiar, con un archivo por línea, que sea la ruta de acceso relativa a la ruta de acceso configurada en el conjunto de datos. Cuando use esta opción, no especifique un nombre de archivo en el conjunto de datos. Ver más ejemplos en Ejemplos de lista de archivos. |
No |
| Configuración adicional: | ||
| recursive | Indica si los datos se leen de forma recursiva de las subcarpetas o solo de la carpeta especificada. Tenga en cuenta que cuando recursive se establece en true y el receptor es un almacén basado en archivos, no se crea una carpeta o una subcarpeta vacía en el receptor. Los valores permitidos son: True (valor predeterminado) y False. Esta propiedad no se aplica al configurar fileListPath. |
No |
| deleteFilesAfterCompletion | Indica si los archivos binarios se eliminarán del almacén de origen después de moverse correctamente al almacén de destino. La eliminación de archivos es por archivo. Por lo tanto, cuando falle la actividad de copia, podrá ver que algunos archivos ya se han copiado en el destino y se han eliminado del origen, mientras que otros aún permanecen en el almacén de origen. Esta propiedad solo es válida en el escenario de copia de archivos binarios. El valor predeterminado es false. |
No |
| modifiedDatetimeStart | Los archivos se filtran en función del atributo Last Modified. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart y menor que modifiedDatetimeEnd. La hora se aplica a una zona horaria UTC en el formato "2018-12-01T05:00:00Z". Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene un valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene un valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea menor que el valor de fecha y hora.Esta propiedad no se aplica al configurar fileListPath. |
No |
| modifiedDatetimeEnd | Igual que la propiedad anterior. | No |
| enablePartitionDiscovery | Para archivos con particiones, especifique si desea analizar las particiones de la ruta del archivo y agregarlas como columnas de origen adicionales. Los valores permitidos son false (valor predeterminado) y true. |
No |
| partitionRootPath | Cuando esté habilitada la detección de particiones, especifique la ruta de acceso raíz absoluta para poder leer las carpetas con particiones como columnas de datos. Si no se especifica, de manera predeterminada, - Cuando se usa la ruta de acceso de archivo en un conjunto de datos o una lista de archivos del origen, la ruta de acceso raíz de la partición es la ruta de acceso configurada en el conjunto de datos. - Cuando se usa el filtro de carpeta con caracteres comodín, la ruta de acceso raíz de la partición es la subruta antes del primer carácter comodín. - Cuando se usa un prefijo, la ruta de acceso raíz de la partición es la subruta antes del último "/". Por ejemplo, supongamos que configura la ruta de acceso en el conjunto de datos como "root/folder/year=2020/month=08/day=27": - Si especifica la ruta de acceso raíz de la partición como "root/folder/year=2020", la actividad de copia generará dos columnas más, month y day, con el valor "08" y "27", respectivamente, además de las columnas de los archivos.- Si no se especifica la ruta raíz de la partición, no se generará ninguna columna adicional. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Nota
Para el formato de texto delimitado o Parquet, aún se admite el tipo BlobSource del origen de copia de seguridad mencionado en la sección siguiente para la compatibilidad con versiones anteriores. Se recomienda usar el nuevo modelo hasta que la interfaz de usuario de creación haya comenzado a generar estos nuevos tipos.
Ejemplo:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Nota
El contenedor $logs, que se crea de forma automática cuando Storage Analytics está habilitado para una cuenta de almacenamiento, no se muestra cuando se realiza una operación de enumeración de contenedores desde la interfaz de usuario. La ruta del archivo se debe proporcionar directamente para que la factoría de datos o la canalización de Synapse consuma archivos del contenedor $logs.
Blob Storage como un tipo de receptor
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
Las propiedades siguientes se admiten para Azure Blob Storage en la configuración storeSettings en un receptor de copia basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de la sección storeSettings se debe establecer en AzureBlobStorageWriteSettings. |
Sí |
| copyBehavior | Define el comportamiento de copia cuando el origen son archivos de un almacén de datos basados en archivos. Los valores permitidos son: - PreserveHierarchy (valor predeterminado): conserva la jerarquía de archivos en la carpeta de destino. La ruta de acceso relativa del archivo de origen a la carpeta de origen es idéntica que la ruta de acceso relativa del archivo de destino a la carpeta de destino. - FlattenHierarchy: todos los archivos de la carpeta de origen están en el primer nivel de la carpeta de destino. Los archivos de destino tienen nombres generados automáticamente. - MergeFiles: combina todos los archivos de la carpeta de origen en un archivo. Si se especifica el nombre del blob o del archivo, el nombre de archivo combinado es el nombre especificado. De lo contrario, es un nombre de archivo generado automáticamente. |
No |
| blockSizeInMB | Especifique el tamaño de bloque en megabytes que se usa para escribir datos en blobs en bloques. Más información sobre los blobs en bloques. El valor permitido está entre 4 y 100 MB. De forma predeterminada, el servicio determina automáticamente el tamaño de bloque en función del tipo y los datos del almacén de origen. En el caso de una copia no binaria en Blob Storage, el tamaño de bloque predeterminado es de 100 MB, para que pueda ajustarse (como máximo) a 4,95 TB de datos. Este tamaño podría no ser óptimo cuando los datos no son grandes, en especial cuando se usa el entorno de ejecución de integración autohospedado con conexiones de red deficientes, lo que genera incidencias de tiempo de espera de operación o rendimiento. Puede especificar explícitamente un tamaño de bloque, asegurándose de que blockSizeInMB*50000 sea lo suficientemente grande como para almacenar los datos. De lo contrario, se generará un error en la ejecución de la actividad de copia. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
| metadata | Establezca metadatos personalizados al realizar la copia en el receptor. Cada objeto de la matriz metadata representa una columna adicional. name define el nombre de la clave de metadatos y value indica el valor de los datos de esa clave. Si se usa la característica para conservar atributos, los metadatos especificados se unirán a los metadatos del archivo de origen o los sobrescribirán.Los valores permitidos de los datos son: - $$LASTMODIFIED: una variable reservada indica que se debe almacenar la hora de la última modificación de los archivos de origen. Se aplica solo al origen basado en archivos con formato binario.: expresión - Valor estático |
No |
Ejemplo:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobStorageWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
Ejemplos de filtros de carpetas y archivos
Esta sección describe el comportamiento resultante de la ruta de acceso de la carpeta y el nombre de archivo con los filtros de carácter comodín.
| folderPath | fileName | recursive | Resultado de estructura de carpeta de origen y filtro (se recuperan los archivos en negrita) |
|---|---|---|---|
container/Folder* |
(vacío, usar el valor predeterminado) | false | contenedor FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
container/Folder* |
(vacío, usar el valor predeterminado) | true | contenedor FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
container/Folder* |
*.csv |
false | contenedor FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
container/Folder* |
*.csv |
true | contenedor FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Ejemplos de lista de archivos
En esta sección se describe el comportamiento resultante de usar una ruta de acceso de la lista de archivos en el origen de la actividad de copia.
Suponga que tiene la siguiente estructura de carpetas de origen y quiere copiar los archivos en negrita:
| Estructura de origen de ejemplo | Contenido de FileListToCopy.txt | Configuración |
|---|---|---|
| contenedor FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv Metadatos FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
En el conjunto de datos: - Contenedor: container- Ruta de acceso de la carpeta: FolderAEn el origen de la actividad de copia: - Ruta de acceso de la lista de archivos: container/Metadata/FileListToCopy.txt La ruta de la lista de archivos apunta a un archivo de texto en el mismo almacén de datos que incluye una lista de los archivos que desea copiar. Se incluye un archivo por línea, con la ruta de acceso relativa a la ruta de acceso configurada en el conjunto de datos. |
Algunos ejemplos de recursive y copyBehavior
En esta sección se describe el comportamiento resultante de la operación de copia para diferentes combinaciones de valores recursive y copyBehavior.
| recursive | copyBehavior | Estructura de carpetas de origen | Destino resultante |
|---|---|---|---|
| true | preserveHierarchy | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la misma estructura que la de origen: Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
| true | flattenHierarchy | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la misma estructura que la de origen: Folder1 nombre de archivo generado automáticamente para File1 nombre de archivo generado automáticamente para File2 nombre de archivo generado automáticamente para File3 nombre de archivo generado automáticamente para File4 nombre de archivo generado automáticamente para File5 |
| true | mergeFiles | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la misma estructura que la de origen: Folder1 El contenido de File1 + File2 + File3 + File4 + File5 se combina en un archivo con un nombre de archivo generado automáticamente. |
| false | preserveHierarchy | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la misma estructura que la de origen: Folder1 Archivo1 Archivo2 No se selecciona la subcarpeta Subfolder1, con File3, File4 y File5. |
| false | flattenHierarchy | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la misma estructura que la de origen: Folder1 nombre de archivo generado automáticamente para File1 nombre de archivo generado automáticamente para File2 No se selecciona la subcarpeta Subfolder1, con File3, File4 y File5. |
| false | mergeFiles | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la misma estructura que la de origen: Folder1 El contenido de File1 + File2 se combina en un archivo con un nombre de archivo generado automáticamente. nombre de archivo generado automáticamente para File1 No se selecciona la subcarpeta Subfolder1, con File3, File4 y File5. |
Conservación de los metadatos durante la copia
Al copiar archivos de Amazon S3, Azure Blob Storage o Azure Data Lake Storage Gen2 a Azure Data Lake Storage Gen2 o Azure Blob Storage, puede optar por conservar los metadatos de archivo junto con los datos. Más información en Conservación de metadatos.
Propiedades de Asignación de instancias de Data Flow
Al transformar datos en los flujos de datos de asignación, puede leer y escribir archivos desde Azure Blob Storage en los siguientes formatos:
La configuración específica de formato se encuentra en la documentación de ese formato. Para obtener más información, consulte los artículos sobre la transformación de origen en un flujo de datos de asignación y la transformación de receptor en un flujo de datos de asignación.
Transformación de origen
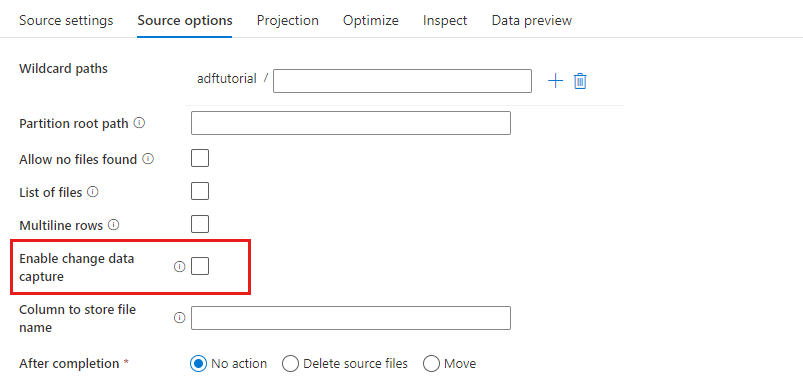
En la transformación de origen, puede leer desde un contenedor, una carpeta o un archivo individual en Azure Blob Storage. Use la pestaña Opciones de origen para administrar cómo se leen los archivos.
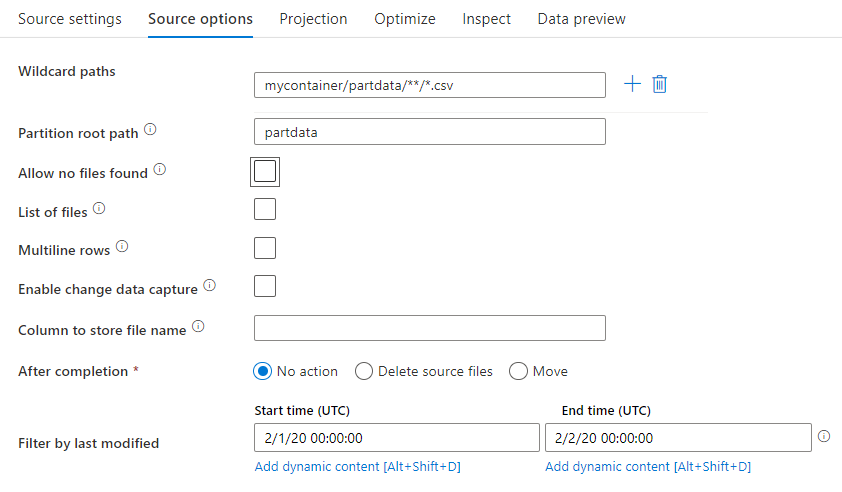
Rutas con carácter comodín: el uso de un patrón de caracteres comodín indicará al servicio que recorra todos los archivos y carpetas que coincidan en una única transformación del origen. Se trata de una manera eficaz de procesar varios archivos en un único flujo. Agregue varios patrones de coincidencia de caracteres comodín con el signo más que aparece al desplazar el puntero sobre el patrón de caracteres comodín existente.
En el contenedor de origen, elija una serie de archivos que coincidan con un patrón. Solo se puede especificar un contenedor en el conjunto de datos. La ruta de acceso con carácter comodín, por tanto, también debe incluir la ruta de acceso de la carpeta de la carpeta raíz.
Ejemplos de caracteres comodín:
*Representa cualquier conjunto de caracteres.**Representa el anidamiento recursivo de directorios.?Reemplaza un carácter.[]Coincide con al menos uno de los caracteres entre corchetes./data/sales/**/*.csvObtiene todos los archivos .csv que se encuentran en /data/sales./data/sales/20??/**/Obtiene todos los archivos del siglo XX./data/sales/*/*/*.csvObtiene los archivos .csv dos niveles debajo de /data/sales./data/sales/2004/*/12/[XY]1?.csvObtiene todos los archivos .csv de diciembre de 2004 que comienzan con X o Y precedido por un número de dos dígitos.
Ruta de acceso raíz de la partición: si tiene carpetas con particiones en el origen de archivo con formato key=value (por ejemplo, year=2019), puede asignar el nivel superior del árbol de carpetas de la partición a un nombre de columna del flujo de datos.
En primer lugar, establezca un comodín que incluya todas las rutas de acceso que sean carpetas con particiones y, además, los archivos de hoja que quiera leer.
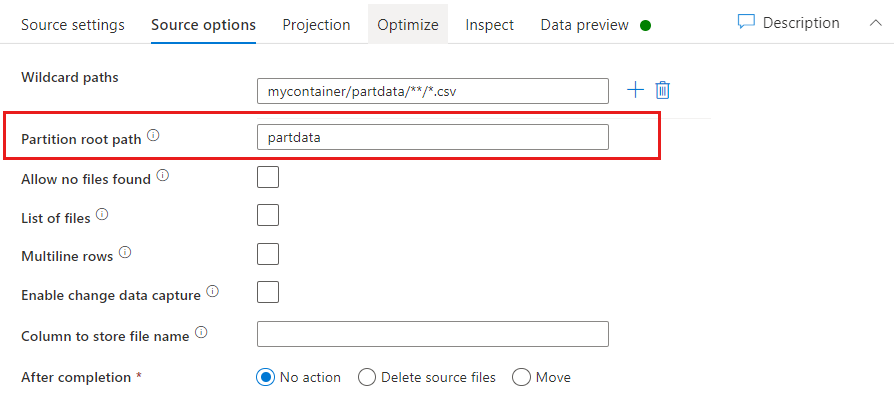
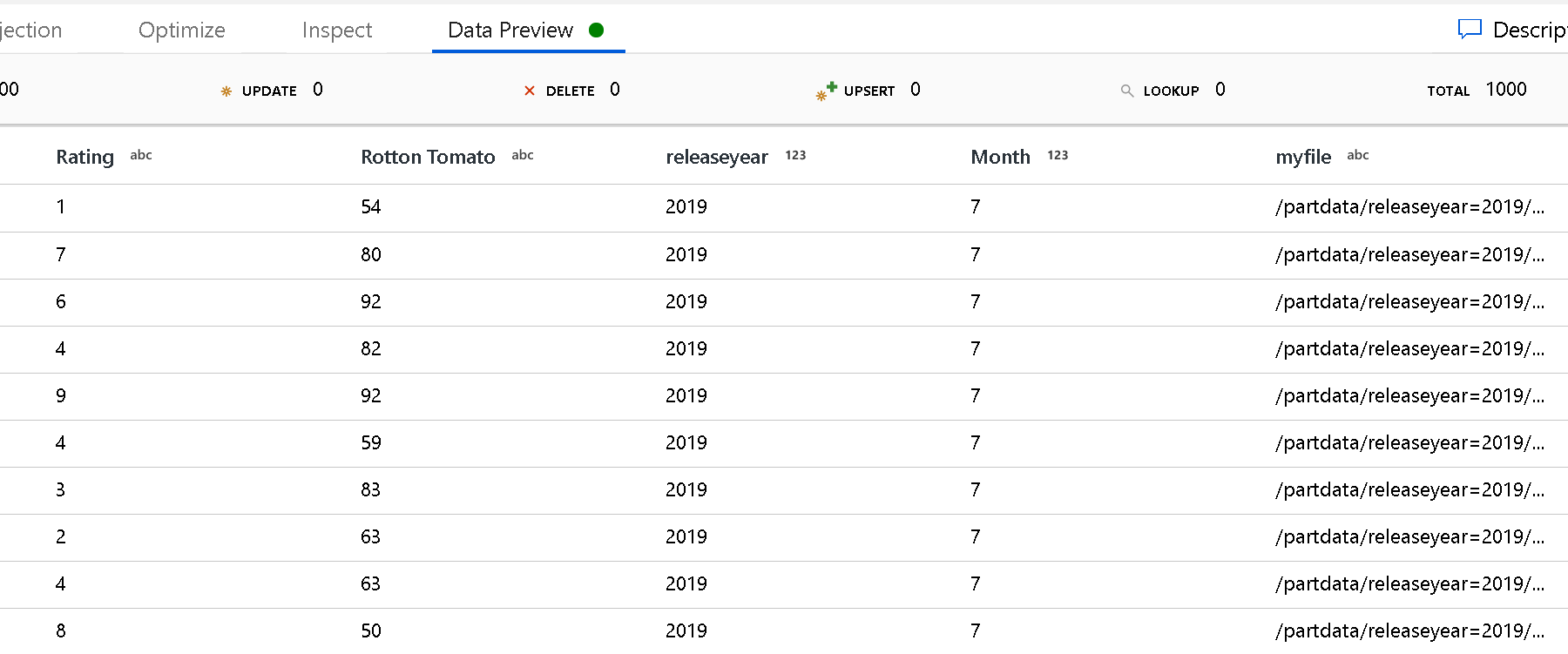
Use el valor de Partition root path (Ruta de acceso de la raíz de la partición) para definir cuál es el nivel superior de la estructura de carpetas. Cuando vea el contenido de sus datos a través de una vista preliminar de datos, verá que el servicio agrega las particiones resueltas encontradas en cada uno de los niveles de carpeta.
Lista de archivos: Se trata de un conjunto de archivos. Cree un archivo de texto que incluya una lista de archivos de ruta de acceso relativa para procesar. Apunte a este archivo de texto.
Column to store file name: (Columna para almacenar el nombre de archivo) Almacene el nombre del archivo de origen en una columna de los datos. Escriba aquí el nombre de una nueva columna para almacenar la cadena de nombre de archivo.
After completion: (Tras finalizar) Elija no hacer nada con el archivo de origen después de que se ejecute el flujo de datos o bien elimine o mueva el archivo de origen. Las rutas de acceso para mover los archivos de origen son relativas.
Para mover archivos de origen a otra ubicación posterior al procesamiento, primero seleccione "Mover" para la operación de archivo. A continuación, establezca el directorio "from". Si no usa ningún carácter comodín para la ruta de acceso, la configuración de "from" será la misma carpeta que la carpeta de origen.
Si tiene una ruta de origen con caracteres comodín, su sintaxis es la siguiente:
/data/sales/20??/**/*.csv
Puede especificar "from" como:
/data/sales
Y puede especificar "to" como:
/backup/priorSales
En este caso, todos los archivos cuyo origen se encuentra en /data/sales se mueven a /backup/priorSales.
Nota
Las operaciones de archivo solo se ejecutan cuando el flujo de datos se inicia desde una ejecución de canalización (depuración o ejecución de canalización) que usa la actividad de ejecución de Data Flow de una canalización. Las operaciones de archivo no se ejecutan en modo de depuración de Data Flow.
Filtrar por última modificación: Puede filtrar los archivos que desea procesar especificando un intervalo de fechas de la última vez que se modificaron. Todos los valores datetime están en formato UTC.
Habilitar captura de datos modificados: si el valor es "true", solo obtendrá archivos nuevos o modificados de la última ejecución. La carga inicial de datos completos de instantáneas siempre se realizará en la primera ejecución, seguida por la captura de archivos nuevos o modificados solo en las ejecuciones posteriores.
Propiedades del receptor
En la transformación del receptor, puede escribir en un contenedor o carpeta en Azure Blob Storage. Use la pestaña Configuración para administrar cómo se escriben los archivos.
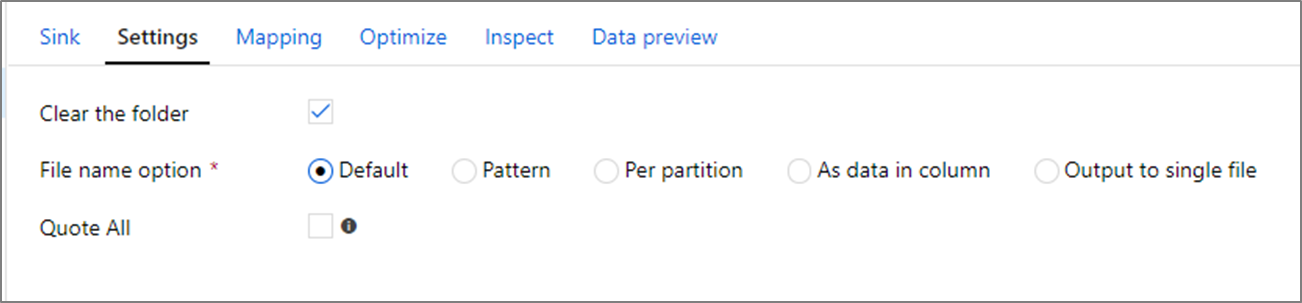
Clear the folder (Borrar la carpeta): determina si se borra o no la carpeta de destino antes de escribir los datos.
File name option (Opción de nombre de archivo): determina cómo se denominan los archivos de destino en la carpeta de destino. Las opciones de nombre de archivo son:
- Valor predeterminado: permita que Spark nombre los archivos según los valores predeterminados de PART.
- Patrón: escriba un patrón que enumere los archivos de salida por partición. Por ejemplo,
loans[n].csvcrearloans1.csv,loans2.csv, y así sucesivamente. - Por partición: escriba un nombre de archivo por partición.
- Como datos de columna: establezca el archivo de salida en el valor de una columna. La ruta de acceso es relativa al contenedor del conjunto de datos, no a la carpeta de destino. Si tiene una ruta de acceso de carpeta en el conjunto de datos, se invalidará.
- Salida en un solo archivo: combine los archivos de salida con particiones en un solo archivo con nombre. La ruta de acceso es relativa a la carpeta del conjunto de datos. Tenga en cuenta que la operación Merge probablemente produzca un error en función del tamaño del nodo. No se recomienda esta opción para conjuntos de datos de gran tamaño.
Quote all (Entrecomillar todo): determina si todos los valores se deben entrecomillar.
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Propiedades de la actividad GetMetadata
Para información detallada sobre las propiedades, consulte la actividad GetMetadata.
Propiedades de la actividad de eliminación
Para información detallada sobre las propiedades, consulte Actividad de eliminación.
Modelos heredados
Nota
Estos modelos siguen siendo compatibles con versiones anteriores. Se recomienda usar el nuevo modelo mencionado anteriormente. La interfaz de usuario de creación se ha cambiado para generar el nuevo modelo.
Modelo de conjunto de datos heredado
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en AzureBlob. |
Sí |
| folderPath | Ruta de acceso para el contenedor y la carpeta en Blob Storage. Un filtro de comodín es compatible con la ruta de acceso sin incluir el nombre del contenedor. Los caracteres comodín permitidos son: * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter). Use ^ como escape si el nombre de la carpeta contiene un carácter comodín o este carácter de escape. Un ejemplo sería myblobcontainer/myblobfolder/. Ver más ejemplos en Ejemplos de filtros de carpetas y archivos. |
Sí, para la actividad de copia o búsqueda; no, para la actividad GetMetadata |
| fileName | Filtro de nombre o carácter comodín para los blobs de la ruta folderPath especificada. Si no especifica ningún valor para esta propiedad, el conjunto de datos apunta a todos los blobs de la carpeta. Para el filtro, los caracteres comodín permitidos son: * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter).- Ejemplo 1: "fileName": "*.csv"- Ejemplo 2: "fileName": "???20180427.txt"Use ^ como escape si el nombre de archivo contiene un carácter comodín o este carácter de escape.Cuando fileName no se especifica para un conjunto de datos de salida y preserveHierarchy no se determina en el receptor de la actividad, la actividad de copia generará automáticamente el nombre de blob con el siguiente patrón: "Data.[GUID de id. de ejecución de actividad].[GUID, si FlattenHierarchy].[formato, si está configurado].[compresión, si está configurada] ". Por ejemplo: "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Si realiza una copia desde el origen tabular usando el nombre de una tabla en lugar de una consulta, el patrón del nombre es [table name].[format].[compression if configured]. Por ejemplo: "MyTable.csv". |
No |
| modifiedDatetimeStart | Los archivos se filtran en función del atributo Last Modified. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato "2018-12-01T05:00:00Z". Tenga en cuenta que activar esta opción afecta al rendimiento general del movimiento de datos cuando desee filtrar grandes cantidades de archivos. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene un valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene un valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea menor que el valor de fecha y hora. |
No |
| modifiedDatetimeEnd | Los archivos se filtran en función del atributo Last Modified. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato "2018-12-01T05:00:00Z". Tenga en cuenta que activar esta opción afecta al rendimiento general del movimiento de datos cuando desee filtrar grandes cantidades de archivos. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene un valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene un valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea menor que el valor de fecha y hora. |
No |
| format | Si desea copiar los archivos tal cual entre los almacenes basados en archivos (copia binaria), omita la sección de formato en las definiciones de los conjuntos de datos de entrada y salida. Si quiere analizar o generar archivos con un formato concreto, se admiten los siguientes tipos de formato de archivo: TextFormat, JsonFormat, AvroFormat, OrcFormat y ParquetFormat. Establezca la propiedad type en format en uno de los siguientes valores. Para más información, consulte las secciones Formato de texto, Formato JSON, Formato AVRO, Formato ORC y Formato Parquet. |
No (solo para el escenario de copia binaria) |
| compression | Especifique el tipo y el nivel de compresión de los datos. Para más información, consulte el artículo sobre códecs de compresión y formatos de archivo compatibles. Los tipos admitidos son GZip, Deflate, BZip2 y ZipDeflate. Niveles admitidos son Optimal y Fastest. |
No |
Sugerencia
Para copiar todos los blobs en una carpeta, especifique solo folderPath.
Para copiar un único blob con un nombre determinado, especifique folderPath para la sección de la carpeta y fileName para el nombre de archivo.
Para copiar un subconjunto de blobs en una carpeta, especifique folderPath para la sección de la carpeta y fileName con un filtro de comodín.
Ejemplo:
{
"name": "AzureBlobDataset",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Modelo de origen heredado para la actividad de copia
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en BlobSource: |
Sí |
| recursive | Indica si los datos se leen de forma recursiva de las subcarpetas o solo de la carpeta especificada. Cuando recursive se establece entrue y el receptor es un almacén basado en archivos, no se copia ni se crea ninguna carpeta ni subcarpeta vacía en el receptor.Los valores permitidos son: true (valor predeterminado) y false. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Blob input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "BlobSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Modelo de receptor heredado para la actividad de copia
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del receptor de la actividad de copia debe establecerse en BlobSink: |
Sí |
| copyBehavior | Define el comportamiento de copia cuando el origen son archivos de un almacén de datos basados en archivos. Los valores permitidos son: - PreserveHierarchy (valor predeterminado): conserva la jerarquía de archivos en la carpeta de destino. La ruta de acceso relativa del archivo de origen que apunta a la carpeta de origen es idéntica a la ruta de acceso relativa del archivo de destino que apunta a la carpeta de destino. - FlattenHierarchy: todos los archivos de la carpeta de origen están en el primer nivel de la carpeta de destino. Los archivos de destino tienen nombres generados automáticamente. - MergeFiles: combina todos los archivos de la carpeta de origen en un archivo. Si se especifica el nombre del blob o del archivo, el nombre de archivo combinado es el nombre especificado. De lo contrario, es un nombre de archivo generado automáticamente. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo:
"activities":[
{
"name": "CopyToBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Blob output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "BlobSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
captura de datos modificados
Azure Data Factory puede obtener archivos nuevos o modificados solo desde Azure Blob Storage mediante la activación de **Habilitar captura de datos modificados** en la transformación del origen de flujo de datos de asignación. Mediante esta opción de conector, solo podrá leer archivos nuevos o modificados y aplicar transformaciones antes de cargar los datos transformados en los conjuntos de datos de destino de su elección. Para más detalles, consulte Captura de datos modificados.
Contenido relacionado
Para obtener una lista de los almacenes de datos que la actividad de copia admite como orígenes y receptores, vea Almacenes de datos admitidos.