Actividad Búsqueda de Azure Data Factory y Azure Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
La actividad Búsqueda puede recuperar un conjunto de datos desde cualquiera de los orígenes de datos admitidos por las canalizaciones de Synapse y Data Factory. Puede usarla para determinar de forma dinámica los objetos en los que operar en una actividad posterior, en lugar de codificar de forma rígida el nombre del objeto. Algunos ejemplos de objeto son los archivos y las tablas.
La actividad de búsqueda lee y devuelve el contenido de una tabla o un archivo de configuración. También devuelve el resultado de ejecutar una consulta o un procedimiento almacenado. La salida puede ser un valor singleton o una matriz de atributos, que se puede utilizar en una copia posterior, una transformación o actividades de flujo de control como la actividad ForEach.
Creación de una actividad de búsqueda con la interfaz de usuario
Para usar una actividad de búsqueda en una canalización, complete los pasos siguientes:
Busque el valor Lookup en el panel Actividades de canalización y arrastre una actividad de búsqueda al lienzo de canalización.
Seleccione la nueva actividad de búsqueda en el lienzo si aún no está seleccionada y la pestaña Configuración para editar sus detalles.
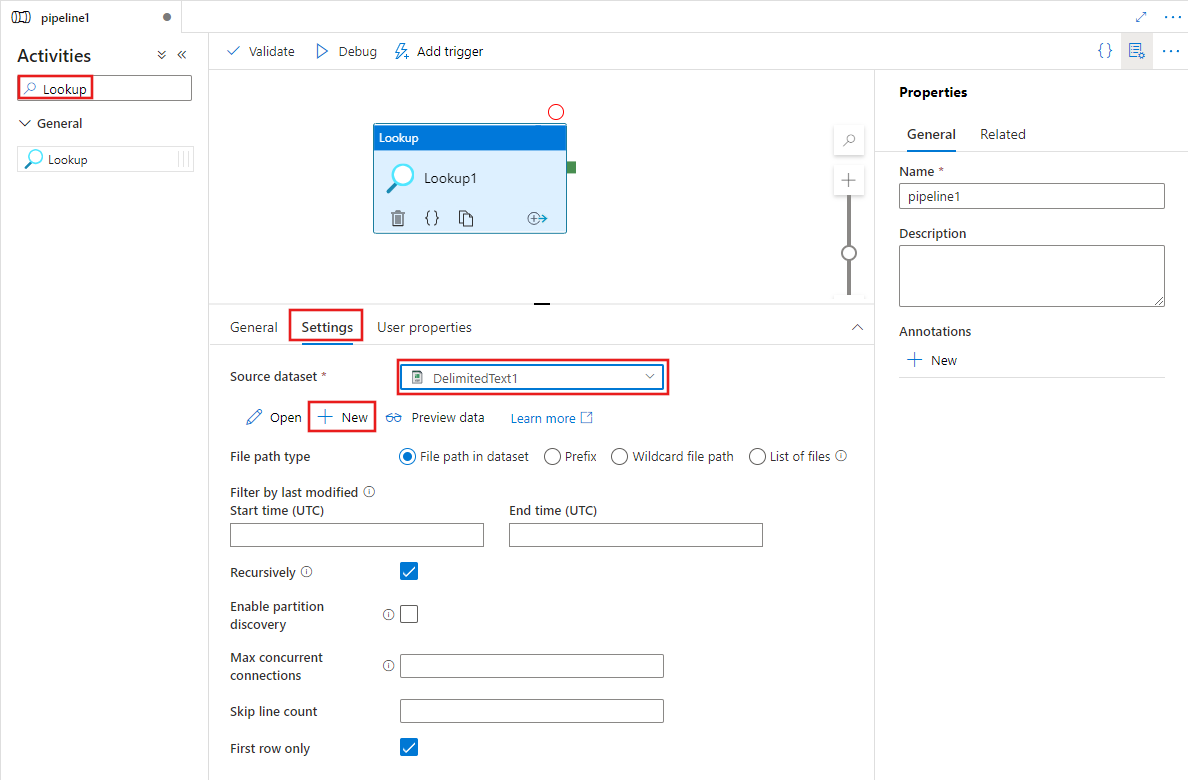
Elija un conjunto de datos de origen existente o seleccione el botón Nuevo para crear uno nuevo.
Las opciones para identificar las filas que se van a incluir del conjunto de datos de origen variarán en función del tipo de conjunto de datos. En el ejemplo anterior se muestran las opciones de configuración de un conjunto de datos de texto delimitado. A continuación, se muestran ejemplos de opciones de configuración para un conjunto de tabla de Azure SQL y un conjunto de datos de OData.
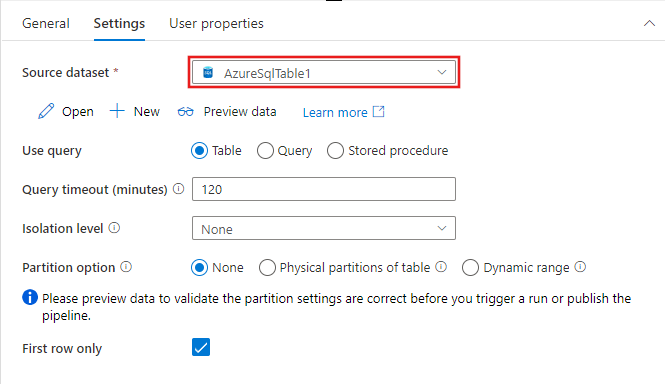
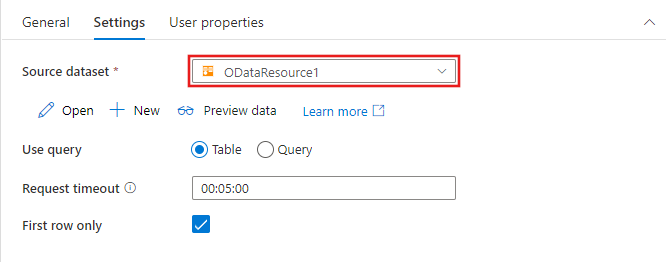
Funcionalidades admitidas
Tenga en cuenta lo siguiente:
- La actividad de búsqueda puede devolver hasta 5000 filas; si el conjunto de resultados contiene más registros, se devolverán las primeras 5000 filas.
- La salida de la actividad de búsqueda admite hasta 4 MB de tamaño; la actividad producirá un error si el tamaño supera el límite.
- La duración máxima de la actividad de búsqueda antes de agotarse el tiempo de espera es de 24 horas.
Nota
Cuando use la consulta o el procedimiento almacenado para buscar datos, asegúrese de que devuelve un conjunto de resultados y solo uno. De lo contrario, se producirá un error en la actividad de búsqueda.
Se admiten los siguientes orígenes de datos para la actividad de búsqueda.
Nota
Cuando aparece entre paréntesis versión preliminar después del nombre del conector, significa que puede probarlo y enviarnos sus comentarios. Si desea depender de los conectores de versión preliminar en la solución, póngase en contacto con el soporte técnico de Azure.
Sintaxis
{
"name":"LookupActivity",
"type":"Lookup",
"typeProperties":{
"source":{
"type":"<source type>"
},
"dataset":{
"referenceName":"<source dataset name>",
"type":"DatasetReference"
},
"firstRowOnly":<true or false>
}
}
Propiedades de tipo
| Nombre | Description | Tipo | ¿Necesario? |
|---|---|---|---|
| dataset | Proporciona la referencia de conjunto de datos para la búsqueda. Obtenga los detalles de la sección Propiedades del conjunto de datos de cada artículo del conector correspondiente. | Par clave-valor | Sí |
| source | Contiene propiedades de origen específicas para el conjunto de datos, al igual que el origen de la actividad de copia. Obtenga los detalles de la sección Copiar propiedades de la actividad de cada artículo del conector correspondiente. | Par clave-valor | Sí |
| firstRowOnly | Indica si se deben devolver todas las filas o solo la primera. | Boolean | No. El valor predeterminado es true. |
Nota
- No se admiten las columnas de origen con el tipo ByteArray.
- La estructura no se admite en las definiciones del conjunto de datos. En el caso de los archivos de formato de texto, utilice la fila de encabezado para proporcionar el nombre de columna.
- Si el origen de la búsqueda es un archivo JSON, la configuración
jsonPathDefinitionpara cambiar la forma del objeto JSON no se admite. Se recuperarán los objetos completos.
Uso del resultado de la actividad de búsqueda
El resultado de la búsqueda se devuelve en la sección output del resultado de ejecución de la actividad.
Cuando
firstRowOnlyestá establecido entrue(valor predeterminado) , el formato de salida es como se muestra en el código siguiente. El resultado de búsqueda está en una clavefirstRowfija. Para utilizar el resultado en una actividad posterior, utilice el patrón de@{activity('LookupActivity').output.firstRow.table}.{ "firstRow": { "Id": "1", "schema":"dbo", "table":"Table1" } }Cuando
firstRowOnlyestá establecido enfalse, el formato de salida es como se muestra en el código siguiente. Un campocountindica cuántos registros se devuelven. Se muestran los valores detallados bajo una matrizvaluefija. En tal caso, la actividad de búsqueda va seguida de una actividad ForEach. Pase la matrizvalueal campoitemsde la actividad ForEach mediante el patrón de@activity('MyLookupActivity').output.value. Para acceder a elementos en la matrizvalue, use la siguiente sintaxis:@{activity('lookupActivity').output.value[zero based index].propertyname}. Un ejemplo es@{activity('lookupActivity').output.value[0].schema}.{ "count": "2", "value": [ { "Id": "1", "schema":"dbo", "table":"Table1" }, { "Id": "2", "schema":"dbo", "table":"Table2" } ] }
Ejemplo
En este ejemplo, la canalización tiene dos actividades: búsqueda y copia. La actividad de copia realiza una copia de los datos de una tabla SQL de la instancia de Azure SQL Database en Azure Blob Storage. El nombre de la tabla SQL se almacena en un archivo JSON en Blob Storage. La actividad de búsqueda busca el nombre de la tabla en entorno de tiempo de ejecución. JSON se modifica de forma dinámica con este enfoque. No es necesario volver a implementar canalizaciones ni conjuntos de datos.
En este ejemplo se muestra solo la búsqueda de la primera fila. Para la búsqueda de todas las filas y el encadenamiento de los resultados con la actividad ForEach, vea los ejemplos de Copia masiva de varias tablas.
Canalización
- La actividad de búsqueda está configurada para usar LookupDataset, que hace referencia a una ubicación en una instancia de Azure Blob Storage. La actividad de búsqueda lee el nombre de la tabla SQL desde un archivo JSON en esta ubicación.
- La actividad de copia usa la salida de la actividad de búsqueda, que es el nombre de la tabla SQL. La propiedad tableName en SourceDataset se configura para usar la salida de la actividad de búsqueda. Con la actividad de copia se copian datos de la tabla SQL en una ubicación de Azure Blob Storage. La ubicación se especifica mediante la propiedad SinkDataset.
{
"name": "LookupPipelineDemo",
"properties": {
"activities": [
{
"name": "LookupActivity",
"type": "Lookup",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "JsonSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "JsonReadSettings"
}
},
"dataset": {
"referenceName": "LookupDataset",
"type": "DatasetReference"
},
"firstRowOnly": true
}
},
{
"name": "CopyActivity",
"type": "Copy",
"dependsOn": [
{
"activity": "LookupActivity",
"dependencyConditions": [
"Succeeded"
]
}
],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderQuery": {
"value": "select * from [@{activity('LookupActivity').output.firstRow.schema}].[@{activity('LookupActivity').output.firstRow.table}]",
"type": "Expression"
},
"queryTimeout": "02:00:00",
"partitionOption": "None"
},
"sink": {
"type": "DelimitedTextSink",
"storeSettings": {
"type": "AzureBlobStorageWriteSettings"
},
"formatSettings": {
"type": "DelimitedTextWriteSettings",
"quoteAllText": true,
"fileExtension": ".txt"
}
},
"enableStaging": false,
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": false
}
}
},
"inputs": [
{
"referenceName": "SourceDataset",
"type": "DatasetReference",
"parameters": {
"schemaName": {
"value": "@activity('LookupActivity').output.firstRow.schema",
"type": "Expression"
},
"tableName": {
"value": "@activity('LookupActivity').output.firstRow.table",
"type": "Expression"
}
}
}
],
"outputs": [
{
"referenceName": "SinkDataset",
"type": "DatasetReference",
"parameters": {
"schema": {
"value": "@activity('LookupActivity').output.firstRow.schema",
"type": "Expression"
},
"table": {
"value": "@activity('LookupActivity').output.firstRow.table",
"type": "Expression"
}
}
}
]
}
],
"annotations": [],
"lastPublishTime": "2020-08-17T10:48:25Z"
}
}
Conjunto de datos de búsqueda
El conjunto de datos lookup es el archivo sourcetable.json de la carpeta de búsqueda de Azure Storage especificada por el tipo AzureStorageLinkedService.
{
"name": "LookupDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorageLinkedService",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "Json",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "sourcetable.json",
"container": "lookup"
}
}
}
}
Conjunto de datos source para la actividad de copia
El conjunto de datos source usa la salida de la actividad de búsqueda, que es el nombre de la tabla SQL. Con la actividad de copia se copian datos de esta tabla SQL en una ubicación de Azure Blob Storage. La ubicación se especifica mediante el conjunto de datos sink.
{
"name": "SourceDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureSqlDatabase",
"type": "LinkedServiceReference"
},
"parameters": {
"schemaName": {
"type": "string"
},
"tableName": {
"type": "string"
}
},
"annotations": [],
"type": "AzureSqlTable",
"schema": [],
"typeProperties": {
"schema": {
"value": "@dataset().schemaName",
"type": "Expression"
},
"table": {
"value": "@dataset().tableName",
"type": "Expression"
}
}
}
}
Conjunto de datos sink para la actividad de copia
Con la actividad de copia se copian datos de la tabla SQL en el archivo filebylookup.csv de la carpeta csv en Azure Storage. La propiedad AzureBlobStorageLinkedService especifica el archivo.
{
"name": "SinkDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorageLinkedService",
"type": "LinkedServiceReference"
},
"parameters": {
"schema": {
"type": "string"
},
"table": {
"type": "string"
}
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": {
"value": "@{dataset().schema}_@{dataset().table}.csv",
"type": "Expression"
},
"container": "csv"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
sourcetable.json
Puede usar los dos tipos siguientes de formatos para el archivo sourcetable.json.
Conjunto de objetos
{
"Id":"1",
"schema":"dbo",
"table":"Table1"
}
{
"Id":"2",
"schema":"dbo",
"table":"Table2"
}
Matriz de objetos
[
{
"Id": "1",
"schema":"dbo",
"table":"Table1"
},
{
"Id": "2",
"schema":"dbo",
"table":"Table2"
}
]
Limitaciones y soluciones alternativas
A continuación se indican algunas de las limitaciones de la actividad de búsqueda y las soluciones alternativas sugeridas.
| Limitación | Solución alternativa |
|---|---|
| La actividad de búsqueda tiene un máximo de 5000 filas y un tamaño máximo de 4 MB. | Diseñe una canalización de dos niveles donde la canalización exterior recorra en iteración una canalización interna, que recupera datos que no superan el tamaño o el número máximo de filas. |
Contenido relacionado
Vea otras actividades de flujo de control compatibles con las canalizaciones de Azure Data Factory y Synapse: